
Lecture3를 하면서 과제가 굉장히 어려웠다...
이론까지는 ok인데 이론을 구현하는 과제는 참 뇌정지를 일으키는 것 같다.
Lecture4 수업을 들었고 이 글을 작성하며 최선을 다해 복습과 공부를 해보겠다.
Back propagation
역전파이다. Forward 계산 이후로 Back prop으로 chain rule에 의거해 weight를 조정하는 작업이다.
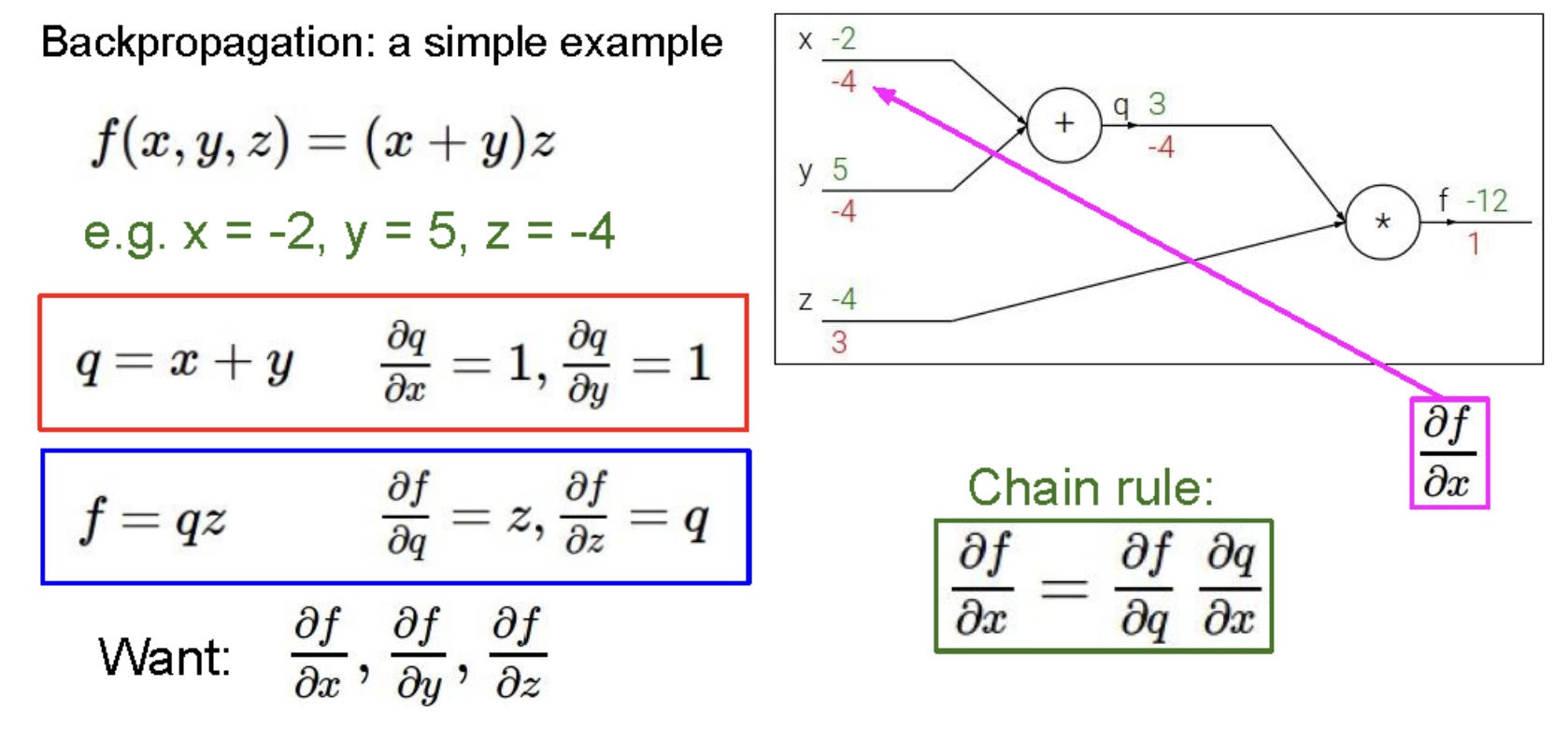
그림에서 보다시피 초록색 숫자는 순전파의 결과이다. Back propagation은 무조건 1로 시작하며 처음에 f = qz이고 q에는 q를 미분한 -4가(z는 -4이기 때문에 q를 편미분 시 -4가 된다) 아래 z에는 qz를 z로 미분한 3이 역전파 된다.
