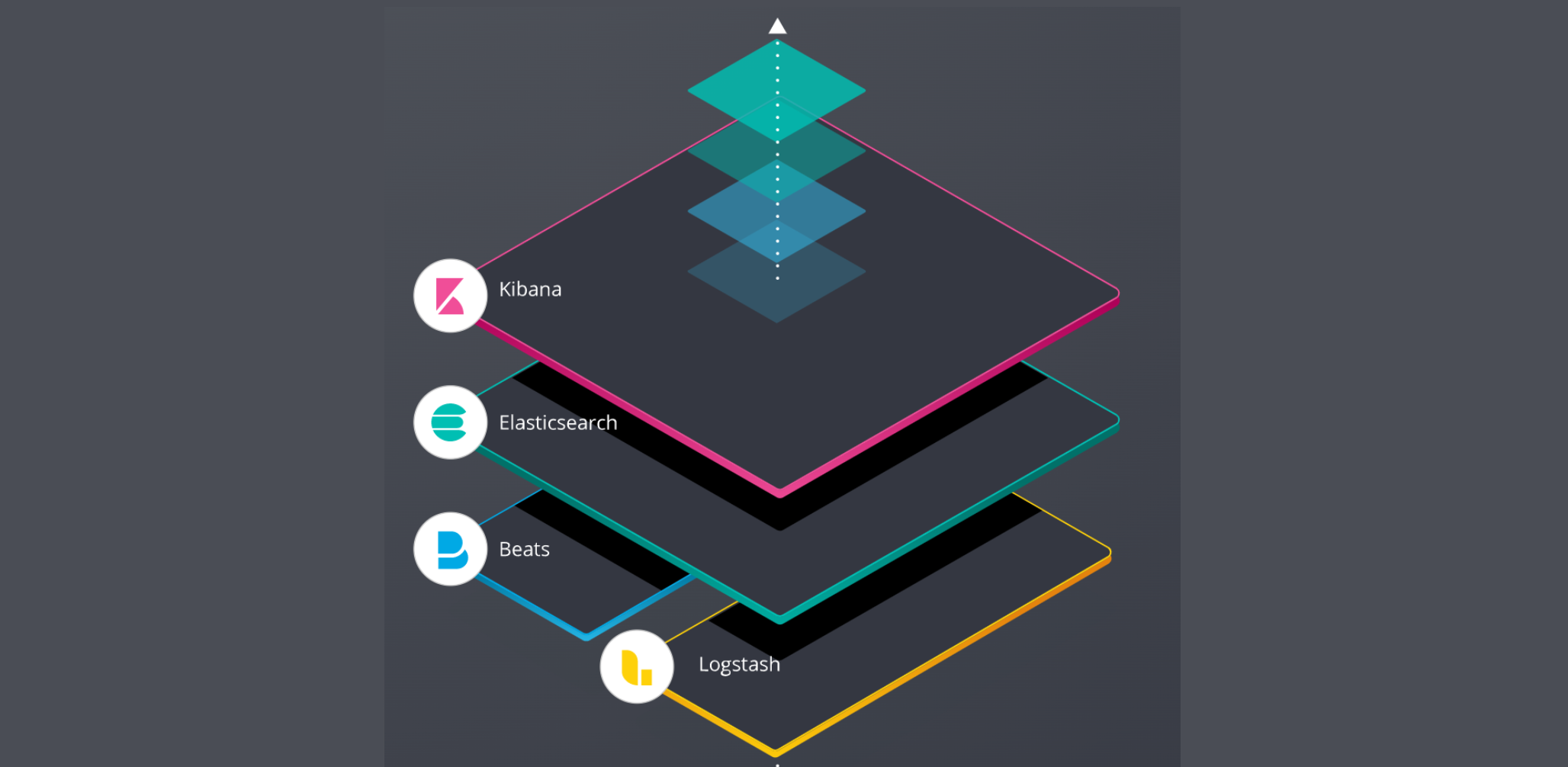
이전 글에서는 ELK 스택에 대해 간략하게 알아보았다.
이번 글에서는 ELK 스택을 설치해보고 실제로 적용해보자.
ELK 적용하기
사전 준비
ELK 설치
ELK 설치를 Window 나 Mac 에 직접 설치하여도 무방하지만 Docker를 사용하면 더욱 편리하게 설치가 가능하다.
참고 사이트
단, ELK는 구성이 조금 더 복잡하다며 컨테이너간 하나의 네트워크 연결이 반드시 필요!
