4. 📚전처리(Preprocessing)
1. 📘전처리(Preprocessing)란?
전처리는 넓은 범위의 데이터 정제 작업을 뜻한다. 필요없는 데이터를 지우고 필요한 데이터만을 취하는 것, null 값이 있는 행을 삭제하는 것, 정규화(Normalization), 표준화(Standardization) 등의 많은 작업들을 포함하고 있다.
머신러닝 실무에서도 전처리가 80%를 차지한다는 말이 있을 만큼 중요한 작업이다.
예를 들어 부동산 데이터를 분석한다고 하자. 집의 넓이(단위 : 평), 준공연도(단위 : 년), 층 수(단위 : 년), 가장 가까운 지하철 역과의 거리 (단위 : km)와 같은 데이터가 있다.
여기서 문제는 각각의 특성들이 단위도 다르고 값의 범위도 차이가 클 수 있다는 점이다.
이런 문제들을 해결하기 위해 정규화 또는 표준화를 사용한다.
2. 📒정규화(Normalization)
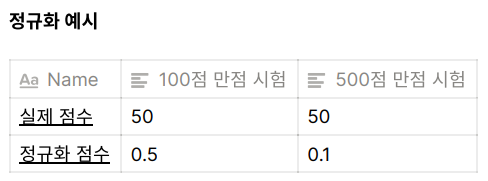
정규화는 데이터를 0과 1사이의 범위를 가지도록 만든다. 같은 특성의 데이터 중에서 가장 작은 값을 0으로 만들고, 가장 큰 값을 1로 만든다.
3. 📙표준화(Standardization)
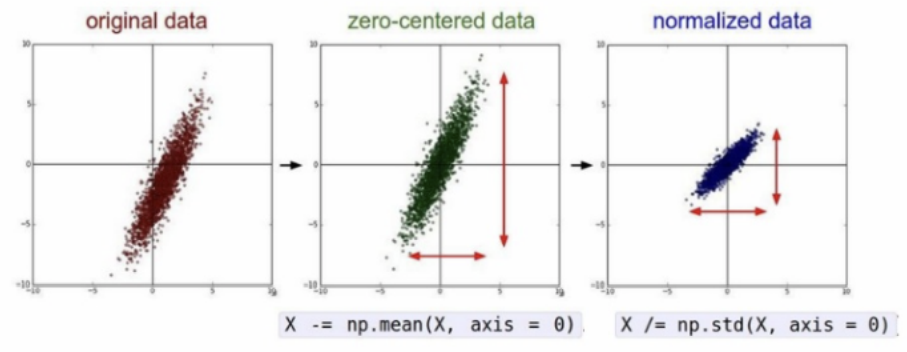
표준화는 데이터의 분포를 정규분포로 바꿔준다. 즉 데이터의 평균이 0이 되도록하고 표준편차가 1이 되도록 만들어준다.
일단 데이터의 평균을 0으로 만들어주면 데이터의 중심이 0에 맞춰지게(Zero-centered) 된다. 그리고 표준편차를 1로 만들어 주면 데이터가 예쁘게 정규화(Normalized) 된다. 이렇게 표준화를 시키면 일반적으로 학습 속도(최저점 수렴 속도)가 빠르고 Local minimum에 빠질 가능성이 적어진다.
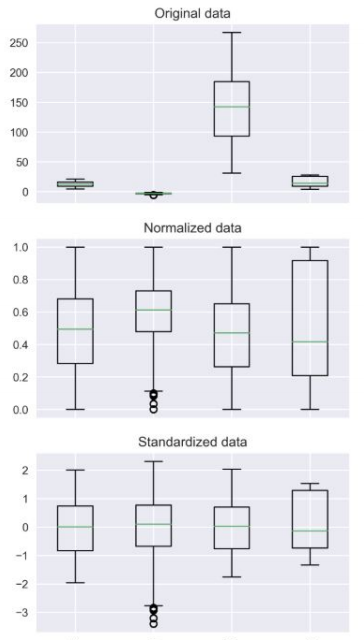
아래 그래프에서 정규화와 표준화의 차이를 대략 느낄 수 있다.