논문분석: Batch Normalization : Accelerating Deep Network Training by Reducing Internal Covariate Shift
paper_review

스터디원의 발표였던 Batch Normalization 논문을 스티디원 발표의 순서에 따라 정리해보겠다.
Advantages of BN
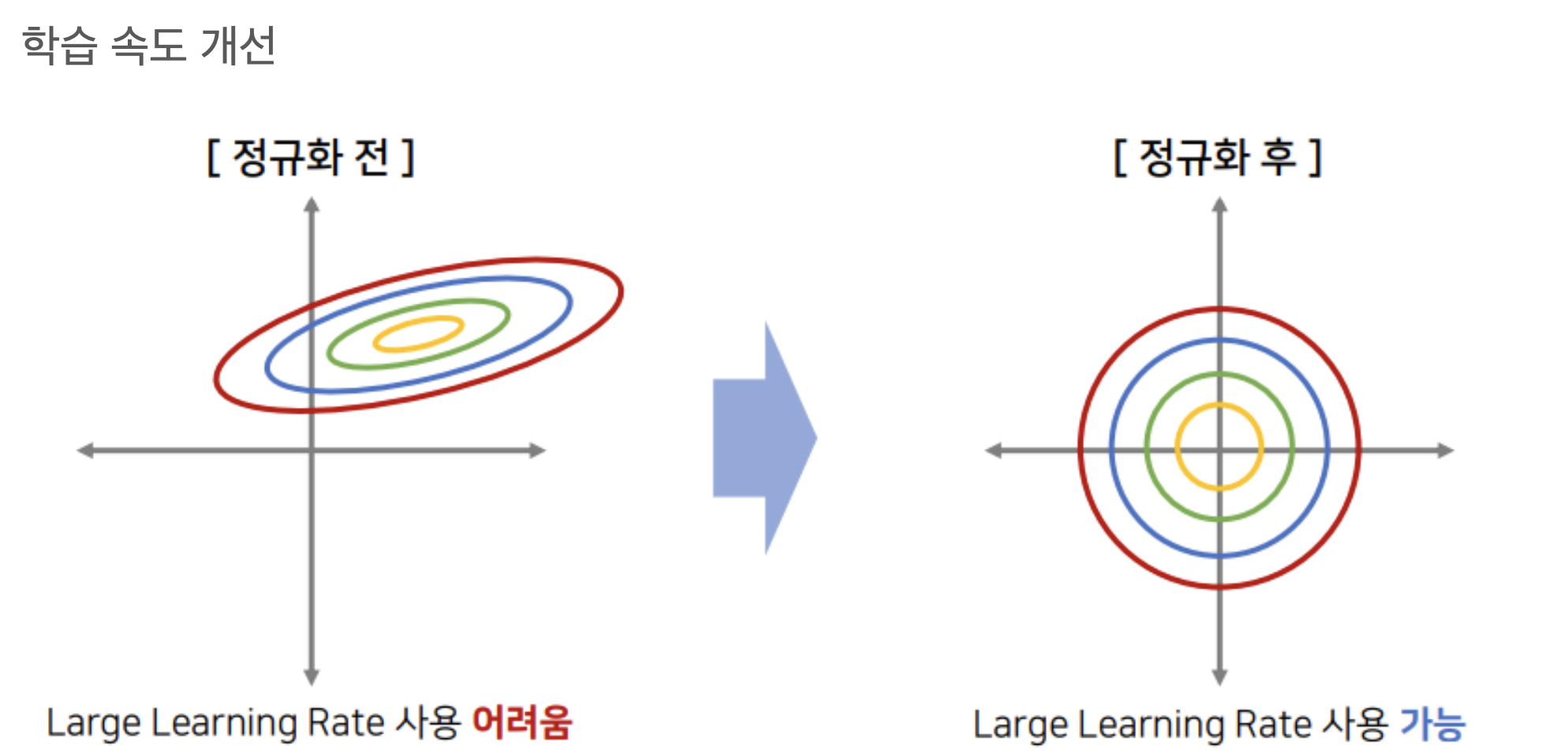
학습 속도 개선 -> 큰 learning rate 사용 가능
가중치 초기화에 대한 민감도 개선
Regularization(일반화) 효과
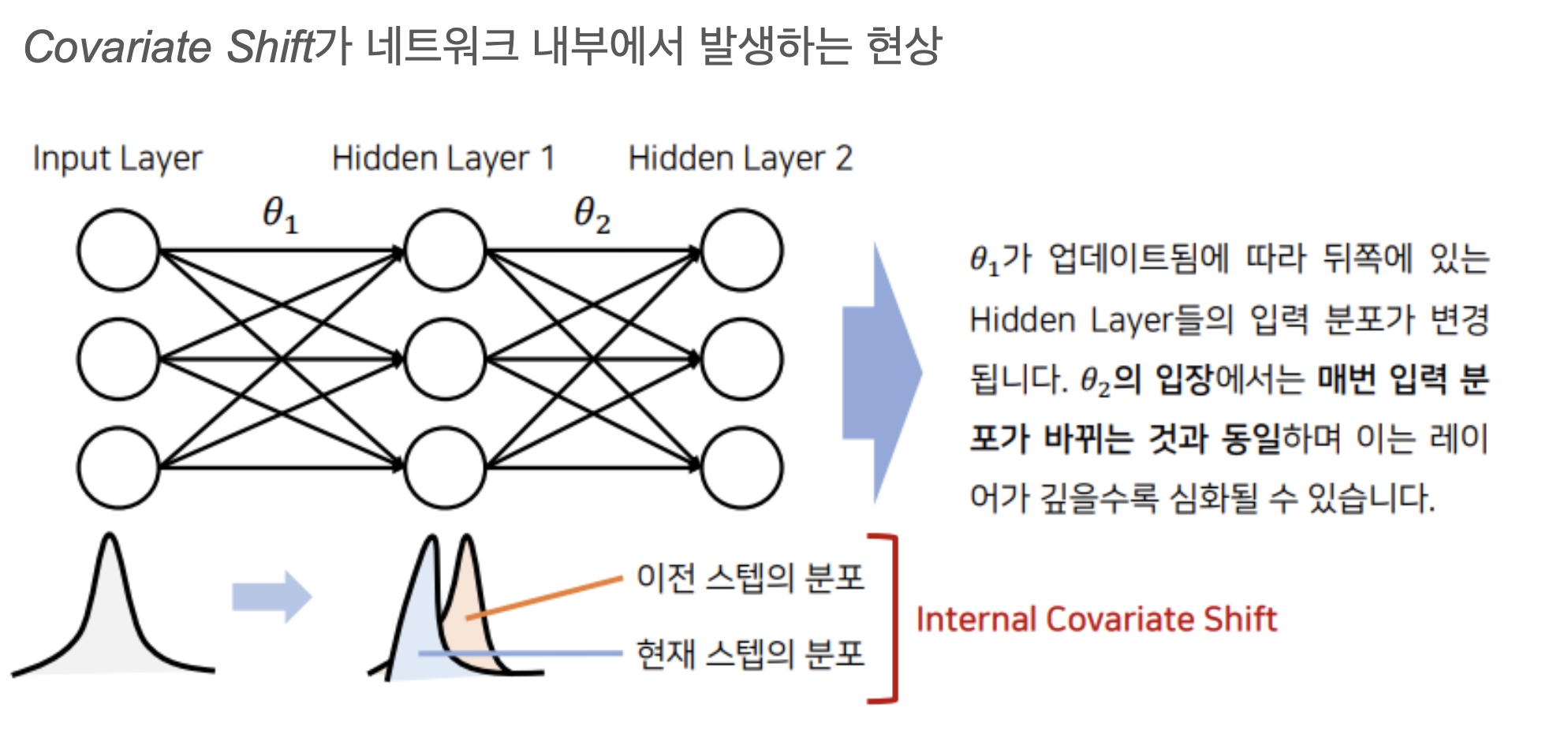
Internal Covariate Shift
When the input distribution to a learning system changes, it is said to experience covariate shift (Shimodaira, 2000).
