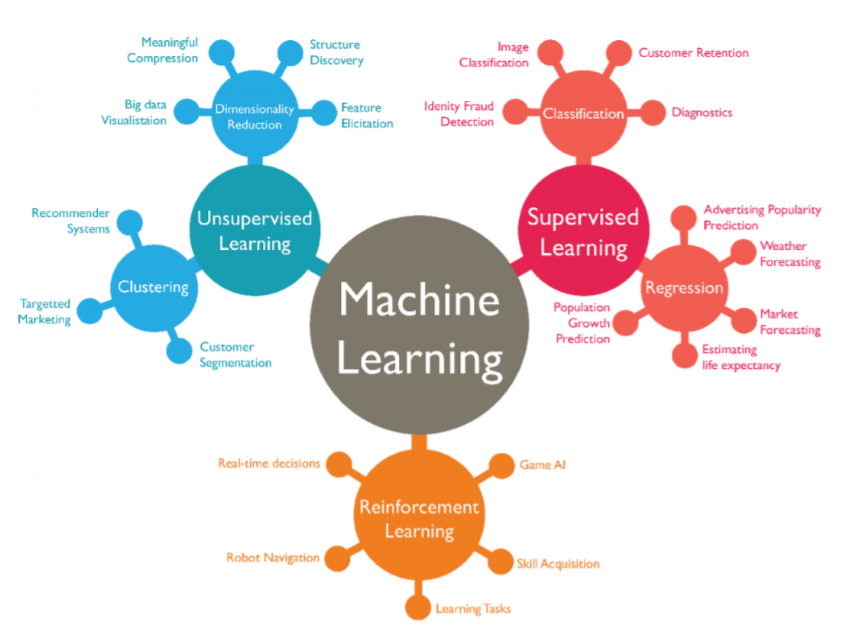
1. 📚논리 회귀(Logistic regression)
1. 📘선형 회귀로 풀기 힘든 문제의 등장
💡 대학교 시험 전 날 공부한 시간을 가지고 해당 과목의 이수 여부(Pass or fail)를 예측하는 문제
이 문제에서 입력값은 [공부한 시간] 그리고 출력값은 [이수 여부]가 된다. 우리는 이수 여부를 0, 1이라는 이진 클래스(Binary class)로 나눌 수 있다. 이런 경우를 이진 논리 회귀(Binary logistic regression)로 해결할 수 있다.
선형 회귀를 사용하는 것이 아닌 Logistic function(=Sigmoid function)을 사용하면 아래와 같이 만들 수 있다.
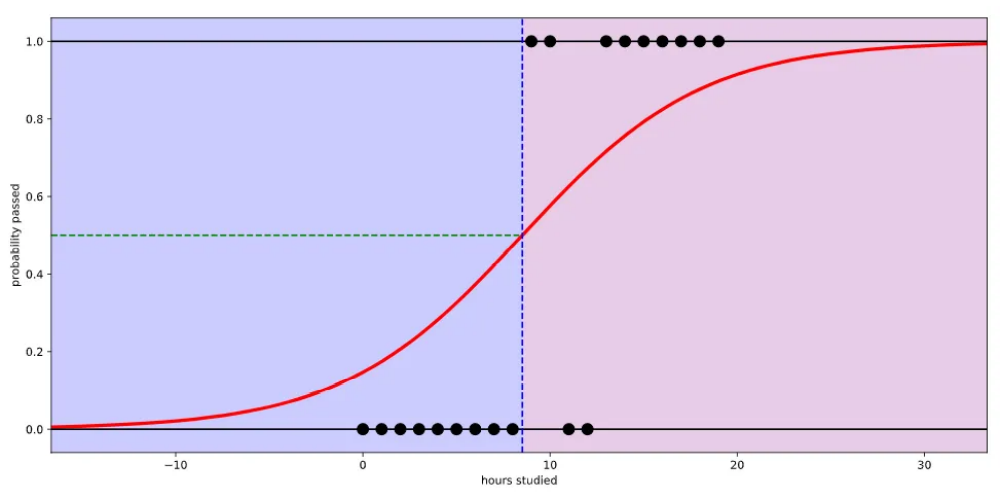
Logistic function은 입력값(x)으로 어떤 값이든 받을 수가 있지만 출력 결과(y)는 항상 0에서 1사이의 값이 된다. 따라서 과목을 이수할 확률을 0과 1 사이의 숫자로 나타낼 수 있게 된다.
2. 📙가설과 손실 함수
1. 🔎가설
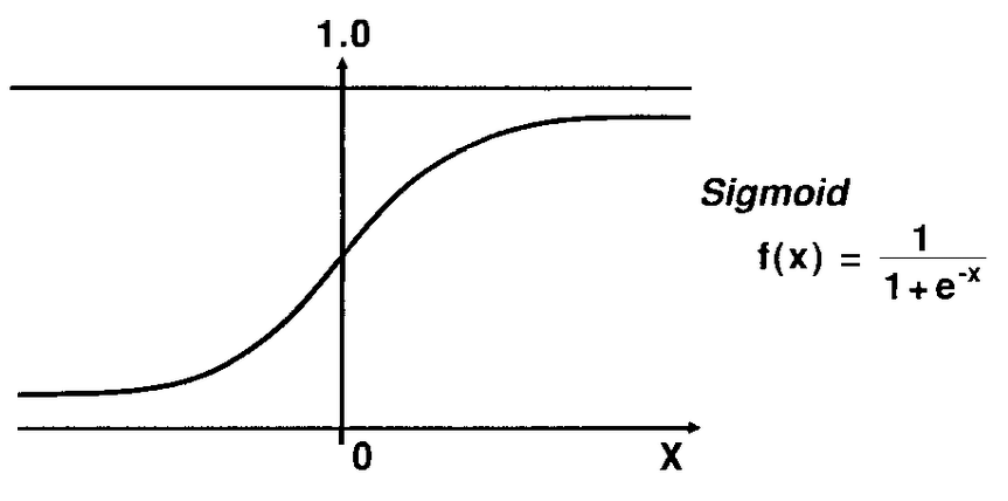
논리 회귀는 실질적인 계산은 선형 회귀과 똑같지만, 출력에 시그모이드 함수를 붙여 0에서 1사이의 값을 가지도록 변형한다. 아래는 시그모이드 함수이다.
