
이번 주 월요일 성공적인 스터디를 마쳤고 CS231n 수업에 더욱 만전을 가하기로 다짐했다ㅎ
저번 주 수업시간 때 KNN을 다뤘다. 그것의 요약을 해보자면...
KNN은 Supervised Learning이며 Lazy-Learning을 추구한다. 즉 training은 빠르지만 predict가 오래걸리면 이유는 training 방법이 모든 초평면(각 축은 freature들이다.) 상에서 점을 찍는 방법으로 단순 저장이라 O(n)만큼 소요된다. 하지만 predict는 K의 개수에 따라 이웃한 값들의 target값들을 활용해 predict값을 얻어야 함으로 한번 predict시 O(n)만큼 소요된다.
단점으로 많은 데이터를 기억해야 하니 메모리 공간 과점에서 비효율적이고 모든 이미지를 다 비교해야하니 매우 계산량이 많이 필요하다.
실제 저번시간 실습 시 CIFAR-10데이터로 약 0.2의 정확도를 보임에도 시간적으로도 너무 느린 알고리즘이었다.
다음은 Linear regression이다. 초평면 상에서를 전제로 하며 이미지의 경우 CIFAR-10을 예시로 32X32X3(가로 세로 32 pixel에 RGB channel 3)이므로 3072차원의 공간에서 각 이미지가 존재한다.그리고 이를 분류할 classifer로 선형 방정식을 사용하는 concept이다.
y = Wx+b
다음 수식을 기본으로 생각할 때 W의 역할은 classifier의 회전이며 b의 역할은 평행이동이다. 그래서 bias는 필요하다.
모든 값들은 행렬 형태로 저장되어 dot연산을 한다. W와 xi는 dot연산 후 b와 scalar add연산을 한 후 나온 값으로 Loss를 구한다.
Loss를 구해야 그 Loss를 사용해 Optimizer step을 진행하게 되며 W 업데이트가 가능하다.
Lecture 3 의 시작은 Support Vector Machine의 소개로 시작한다.
SVM 알고리즘이 존재한다고 생각했는데 여기서는 Linear regression 알고리즘의 Loss function으로 소개한다. 물론 거기서 거기인것 같다...
기본적인 concept는 초평면 상에서 classifier들이 존재하며 이를 Decision boundary라고 하자. Decision boundary 와 인접한 data point를 Suport Vectors라고 하며 Support Vectors와 Decision boundary 간의 거리를 Margin이라고 한다.
결국 SVM은 허용 가능한 오루 범위 내에서 최대의 Margin으로 만들어 내는 방향으로 학습된다.
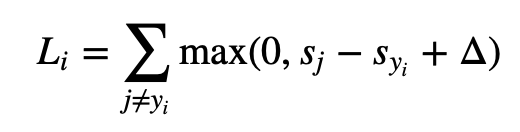
다음은 SVM의 수식이다. Loss를 계산하는 방법으로 target이 아닌 각 class에 대한 score 값인 sj에서 target에 대한 score 값인 sy를 뺀다. stanford univ에서 제공한 수식에서는 1을 더하는데 이는 safty margin: decision rule 이 1보다는 큰 값을 주기 위한 것으로 보인다. 다른 글에서는 safty margin 값으로 10을 주는 자료들도 있다.
결국 이 계산한 값이 0 보다 크면 Loss로 간주되며 없데이트 되고 0보다 작은 경우 Loss가 없는, 즉 target을 맞춘 것으로 간주된다.
Lecture 3는 SVM에 이어 Loss function을 더 설명하지 않고 Regularization에 대해 설명한다.
W는 unique할 수 없다. 특히 traning set에 unique할 시 오히려 새로운 데이터를 더 잘 측 못할 가능성이 크다. 그것을 overfitting이라고 하며 Regularization은 이를 방지해준다.
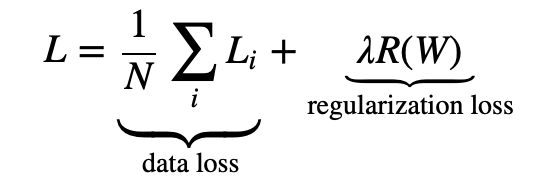
식은 다음과 같다. loss function 뒤에 regularization 값을 더해주면 된다.