카프카 설치
카프카의 기본 개념에 대해 알고 있다고 가정하고 진행
Kafka 설치도 아래처럼 Docker를 사용하면 쉽게 띄울 수 있다.
version: "3"
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- 2181:2181
restart: always
kafka:
image: wurstmeister/kafka
environment:
KAFKA_BROKER_ID: 1
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
ports:
- 9092:9092
volumes:
- ./broker/data:/kafka # kafka 데이터
- ./broker/logs:/opt/kafka/logs # kafka 로그
restart: always
depends_on:
- zookeeper # 항상 zookeeper가 먼저 실행도커를 개인 PC에 설치한 이후 아래 docker-compose.yml 파일을 생성하고
docker-compose up -d
커맨드를 입력하면 손쉽게 zookeeper와 kafka가 백그라운드로 실행된다.
ElasticSearch, Kibana 실행
위에서 docker-compose로 ELK 설치가 완료 되었으면, 우선 ElasticSearch와 Kibana에 정상적으로 접근이 되는지 확인한다.

ElasticSearch - localhost:9200
Kibana - localhost:5601
위 포트로 각각 접근이 되면 OK!
Logstash 실행
위 구성도에서 보면 Logstash의 input과 output 이 각각 kafka, elasticsearch로 되어 있으니 logstash에 해당 정보를 입력해주어야한다.
Logstash의 경우 config 폴더 안에 있는 logstash.conf 파일과 pipelines.yml 을 수정해보자.
logstash.conf 설정
# logstash.conf
input {
kafka {
bootstrap_servers => "localhost:9092"
topics => "kafka-elk-test-log"
}
}
filter {
json {
source => "message"
}
}
output {
elasticsearch {
hosts => "localhost:9200"
index => "kafka-elk-test-log-%{+YYYY.MM.dd}"
}
}- input 설정에는 Kafka 서버 경로와 어느 토픽에서 데이터를 가져올지 지정해준다.
