
RDB와 Elasticsearch 동기화
이제 Elasticsearch의 기본 개념에 대해서 알아 보았으니 실제 프로젝트에 어떻게 적용 시킬 것인가에 대해서 고민해보자.
만약, ‘기업 데이터를 가지고 검색엔진을 만들고 싶다’ 라고 할때 어떻게 구조를 잡아야할지 가장 먼저 고민이 되었다.
결국, 검색엔진의 역색인 구조를 활용한 전문 검색을 하기 위해서는 Elasticsearch에 데이터가 적재되어야하기 때문에 운영 중인 서비스에서 DB 데이터 변경이 발생했을 경우에 Elasticsearch 쪽과 데이터를 동기화 시켜주어야 한다.
그렇다면 어떤 방식을 사용하여 동기화 시킬까?
이전 ELK 문서에서 작업했던 내용에서 Logstash의 역할에 대해서 설명했다.
Logstash는 다양한 input 플러그인을 제공하는데 그 중에는 JDBC 관련 플러그인도 제공해준다.
jdbc input plugin
해당 플러그인을 사용하면, Logstash가 설정된 주기마다 DB로부터 데이터를 조회해서 Elasticsearch에 자동으로 동기화 시켜줄 수 있다.
여기서 몇가지 고민이 생기는데 다음과 같다.
새로 생성되는 데이터, 업데이트 되는 데이터를 구체적으로 어떻게 동기화 처리하는가?
2가지 방법이 있을 것 같다.
- 특정 동기화 시간 주기를 정한 뒤 모든 테이블 데이터를 조회해와서 다시 인덱싱
- 변경된 데이터만 감지하여 업데이트
1번의 경우 는 테이블이 크면 클 수록 DB에 부하가 커질 것이고 변경되지 않은 데이터도 불러와서 인덱싱하므로 엄청 비효율적일 것 같다.
2번의 경우 가 변경된 데이터만 조회하여 인덱싱하므로 가장 효율적인 방법일 것 같다.
jdbc input plugin 에서는 어느 시점의 데이터까지 조회하여 인덱싱하였는지 알려준다.
- 아래처럼
.logstash_jdbc_last_run파일에 Logstash 가 언제 폴링하여 데이터를 조회 했는지 기록해준다.- 쿼리를 수행할 때 가장 최근에 실행했던 시간 정보를 불러올 수 있다. (
:sql_last_value)
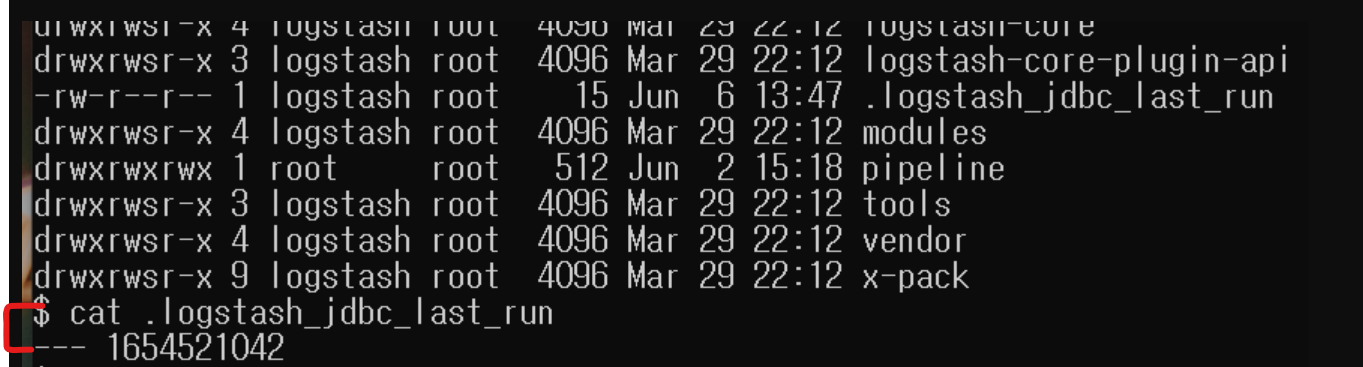
- 쿼리를 수행할 때 가장 최근에 실행했던 시간 정보를 불러올 수 있다. (
그렇다면, 삭제되는 데이터도 자동으로 트래킹이 가능한가?
이 부분은 위에서 설명한 최근 폴링한 시점을 기록하여 관리하더라도 삭제된 데이터는 트래킹이 불가능하다.
이에 대해서는 2가지 방법이 있다고 한다.