람다는 regularization penalty에 해당하며 이를 tuning하는 방법은 특별히 없으며 cross-validation 방식으로 결정하곤 한다고 한다.
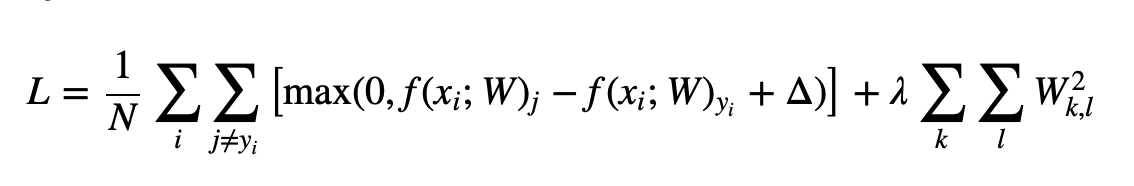
이제 위 식에 Loss function을 svm으로, Regularization을 L2-norm으로 설정한다고 할 시 식은 다음과 같같다.
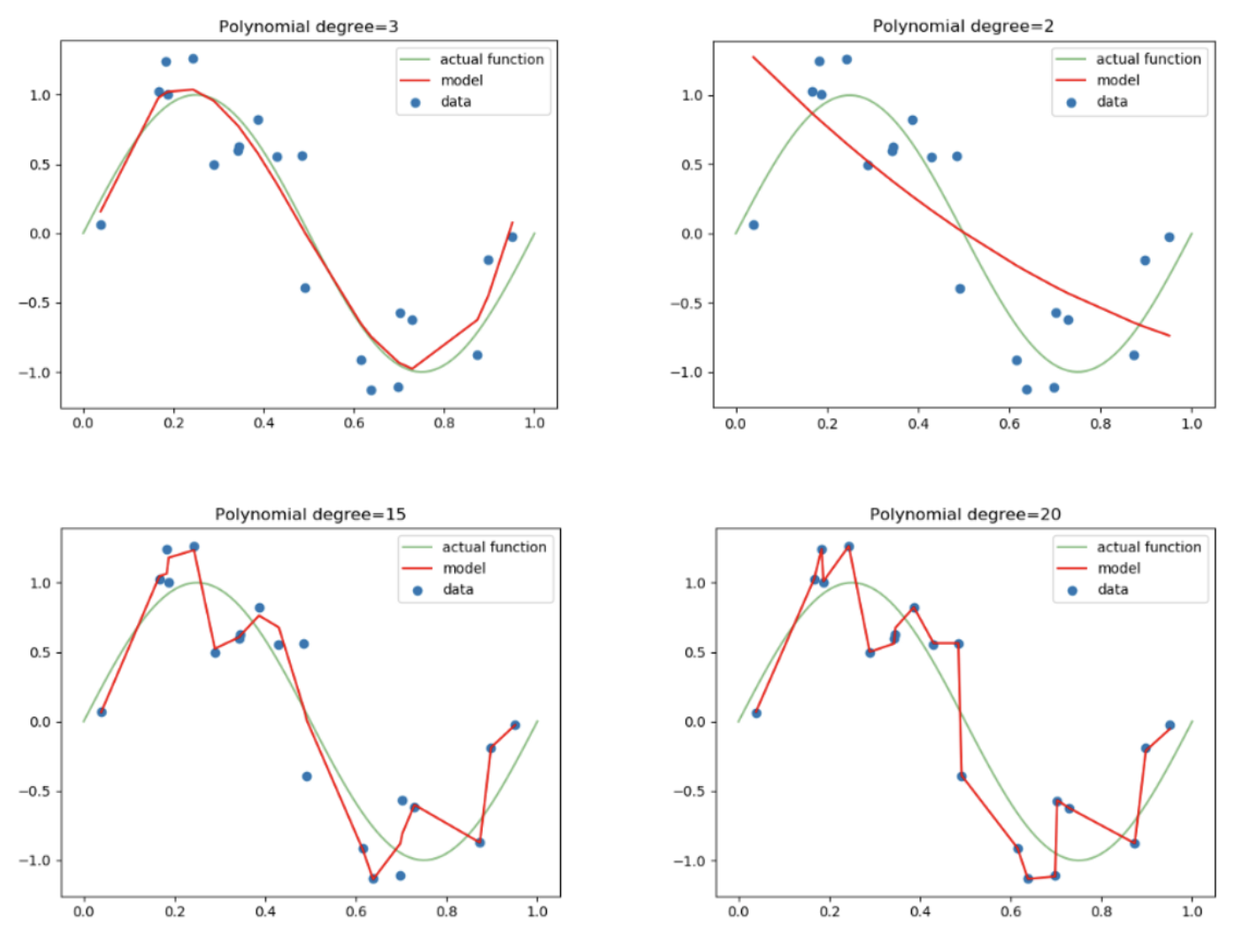
위와 같이 polynomial degree가 15인 경우 또는 20인 경우는 너무 training data set에 최적화 된 overfitting 된 모델의 모습이라고 할 수 있다.