- filter 설정은 받은 데이터가 json임을 명시해주는 역할
해당 옵션을 적용시켜야 ElasticSearch에 저장될 때 ES Field가 json 형태로 분리된다. - output 설정에는 ElasticSearch 호스트 경로와 어느 인덱스에 데이터를 저장할지 지정해준다.
- 날짜별로 인덱스를 분리해서 저장시킨다.
pipeline.yml
- pipeline.id: kafka-test-logs
path.config: "config/logstash.conf"logstash를 실행할때 default가 pipeline 설정을 보고 실행하기 위와 같이 지정해주고 재시작하자.
Spring 서버에서 토픽 발행
Producing에 성공했을 경우, 아래와 같이 설정하여 Kafka로 재발행하는 로직을 추가한다.
성공 메시지 저장 로직 (RDB 저장 > Kafka 프로듀싱 로직으로 변경)
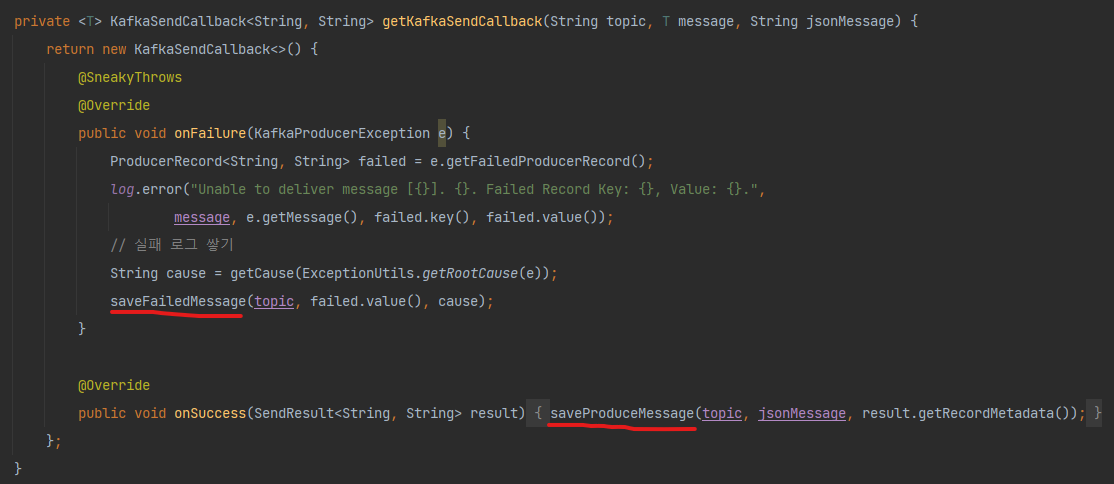
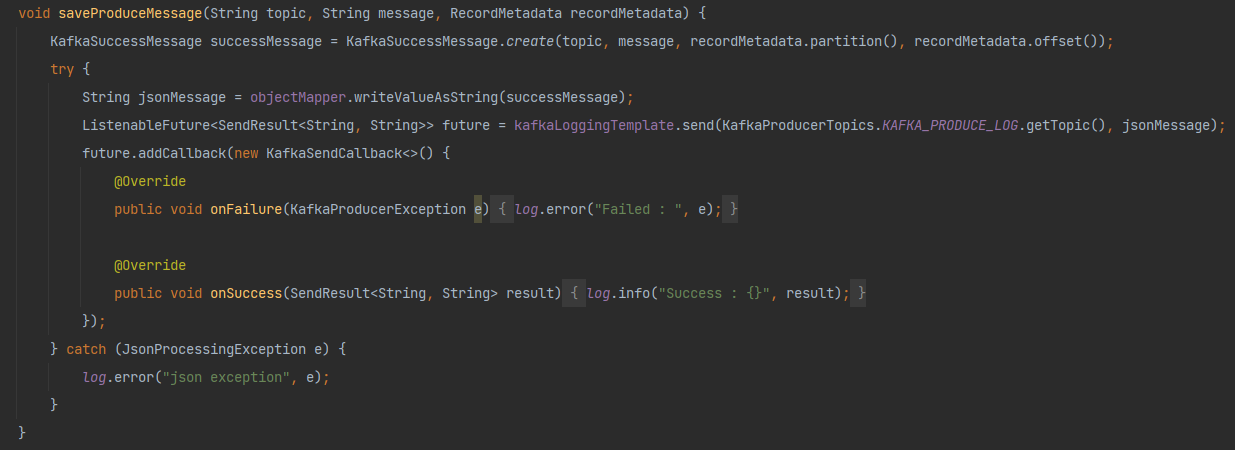
KafkaSuccessMessage 정보
@Getter
@Setter
public class KafkaSuccessMessage {
private String topic;
private String message;
private int partition;
private long offset;
// ...
}Factory, Template 설정
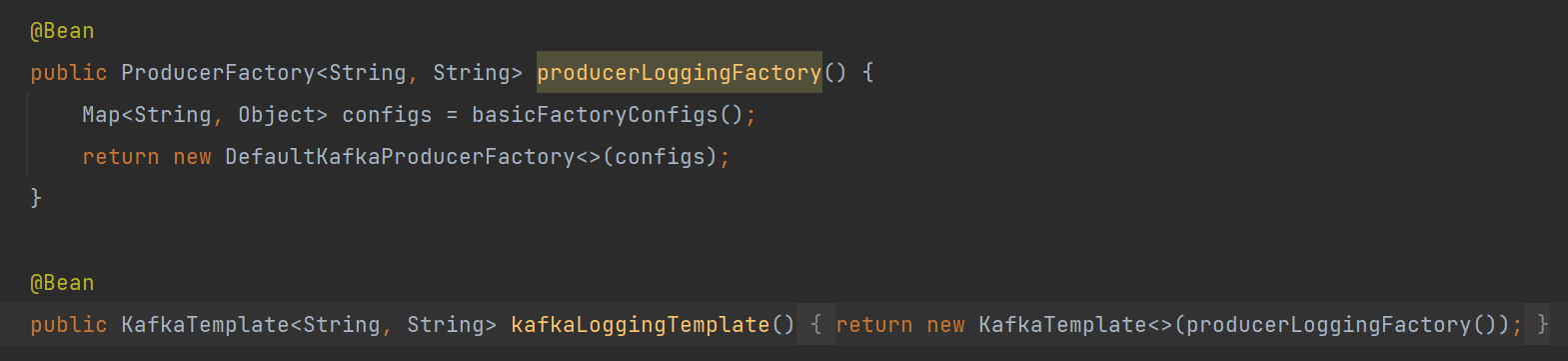
💡 Factory와 KafkaTemplate을 로깅 전용으로 별도로 만드는 이유는 callback 내부에서 프로듀싱하는데 동일 Template으로 다른 토픽에 데이터를 전송하면 Timeout 에러가 발생하여 서로 다른 스레드에서 분리되어 동작할 수 있도록 Template을 분리시킴

KafkaTemplate이 분리되지 않았을 때, Timeout 에러 발생한 케이스

KafkaTemplate이 분리되었을 때, 성공한 케이스
간단하게 테스트용 컨트롤러에 토픽 발행 로직을 이용하여 로깅 데이터를 저장해보자.

KafkaTestRq 정보
@Getter
@Setter
public class KafkaTestRq {
@Schema(description = "메시지 제목")
private String title;
@Schema(description = "내용")
private String message;
}로깅 구조 연동 테스트 결과
위 데이터를 요청한 뒤 Kibana 정보를 확인해보자.