- DB에
is_deleted필드를 추가한뒤 유효하지 않은 데이터임을 표기하여 조회 시점에 해당 값이 false인 (삭제되지 않은) 데이터만 불러와 사용한다. (소프트 삭제를 이용) - 도큐먼트 삭제 이벤트가 발생하였을 때, 직접 Elasticsearch에 해당되는 문서 삭제 요청을 날린다.
현재 운영중인 서비스의 경우 소프트 삭제를 하지 않고 실제 데이터를 모두 삭제하고 있어서 기존 구조를 변경하여 처리하거나,
2번의 방법을 사용하여 데이터가 삭제될 때 ES로 삭제 요청을 보내도록 관리하는 방법이 있을 것 같고
또는, 삭제된 데이터를 큐처럼 모아두었다가 배치로 한번에 ES로 삭제 요청 보낸다던지의 처리가 필요해보인다.
반복적으로 데이터가 많은 테이블을 계속 조회하게 되면 DB에 부하가 갈텐데 괜찮을까?
RDB <> ES 동기화 시간 주기를 늘리는 방안으로 조정하는 방법도 있고, 운영중인 서비스의 경우는 조회 목적 레플리카 DB가 별도로 나와 있으므로 추후 MariaDB와 ES 데이터를 동기화할 때는 레플리카 DB를 바라보고 동기화 하는 방법도 좋을 것 같다.
RDB <> ES 동기화에 대한 상세 정보는 아래 사이트를 참조
MariaDB <> ES 동기화 적용시키기
DB 설정
실습 적용에 사용된 데이터는 기업 데이터를 일부 추출하여 사용함.
적용할 때 실제 약 89000개를 로컬 DB에 붙였다.
- Company 테이블
create table company ( id bigint auto_increment primary key, business_registration_number varchar(255) null, ceo_name varchar(255) null, industry_name varchar(255) null, location varchar(255) null, name varchar(255) null, revenue decimal(19, 2) null, likes bigint default 0 not null, views bigint default 0 not null, created_date_time datetime default CURRENT_TIMESTAMP not null, last_modified_date_time datetime default CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP not null );
Logstash 설정
logstash pipeline에 새로운 파이프를 다음처럼 추가한다.
- pipeline.id: mariadb-sync-elasticsearch
path.config: "pipeline/logstash-mysql.conf"그후 logstash-mysql.conf 파일을 새로 생성하여 아래처럼 JDBC input, filter, output 을 작성하자.
input {
jdbc {
jdbc_driver_library => "/usr/share/logstash/jar/mysql-connector-java-8.0.29.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://mysql:3306/es-test?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Seoul&autoReconnect=true"
jdbc_user => "root"
jdbc_password =>"mysql"
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
tracking_column_type => "numeric"
use_column_value => true
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(last_modified_date_time) AS unix_ts_in_secs FROM company WHERE (UNIX_TIMESTAMP(last_modified_date_time) > :sql_last_value AND last_modified_date_time < NOW()) ORDER BY last_modified_date_time ASC"
}
}
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "es-test-company"
document_id => "%{[@metadata][_id]}"
}
stdout {
codec => rubydebug # 디버깅용
}
}옵션에 대해 간략하게 설명하면 다음과 같다.
JDBC 관련 옵션
- 현재 사용중인 RDB의 관련된 정보이다.
- JDBC Driver의 경우는 해당 사이트에서 다운로드 가능하다.
- 데이터가 큰 경우에는 페이징 옵션을 켜주자.
tracking_column, use_column_value 관련 옵션
- 위에서 말한 최근 인덱싱하기 위해 데이터를 조회했던 시간을 기록해주는 옵션이다.
- 예제에서는 Company 테이블의 Base 필드인
last_modified_date_time로 잡았다. (수정일자)- 해당 값은
.logstash_jdbc_last_run파일에 저장되며 statement 쿼리문에서:sql_last_value변수로 가져올 수 있다.
- 해당 값은
schedule 옵션
- Logstash가 얼마나 자주 DB를 폴링 해야하는지를 지정하는 cron 구문이다.
statement 옵션
- 어떤 데이터를 조회해서 ES에 동기화 시킬지 지정하는 쿼리문
- where 조건에 범위 조건이 포함되어 있는데 간략하게 설명하면 추가/수정된 경우 데이터가 중복, 누락 없이 동기화 시키기 위한 범위 조건이다.
JDBC Input에 여러 테이블을 동기화 시키려는 니즈가 있을 경우 하나의 파일에 여러 설정도 가능하거나 별도의 여러 파이프라인을 만들어서 처리도 가능하다.
단, 해당 케이스의 경우는 .logstash_jdbc_last_run 의 경로를 다르게 설정하여 :sql_last_value 값이 서로 간섭되지 않게 설정하는 것이 중요하다.
JDBC 관련 플러그인 공식 문서를 참고하면 각 옵션의 기능을 상세하게 알 수 있다.