q = x+y인데 x로 편미분시 1, y로 편미분시 1이며 결국 각각 -4로 역전파 된다.
y와 x 가 q 에 미치는 영향은 값이 1이다. 그래서 1xq의 값(-4)를 하면 -4 가 된다.
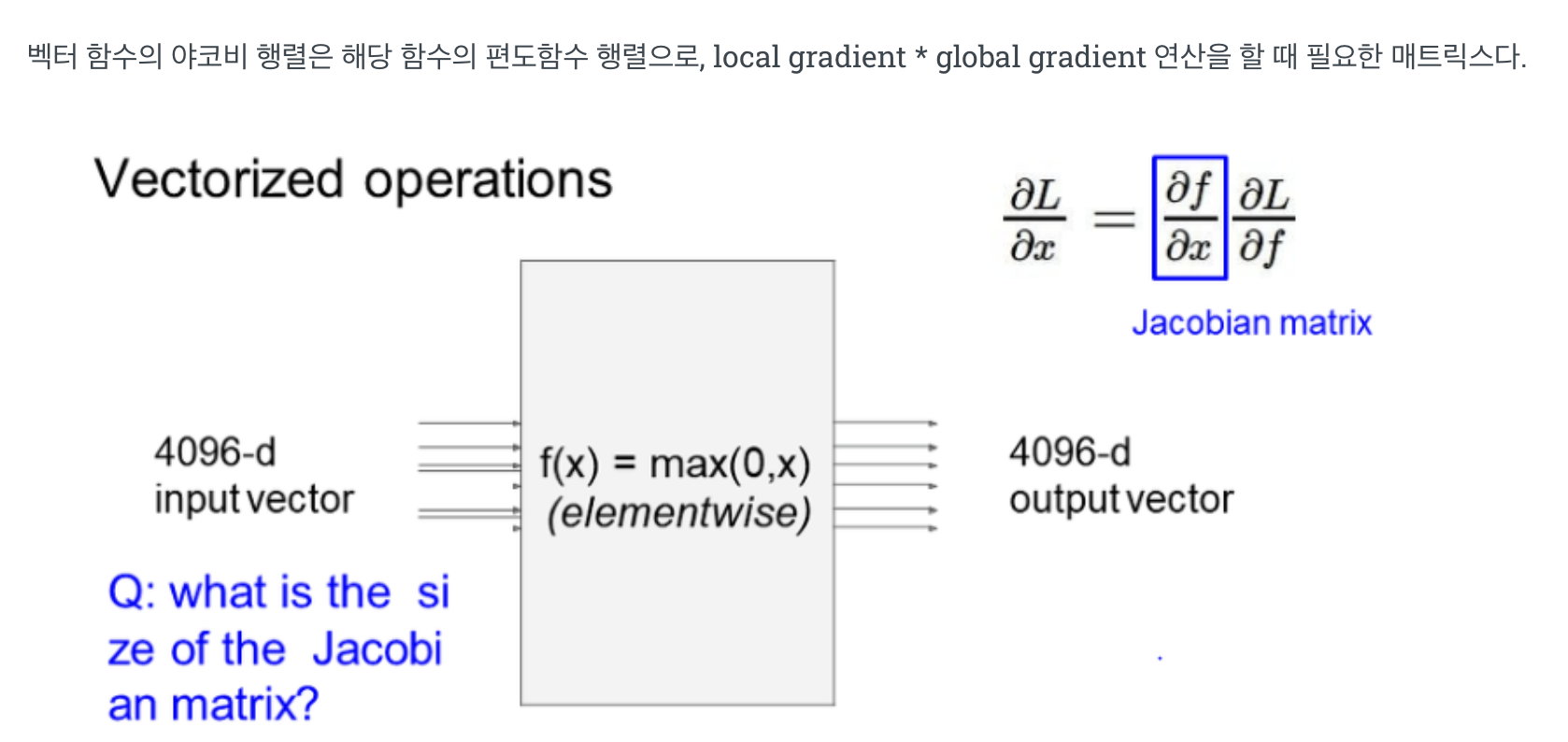
Jacobian matrix크기는 4096 * 4096 으로 주어지면 minibatch 를 이용해 연산 시, 실용적이지 못하다. 따라서 연산하지 않고, 출력에 대한 x영향을 구할 때 max 연산을 통해 일부는 0으로 채운다.

