SNU 강화학습의 기초 (2) DP
Dynamic Programming

- Model이 완벽하게 알려져 있는 상황을 가정함.

- MDP 문제는 전체 Optimal Solution을 부분의 Optimal Solution으로 구할 수 있음.
- Subproblem은 그 다음 Subproblem으로 표현 가능함.


Bellman expectation equation에서 Rt+1로 되어있는 이유는 그냥 t인데 t+1로 편의상 치환한 것이다. 그리고 모든 action과 해당 action을 통해 도달할 수 있는 Next State에 대해서 평균을 취한 것이다.
가장 General한 표현방식으로 stochastic하게 state가 정해진다. state가 deterministic하게 정해진다면 수행된 action에 대한 Next State가 정해진 확률부분을 제외하면 된다. 보통은 제외한다.

전 페이지 그림을 실제 수행할 때 알고리즘 형식으로 표현한 것이다. Convergence가 일어나면 수행을 멈춘다. (델타값(변화량)이 세타보다 작아질 경우)
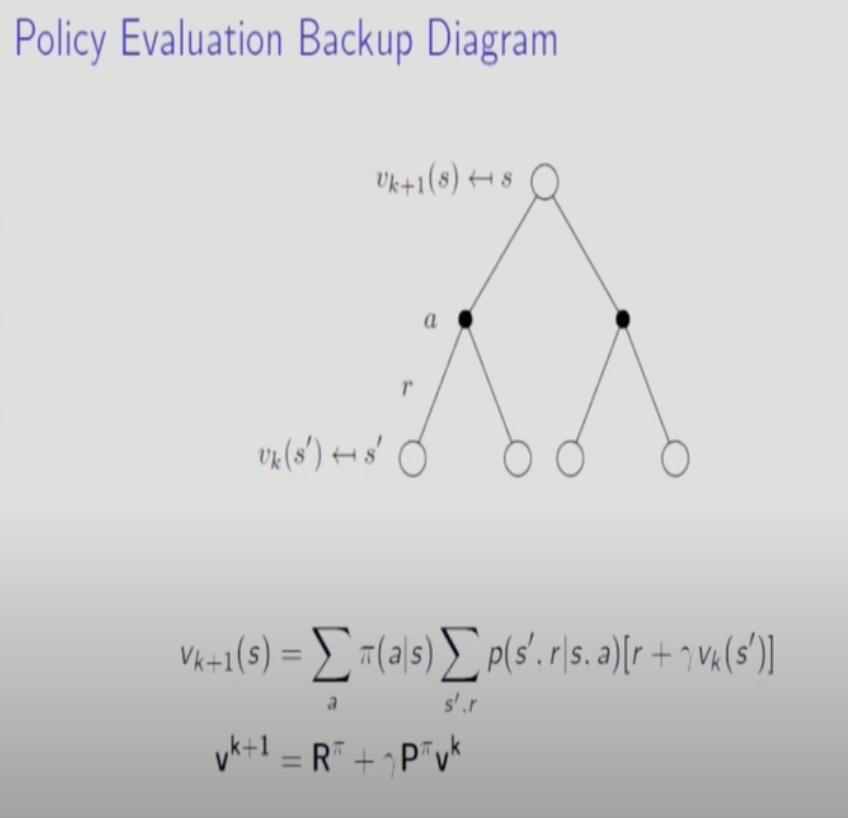
Matrix, Vector에서는 다음과 같이 표현할 수 있다.

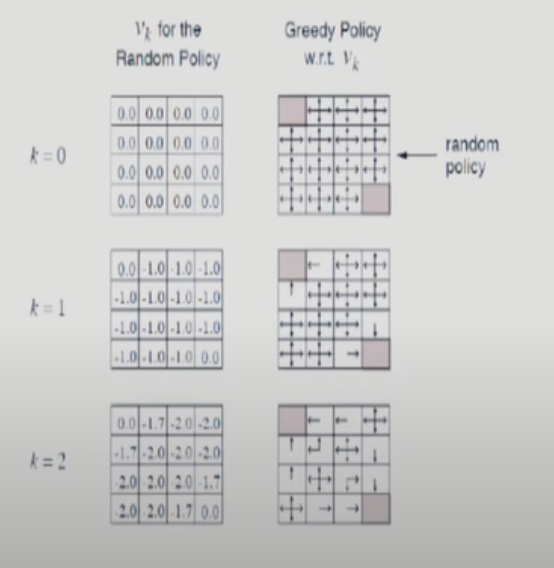
k=1 에서는 value function이 다 0이라 해당 state의 reward만 고려하면 된다. 따라서 -1이 된다.
k=2에서는 reward -1에 네방향의 value funciton들을 평균취한다. 그럼 위치에 따라 -2와 -1.75값이 나온다.

