
🙄 선형 회귀
➡ 선형 회귀 (Linear Regression)란?
- 데이터를 가장 잘 대변해 주는 선을 찾아내는 것
- 이 선을 최적선 (
line of best fit)이라고 함
➡ 변수
목표 변수
- 맞추려도 하는 값, 아웃풋
- 영어로는
target variable,output variable
입력 변수
- 목표 변수를 맞추기 위해서 사용하는 값, 인풋
- 영어로는
input variable,feature
➡ 데이터 표현법
-
학습 데이터 : 프로그램을 학습시키기 위해 사용하는 데이터
-
학습 데이터의 개수를 보통 이라는 문자로 표현
ex) , 50개의 데이터를 갖고 프로그램을 학습시킴 -
입력 변수는 로 표현하고, 목표 변수는 로 표현
-
각 데이터들은 번호를 써서 표현
ex) 번째 데이터는 ,
🙄 가설 함수
➡ 가설 함수 (hypothesis function)
- 최적선을 찾아내기 위해 다양한 함수를 시도
- 시도하는 함수 하나하나를 가설 함수라고 함
➡ 가설 함수 표현법
-
목표 변수에 영향을 미치는 입력 변수는 여러 개
-
입력 변수가 너무 많아지면 식이 복잡해짐
ex) -
일관성 있게 하기 위해 가설 함수는 다음과 같이 표기
-
는 상수항이기 때문에 입력 변수가 없지만 통일성을 위해 다음과 같이 표기하기도 함
-
은 상수항이라고 생각하자
🙄 평균 제곱 오차 (MSE)
➡ 평균 제곱 오차 (mean squared error)
- 가설 함수가 얼마나 좋은지 평가하는 방법
- 데이터들과 가설 함수가 평균적으로 얼마나 떨어져 있는지 나타내기 위한 방식
- 함수 출력값과 실제 값의 오차를 제곱하고 모두 더한 뒤 으로 나눔
➡ 제곱을 하는 이유
- 오차를 양수로 통일하기 위함
- 오차가 커질수록 더 부각시키기 위함
➡ 평균 제곱 오차 일반화
- 평균 제곱 오차가 크면 : 가설 함수가 데이터에 잘 안 맞다
- 평균 제곱 오차가 작으면 : 가설 함수가 데이터에 잘 맞다
🙄 손실 함수
➡ 손실 함수 (Loss Function)
- 가설 함수의 성능을 평가하는 함수
- 손실 함수가 작으면 : 가설 함수가 데이터에 잘 맞다
- 손실 함수가 크면 : 가설 함수가 데이터에 잘 안 맞다
-
선형 회귀의 경우 평균 제곱 오차가 손실 함수의 아웃풋
-
-
으로 바뀐 것은 차후 설명, 이후 계산을 위한 장치
➡ input
- 손실 함수 의 인풋은
- 가설 함수 :
- 값을 조율해서 가장 적합한 가설 함수를 찾아내는 것
- 손실 함수의 아웃풋은 값들을 어떻게 설정하느냐에 달려 있음
- , 는 정해진 데이터를 대입하는 것이기 때문에 상수
🙄 경사 하강법
➡ 경사 하강법 (Gradient Descent)
- 손실 함수의 아웃풋을 최소화 하기 위해 변수 를 계속 업데이트 해나가는 최적화 전략
➡ 경사 하강법 계산
경사 하강법 일반화
-
손실 함수 를 에 대해 편미분해서 나온 결괏값에 를 곱하고 에서 뺀다
새로운 -
손실 함수 를 에 대해 편미분해서 나온 결괏값에 를 곱하고 에서 뺀다
새로운
손실 함수 에는 업데이트 된 이 아닌 기존의 을 대입한다
👉 계속해서 반복하다 보면 손실 함수의 극소점에 가깝게 갈 수 있음