Multi-layer-perceptron의 모습을 보는 것 같다. 2-layer Neural Network고 hidden node를 적용함에 따라 더 많은 classification을 생성할 수 있다.
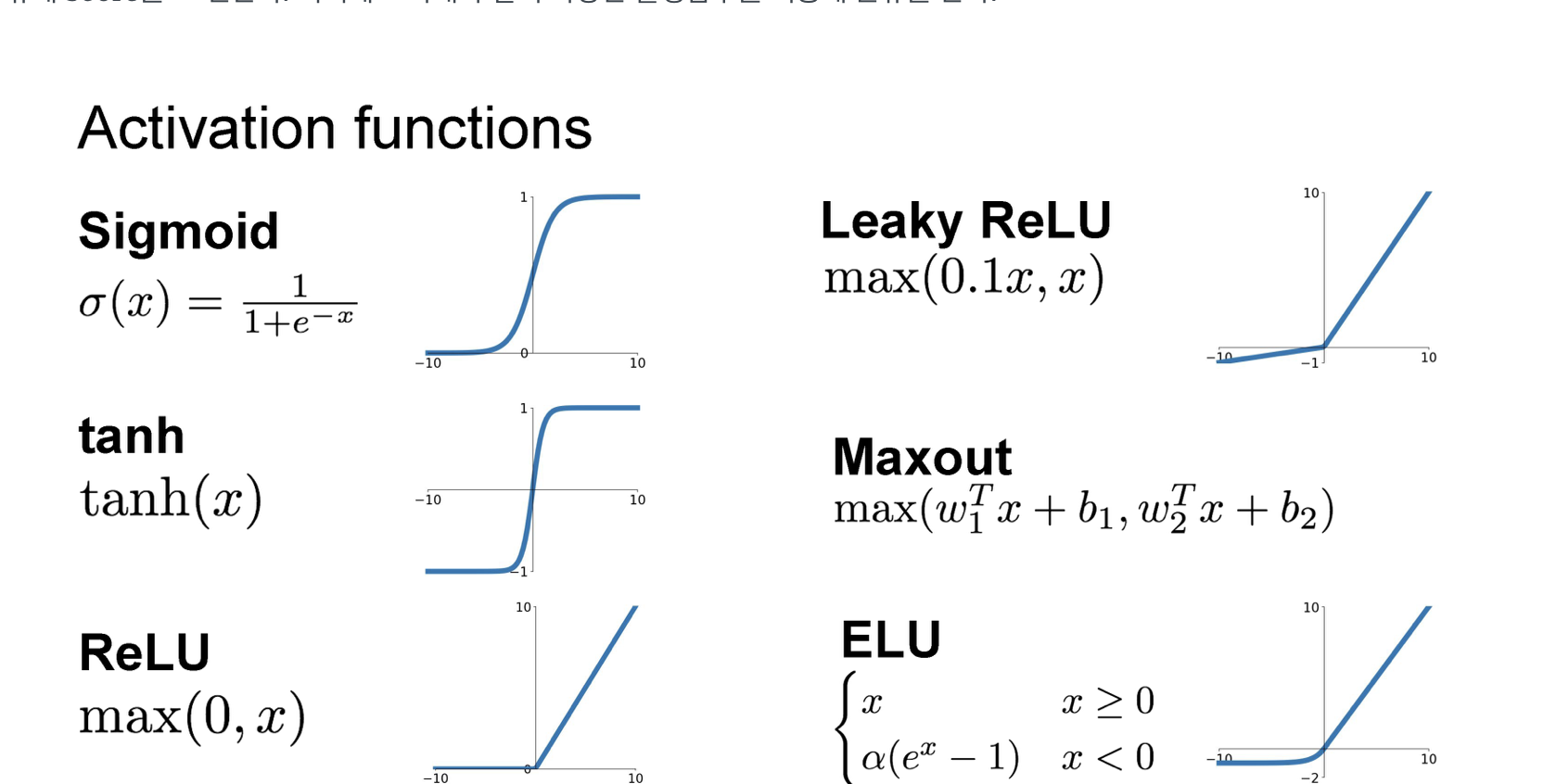
다양한 Activation Function을 보여준다. 4개는 알고 있다. 특히 non-linearity를 위해 ReLU를 많이 쓰고 있는 것으로 알고 있다.
솔직히 여기다가 과거 내가 정말 가고싶던 면접에서 나왔던 질문을 생각해볼때 ResNet관련으로 deep layer network에서 왜 vanishing gradient가 생기냐는 질문에 나는 LSTM의 핵심 아이디어를 최대한 떠올렸고 또는 ReLU 에서 음수 데이터 사라지는 그런 방향으로 얘기를 했다....
근데 별로 면접관이 탐탁치 않아했던거 같은데 솔직히 그 부분에서 참 슬펐다. 근데 인터넷을 뒤져도 그것에 대한 정확한 답을 알 수 는 없었다ㅠ
아무튼 나의 질문은 그럼 Leaky ReLU를 사용하는게 답이지 않나 이긴 한데 실제로 ReLU를 많이 사용하고 너무 보편화 되어 있어서 솔직히 궁금하긴 하다.
