
🙄 k겹 교차 검증
➡ k겹 교차 검증
- 기존
test set하나로만 모델을 평가하기엔 신뢰도가 떨어진다 - 딱
test set에서만 성능이 좋을 수 있고 반대로 안 좋게 나올 수도 있음 - 교차 검증은 이러한 문제를 해결해주는 방법
- 가장 흔히 쓰이는 것이 k-겹 교차 검증
-
먼저 전체 데이터를 k개의 같은 사이즈로 나눈다
ex)k=5, m=1000이라면 200개씩 5세트로 나눈다 -
한 세트를
test set, 나머지를training set으로 총 k번 성능을 평가한다 -
성능 k개의 평균을 모델 성능으로 본다
여러 번 다른 데이터로 검증하기 때문에 평가에 대한 신뢰도 상승
k는 데이터가 몇 개가 있느냐에 따라 다르겠지만 가장 일반적인 숫자는 5
데이터가 많을수록 우연히test set에서만 성능이 다르게 나올 확률이 적기 때문에 작은 k를 사용해도 무방
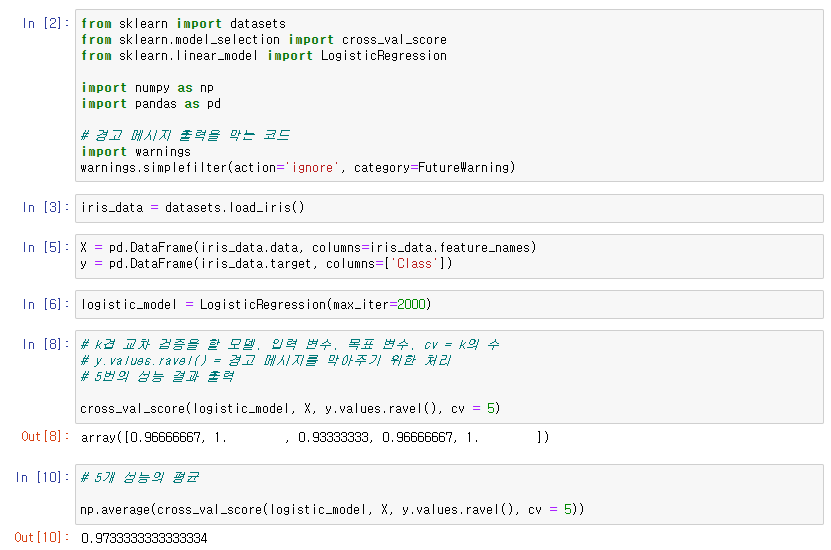
➡ scikit-learn으로 k겹 교차 검증
🙄 그리드 서치
➡ 하이퍼 파라미터
- 머신 러닝 모델을 학습시키기 전에 사람이 미리 정해줘야 하는 변수들
ex)Lasso모델의alpha,max_iter
scikit-learn에서 보통 모델을 만들 때 옵셔널 파라미터로 정해주는 변수들- 어떤 값을 넣으냐에 따라 모델 성능에 큰 차이가 있음
➡ 그리드 서치 (Grid Search)
- 좋은 하이퍼 파라미터를 고르는 방법 중 하나
- 각 하이퍼 파라미터에 넣어보고 싶은 후보 값을 몇 개씩 정함
- 모든 후보 값의 조합으로 모델을 학습시키고 성능이 가장 좋았던 조합 선택
후보 값들이 감이 안온다면 구글링을 통해 sklearn에서 사용되는 디폴트 값을 확인
디폴트 값과 비슷한 값들을 후보 값으로 정하는 것
ex)Lasso모델의max_iter디폴트 값은 1000
ex)
| 0.1 | 1 | 10 | |
|---|---|---|---|
| 1000 | 6.12 | 6.78 | 9.23 |
| 2000 | 7.3 | 5.41 | 8.4 |
| 3000 | 8.57 | 10.98 | 7.6 |
alpha= 1,max_iter= 2000 으로 하이퍼 파라미터 선택
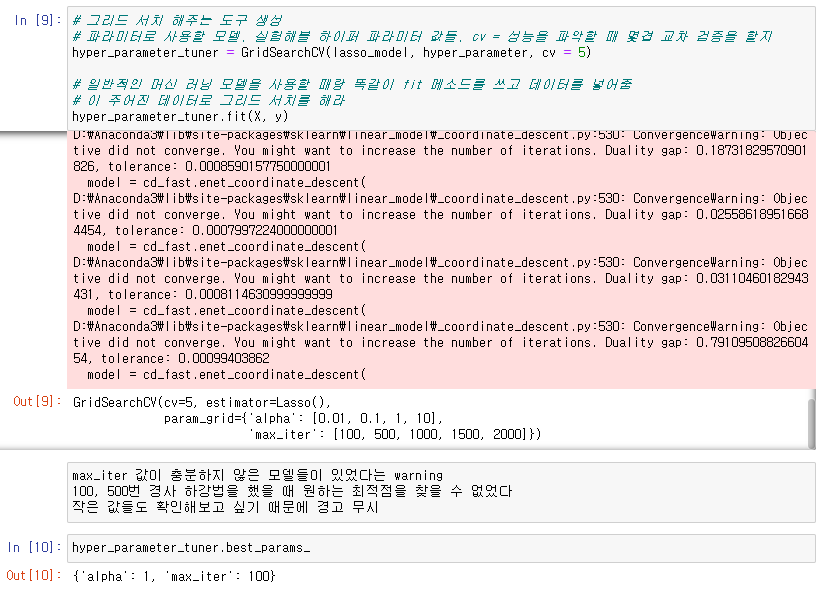
➡ scikit-learn으로 그리드 서치

.png)
IWBAGDS