
🙄 데이터 전처리
➡ 데이터 전처리
- 데이터를 그대로 사용하지 않고, 가공해서 모델을 학습시키는데 좀 더 좋은 형식으로 만들어주는 것
🙄 Feature Scaling
➡ Feature Scaling
Feature: 입력 변수의 크기를
scale: 조정해 준다
- 머신 러닝 모델에 사용할 입력 변수들의 크기를 일정 범위 내로 조정
- 경사 하강법을 조금 더 빨리할 수 있다는 장점
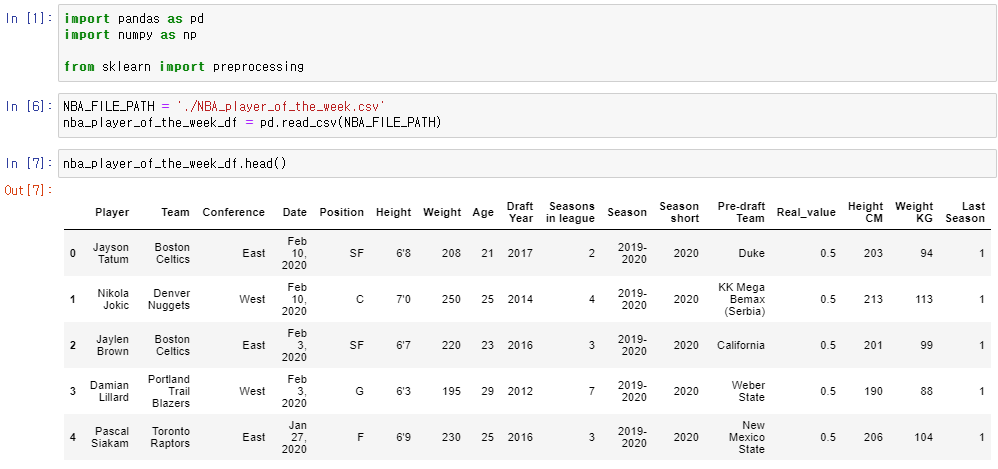
Feature Scaling을 하는 방법은 여러 가지- 가장 직관적인
Min-Max Normalization을 해보자
➡ Feature Scaling : 정규화, Min-Max Normalization
nomalization: 숫자의 크기를 0과 1사이로 만든다- 데이터의 최솟값, 최댓값을 이용해 데이터의 크기를 0과 1사이로 바꿔주는 방법
- 새로운 값은 원래 값에서 최솟값을 빼고 (최댓값최솟값)으로 나눠준다

➡ Feature Scaling과 경사 하강법
feature scaling을 하면 경사 하강법을 조금 더 빨리 할 수 있음- 경사 하강법은 어떤 지점에서 경사가 가장 가파른 방향으로 내려가는 것
- 2차원 등고선으로 보면 접선에 수직 방향이 경사가 가장 가파른 방향
- 데이터 전처리를 하지 않으면 타원 모양의 등고선
- 경사 하강을 하면 지그재그 모양으로 그래프를 내려가게 됨
가장 가파른 방향과 최소점을 향하는 방향 불일치
fearture scaling을 함으로써 경사가 가장 가파른 방향이 최소점으로 향하는 방향이 됨
경사 하강법을 사용하는 모든 알고리즘에 적용
다항 회귀, 로지스틱 회귀를 할 때도feature scaling을 해주면 모델을 더 빠르게 학습