We refer to the change in the distributions of internal nodes of a deep network, in the course of training, as Internal Covariate Shift.
We define Internal Covariate Shift as the change in the distribution of network activations due to the change in network parameters during training.
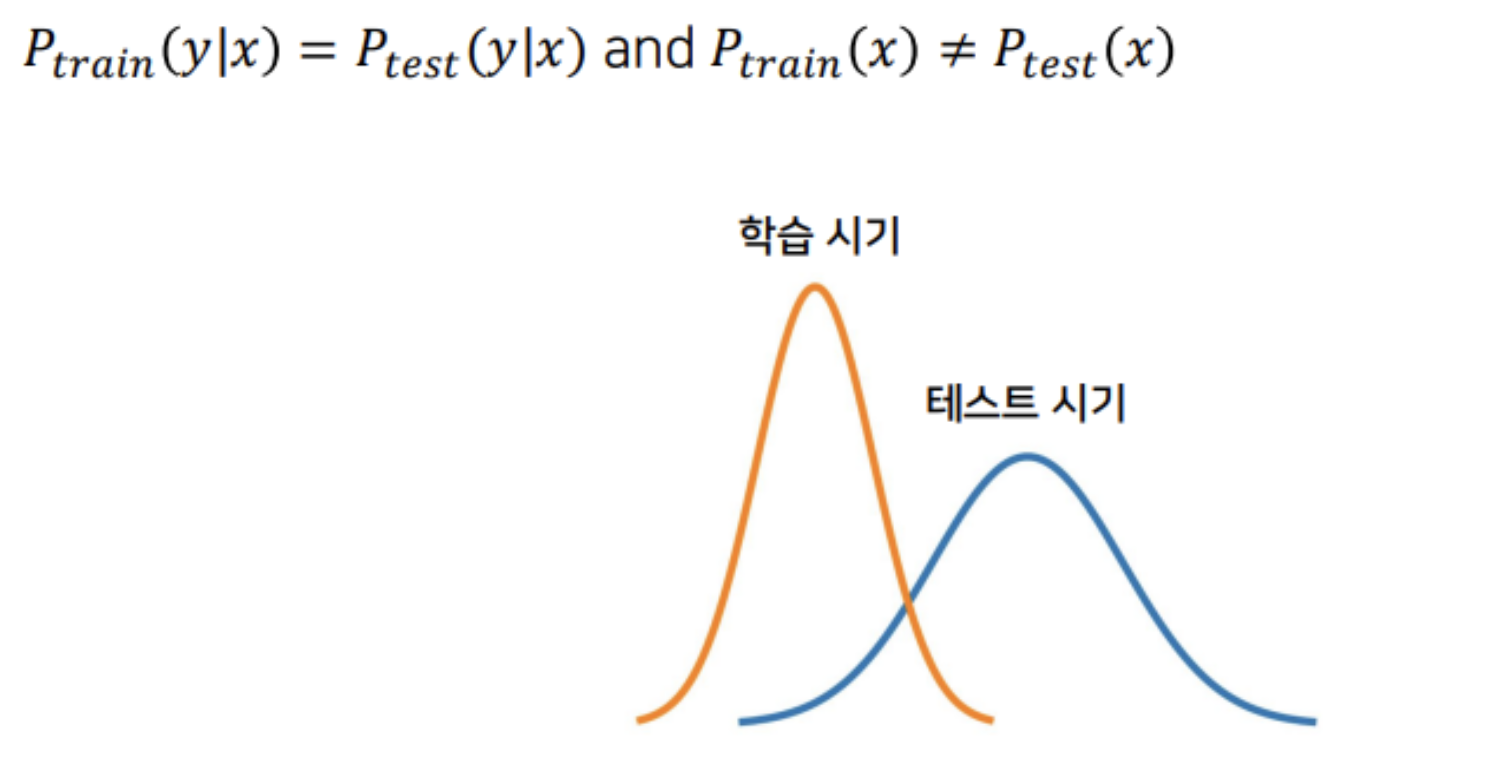
Covariate Shift
공변량 변화(Covariate Shift): 학습 시기와는 다르게 테스트 시기에 입력 데이터의 분포가 변경되는 현상
Whitening vs Normalization
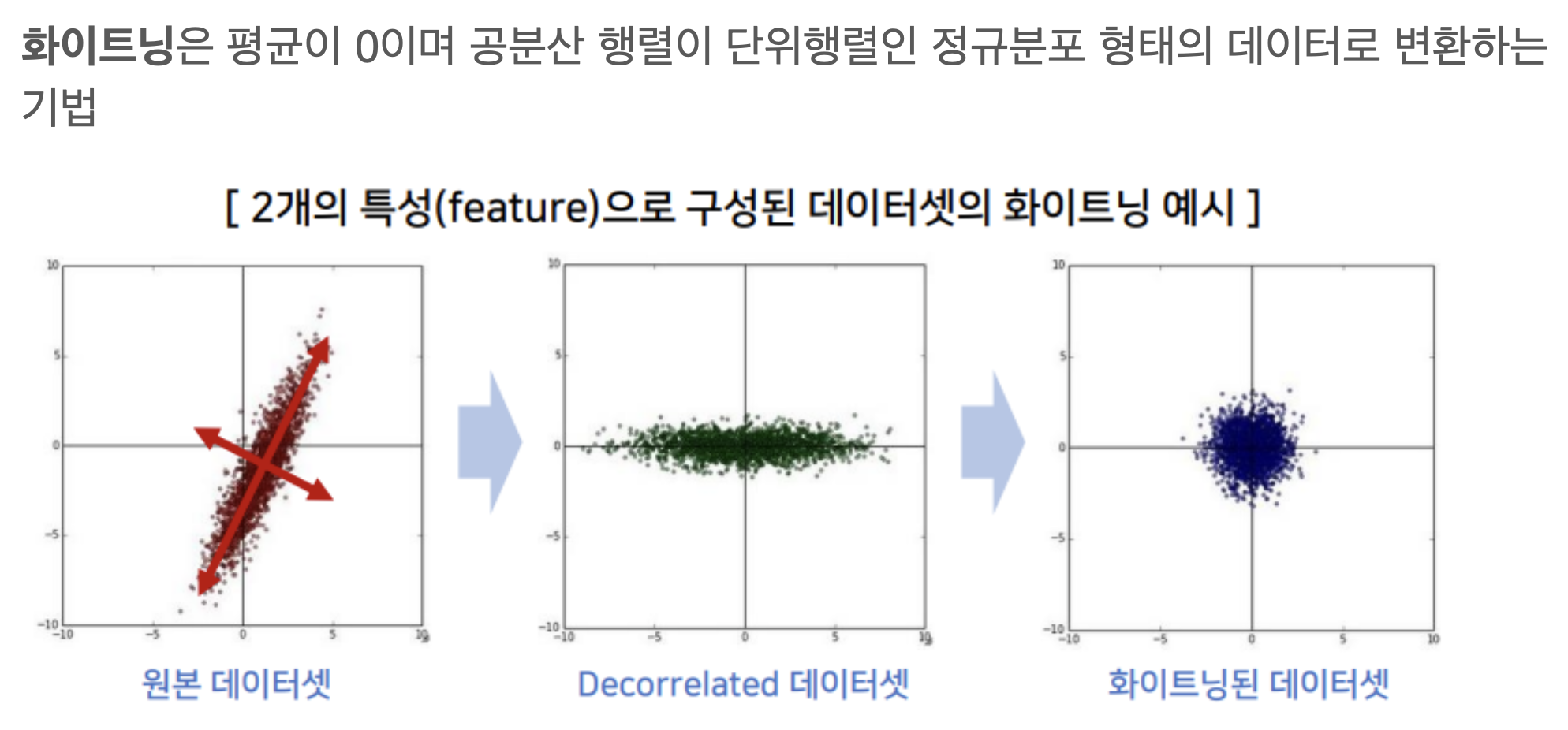
It has been long known (LeCun et al., 1998b; Wiesler & Ney, 2011) that the network training converges faster if its inputs are whitened – i.e., linearly transformed to have zero means and unit variances, and decorrelated.
Since the full whitening of each layer’s inputs is costly and not everywhere differentiable, we make two necessary simplifications. The first is that instead of whitening the features in layer inputs and outputs jointly, we will normalize each scalar feature independently, by making it have the mean of zero and the variance of 1.
As shown in (LeCun et al., 1998b), such normalization speeds up convergence, even when the features are not decorrelated.