다음은 실습을 진행했다.
첫번째로 forward와 backward를 직접 작성하는 것이다.
x의 shpae가 달라서 처음부터 약간 해맸다ㅎㅎ
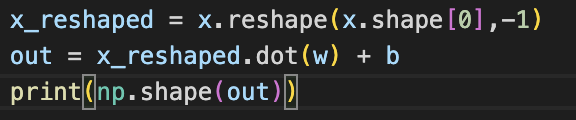
np.dot연산으로 계산을 했는데 답은 @를 사용했다.

backward는 다음과 같다.
중요한것은 x @ w = f일때 df/dx = f @ w.transpose 로 구현이 가능하다는 것이다.
이 부분을 잘 기억해야겠다.
dw는 순서가 다르다. 행렬은 곱셈의 순서가 중요하며 x @ w = x.T @ out 을 기억해야겠다.
다음은 ReLU 구현이다.

단순하다ㅎ
다음은 ReLU Backward이다.

강의에서도 max를 어떻게 backprop시키는지 알려줬는데 ReLU의 Backprop을 구하기 위해서구나 생각했다...
다음은 softmax_loss이다.
전에도 한번 구현해봤지만... 이 방법은 다른 분의 것을 참고했다ㅎ
솔직히 이해하기는 쫌 어렵다ㅋㅋ
저번이랑 달라진 거는 regurlization이 빠졌다. 그래도 expernation계산과 sum값으로 나눠주고 log 정규화는 모두 같다.