인덱스, offset, partition, message 정보가 정상적으로 Kibana Discover 에 노출된 것을 확인 할 수 있다. 👏

Kibana Dashboard 활용하기
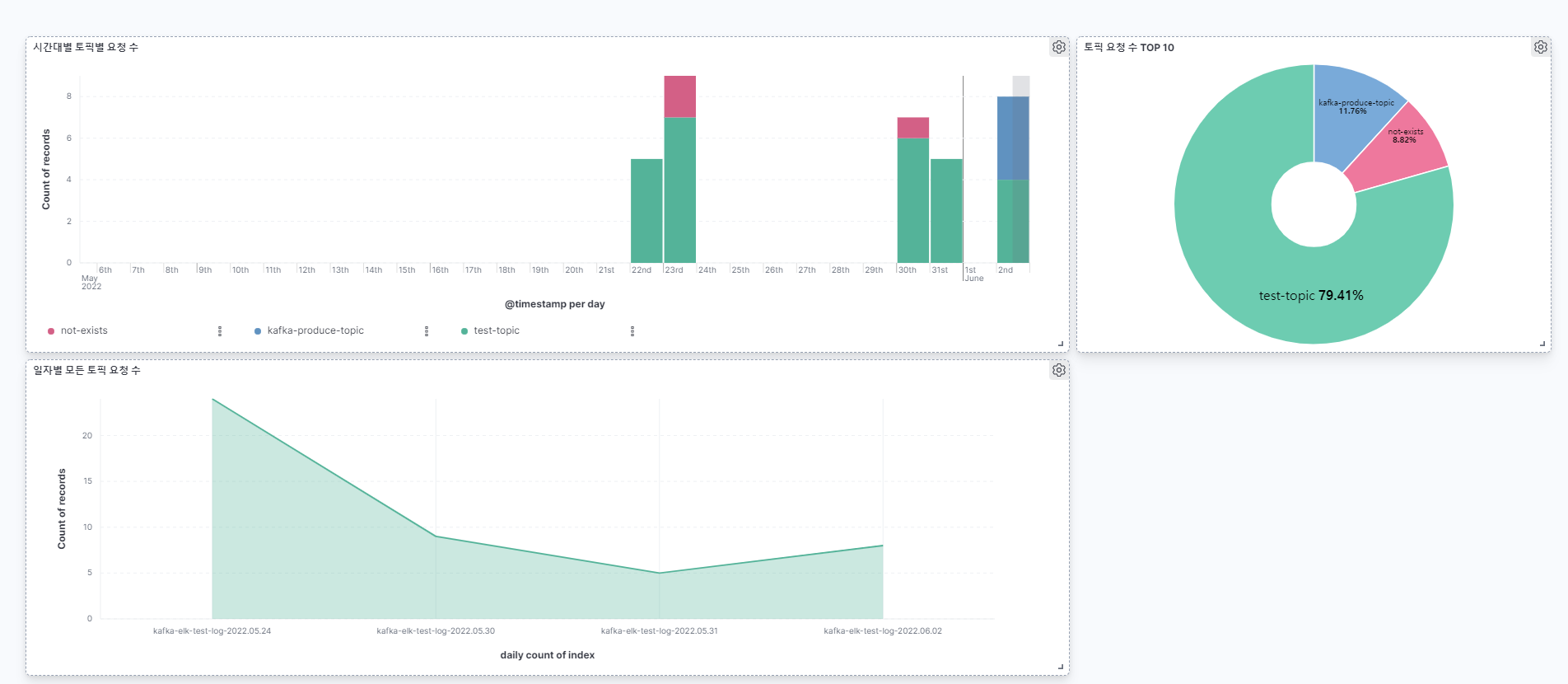
대시보드를 활용하면 기존 ES 적재되어 있던 데이터 기반으로 다음처럼 시각화가 가능하다.