action value function에서 a를 해당 state에서 고를 수 있는 최적의 action으로만 greedy하게 고르는 방법.
하지만, 현재 state에서만 최적의 action을 고르고 그 다음 state들에서는 과거에 골랐던 policy들을 고른다(?). 따라서 엄밀히 말하면 policy가 아님. => value function을 증가시키는 것을 증명하기 쉽지 않다.
다시 말해, 현재만 새로운 policy를 쓰고 미래에는 이전에 골랐던 policy를 쓴다.

하지만 의외로 결론은 다음과 같이 간단하게 나온다.
여기서도 볼 수 있듯이, 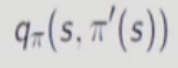
현재 state에서만 new policy를 사용하고 그 다음부터는 이전의 policy(파이)를 사용한다.

가정에 의해 파이프라임은 모든 state에서 기존의 파이 보다 더 나은 value function을 향해 움직인다. 증명은 이를 통해 되는데 계속 recursive하게 파이프라임으로 식을 표현하는 것이다. 그럼 결국 모든 state에서 파이 프라임으로 action을 취하게 되고 파이프라임에 대한 value function이 나온다.
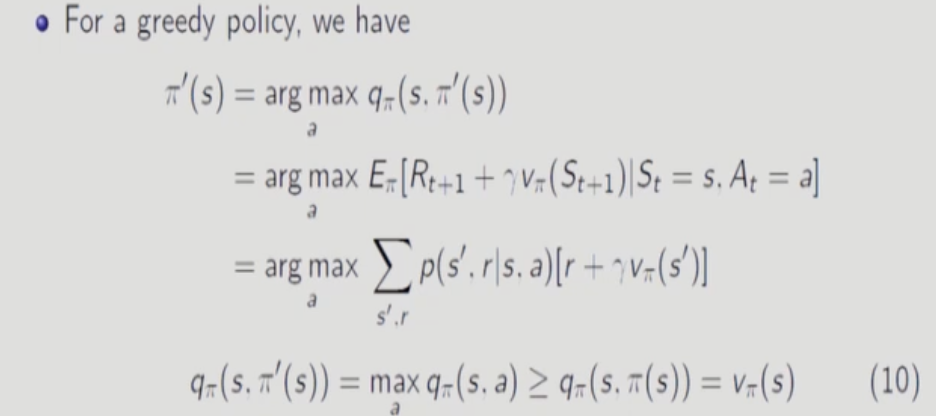
다음과 같이 증명할 수도 있다.

만약 파이프라임이 더 이상 value function을 증가시키지 않는다면 파이와 파이프라임은 반드시 optimal policy이다.
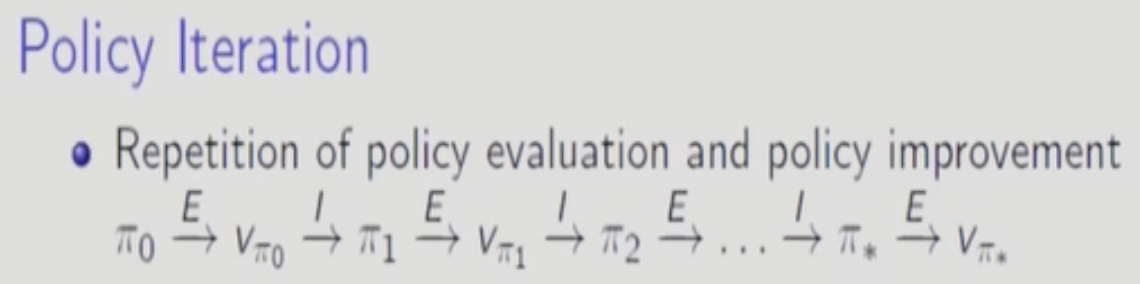
E는 Evaluation 으로 주어진 policy에 대한 exact한 value function을 계산하는 것.(대략값이 아님)
I는 Iteration으로 greedy하게 현재 state에서 제일 좋은 action을 선택해서 새로운 policy를 만드는 것