weight decay는 특정 모델에 가중치에 penalty 항목을 집어넣어 과적합을 방지하는 방법으로 가장 대표적으로 위에서 배운 L2 Regularization이 있다.
이론은 이론이고 CS231n과제를 시도해 봤다...
colab 기반 코드가 있고 채워넣는 곳이 있는데 솔직히 전혀 모르겠어서 다른 분들 블로그를 참고해 답을 보았다.
데이터셋은 CIFAR-10을 사용하고 첫번째 과제는 SVM이다.
Loss를 구하는 것까지는 되어있는데 dw의 값을 정의하는 코드를 직접 작성하라고 되어있다.
또한 naive버전과 vectorized 버전 2가지 함수를 작성해야하는데 그 차이도 잘 모르겠다.
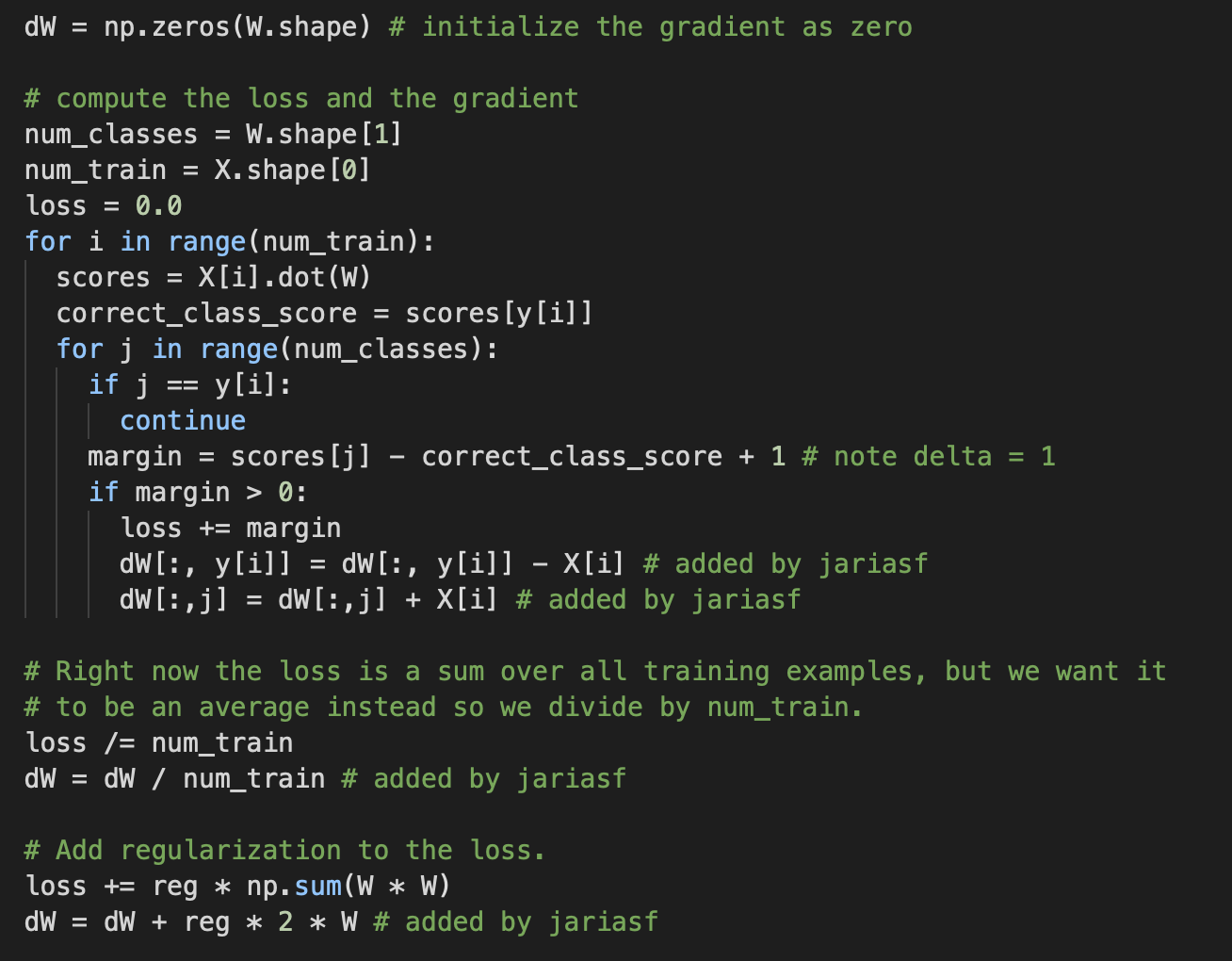
참고 코드를 한번 이해해보자면....
score는 데이터와 가중치를 dot연산을 수행한다.
margin은 다른 class score - correct_class_score + 1 이다.
margin이 0보다 클 때... 이게 max함수를 적용하는것과 같은 상황인거 같다.
loss += margin을 해준다.
dw를 계산하는 부분은 솔직히 어려운데....
for 문 안에서는 margin을 모두 sum하는것 처럼 보이고 나중에 나와서 data 수로 나눠주는 모습으로 보인다.
그리고 L2 regularization을 계산해준다.
과제 자체가 평상시 pytorch에서 제공해주는 함수만 사용하다 보니 직접 구현하라는 입장에서 정말 난처했다.
Linear classification도 직접 구현해야지 코드가 끝까지 돌아가는데.... 전혀 감도 안온다...