Kafka 토픽 데이터
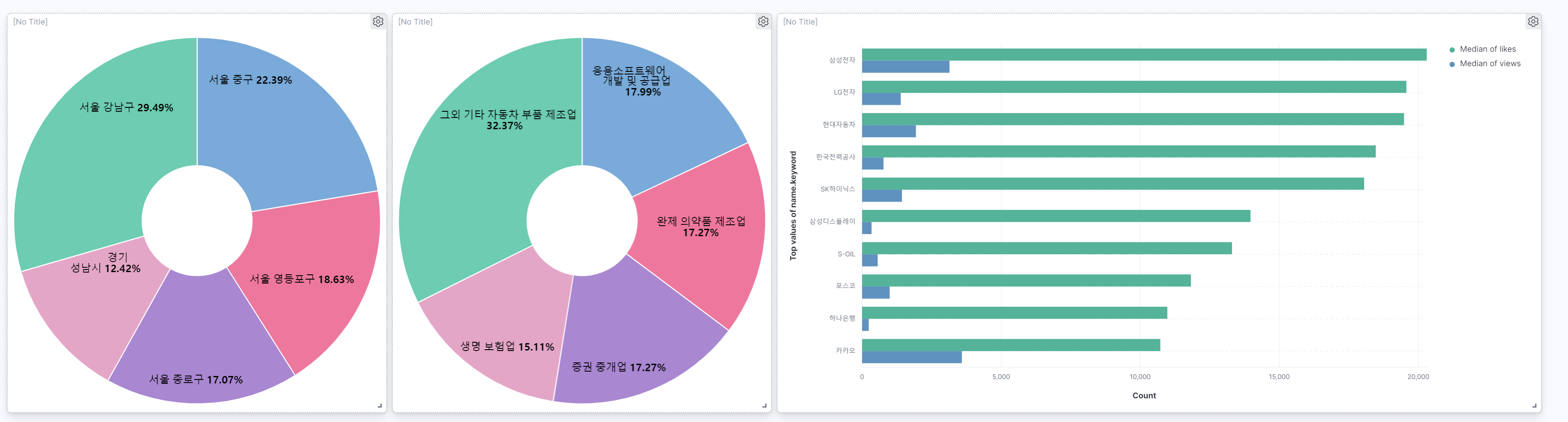
Company 데이터
그 밖의 활용 방법
Curator, Repository-S3 를 활용하여 오래된 로그 데이터 관리
Curator 를 활용하면, ElasticSearch에 적재되는 많은 로그 파일을 기간(Ex: 30일) 혹은 디스크 용량(Ex: 10GB)을 기준으로 오래된 로그를 지워준다.
만약, ElasticSearch 데이터를 미리 백업하고자 하는 니즈가 있다면 ElasticSearch에 repository-s3를 사용하면 ES 스냅샷한 뒤, S3로도 백업이 가능하다.
WAS 서버 로깅
에러의 경우 에러 모니터링 도구 Sentry나 APM 도구인 Pinpoint로 트래킹이 충분히 가능하지만 어플리케이션에서 발생한 전문 로깅 정보가 필요하거나 확인이 필요한 경우 DV, ST 정도는 인스턴스 접근 후 로그 