선형 회귀에서 가설은 H(x) = Wx + b이고, 논리 회귀에서는 시그모이드 함수에 선형 회귀 식을 넣어주면 된다.
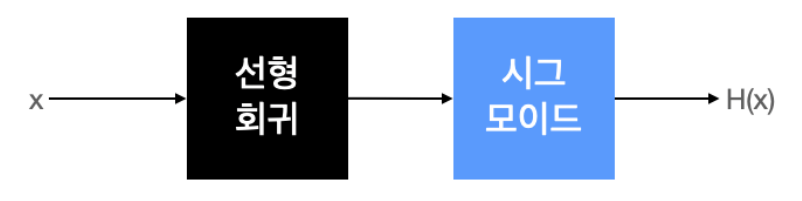
가설 :
2. 🔎손실 함수
손실 함수 :
논리 회귀에서 손실 함수는 위와 같이 어려운 수식이지만 아래와 같이 간단하게 생각해보자.
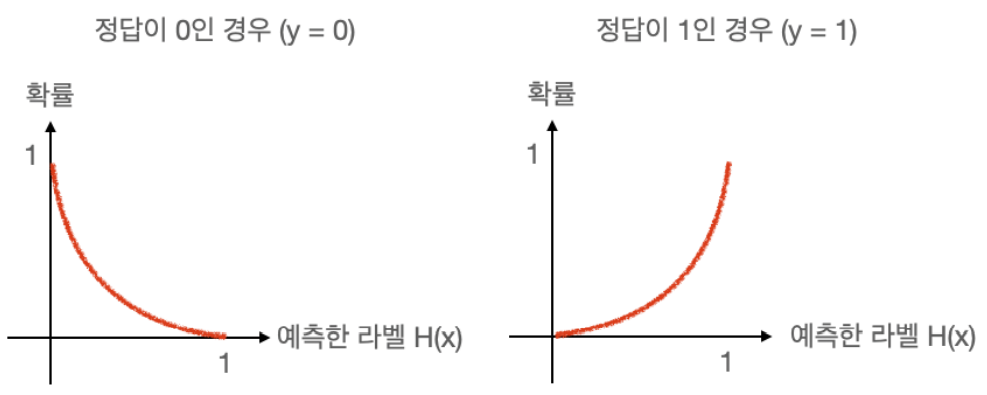
정답 라벨 y가 0 이어야 하는 경우, 예측한 라벨이 0일 경우 확률이 1(=100%)이 되도록 해야하고, 예측한 라벨이 1일 경우 확률이 0(=0%)이 되도록 만들어야 한다.
반대로 정답 라벨 y가 1일 경우에는, 예측한 라벨이 1일 때 확률이 1(=100%)이 되도록 만들어야 한다.
위 그래프를 더욱 실제적으로 그리면 아래 그래프가 된다.
📌 이렇게 가로축을 라벨(클래스)로 표시하고 세로축을 확률로 표시한 그래프를 확률 분포 그래프라고 한다.
확률 분포 그래프의 차이를 비교할 때는 Crossentropy 라는 함수를 사용하는데 임의의 입력값에 대해 우리가 원하는 확률 분포 그래프를 만들도록 학습시키는 손실 함수이다.
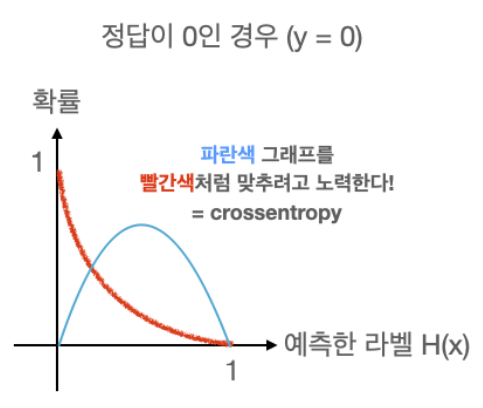
정답이 0인 경우만 살펴보면, 우리가 현재 학습 중인 입력값의 확률 분포가 파란색 그래프처럼 나왔다고 가정하자.
crossentorpy는 파란색 그래프를 빨간색 그래프처럼 만들어주는 함수이다. 우리가 선형 회귀를 했을 때 정답값을 나타내는 점과 우리가 세운 가설 직선의 거리를 최소화하려고 했던 거리 함수와 같은 개념이다.
📌 Keras에서 이진 논리 회귀의 경우 binary_crossentropy 손실 함수를 사용한다.