이 과정을 policy가 더 이상 안변할 때 까지 지속함.
이중 loop로 되어 있는데 안쪽 loop에서 위에서 다룬 Policy Evaluation을 policy를 improvement시킬 때 마다 계속 실행하고 바깥쪽 loop에서는 policy 를 improve 시키고 value function과 policy가 수렴할 때 까지 지속한다.
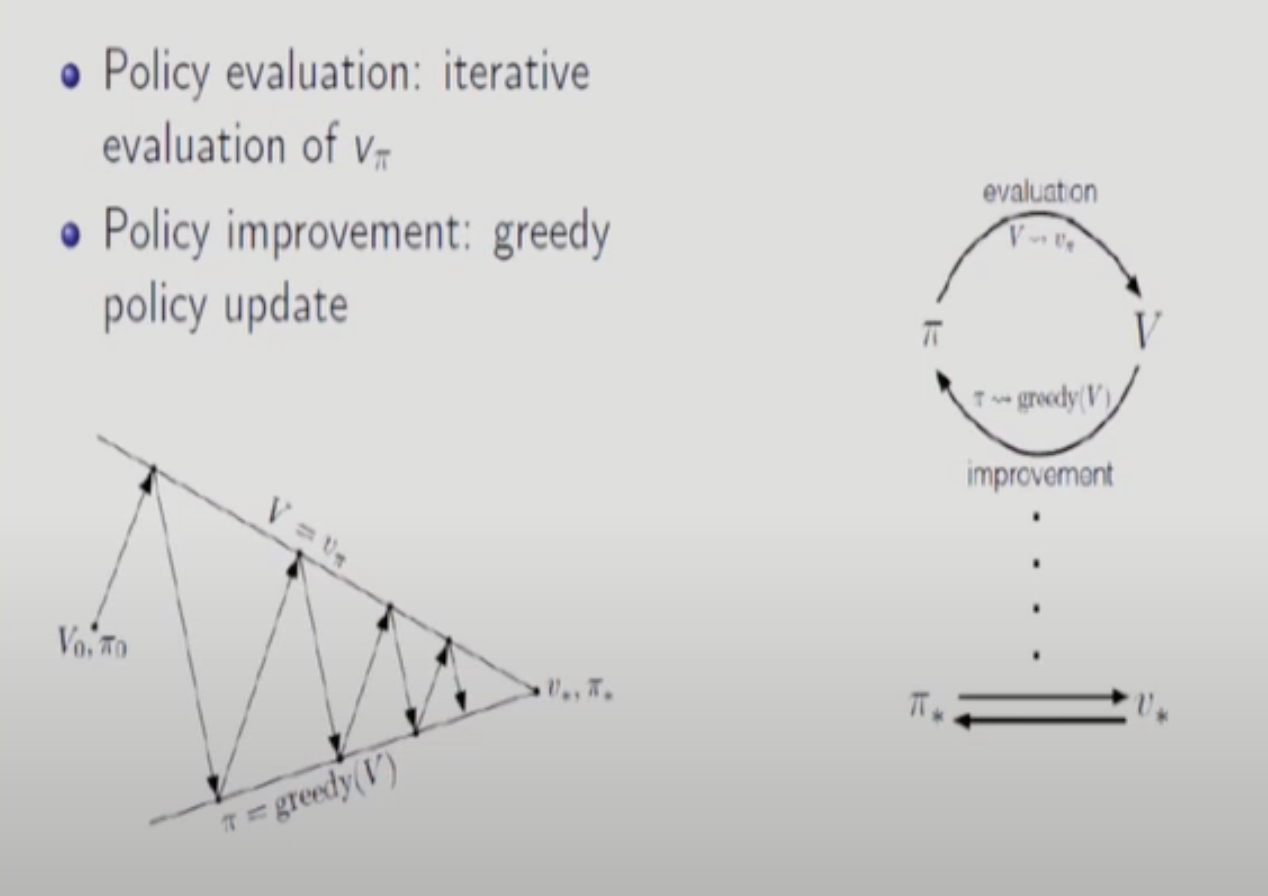
파이제로는 random한 policy라도 생각해도 무관하다.
다음 Case를 한 번 보자.

