paper_review
1.논문분석: Attention is all you need

오늘은 면접대비 겸 예전부터 분석해 보고 싶은 NLP 관련 가장 유명한 논문인 Attention is all you need를 분석해보겠다.Abstract:Encoder/Decoder 기반의 Attention mechanisms으로 된 Transformer을 소개한다.
2.논문분석: Big Bird: Transformers for Longer Sequences

최근 구름IDE에서 딥러닝으로 MRC를 제작하는 프로젝트를 진행했고 Long-sequence 처리가 핵심 문제임을 파악했다. 이를 해결하기 위해 팀에서는 BigBird 모델을 활용했고 문제를 해결했다. Huggingface에서 제공해주는 라이브러리를 사용하면 BigBi
3.논문 리뷰: DEEP DOUBLE DESCENT: WHERE BIGGER MODELS AND MORE DATA HURT

요즘 내가 자소서에 자주 쓰고 있는 나의 목표인 크고 깊은 딥러닝 모델 구축의 근거가 되는 논문이다. 물론 논문을 자세히 살펴보지는 못했기 때문에 리뷰를 해보고자 한다.Abstract:최신 딥러닝 모델의 크기가 증가함에 따라 double_descent 현상을 보인다.
4.논문분석: Going deeper with convolutions

스터디날 발표하기로 한 논문이다. 사실 읽는거를 방금 끝내서 촉박하지만 그래도 제시간에 나름 읽긴 했으니깐ㅎ 그냥 넘어가고 읽은 것을 정리하고 다시 고민하고자 글을 쓴다배경은 2014년 Imagenet 대회이고 지금 분석하는 논문의 모델은 Googlenet으로 당시 V
5.논문분석: Deep Residual Learning for Image Recognition

저번 스터디때 팀원이 조사해왔던 논문을 분석해보았다. Abstract Imagenet 2015에서 우승을 한 model이다. 오차율 3.57%로 인간의 오차율 보다 적어서 ImageClassification문제는 AI가 정복했다고 봐도 과언이 아니다. Deep-Neu
6.논문 분석: AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE

Transformer는 NLP의 꽃이다. 나는 BERT나 ELECTRA, BigBird를 사용하면서 여러 NLP Task들을 수행했고 이들은 모두 Transformer 기반이다. NLP와 Vison은 철저하게 분리되어있다고 생각했는데 결과적으로 AI의 기본 원리 안에서
7.논문분석: Playing Atari with Deep Reinforcement Learning

요즘 아주 Hot한 강화학습을 리뷰하기 위해 가장 기본이 되는 논문을 읽어보았다.강화학습을 사용해 학습하는 최초의 모델 제시.Q-Learning의 변형으로 만든 convolutional neural network Input은 Pixel이지만 output은 미래의 rew
8.논문 분석: Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning

오늘은 스터디원이 발표 예정인 논문을 직접 읽어보려고 한다. 기본적으로 알고가야할 부분인거 같다. uncertainty의 유형 Out of distribution test data 한번도 학습할 때 사용하지 못한 유형의 데이터가 테스트 시 사용되는 경우 Ex) 여러
9.논문 분석: Generative Adversarial Nets

그저께 스터디에서 스터디원이 GAN논문을 발표했다. GAN의 대략적 내용은 알지만 Unsupervised Learning 이라는 점에서 굉장히 특별하고 유용하기 때문에 그 내용을 자세히 들여다 보고자 나도 논문을 읽어보았다.adversarial process -> si
10.논문 분석: Denoising Diffusion Probabilistic Models

스터디원이 DDPM을 발표했다. 그래서 나도 이 논문을 읽어보고 정리해 보고자 한다.latent variable models인 Diffusion Probabilistic model을 사용한다고 한다.CIFAR10을 사용해서 이미지 생성을 했으며 ProgressiveGA
11.논문분석: Batch Normalization : Accelerating Deep Network Training by Reducing Internal Covariate Shift

스터디원의 발표였던 Batch Normalization 논문을 스티디원 발표의 순서에 따라 정리해보겠다.학습 속도 개선 -> 큰 learning rate 사용 가능가중치 초기화에 대한 민감도 개선Regularization(일반화) 효과When the input dist
12.논문분석: LIFELONG LEARNING WITH DYNAMICALLY EXPANDABLE NETWORKS

Transfer Learning을 RL을 보다 우연히 발견했는데 처음에는 progressive learning을 조사하려다 국내에서 DEN이라는 굉장히 놀라운 논문이 있다고 해서 궁금함에 조사하게 되었다.이 논문은 LIFELONG LEARNING을 위한 Dynamica
13.논문 분석: Language Models are Few-Shot Learners

저번 스터디때 DALL-E 모델 설명을 들었었는데 VAE 개념이나 GPT-3 개념이 제대로 없어서 이해하는게 쉽지 않았다. 그래서 이번 기회에 GPT-3를 확실히 배우고 DALL-E 같은 복합적 모델을 이해해보고자 한다. Background language model
14.논문분석 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows

요즘 ViT를 활용한 Image Classification을 하고 있는데 ViT의 발전된 형태가 Swin이며 SOTA 모델임을 들었다. 그래서 논문을 통해 Swin Transformer을 잘 이해해보고 싶어서 공부하게 되었다. Abstract 이 논문은 Swin T
15.논문 분석: Learning Transferable Visual Models From Natural Language Supervision

