
검색엔진 사용해보기
이전 글에서 만든 기업 데이터는 대부분 한글 관련 데이터 이다.
Elasticsearch의 기본 분석기는 한글 단어에 대해 형태소 분리가 정확히 이루어지지 않는다.
아래 예시를 한번 보자.
- ‘한국공항공사’ 라는 기업을 ES에 저장했을 경우 ‘한국공항공사’ 로 저장되고 한국, 공항, 공사 등 처럼 검색어 토큰이 분리가 되지 않는 다는 의미
형태소 분리가 되지 않으면, 검색 엔진을 사용하지만 검색 자체가 잘 되지 않는다.
Elasticsearch 6.6 버전부터 공식적으로 Nori(노리) 라는 한글 형태소 분석기가 Elastic 사에서 공식적으로 개발해서 지원하기 시작했다.
Nori 분석기 구성
Nori 분석기는 1개의 토크나이저와 2개의 토큰 필터로 구성되어있다.
토크나이저
- nori_tokenizer
- 한국어 사전 정보를 이용해 형태소(토큰)형태로 분리하는 데 사용
- decompound_mode 옵션을 제공하는데 3가지
- none
- 복합명사로 분리하지 않는다
- Ex) 잠실역
- 복합명사로 분리하지 않는다
- discard (기본)
- 복합명사로 분리하고 원본 데이터는 삭제한다.
- Ex) 잠실, 역
- 복합명사로 분리하고 원본 데이터는 삭제한다.
- mixed
- 복합명사로 분리하고 원본 데이터도 유지한다.
- Ex) 잠실역, 잠실, 역
- 복합명사로 분리하고 원본 데이터도 유지한다.
- none
토큰 필터
- nori_part_of_speech
- stoptags 에 제거할 품사를 지정해 제외 시킨다.
- nori_readingform
- 한자로 된 단어를 한글로 바꾸어 저장
- lowercase
- 영어 대문자를 소문자로 바꿔서 저장
자세한 내용은 공식 문서를 참고하자.
Nori 설치
먼저, Nori 한글 형태소 분석기는 Elasticsearch 기본 플러그인이 아니기 때문에 설치를 해주어야한다.
# Nori 플러그인 설치
bin/elasticsearch-plugin install analysis-noriDocker를 사용한다면 플러그인이 설치된 Elasticsearch 이미지를 사용해야 하기 때문에 별도 Dockerfile을 아래 처럼 만들어서 build 해서 쓴다.
# https://www.docker.elastic.co/
FROM docker.elastic.co/elasticsearch/elasticsearch:8.1.2
RUN bin/elasticsearch-plugin install analysis-nori 설치 이후 ES를 재시작한뒤, 아래처럼 Nori 플러그인이 로드되면 OK

이후에는 사용하는 인덱스에 Nori 한글 형태소 분석기 선언과 Nori를 적용시킬 필드 설정이 필요하다.
변경된 analysis 적용을 위해서는 인덱스를 재생성하는 reindex 하거나 새로운 인덱스에 원하는 설정을 입력한 뒤 데이터를 추가하여 적용시키자.
settings에 analysis와 tokenizer를 설정 한 뒤 mappings에 기업명 (name) 필드에 적용 시킨다.
PUT es-test-company-v2
{
"mappings" : {
"properties" : {
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"analyzer": "nori_discard"
}
}
},
"settings" : {
"index" : {
"analysis" : {
"analyzer" : {
"nori_discard" : {
"type" : "custom",
"tokenizer" : "nori_discard"
}
},
"tokenizer" : {
"nori_discard" : {
"type" : "nori_tokenizer",
"decompound_mode" : "discard"
}
}
}
}
}
}💡 Kibana의 Dev tools를 사용하면 편리하게 API를 호출 해볼 수 있다.
검색 결과
analysis 적용 안된 버전과 analysis 적용된 버전을 비교해보면 어떤 차이인지 확실하게 볼 수 있다.
analysis 적용 안된 버전
아래처럼 기업 이름(name)에 ‘한국공사’를 쳐서 검색해보자.