차 rental shop 예제이다. rental shop이 두 군데 있다. 돈을 가장 많이 벌 수 있게 차를 옮겨놓는 문제이다. 람다는 평균값이다. 단위시간당 차량의 요구 개수 or 반납 개수를 람다로 표현한 것. 파송distribution(?)
=> Policy Iteration으로 해결할 수 있다.
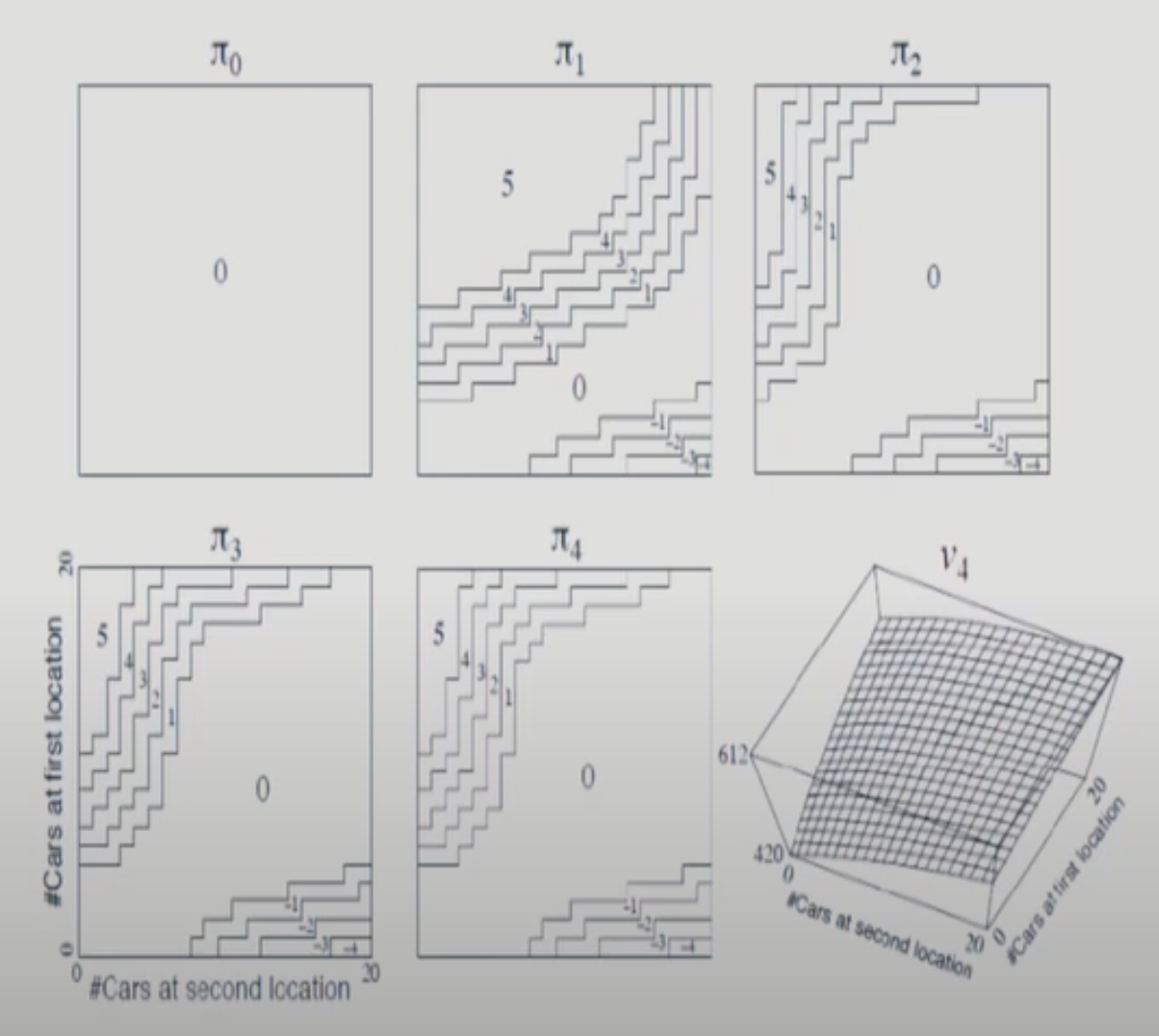
각 축은 각 location에 있는 차량의 수. 먼저, 모든 policy을 0으로 초기화 하고 시작. 각 칸에 있는 값은 policy를 의미. (a에서 b로 몇 대 옮겨라)

