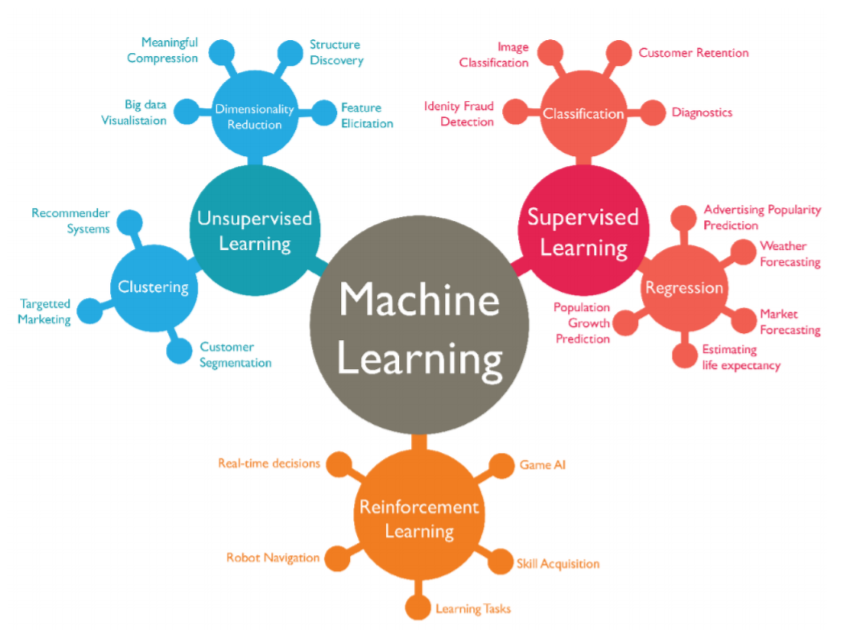
6. 📚캐글(Kaggle) 선형회귀 실습
1. 📗Kaggle이란?
Kaggle은 데이터 사이언티스트를 위한 커뮤니티이다. 다양한 데이터셋이 공개되어 있어 직접 분석해보고 결과를 공유하고 서로 비교해볼 수 있고 데이터를 가져와서 사용하는 것이 가능하다.
2. 📕Kaggle 데이터셋 다운로드 방법
- Kaggle 회원가입
- Account 페이지 진입
- API - Create New API Token 클릭하고 kaggle.json 다운로드
- 브라우저에서 json 파일을 열어 username 및 key 복사
- 아래 코드에 자신의 username 및 key를 붙여넣어 환경 변수 설정
3. 📘Kaggle 선형회귀 실습
import os
os.environ['KAGGLE_USERNAME'] = 'gommchizil' # username
os.environ['KAGGLE_KEY'] = '0365fa31094edebe20cd1c12b5d482dc11' # key👉 username과 key를 입력해 환경 변수를 지정한다.
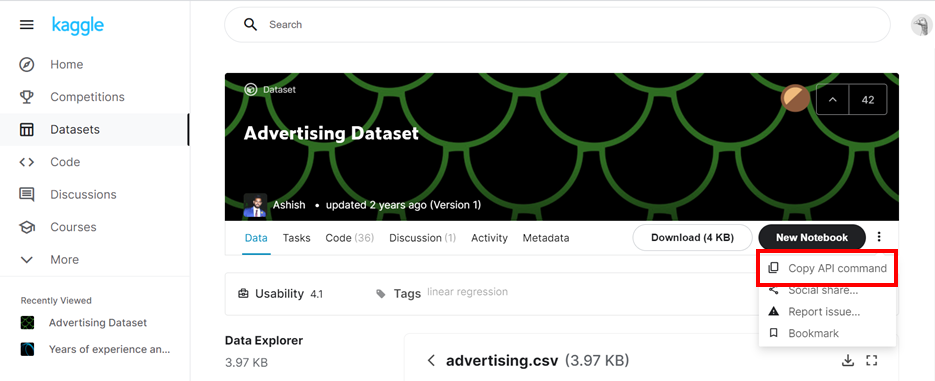
!kaggle datasets download -d ashydv/advertising-dataset👉 Kaggle에서 원하는 데이터셋(https://www.kaggle.com/ashydv/advertising-dataset)을 검색하고 [Copy API command]을 눌러 복사를 한 뒤 코드 셀에 붙여넣고 실행한다. (맨 앞에 "!" 꼭 붙여야 한다.)
