
최근 구름IDE에서 딥러닝으로 MRC를 제작하는 프로젝트를 진행했고 Long-sequence 처리가 핵심 문제임을 파악했다. 이를 해결하기 위해 팀에서는 BigBird 모델을 활용했고 문제를 해결했다. Huggingface에서 제공해주는 라이브러리를 사용하면 BigBird 사용은 크게 문제는 아니지만 논문 분석을 통해 BigBird의 메커니즘이 왜 긴문장 처리에 적합한지 정확히 알아보고자 한다.
Abstract:
필자는 BERT의 약점으로 full attention mechanism을 뽑고있다. 메모리 문제가 발생한다고 한다. BigBird의 sparse attention mechanism을 필자는 제안했으며 이 논문의 가장 핵심 기술인 것 같다. 8배 길이의 sequence 처리가 가능하다고한다.
Introduction:
저번에 Attention is all you need에서 배웠던 파트가 재등장해서 반갑다. BERT는 Transforemer을 사용하며 이는 self-attention mechanism이 핵심이며 RNN의 Sequential Dependency는 제거하고 병렬 처리로 쉽게 학습할 수 있음이 적혀있다. BERT는 Transformers로 pretrained 된 모델로 NLP의 가장 핵심이다.
full self-attention은 sequence 길이 제곱 정보가 필요하며 일반적으로 512 tokens가 최대이다. 또한 적은수의 내적과 표현성과 유연성이 유지되는 장점을 가진다.
BigBird의 3 attention:

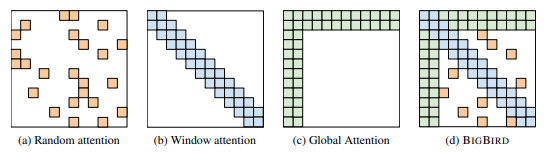
BigBird Architecture
i번째 token에 대한 generalized attention mechanism output vector
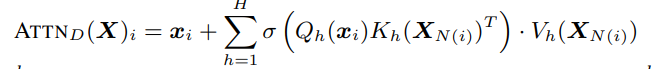

나의 결론:
솔직히 BigBird에 대해 면밀히 아는 것은 쫌 어렵다. 그래도 핵심은 graph Sparcification 이며 3 attention 으로 이루어져 Long-Sequence를 처리하기에 알맞다 까지는 이해했다. 그래도 확실히 난이도 있는 논문 리뷰이다.
