
개요
Elasticsearch의 기본 개념과 특징에 대해서 간단히 알아보고 어떻게 데이터를 관리하여 검색엔진을 적용 시킬 것인지에 대해서 알아보자.
ElasticSearch 에 대하여
ElasticSearch의 기본적인 특징
Elastic 홈페이지에서는 Elasticsearch 를 Elastic Stack의 심장이라고 소개한다.
모든 데이터를 색인하여 저장하고 검색, 집계 기능을 제공하는 ELK 스택에서 가장 중요한 역할을 담당하고 있다.
특징은 다음과 같다.
- 오픈 소스 (open source)
- Elasticsearch는 자바로 코딩되어 있으며 핵심 기능들은 Apache 2.0 라이센스로 배포된다.
Elastic Stack의 모든 제품은 https://github.com/elastic 에서 소스들을 찾을 수 있다.
- Elasticsearch는 자바로 코딩되어 있으며 핵심 기능들은 Apache 2.0 라이센스로 배포된다.
- 실시간에 가까운 분석 (real-time)
- Elasticsearch 클러스터가 실행되고 있는 동안에는 계속해서 데이터가 입력되고, 그와 동시에 실시간에 가까운 속도로 색인된 데이터의 검색, 집계가 가능
- 검색이 가능해지는 시간까지 약 1초 가량의 짧은 대기 시간을 갖는다.
- 전문 검색 엔진 (full-text search)
- 일반적인 RDB와 다르게 전문 검색이 가능하도록 역색인 (inverted index) 구조로 데이터를 저장하여, 빠른 검색이 가능하다.
- 구조
- RDBMS

- ElasticSearch 검색어 토큰을 분리한 뒤 역색인 구조로 만든다.
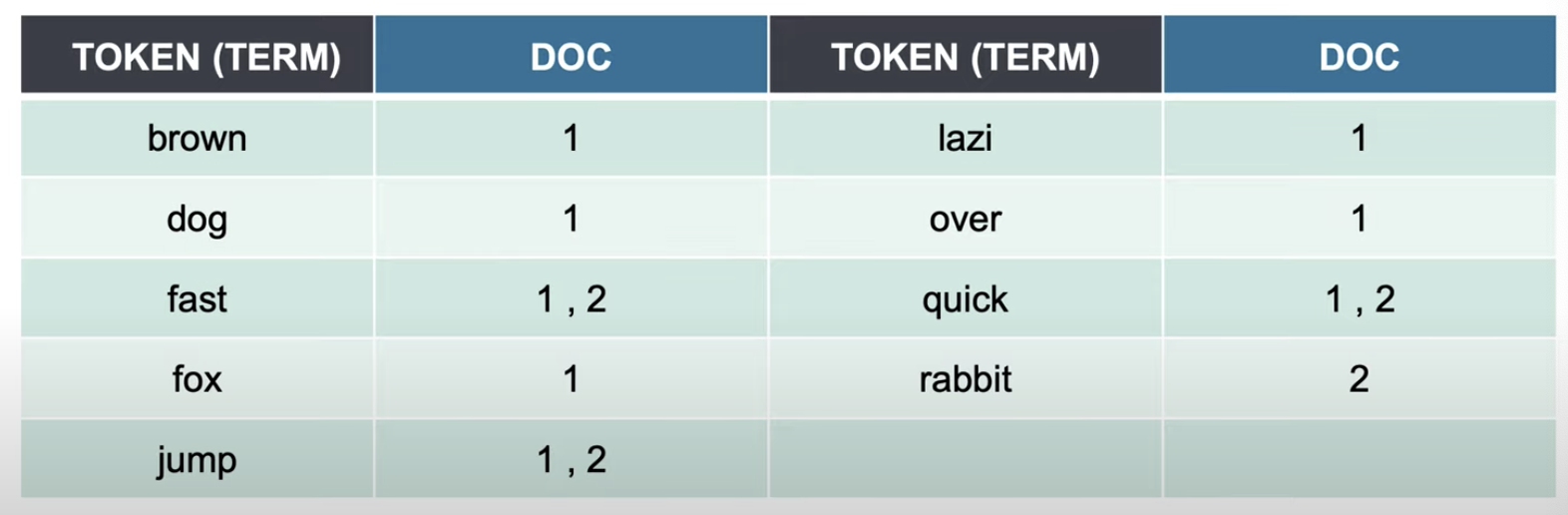
- RDBMS
- RESTFul API
- REST API와 같은 표준 인터페이스를 제공
- 데이터 조회, 입력, 삭제 등을 모두 HTTP 프로토콜을 통해서 REST API로 처리된다.
- 멀티테넌시 (multi tenancy)
- Elasticsearch의 데이터들은 인덱스(Index) 라는 논리적인 집합 단위로 구성되며 서로 다른 저장소에 분산되어 저장된다.
- 서로 다른 인덱스를 별도의 하나의 질의로 묶어서 검색할 수 있는 ES의 특징을 멀티 테넌시라고 한다.