CoCa논문을 읽으며 알게된 사실이 주요 기술이 CLIP이나 SimVLM을 모방했다는 것이다. 그래서 CLIP을 우선적으로 공부 후 찾아봐야겠다 결정하고 CLIP 논문을 분석했다.computer vision의 SOTA는 predetermined object catego
16.논문분석: CoCa: Contrastive Captioners are Image-Text Foundation Models

Abstract large-scale pretrained foundation models은 빠르게 down- stream tasks로 바꿀 수 있어서 vision에서 인기가 많다. 이 논문은 Contrastive Captioner (CoCa) 를 소개한다. cont
17.You Only Look Once: Unified, Real-Time Object Detection

abstract 이 논문은 new approach to object detection인 YOLO를 제시한다. 이전 object detection은 detection에서 classifiers을 수행한다. 하지만 YOLO는 spatially separated boundi
18.Is Space-Time Attention All You Need for Video Understanding?

최근 자동차 충돌 대회에서 huggingface의 timesformer을 사용해보았다. 실제 핵심 기술을 자세히 알고자 위 논문을 리뷰해보았다. Abstract video classification에 self-attention에만 기반한 conv연산이 없는 접근방식
19.Long Text Generation via Adversarial Training with Leaked Information

일관성있고 의미있는 text를 자동으로 생성하는 기계번역, 대화 시스템, Image-caption 등에서 많은 응용분야를 가지고 있다. Reinforcement learning policy로써 generative model은 text생성에서 유망한 결과를 보여줬지만 s
20.Swin Transformer V2: Scaling Up Capacity and Resolution

large-scale NLP 모델은 signs of saturation없이 language 작업의 성능을 현저하게 향상시켰고 few-shot capabilities의 인간의 성능을 보인다. 이 논문은 CV에서 large-scale models을 탐구하는 것을 목표로 한
21.End-to-End Object Detection with Transformers
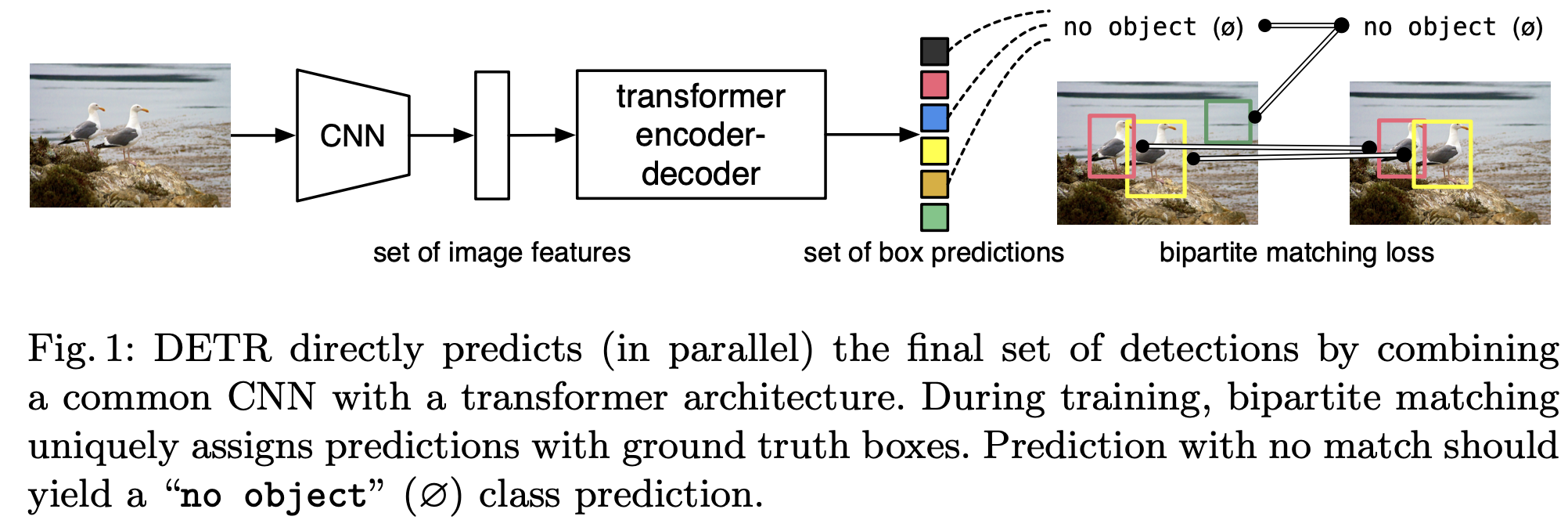
이 논문은 object detection을 direct set prediction problem으로 보는 새로운 방법을 제시한다. 위 접근 방식은 detection pipeline을 간소화하고자 hand-designed components(non-maximum supp
22.Emerging Properties in Self-Supervised Vision Transformers

이 논문에서는 self-supervised learning이 CNN에 비해 ViT에 새로운 속성을 제공하는지 질문한다. self-supervised learning을 이 architecture에 적용하는 것이 잘 잘동하는 것 외에 다음과 같은 관찰을 한다.1\. sel