실행하기
Logstash를 실행하면, 아래처럼 schedule 옵션에 설정한 시간만큼 반복적으로 데이터를 불러오는 것을 볼 수 있다.
- Logstash 설치 및 실행 방법은 해당 링크에서 확인 할 수 있다.

💡 약 89000개의 기업을 초기에 업데이트 했는데 30초도 안걸리고 동기화가 이루어진다.
RDB 데이터와 Elasticsearch 데이터가 정상적으로 동기화 되었는지 확인해보자.
RDB 데이터 개수
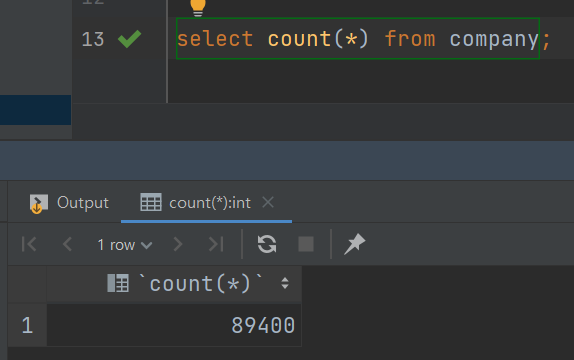
Elasticsearch 데이터 개수
// 데이터 개수 확인 쿼리
GET es-test-company/_count
// 결과
{
"count" : 89400,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}초기 데이터가 모두 들어갔으면, 이제 연결된 테이블에 새로운 기업을 생성 추가, 수정해보자.

그러면 Logstash는 변경 사항을 감지하고 아래처럼 ES에 데이터를 동일하게 써주는 것을 볼 수 있다.

Kibana에 접속해서 Discover를 살펴보면 정상적으로 ES에 데이터가 동기화 된 것을 볼 수 있다.

기업 정보를 활용하면 대시보드에 이런 시각화도 가능하다.
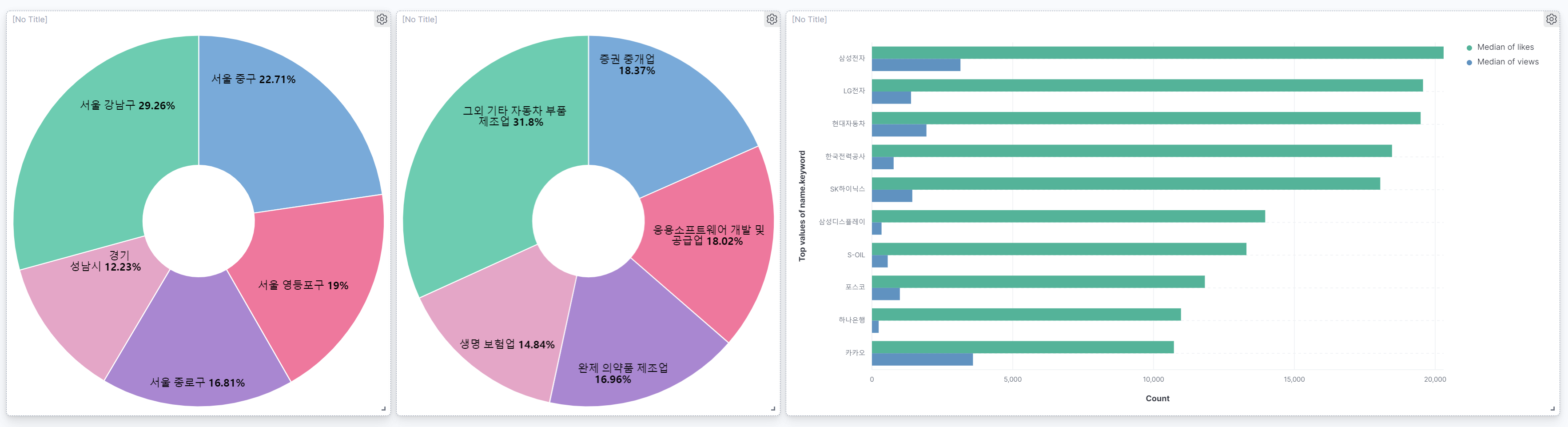
마무리
ElasticSearch와 RDB간에 데이터를 어떻게 동기화 시킬 것인지에 대한 방안을 살펴봤다.
- 새로 생성되거나 업데이트 되는 데이터 동기화
- 삭제되는 데이터 트래킹하여 동기화
- Logstash를 활용하여 RDB <> ElasticSearch 데이터 동기화
다음 글에서는 ElasticSearch에 동기화된 데이터를 가지고 검색 엔진을 활용하는 법에 대해서 다뤄보자.