ElasticSearch 용어 정리
색인 (indexing)
- 원본 문서들을 데이터가 검색될 수 있는 구조로 검색어 토큰으로 변환하여 저장하는 과정
인덱스 (index, indices)
- 색인 과정을 거친 실제 결과물 또는 ElasticSearch에서 도큐먼트들의 논리적인 집합
검색 (search)
- 인덱스에 들어있는 특정 검색어 토큰을 포함하고 있는 문서를 찾는 과정
질의 (query)
- 검색 시 입력하는 검색어 또는 검색 조건
ElasticSearch의 구조
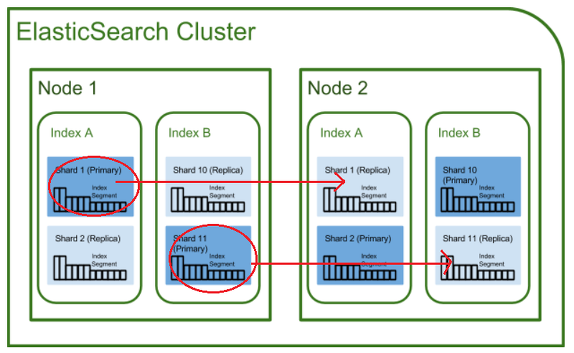
클러스터
- 클러스터는 전체 데이터를 저장하고 모든 노드를 포괄하는 색인화 및 검색 기능의 가장 큰 단위이다.
- 클러스터는 고유한 이름으로 구분되며, 물리적인 구성과 상관 없이 여러 노드가 하나의 클러스터로 묶이기 위해서는 클러스터명 (cluster.name) 이 모두 동일해야한다.
# config/elasticsearch.yml # 노드1 cluster.name: es-cluster-1 node.name: "node-1" # 노드2 cluster.name: es-cluster-1 node.name: "node-2"💡 서로 다른 서버인데 어떻게 하나의 클러스터를 이룰수 있는가?
'discovery.seed_hosts: [ ]' 라는 옵션에 설정된 네트워크 상의 다른 노드를 찾아 하나의 클러스터로 바인딩 하는 과정을 디스커버리 라고 하는데 이 기능이 클러스터 구축을 가능하게 함
노드
- 노드는 클러스터에 포함된 서버로서 데이터를 저장하고 클러스터의 색인화 및 검색 기능에 참여하는 프로세스이다.
- 일반적으로 1개의 물리 서버마다 하나의 노드를 실행하는 것을 권장한다.
- 노드는 클러스터의 상태를 저장하는 마스터 노드, 실제 데이터를 저장하는 데이터 노드로 구성됨
- 데이터들은 각 노드에 분산 저장되고 복사본을 갖기 때문에 가용중인 노드 1개가 중단되더라도 다른 노드에 데이터를 이동하여 높은 가용성과 안전성을 갖는다.
샤드
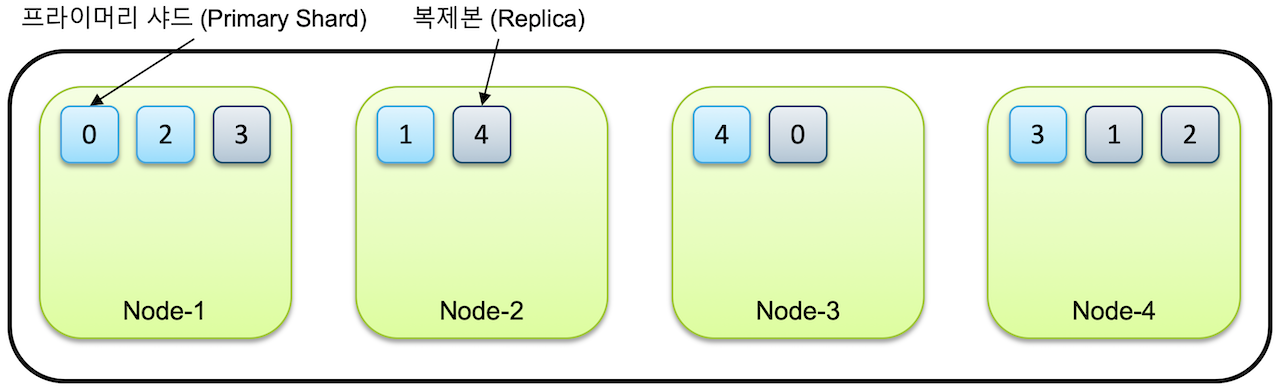
- 샤드는 검색에 사용되는 최소 단위이다.
- 각각의 인덱스는 데이터의 원본을 저장하는 프라이머리 샤드, 복사본을 저장하는 레플리카 샤드를 갖는다.
- 프라이머리 샤드가 유실될 경우, 다른 노드의 레플리카 샤드가 프라이머리 샤드로 승격되고 또 다른 레플리카 샤드가 다른 노드에 생성되어 일정한 개수를 계속 유지해준다.
- 프라이머리 샤드, 레플리카 샤드 개수는 인덱스 생성할 때 설정 가능
검색 과정
- Query Phase
- 첫 쿼리 수행을 받은 노드는 인덱스 내의 모든 샤드에게 질의를 보낸다. (라운드 로빈 방식)
- 각 샤드들은 요청된 크기만큼 검색 결과 큐를 노드로 리턴.
- 리턴된 결과는 루씬 doc id와 _score(랭킹 점수)만 가지고 있다.
- Fetch Phase
- 노드는 리턴된 결과를 랭킹 점수 기반으로 정렬 후 받은 id에 해당하는 유효한 샤드들에게 최종 결과를 다시 요청하여 전체 문서 내용을 받아온다.
마무리
ElasticSearch의 기본적인 특징과 구조에 대해서 알아보았다.
다음 글에서는 ElasticSearch와 RDB를 어떻게 동기화 시킬 것인지에 대한 구체적인 방안에 대해서 다뤄보자.

개발 블로그 📝