!unzip /content/advertising-dataset.zip👉 데이터셋이 zip file로 받아지기 때문에 압축을 푼다. csv file로 압축이 풀리게 되는데 csv는 comma seperated value의 약자로 컴마로 구분되어 있는 값을 의미한다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split👉 필요한 라이브러리를 임포트한다.
📌
import pandas as pd : csv file을 읽을 때 사용
import matplotlib.pyplot as plt
import seaborn as sns : 그래프 그릴 때 사용
from sklearn.model_selection import train_test_split : sklearn은 머신러닝을 도와주는 패키지로 그 안에 train_test_split는 training, test set을 분리해주는 class
df = pd.read_csv('advertising.csv')
df.head(5)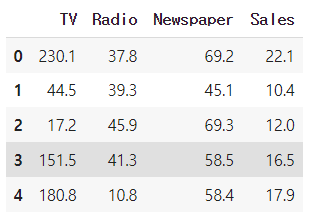
👉 advertising.csv를 df로 read하고 df의 맨 앞에서 5줄을 출력해 데이터를 확인한다.
print(df.shape)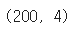
👉 데이터의 형태를 확인한다. 행 200, 열 4인 것을 알 수 있다.
sns.pairplot(df, x_vars=['TV', 'Newspaper', 'Radio'], y_vars=['Sales'], height=4)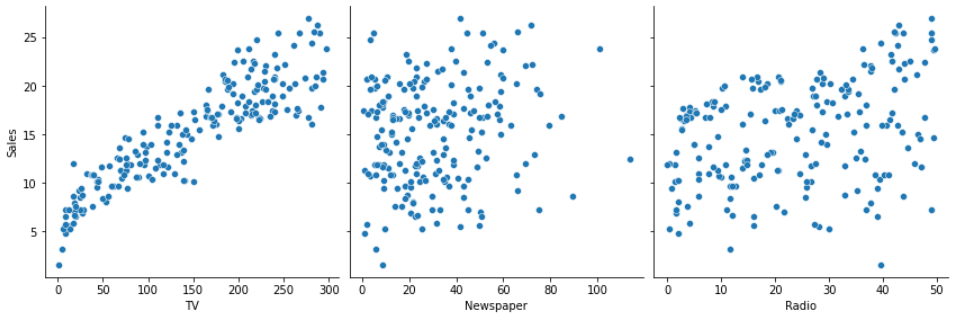
👉 위와 같이 데이터 분포를 확인할 수 있고 그 중 TV와 Sales의 관계를 선형으로 모델링할 수 있다는 것을 알 수 있다.
x_data = np.array(df[['TV']], dtype=np.float32)
y_data = np.array(df['Sales'], dtype=np.float32)
print(x_data.shape)
print(y_data.shape)
x_data = x_data.reshape((-1, 1))
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)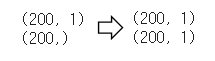
👉 데이터셋을 가공한다.
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)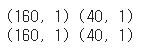
👉 데이터셋을 학습 데이터와 검증 데이터로 분할한다.
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.1))
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)
👉 100 step으로 학습을 시키고 loss가 점점 줄어드는 것을 볼 수 있다.
y_pred = model.predict(x_val)
plt.scatter(x_val, y_val)
plt.scatter(x_val, y_pred, color='r')
plt.show()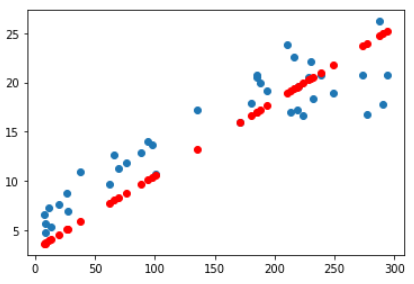
👉 검증 데이터를 넣어 예측을 한다.