그리고 나서는 solve함수를 사용하는 것이다.
cs231n에서 solve를 만들어줬고 이것은 마치 pytorch의 model을 정의하는 것과 마찬가지다ㅎ
하이퍼파라미터를 넣고 .train을 하는 방식이다.
한참 에러뜨고 해맸던 부분은 regularization값을 정의해 줘야지만 돌아가는 것이었다ㅠ 아마 default값으로 0을 해놨는데 그 부분이 에러를 일으키는 건 아닐까 싶다ㅠ 그래도 이거때문에 너무 고생했다...
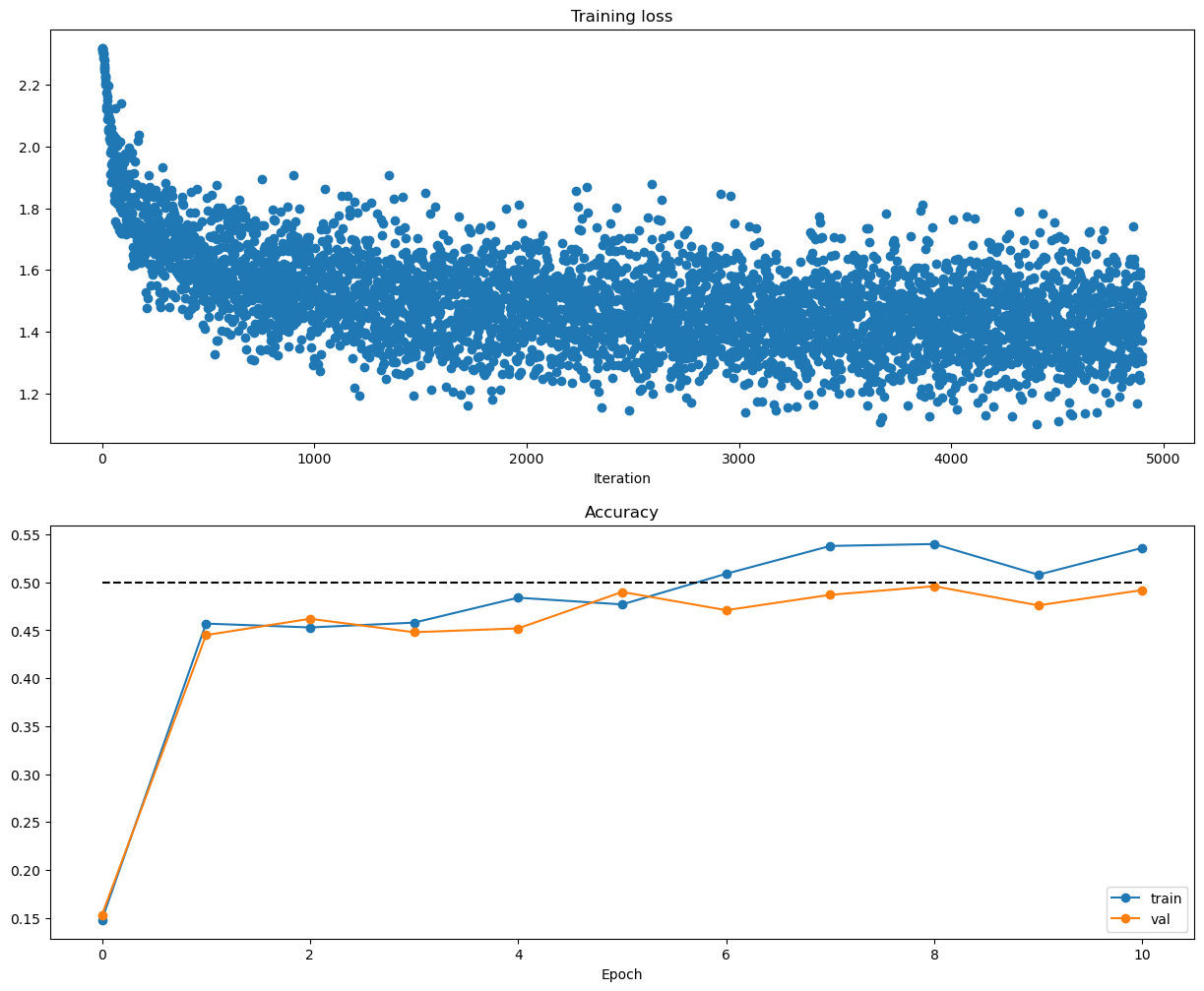
loss와 accuracy다.