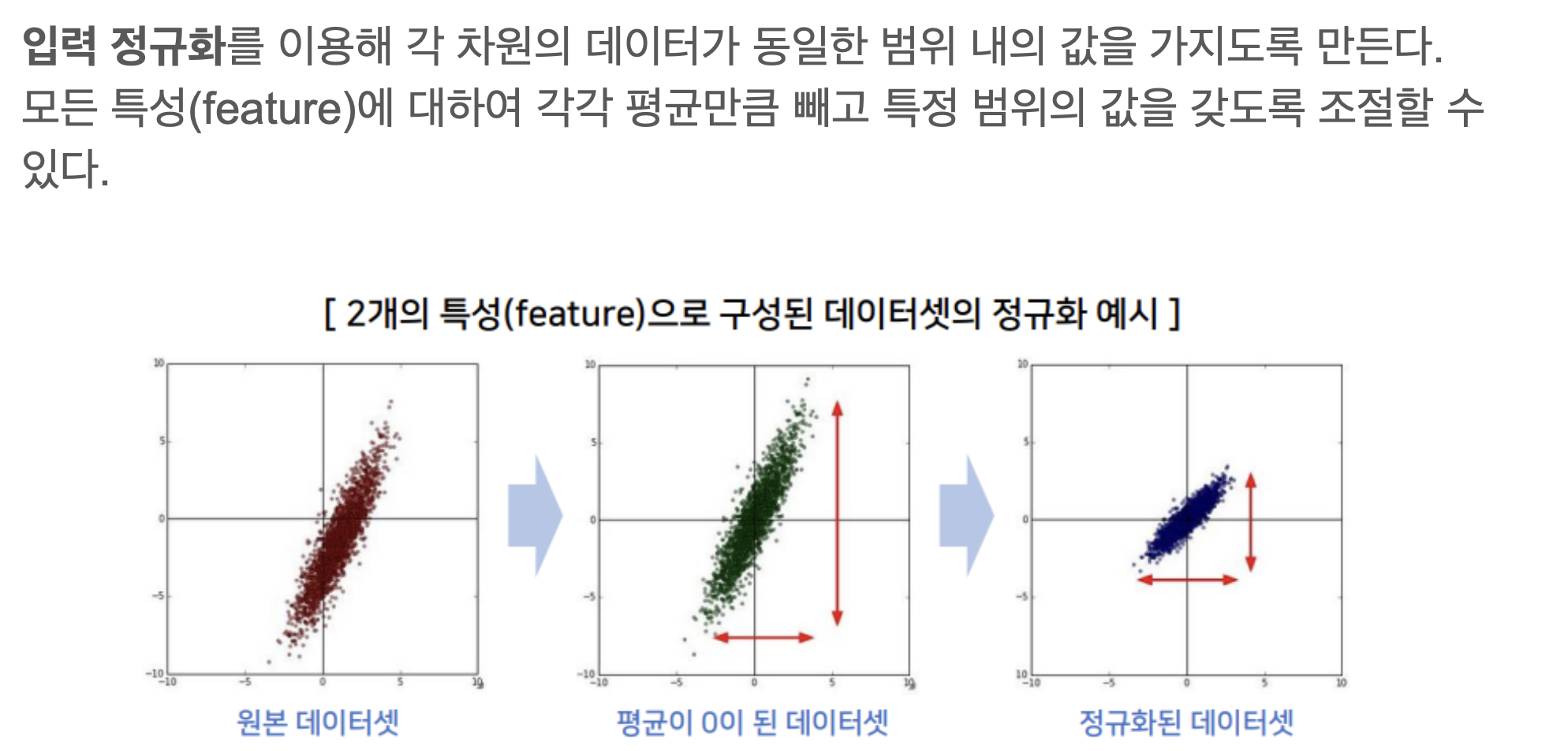
Normalization
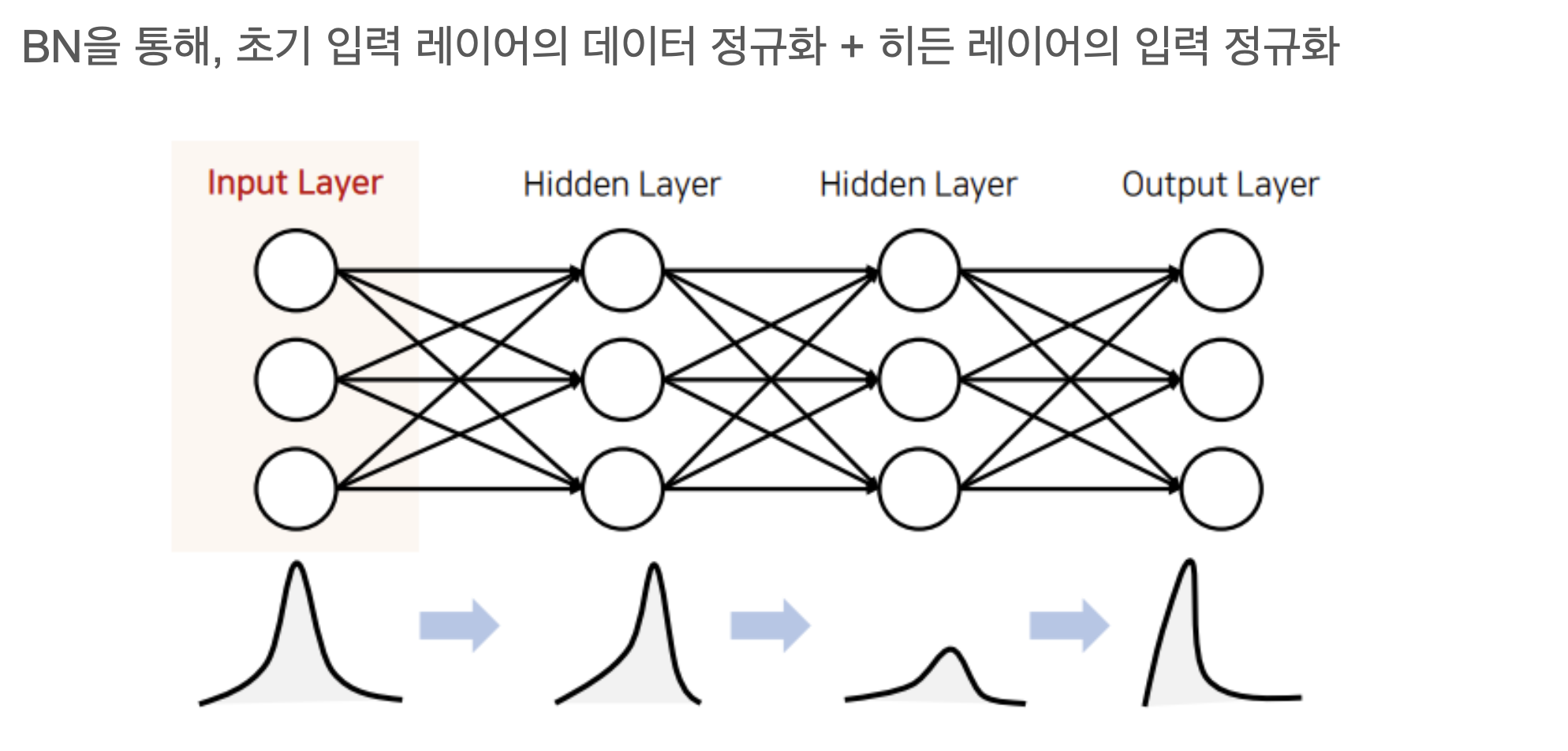
각 Layer 입력 분포