경사 하강법 간단하게 표현하기
- 을 각각 , 에 대해 편미분을 하면 아래와 같음
- = 로 오차를 표현한다면 아래와 같이 표현 가능
선형 회귀 경사 하강법 구현
import numpy as np
def prediction(theta_0, theta_1, x):
"""주어진 학습 데이터 벡터 x에 대해서 모든 예측 값을 벡터로 리턴하는 함수"""
return theta_0 + theta_1 * x
def prediction_difference(theta_0, theta_1, x, y):
"""모든 예측 값들과 목표 변수들의 오차를 벡터로 리턴해주는 함수"""
return theta_0 + theta_1 * x - y
def gradient_descent(theta_0, theta_1, x, y, iterations, alpha):
"""주어진 theta_0, theta_1 변수들을 경사 하강를 하면서 업데이트 해주는 함수"""
for _ in range(iterations): # 정해진 번만큼 경사 하강을 한다
error = prediction_difference(theta_0, theta_1, x, y) # 예측값들과 입력 변수들의 오차를 계산
theta_0 = theta_0 - alpha * error.mean()
theta_1 = theta_1 - alpha * (error * x).mean()
return theta_0, theta_1
# 입력 변수(집 크기) 초기화 (모든 집 평수 데이터를 1/10 크기로 줄임)
house_size = np.array([0.9, 1.4, 2, 2.1, 2.6, 3.3, 3.35, 3.9, 4.4, 4.7, 5.2, 5.75, 6.7, 6.9])
# 목표 변수(집 가격) 초기화 (모든 집 값 데이터를 1/10 크기로 줄임)
house_price = np.array([0.3, 0.75, 0.45, 1.1, 1.45, 0.9, 1.8, 0.9, 1.5, 2.2, 1.75, 2.3, 2.49, 2.6])
# theta 값들 초기화 (아무 값이나 시작함)
theta_0 = 2.5
theta_1 = 0
# 학습률 0.1로 200번 경사 하강
theta_0, theta_1 = gradient_descent(theta_0, theta_1, house_size, house_price, 200, 0.1)
theta_0, theta_1
# (0.16821801417752186, 0.34380324023511988)선형 회귀 경사 하강법 시각화
cost_list: 경사 하강을 한 번 할 때마다 그 시점에서의 손실 저장- 오차를 모두 제곱하고 으로 나눠 손실을 계산
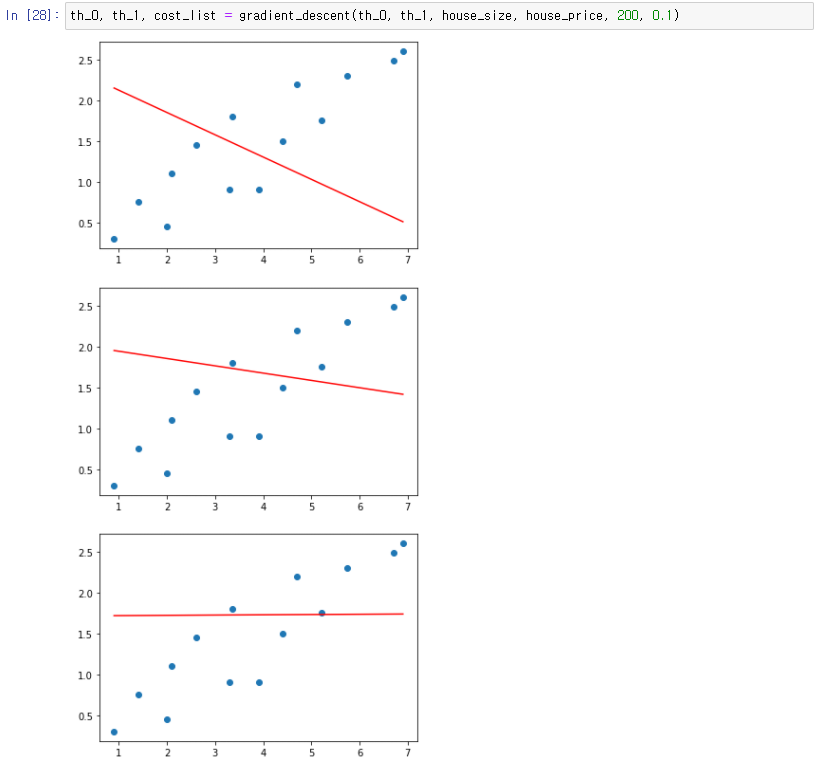
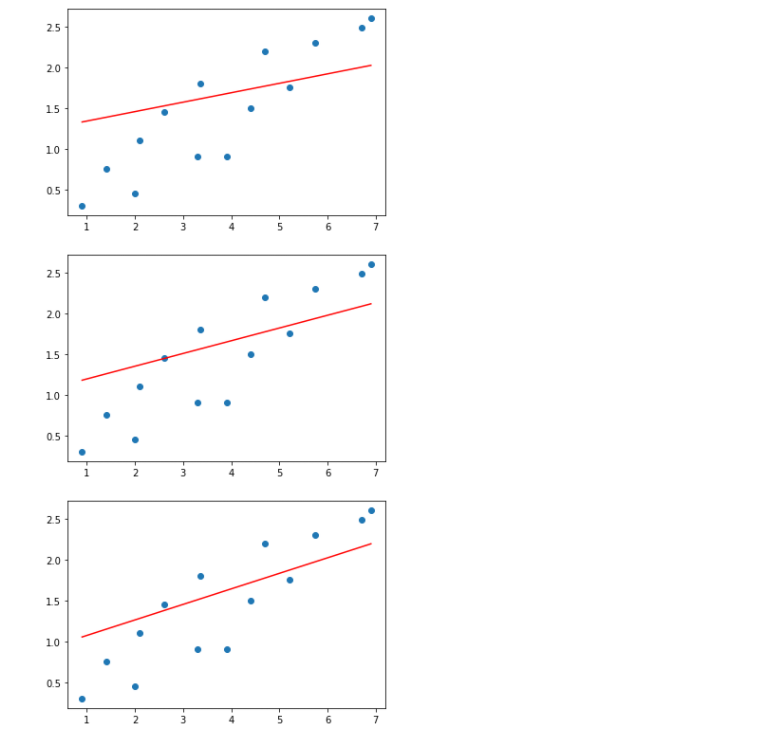
- 가설 함수가 개선되는 모습
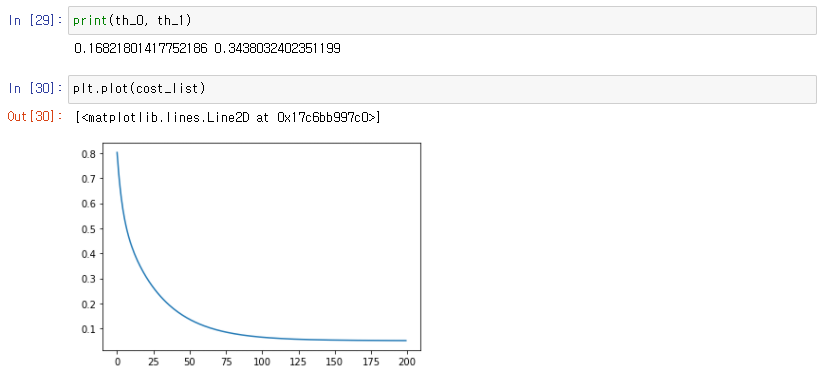
- 경사 하강을 반복할수록 손실이 줄어드는 것을 볼 수 있음
학습률
- 경사를 내려갈 때마다 얼마나 많이 그 방향으로 갈 건지를 결정하는 변수