지금 이 글을 임시 글로 남겼다가 다시 작성하는 시점에서도 다시 이론을 충분히 공부 후 과제를 수행해야된다는 생각이 절실히 든다.
다음은 SoftMax이다.
보통 Multy-classify를 할 때 사용하는 것으로 알고 있으며 exponential 분수 형태로 나타내는것이 기억난다.
결과적으로 이 또한 Lossfunction이며 SVM과 비교 대상이다.

위의 예시대로 exp 계산 후 Normalize한다.
car부분이 굉장히 강조가 된다.
여기서 의문은 frog부분이 0에 가까워지지만 0이 되지는 않을텐데 굉장이 0인 것 처럼 보인다.
그다음은 Optimizer을 가르쳐준다.
current w에서 dw를 구하는 것을 얘기해준다.
실제로 위의 실습에서 dw를 구하라고 제시해줬고 애를 먹었다ㅎ

Numerical은 느리지만 코드작성이 쉽고 Analytic은 빠르지만 에러가 나기 쉽다.
제시한 gradient check는 analytic으로 계산 후 numerical 로 에러 검사하는 방식이다.
Loss function,weight,data를 통해 gradient를 구하고 gradient에 stepsize(Learningrate)를 구해서 Global optima를 향해 전진한다.
이렇게 최적화 해주는 것이 gradient descent
정말 유명한 Stochastic gradient descent이 있는데 이는 미니배치를 활용해 training set 일부만 사용해서 gradient 계산해 parameter을 업데이트한다.
내가 알기로는 가장 좋은 것은 Adam인데 나중에 optimizer을 다시 한번 찾고 공부해봐야겠다.