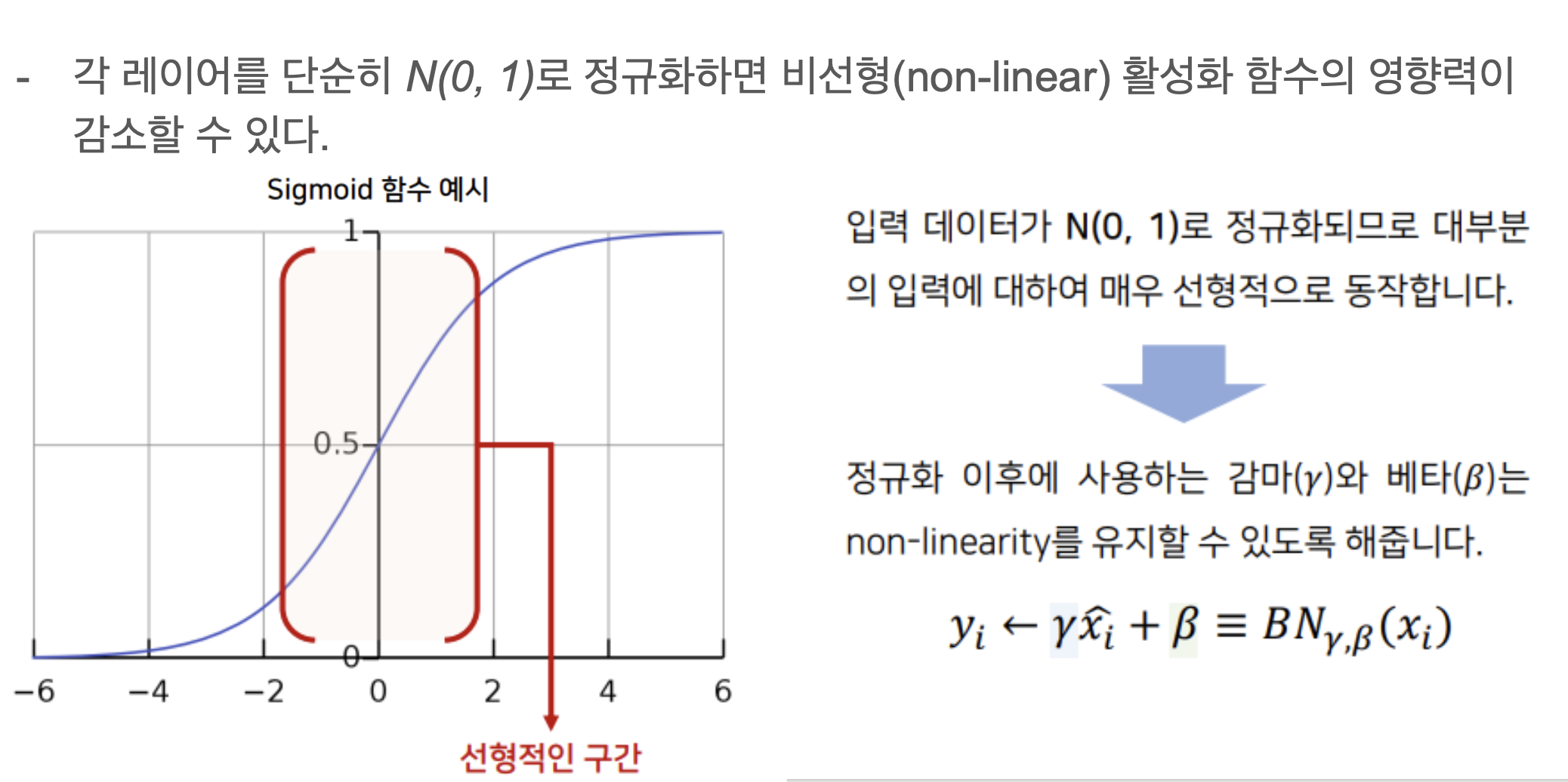
Batch Normalization

γ, β 파라미터의 필요성
BN: 학습(Training) 및 추론(Inference)

Gradient 계산