- 학습률 가 너무 큰 경우 값이 크게 바뀌기 때문에 극소점을 넘어 점점 멀어질 수도 있다
- 학습률 가 너무 작은 경우 값이 작게 움직여 최소 지점을 찾는게 너무 오래 걸릴 수 있다
- 적절한 학습률은 상황과 문제에 따라 다름
- 일반적으로
0 ~ 1.0사이의 숫자로 정하고, 여러개를 실험해보면서 경사 하강을 제일 적게하면서 손실이 잘 줄어드는 학습률을 선택
🙄 모델 평가하기
➡ 모델의 평가
- 가설 함수는 세상에 일어나는 상황을 수학적으로 표현한다는 의미에서
모델이라고 부름 - 데이터를 이용해서 모델을 개선시키는 걸
모델을 학습시킨다라고 표현 - 모델을 학습시키고 나서는 이 모델이 얼마나 좋은지 평가해야 함
RMSE
- 평균 제곱근 오차, Root Mean Square Error
- 많이 쓰이는 평가 방식
- 학습시킨 모델, 최적선을 데이터랑 비교해서 평균 제곱근 오차를 구하는 것
- 그러나 데이터에 맞게끔 모델을 학습시켜 평균 제곱근 오차가 당연히 낮게 나옴
- 평가의 신빙성을 위해 데이터를 두 가지로 분리
- 예를 들어 일 때 다 학습시키기 위해 사용하는 게 아니라 24개만 학습시키고 6개는 평가할 때 사용
- 이 때 24개의 데이터를
training set, 6개의 데이터를test set이라고 함 - 6개 데이터의 평균 제곱근 오차를 계산해서 평가
🙄 scikit-learn으로 선형 회귀
# 필요한 라이브러리 import
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import pandas as pd
# 보스턴 집 데이터 갖고 오기
boston_house_dataset = datasets.load_boston()
# 입력 변수를 사용하기 편하게 pandas dataframe으로 변환
X = pd.DataFrame(boston_house_dataset.data, columns=boston_house_dataset.feature_names)
# 목표 변수를 사용하기 편하게 pandas dataframe으로 변환
y = pd.DataFrame(boston_house_dataset.target, columns=['MEDV'])
# 동네 범죄율 'CRIM'을 가지고 선형회귀 하기
X = X[['CRIM']]
# 데이터 셋을 학습용, 테스트용으로 분리
# test_size = 20%를 테스트 데이터로 배당
# random_state = 옵셔널 파라미터, 안넘기면 매번 다른 테스트 데이터 셋 구성
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=5)
# 배당된 학습 데이터들을 학습
model = LinearRegression()
model.fit(x_train, y_train)
# 학습된 model에 테스트 데이터를 이용해 y값 예측
y_test_predict = model.predict(x_test)
# 테스트 코드 (평균 제곱근 오차로 모델 성능 평가)
mse = mean_squared_error(y_test, y_test_predict)
mse ** 0.5
# 8.1806972283173476
# 8000달러의 오차 의미.png)
IWBAGDS