validation값이 상승하는것으로 보아 test값도 좋을 것으로 예상할 수 있다.
물론 그게 0.5 구간이지만ㅎ CIFAR-10데이터로 학습했고 binarycase에 익숙해서 그런지 여러개 classification은 성능이 잘 안나온다ㅎ
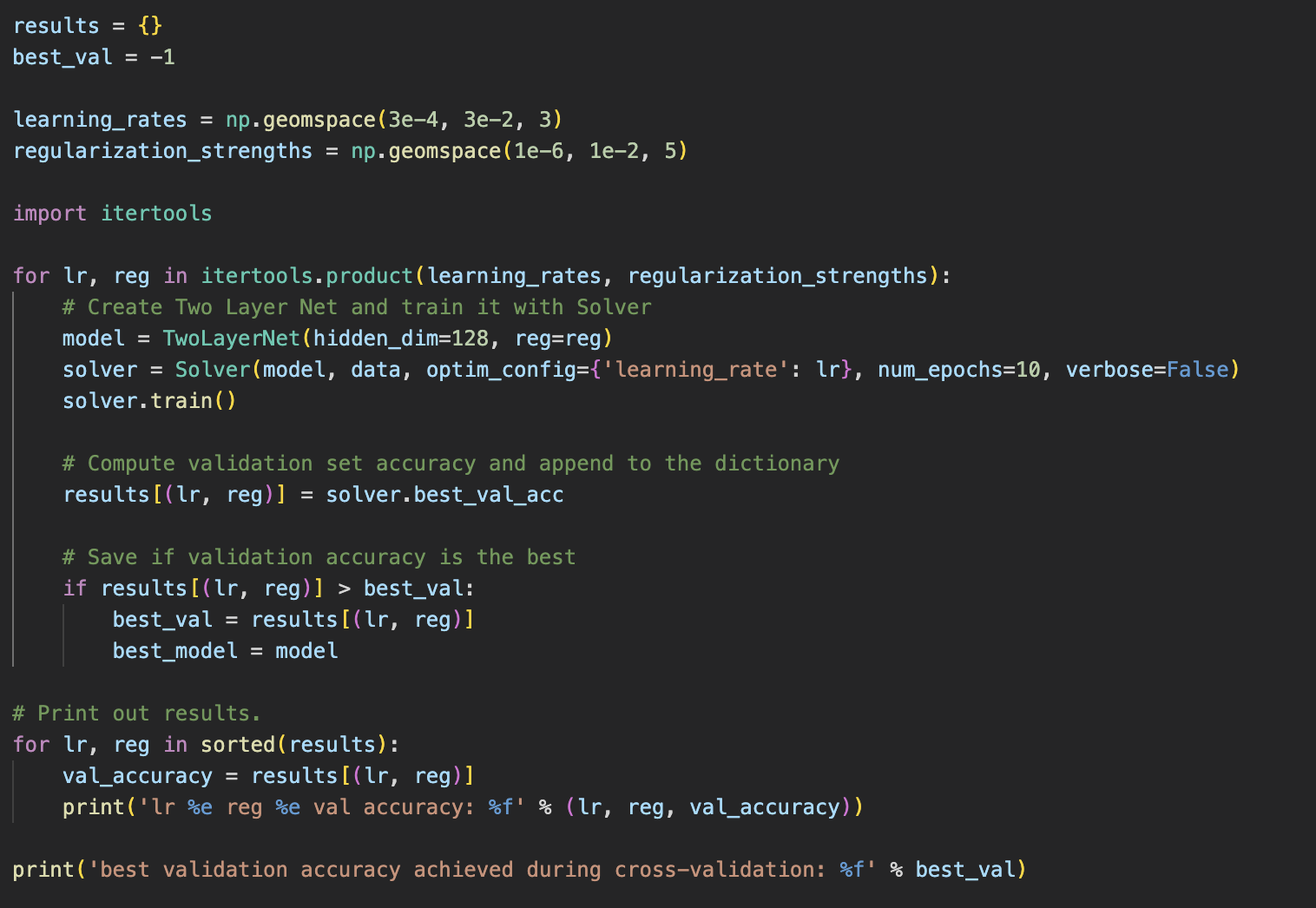
마지막은 Hyperparameter tuning이다.