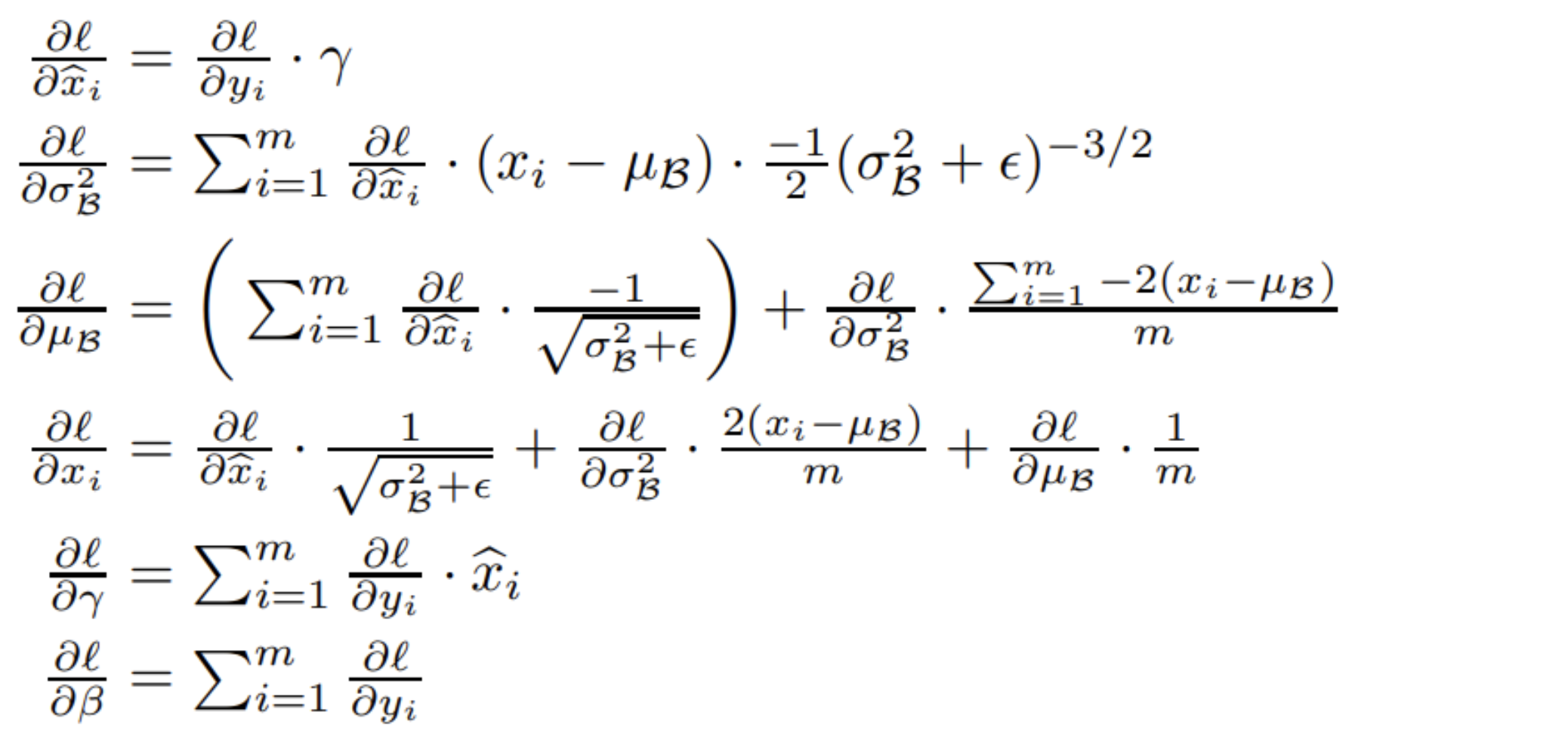
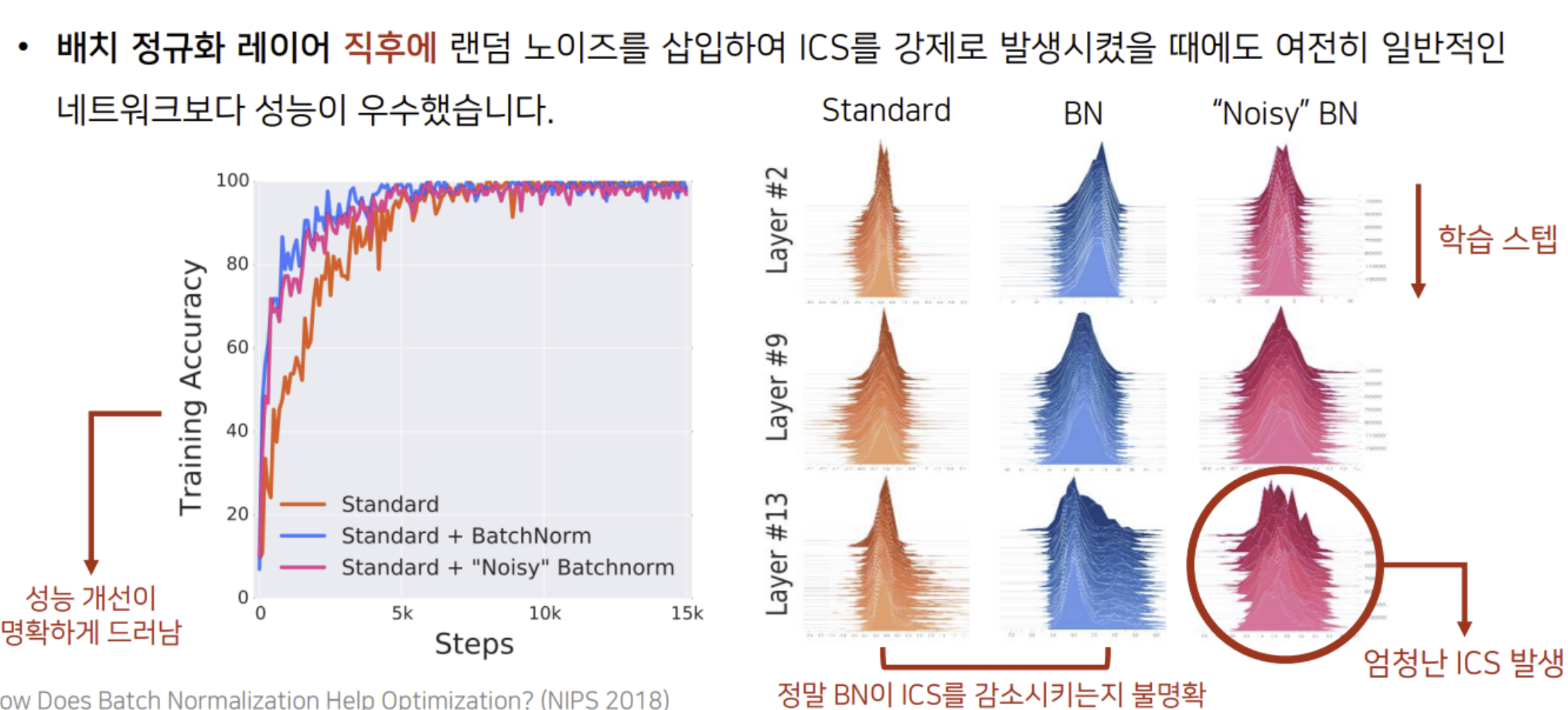
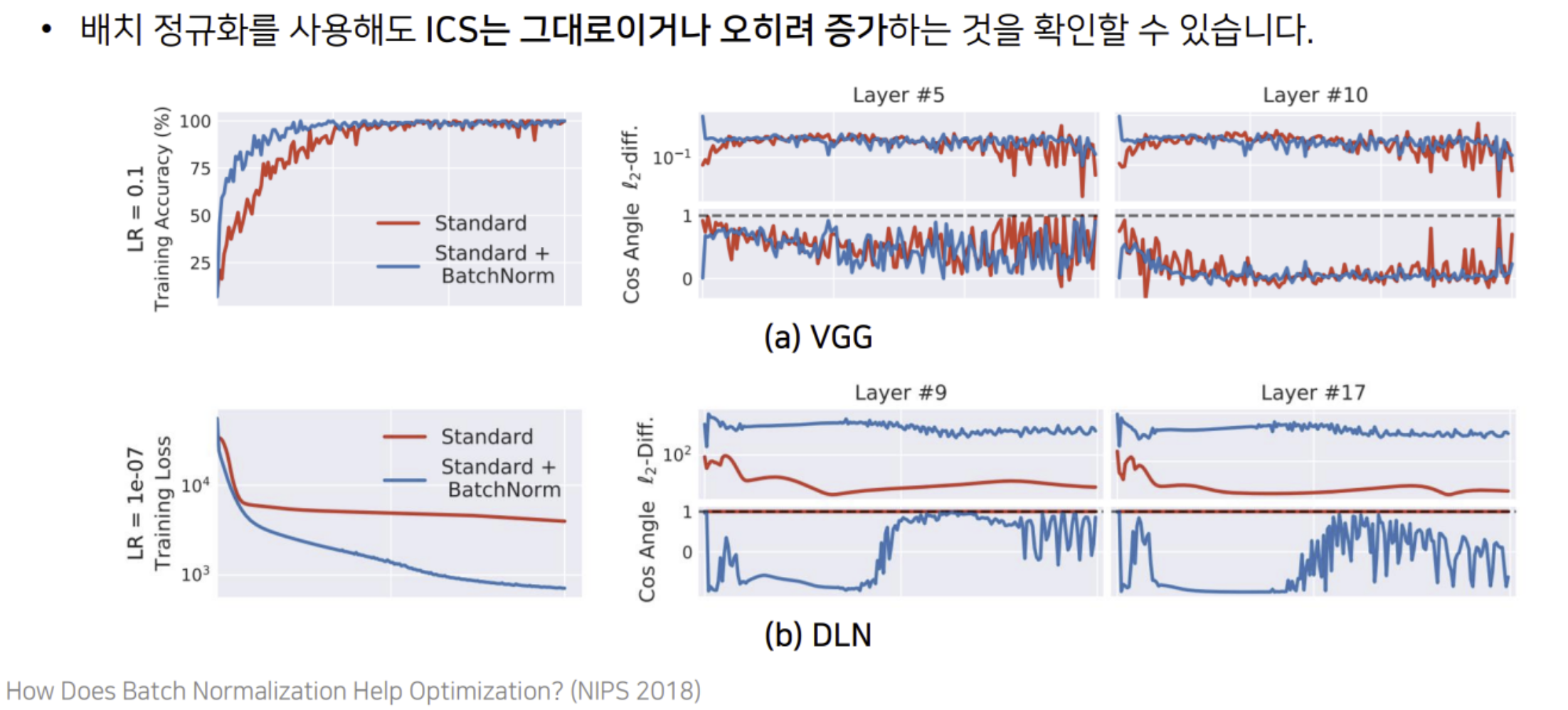
배치 정규화와 ICS와의 관계