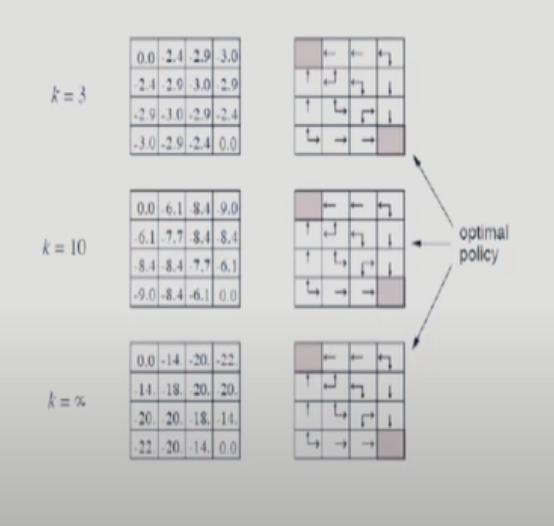
Iteration 할 때 굳이 완전히 converge할 때 까지 진행할 필요가 없다. 그래도 최종 converge policy까지 도달할 수 있다.이번 gridword에서는 3번만 진행하기로 한다.(경험적). 이후에 배우는 value iteration에서는 한 번만 돌리기도 한다. value iteration은 policy iteration의 부분집합이다.
이를 테면, 다음 그림에서 k=3까지만 진행하는 것이다.
value iteration

One step Backup만 하는 알고리즘.
Backup: 다음 시점의 모든 가능한 markov process를 확률적인 것 까지 고려해서 평균 취한 것.

위 value iteration에 대한 알고리즘.
일단, 지금까지 계속 다룬 iteration은 converge하는 것이 수학적으로 증명되었다.

현재 state n개에 대해 다음 state n개를 고려하므로 state value function에 대해서는 iteration 계산이 mn제곱이고 action value function에 대해서는 iteration 계산이 m제곱n제곱 걸린다. n이 400이라 할 때 한 iteration에 대해서 16만m걸리는 것이므로 좋은 방법이기는 하지만 쓰기가 어렵다.
하지만 현재까지 알려진 방법으로는 최선의 방법이다. 왜냐하면 polinomial한 시간에 계산되기 때문이다.
이러한 문제점을 어떻게 해결할 것인가?? => 최근에 연구되는 강화학습의 Key Point 이고 지금부터 배울 내용이다.
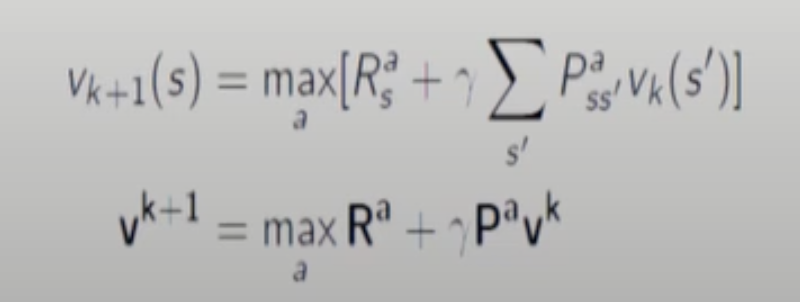
메모리적으로 말하자면 Vk와 Vk+1은 아예 다른 value function으로 각각 따로 저장해놔야 한다. (synchronous)
근데 결국 Vk보다 Vk+1이 더 좋은(수렴에 가까운)Value function이니까 중간에 Vk를 Vk+1에 의해 업데이트 하는 방식도 있다.(asynchronous)
Asynchronous DP(Inplace DP)

