-
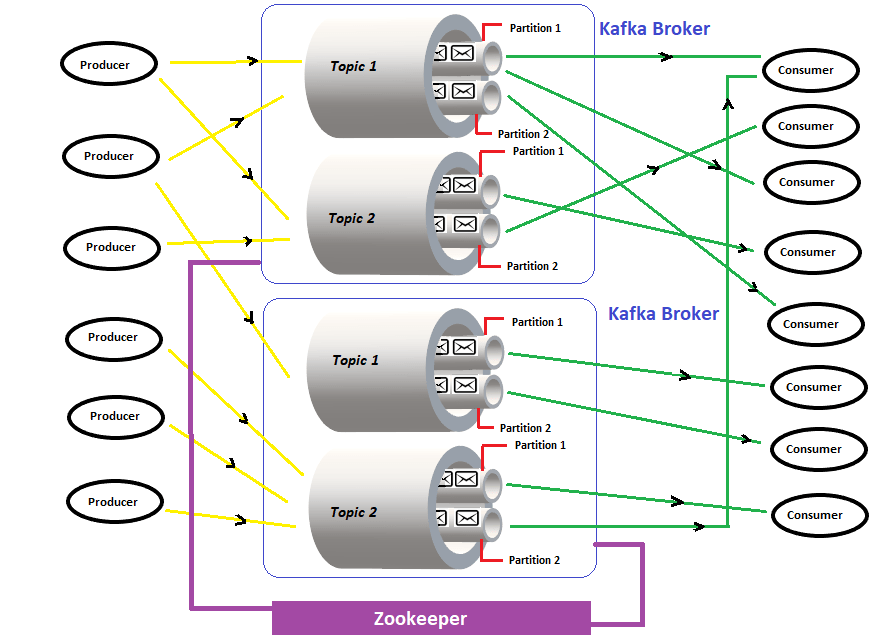
카프카
data stream 에 있어서 aws 공부할때 배웠던 kinesis 처럼 대용량 데이터 서비스 stream 에 최적화된 message Q 스트림!-
매번 스트림이란 무엇인가에 대해 고민을 하던 찰나 써보게 되어서 아주 반갑구만유..
-
-
근데 이렇게 깜깜이 정책이 아닐수가 없다
- 분명 aws 에서는 서버리스(?) 처럼 돌아가는거 같아서 이 친구도 알아서 어련히 잘 돌아가려나 했는데
- 아무래도 현재 구축 환경이 완전한 saas 가 아니다 보니 (최소한 나에게는...)
- development 환경 에서 최대한 코드로 message Q를 처리를 해야하는데 consumer와 producer 개념이 나와서 신기했구요
- 이게 application level에서도 접근이 되는구나 하면서 한편으로는 메모리를 관리하는 데 굳이 서버리스 서버(?)를 두고 접근하는 이유에 대해 고민을 처음엔 많이 했던것 같음.
custom 한 데이터 전처리 및 ai 모델링, 안정화되고 명확한 파이프라인 구축이 핵심인 듯 하다.
- 분명 aws 에서는 서버리스(?) 처럼 돌아가는거 같아서 이 친구도 알아서 어련히 잘 돌아가려나 했는데
오만
처음 공부할때 shell 스크립트로 뚝딱 되길래 아 쉽겠네 했는데 안 쉽다
오프셋도 다시 공부했다
- 기존의 오프셋은
- 아래와 같이 레지스트리 application 리버스 엔지니어링 및 디버깅할때 자주나오던 개념이라..
- 디버그 할때 봐야하는 값들 중 하나라고 착각하고 있었음
 예시 )
예시 )
메모리 주소 , 변수값
402000 ,0
402001 , 1
402002 , 2
402003, 3
char a[4] = {0,1,2,3}
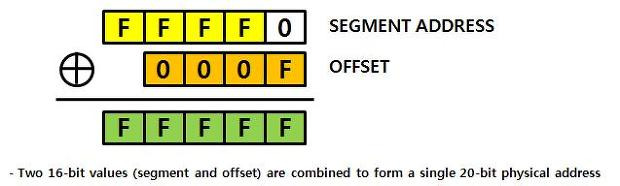
offset
- 세그먼트에서 물리주소 표현할때 segement+offset 조합으로 얘기함
0xFFFFF
FFFFh:000Fh, FFF0h:00FFh, FF00h:0FFFh, F000h:FFFFh - 어셈블리어에서는 상대주소로 일컫는다 (해당 변수나 메소드의 상대적인 위치를 알고, 역 추적/ 변조할 수 있음)
★ 프로그래밍을 마냥 좋아하는 아이 - 심스의 프로그래밍 세상 ★:티스토리 - 16진수로된 상대적인 위치의 개념?에 가까웠는데
-
페이지 : 메모리나 디스크에서 관리되는 고정크기의 데이터 블록.