GET es-test-company/_search
{
"query": {
"match": {
"name": "한국 공사"
}
}
}결과
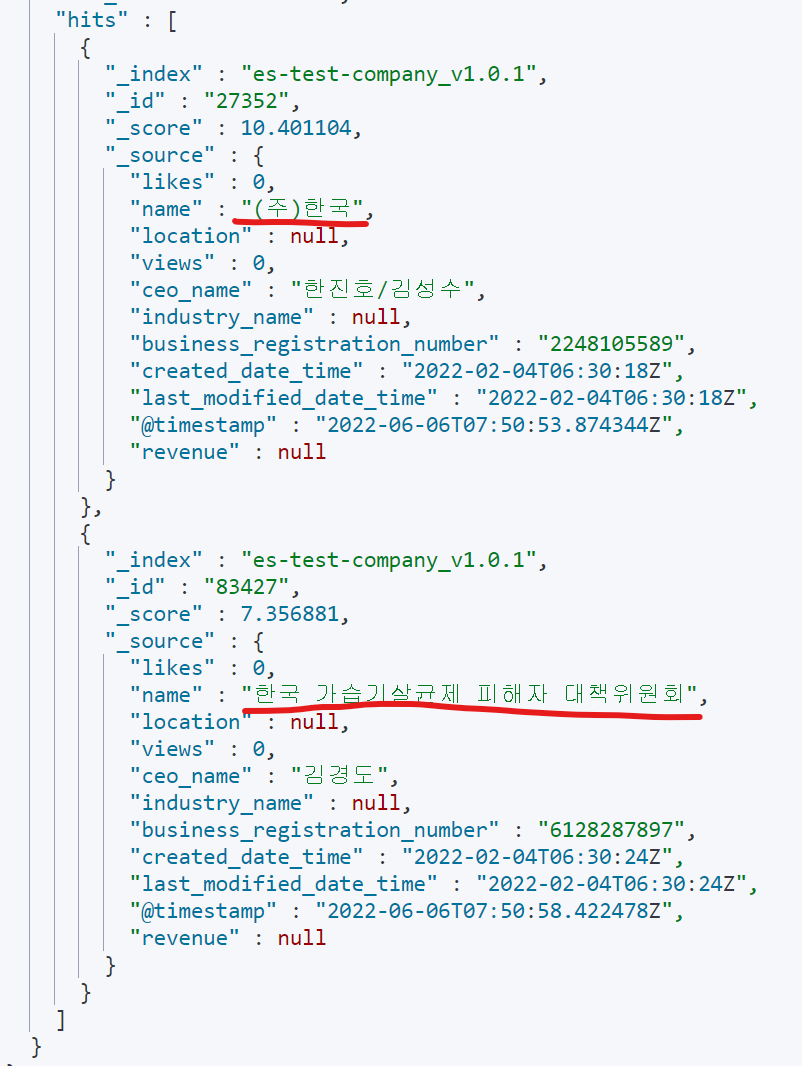
analysis 적용된 버전
GET es-test-company-v2/_search
{
"query": {
"match": {
"name": "한국 공사"
}
}
}결과
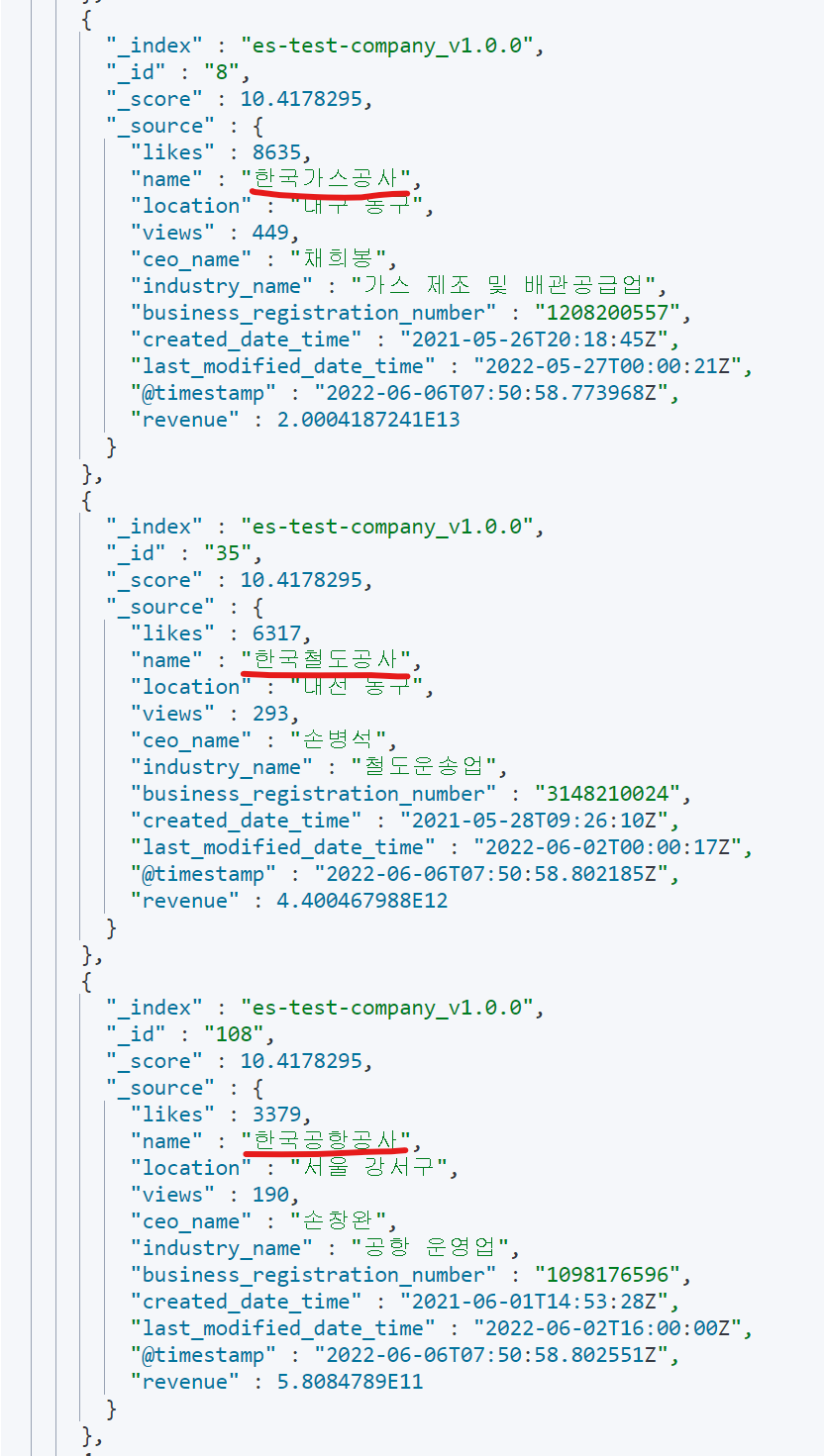
훨씬 정제되고 원하는 결과가 나온 것을 볼 수 있다.