확인하여 가능하나 불편하고 PR의 경우는 접근이 안되기 때문에 Raw 한 서버 로그를 볼 수 없는데 이런 부분도 활용하고 싶은 니즈가 있다면 충분히 반영 가능할 것 같다.
적용
Logback에는 로그 정보를 Kafka로 바로 쏴주는 라이브러리가 있다.
com.github.danielwegener:logback-kafka-appender:0.2.0-RC2
해당 라이브러리를 사용하면, 서버에서 발생하는 log 정보를 kafka로 바로 쏴줄 수 있다.
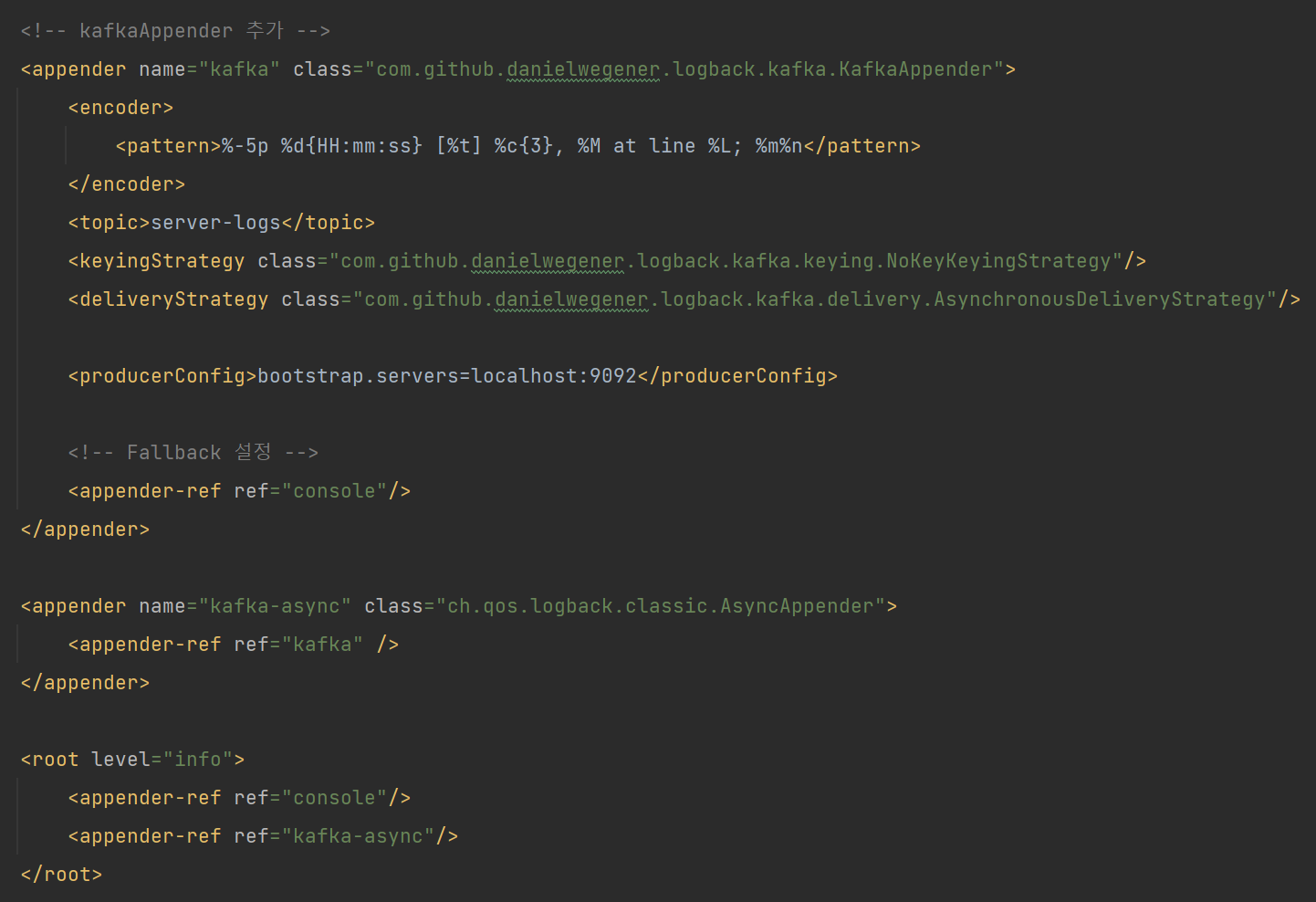
결과
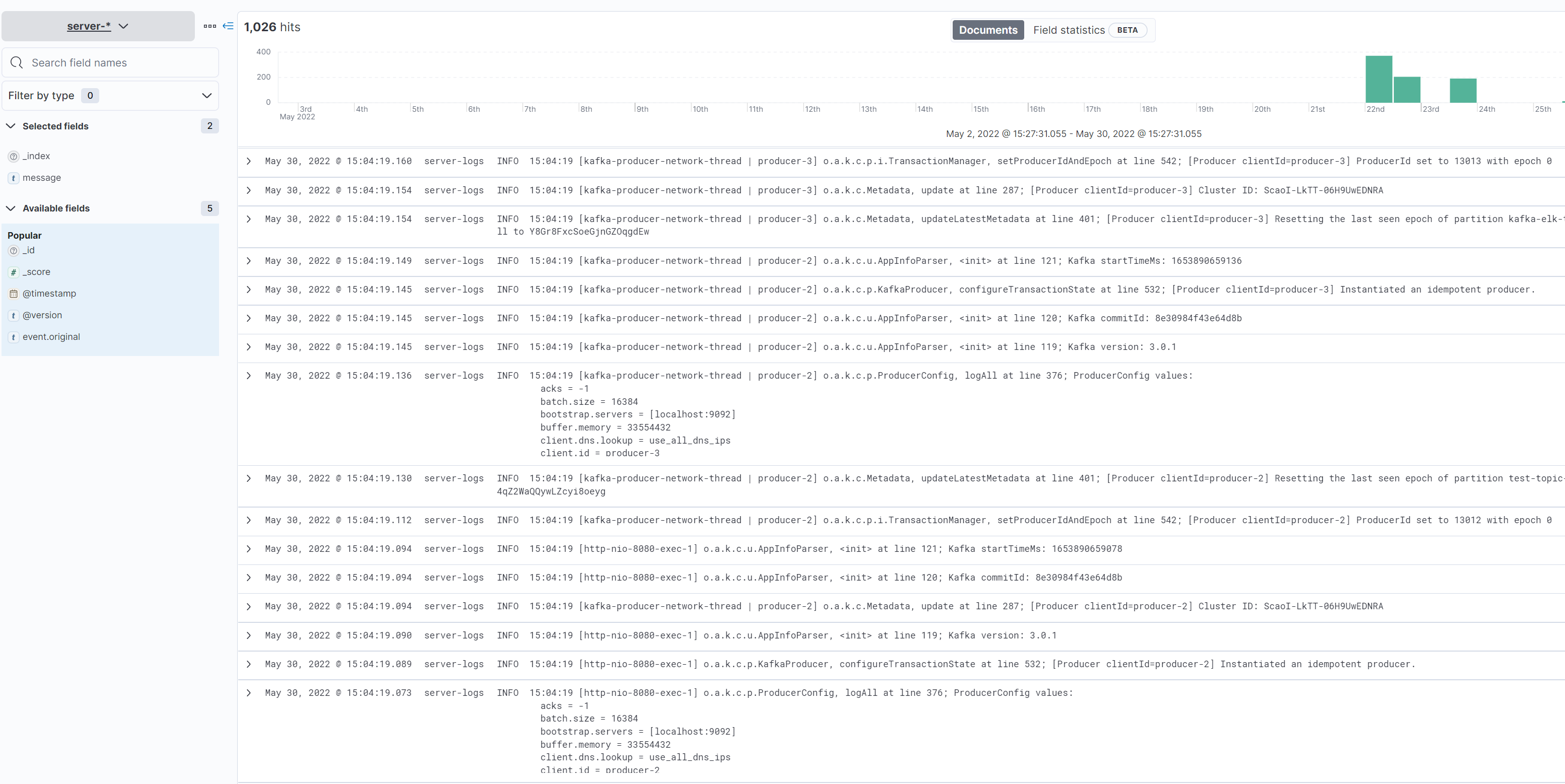
Info 레벨의 로깅 데이터를 적재한 모습
물론 위의 방법을 사용하여도 무방하지만, Logback으로 서버의 로깅 정보를 파일로 관리하게 한 뒤, FileBeats 를 사용해서 kafka로 전달하게 하는 구조도 가능하다.