ex ) OS는 고정 크기의 메모리 블록 4KB 페이지를 사용해 메모리와 디스크간 데이터를 주고받는다고 함 -
페이지 cache: OS의 메모리 관리 시스템 일부.
물리적으로 메모리 일부 사용. 주로 해당 데이터의 페이지를 저장한다고 함 (IO 횟수를 줄이는 용) (file system과 관련됨) -
registry: OS setting option 용 database.
그럼 일반 cache는 무엇인가
일반 저장소 ( cpu, web 등..) 일반적인 데이터 임시 저장소 - memory 일부..
buffer / stack / queue ( mechanism)
- 데이터 일시적 저장을 위한 논리적 공간.( 일반 cache 와 비슷함)
- FIFO/LIFO/FIFO
그 외 register
-
cpu 와 매우 밀접합 ( memory 보다 훨씬 빠르다고 함)
그래서 카프카는요..
-
카프카 자체는 디스크에서 도는데
-
카프카의 오프셋은 Page Cache라는걸 사용해서 속도를 높임
-
카프카의 오프셋은 브로커내 토픽 파티션에 consumer 가 '읽을'위치
-
어디까지 읽었나? (사물함의 물건의 위치)
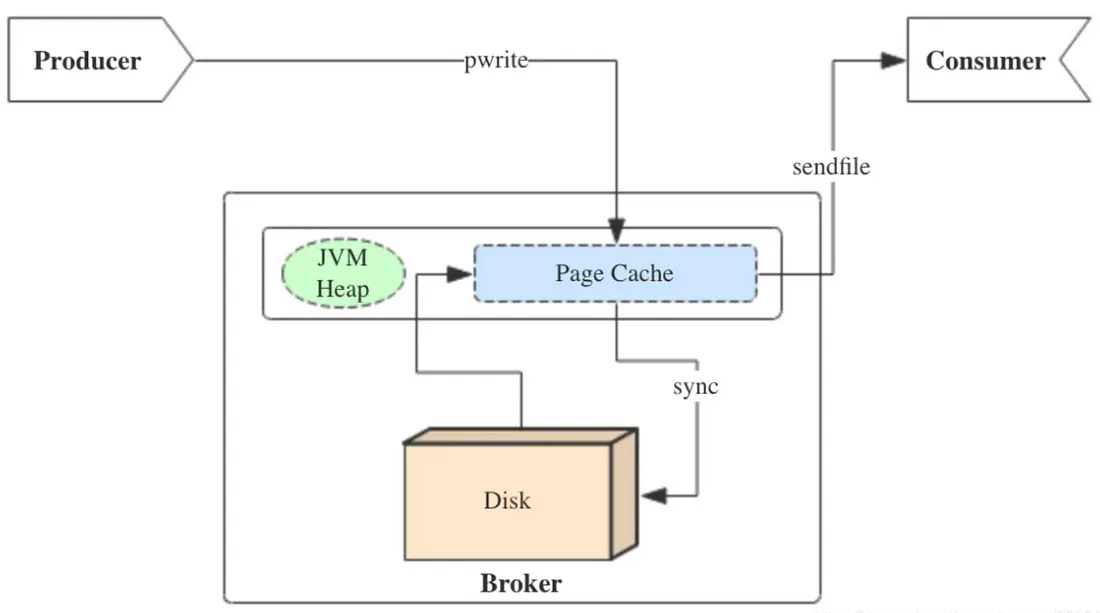
- 또한 저장(?)의 개념이 없기에 빠른처리가 가능함.
-
-
이래서 서버리스 서비스가 좋은건가(?)
- 조만간 rabbitMQ도 공부해야겠음

나는야 깔짝냠냠핑..

🏠TECH & GOSSIP