💡 ES에서 기본 정렬은 _score 값으로 검색엔진 내부적으로 계산된 스코어가 활용되는데
운영 중인 서비스에 매번 ‘가나다순’ 이런 무의미한 정렬 기준 말고 _score로 데이터가 정렬되면 훨씬 좋은 결과를 보여줄 수 있을 것 같다.
이러한 결과 차이가 발생하는 이유는 한글 문장에 대해 키워드 분리 방식이 다르기 때문이다.
Nori를 적용하지 않으면 기본 형태소 분석기가 붙는데 이 분석기는 대문자 > 소문자, 특수문자 제거, 공백에 따라 문장 분리 등의 작업을 진행한다.
한글에 대해서는 공백을 기준으로 분리하는 작업 밖에 하지 못한다.
반면에, Nori의 경우에는 한국어 사전 정보를 이용해 단어를 분리해준다.
꼬꼬마 한국어 형태소 분석기 - http://kkma.snu.ac.kr/documents/?doc=postag
한글 검색은 보통 주요하다 판단되는 명사, 동명사 정도만을 검색하고 조사, 형용사 등은 제거하는 방향으로 검색한다.
제거 코드는 stoptags 로 관리되는데 Nori의 디폴트 값은 다음과 같다.
"stoptags": [
"E", "IC", "J", "MAG", "MAJ",
"MM", "SP", "SSC", "SSO", "SC",
"SE", "XPN", "XSA", "XSN", "XSV",
"UNA", "NA", "VSV"
]Spring에 적용시 고려할 사항
추후 검색엔진이 Spring 프로젝트에 들어올 텐데 이때, 연결할 수 있는 Client 모듈이 현재 총 3개이다.
- Java High Level REST Client
- org.elasticsearch.client:elasticsearch-rest-high-level-client
- 가장 많이 사용되고 문서도 많은 Client 지만, Elasticsearch 7.15.0 버전에서 Deprecated된 모듈이다.
- Elasticsearch 8.x 버전을 호환되게끔 하는 옵션을 키면 8.x 버전에서도 사용 가능하다고 한다.
- Spring Data Elasticsearch
- Spring의 Data 프로젝트 중 하나로 Java High Level REST Client 를 추상화 시켜서 만든 모듈이다.
- 버전 변경에 민감하고 최신 버전을 사용할 수 없는 단점 (1년에 1번정도 업데이트된다)
- ORM을 지원해서 메소드 쿼리 등 JPA를 사용할 때처럼 보일러 코드가 줄어들 수 있다.
- Spring Data ES의 경우도 ES7 버전부터 구현체를 Java High Level REST Client 를 사용한다.
- Elasticsearch Java API Client
- co.elastic.clients:elasticsearch-java
- 7.16 버전 이후 Elastic 사에서 새로 개발한 Client 모듈
- 자료가 많이 없다.
- Java High Level REST Client 를 안써봐서 정확히는 모르겠지만 사용성 자체는 비슷해보인다.
모듈 의존성 구조 정리
7.15버전 이전 의존성 구조는 다음과 같다.
- Java Low Level Client > Java High Level Client > Spring Data Elasticsearch
7.16버전 이후 의존성 구조는 다음과 같다.
- Java Low Level Client > Elasticsearch Java API Client
추후 Elasticsearch Java API Client를 구현한 Spring Data Elasticsearch 버전이 나올 수도 있겠다.
💡 Devops에서 아직 명확한 ES 버전을 명시해주지 않아서 위의 특징을 비교해서 어떤 모듈을 사용할지 의논해서 결정해야할 것 같다.
참고하면 좋은 사이트
ElasticSearch 가이드북
Logstash 와 JDBC를 사용해 RDB와 Elasticsearch 동기화