itertools.product로 for문 grid_search를 안만들 수 있다.
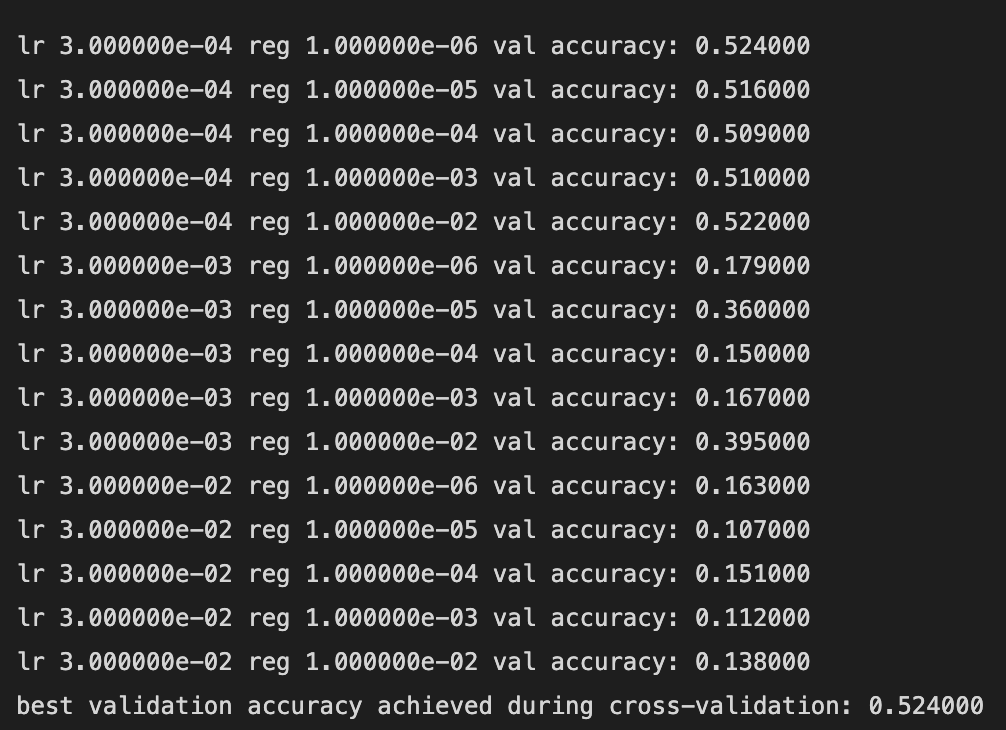
best모델의 accuracy는 0.524이다.
hyperparameter 값들은 모두 다른 사람들 것을 참조했고 더 좋은 값이 있을지 고민해봐야겠다...
best model을 사용한 test값은 0.513이고 knn으로 처음 시도할때 0.2에 머무른 거에 비해 많이 개선된 성능이었다ㅎ
CS231n의 과제부분에서 많이 배우는 것 같다. 평상시 pytorch 기능으로 사용한 부분들을 직접 구현한 다는 것은 굉장히 중요한 것 같다ㅎ