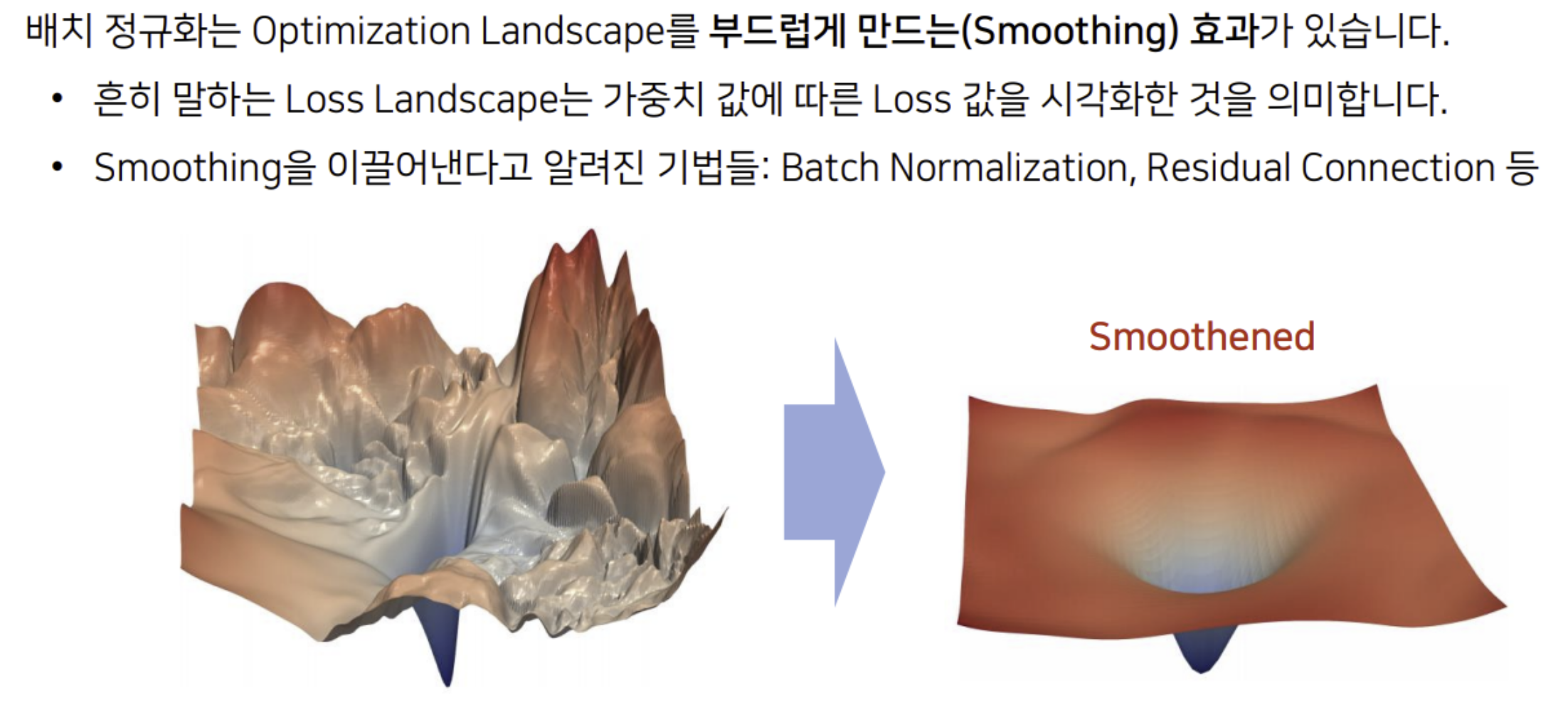
배치 정규화의 Smoothing 효과
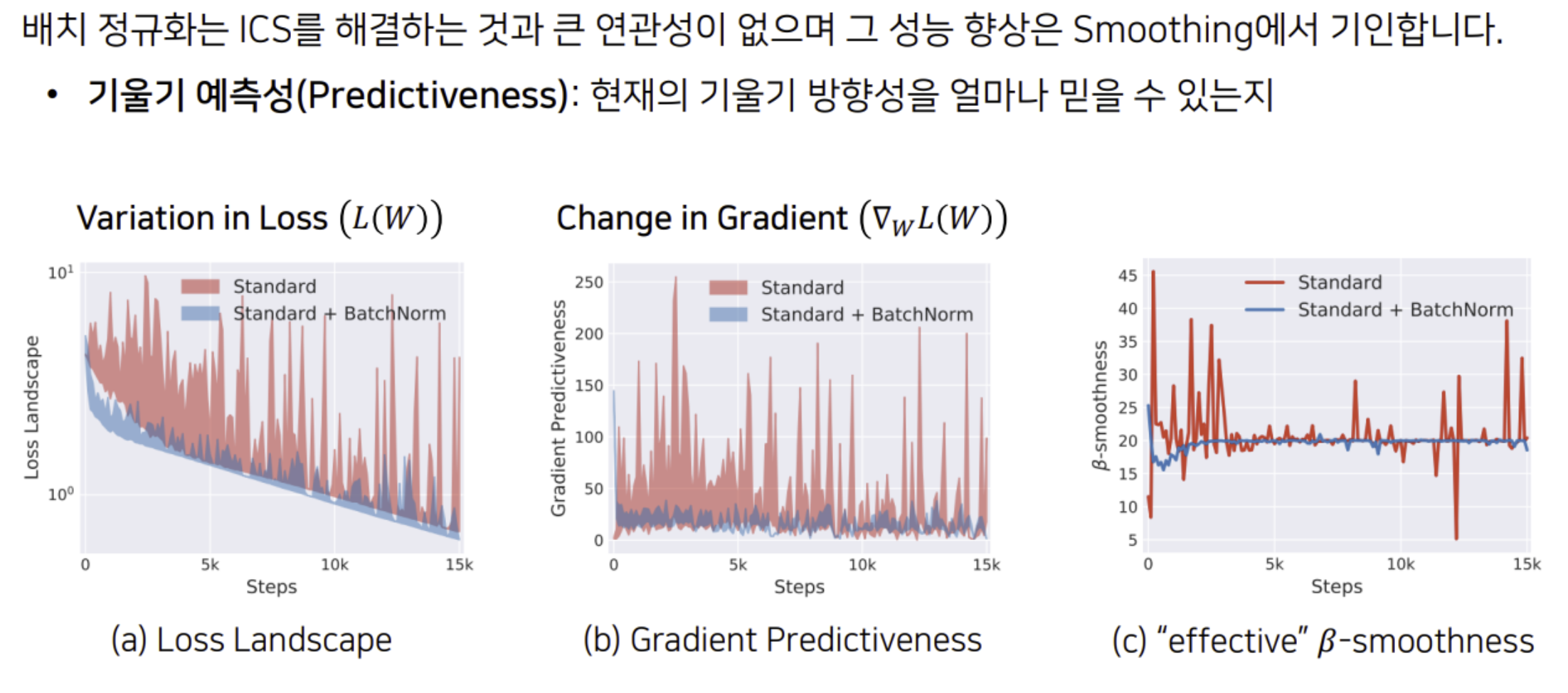
배치 정규화의 Smoothing 효과
스스로 결론
논문과 다른 자료를 가지고 잘 공부할 수 있었다.
논문의 의견과는 다르게 아쉽게도 BN이 ICS를 감소시키는 것이 아님이 밝혀졌지만 그럼에도 CNN 안에서 장점이 충분히 있기 때문에 BN을 잘 익히는 것이 중요하므로 보람있었다.