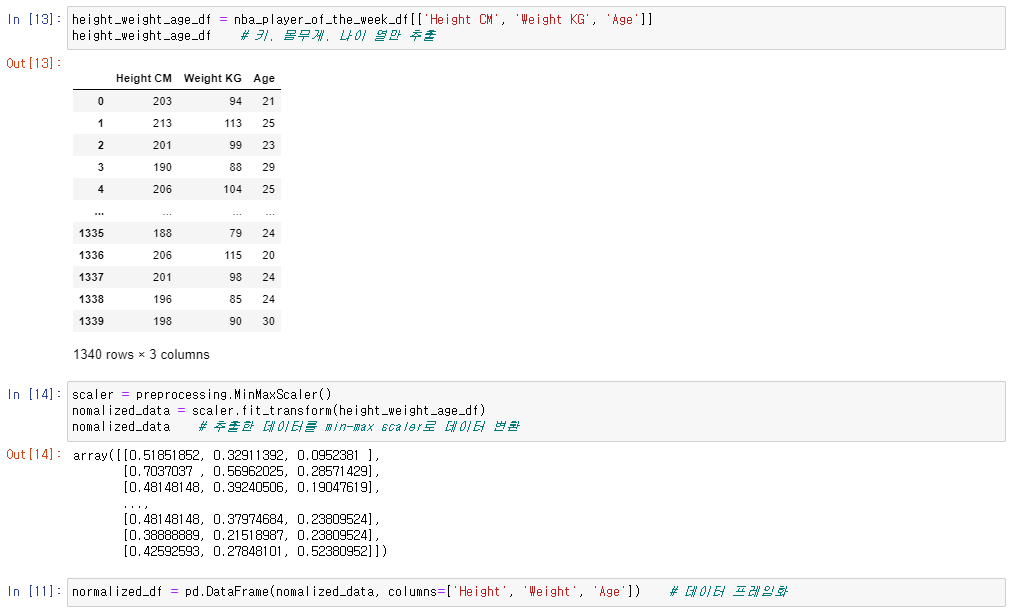
➡ Feature Scaling : 표준화
feature scaling을 하는 또 다른 방법
- 는 데이터의 평균, 는 데이터의 표준 편차
- 표준화를 하면 항상 새로운 데이터의 평균은 0, 표준 편차는 1
🙄 One-hot Encoding
- 머신 러닝에 사용되는 두 가지의 데이터 종류
1. 수치형(numerical) 데이터 : 나이, 몸무게, 키
2. 범주형(categorical) 데이터 : 혈액형, 성별
- 많은 머신 러닝 알고리즘은 입력 변수의 값이 수치형 데이터여야 함
- 그래야 손실 함수, 경사 하강법 등을 적용할 수 있음
- 범주형 데이터가 주어지면 자연수를 각 카테고리에 지정
ex) A형은 1, AB형은 2, B형은 3, O형은 4
하지만 이렇게 데이터를 바꿔주면 혈액형에 크고 작다는 개념이 생기고
머신 러닝 알고리즘은 이런 관계도 학습하기 때문에 예측에 방해
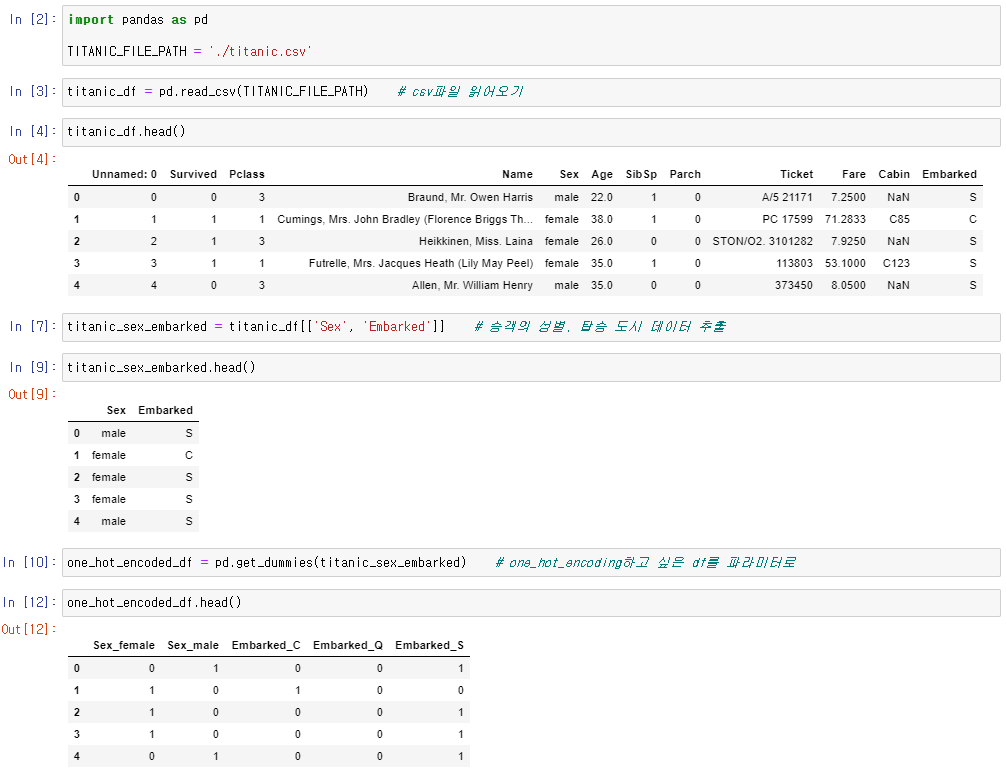
➡ One-hot Encoding
- 범주형 데이터일 때, 각 카테고리를 하나의 새로운 열로 만들어주는 방법
| 혈액형 | 나이 |
|---|---|
| A | 9 |
| AB | 40 |
| B | 35 |
| O | 20 |
| A | 70 |
| A형 | AB형 | B형 | O형 | 나이 |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 9 |
| 0 | 1 | 0 | 0 | 40 |
| 0 | 0 | 1 | 0 | 35 |
| 0 | 0 | 0 | 1 | 20 |
| 1 | 0 | 0 | 0 | 70 |
범주형 데이터에게 크고 작음의 엉뚱한 관계가 생기는 걸 방지하면서 수치형 데이터로 변환
.png)
IWBAGDS