
오늘은 면접대비 겸 예전부터 분석해 보고 싶은 NLP 관련 가장 유명한 논문인 Attention is all you need를 분석해보겠다.
Abstract:
Encoder/Decoder 기반의 Attention mechanisms으로 된 Transformer을 소개한다. 번역 관련 BLEU 스코어가 높다는거 같긴 한데 점수에 대한 감은 잘 안온다ㅎㅎ 꽤 시간이 된 논문이고 요즘의 pretrained 모델로 NMT를 수행하면 BLEU 스코어가 훨씬 높겠지?
Introduction:
recurrent model은 symbol positions of the input and output sequences를 계산한다. hidden states ht라는게 계산시 나타난다는데... LSTM을 얘기하는 건가 싶기는 하다. 중요한 핵심은 순차적인 특성이 훈련 때 병렬화를 배제하게 된다. 이 안에서 해결하기 보다는 필자는 Attention mechanisms는 input and output sequences 거리에 관계없기 때문에 제안한다고 주장한다.
훨씬 더 많은 병렬화를 허용해서 성능이 더 좋다는거 같다.
Background:
sequential computation을 줄이는 것에 대해 앞이랑 반복해서 강조로 나와있다. 아무래도 두 위치를 갖고 가는 계산 방법은 연산 양에서 많은 문제가 되긴 하나보다.
Model Architecture:
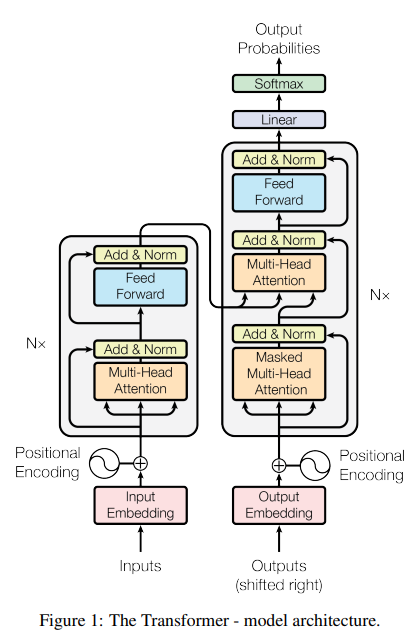
- Encoder:
N=6 layer stack -> layer : multi-head self-attention mechanism, feed-forward network. - Decoder:
N=6 layer stack -> Masked multi-head self-attention mechanism,multi-head self-attention mechanism, feed-forward network.
둘의 차이는 Masked multi-head self attention정도? 이름 엄청 길다ㅋ

Scaled Dot-Product Attention 이라고 내적과 softmax등 들어가는 attention 계산 수식이다. Q=matrix, K=keym V=value

multihead attention 수식인데 앞서 본 attention 수식을 concat한 형태인거 같다. 병렬수행과 병합이 포인트인 것 같다.
The Transformer uses multi-head attention in three different ways:
1. "encoder-decoder attention
2. The encoder contains self-attention layers
3. the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position.
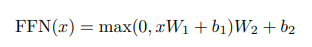
FFN은 보다시피 ReLU 함수가 들어가는 선형변환이다.보통의 CNN같은 곳의 FCL과 비슷한 역할로 보이기도 하다.
Why Self-Attention:
- total computational complexity per layer, the amount of computation that can
be parallelized -> 병렬화로 인한 연산량 감소가 중요한 포인트다. - the path length between long-range dependencies in the network.-> 앞서 말한 대로다.
Conclusion:
encoder-decoder architecture을 transformer로 교체하니 빠른 훈련, 좋은 성능!!
나의 결론:
Encoder-Decoder 기반의 seq2seq 기반이 나왔지만 transformer는 RNN을 다 빼버린 그리고 새로운 Encoder-Decoder의 self-attention 메커니즘이며 대강 굉장히 좋다... 이런 맥락인 것 같다. 미래에서 온 입장으로 엄청 좋은 아이디어고 앞으로의 Bert나 GPT-2의 세대의 아버지 격이긴 하니 배움의 의미는 큰 것 같다. 다만 layer의 자세한 설명은 생각보다 논문에 잘 기제되어있지는 않아서 아쉽기는 하다. 이 논문만 보고 transformer을 구현한다고 생각하면 그것대로 쉽지 않은 것 같다.