구직자 행동 데이터 로깅
추후, 운영 중인 서비스에서 타 서비스 (솔버) 쪽과 연동하여 작업하려던 구직자 행동 데이터(유입 경로 트래킹)의 경우도 ELK를 활용하여 쌓도록 개발하면 좋을 것 같다.
Kafka 서버 로깅, 메트릭 로깅
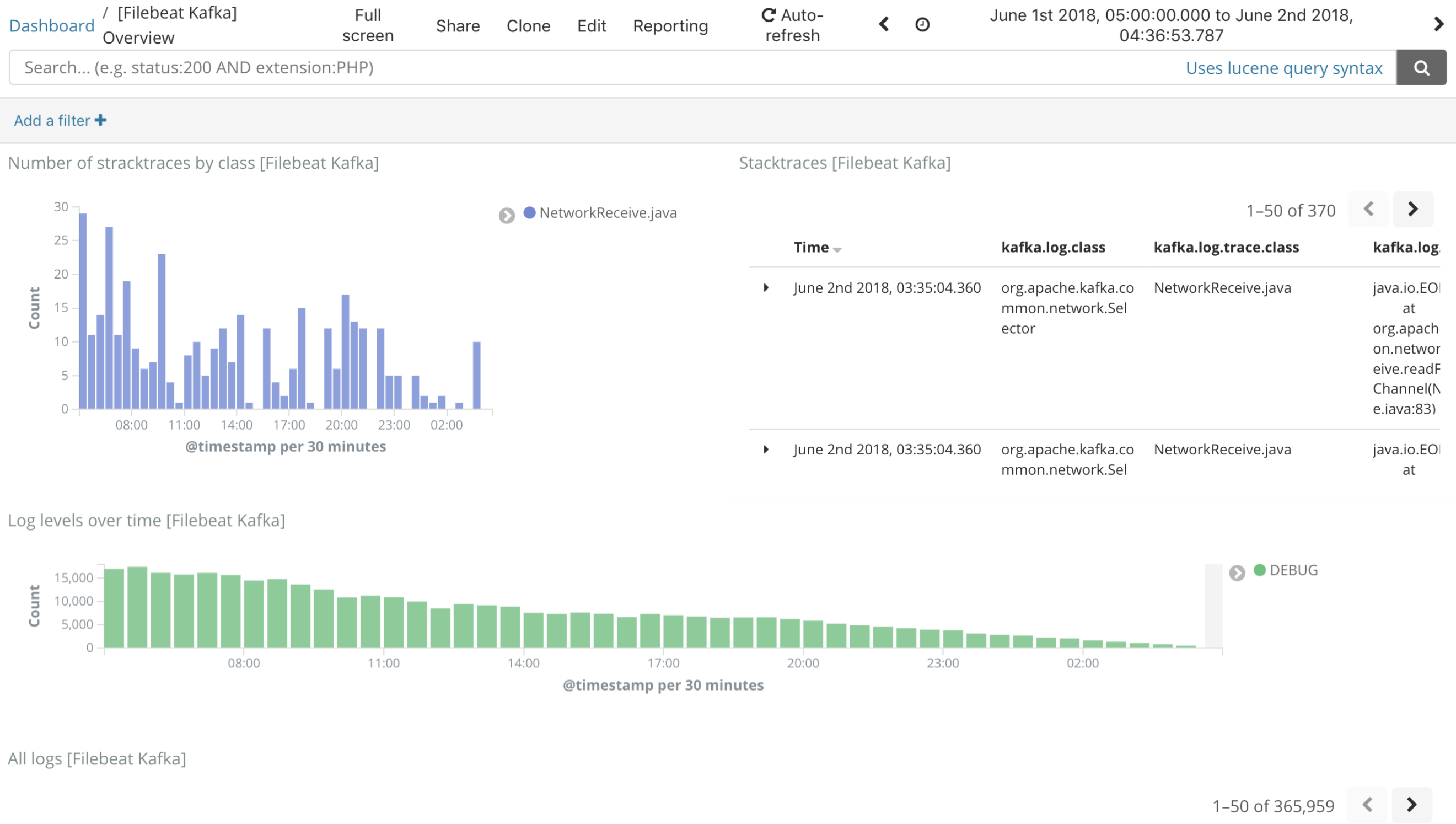
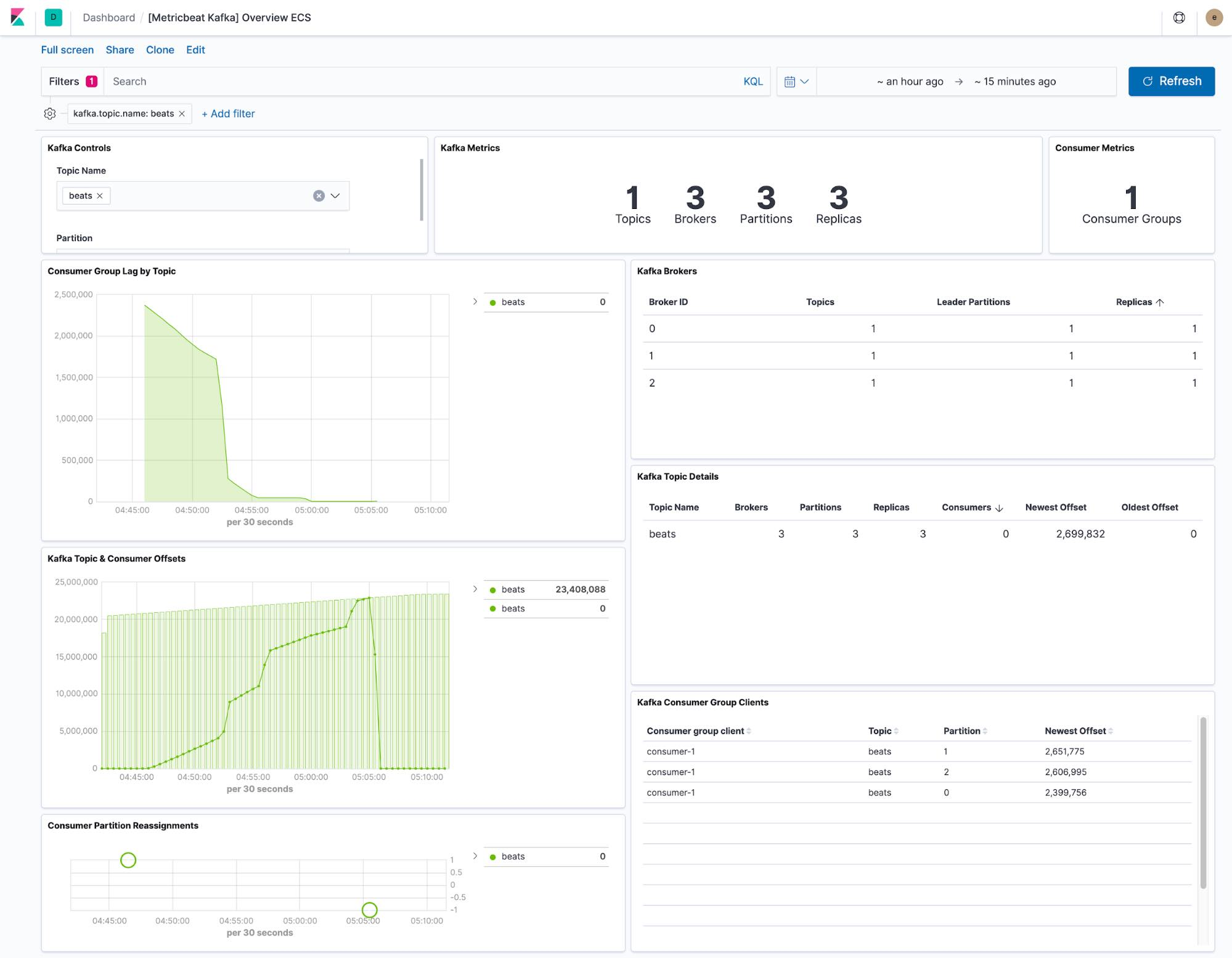
Beats의 종류인 FileBeats와 MetricBeats 를 이용하면 아래와 같이 카프카 자체 에러 로그, 메트릭도 파악이 가능하다고한다.
Kibana & Beats Integration 종류
카프카 자체 Logs
카프카 Metrics

잘 봤습니다!