이 전에 배운 DP는 모두 synchronous방식이다. asynchronous에서는 synchronous방식과 달리 메모리 공간을 V하나에 대해서만 쓴다. Inplace는 메모리를 공유한다는 의미이다.
Real time DP
Inplace와 비슷한 개념이 Real time DP이다. Inplace를 좀 더 일반화시킨 개념. => value function이 policy를 구하는데 필요하지 않다면 굳이 안구하는 방식.
무수히 많은 state가 있는 경우 실제로는 잘 안지나가는 state들이 있는데 얘네들은 이후에 구하게 될 policy에 별로 영향을 주지 않는다.(에피소드) 그래서 안지나간다. 선호하는 state들만 지나간다.
=> 모든 현대적인 강화학습 방법론은 Real Time DP에 기초를 둔다.
Sample Backup

random하게 action을 여러번 진행해서 평균값을 취해서 value function을 업데이트. 장점은 다음 세 가지 이다.
1) 모델을 몰라도 된다.
모델은 다음 두 가지 컴포넌트를 포함한다.
(1) 리워드가 어떻게 발생하는지 안다.
(2) transition probability를 안다. P(S|a)2) 샘플링을 통해 dimension의 저주에서 벗어난다.
=> 현재 state에서 랜덤하게 몇 개만 해본 거니까. 한 번 Iteration할 때 시간이 걸리지만(블랙잭으로 예를들면, 게임이 끝날 때 까지 해야되니까) 계산이 심플해진다.
Value Function Approximation

V(s)에서 s의 크기가 Bottle Neck이라 할 수 있다. state가 continuous하거나 discrete하지만 무지 크면 사실상 정확한 값을 구하는 것(튜블라 메소드)은 불가능 하다. 따라서 근사치를 구한다.
w는 dnn이다. value function을 w을 사용하여 approximate 한 것을 v햇으로 표현한다.
s틸다(물결)는 s의 부분집합이고 v틸다는 일부 state에 대해서만 적용된 approximation이다.

실수공간에 있는 sequence일 경우 어떤 함수가 Cauchy Sequence이면 해당 함수는 무조건 수렴한다.
하지만 이걸 임의의 vector space인 normed vector space로 확장하면 항상 성립하지 않는다. normed vector space중 cauchy sequence를 만족하는 vector space를 complete하다고 하고, Banach Space라 부른다.
Norm
- ||v|| = 0 이면 그 벡터 v는 0 이다.
- ||스칼라v|| = |스칼라|||v||
- ||u+v|| <= ||u|| + ||v||

리프시츠 정의: normed vector space V에 대해 V -> V 로 정의된 함수 T가 위 조건을 만족할 때 T를 L-Lipschitz라 부른다.(L은 상수)
- L이 1보다 작으면 T를 L-contraction라 부른다.
- T가 리프시츠이면 T는 continuous하다.
=>어떤, 함수 T가 continuous하면 lim(t Vn)은 t lim(Vn)과 같다. lim 밖으로 빠져나올 수 있다.
Fixed Point는 Model이 수렴하는지 안하는지 정하는데 사용되는 아주 중요한 개념이다. Tv = v이면 v를 T의 fixed point라고 부른다.

Banach space이므로 Cauchy이면 무조건 수렴한다. 그리고 이 수렴하는 지점이 Fixed Point가 된다. 우리는 해당 함수 T가 Cauchy임을 보여서 이를 증명한다.
일단, 밑에 (Proof)는 가정에 의해서 풀이된 것이다.
- Vn = TVn-1이고(1번쨰줄)
- 감마-contraction이므로 T가 밖으로 나오면서 부등호가 생긴다.
이 과정을 계속 반복하면 마지막 줄과 같은 형태가 된다.

1->2: Vk - V0를 Vk - Vk-1 + Vk-1 + ... + V1 + V0로 표현하자. 그러면 ||u+v|| <= ||u|| + ||v|| 이 정의에 의해 1->2가 된다.
2->3: 감마-constraction성질에 의해 다음과 같이되고 등비수열의 합 공식에 의해 다음과 같이 된다.
이걸 앞 페이지의 정의와 합치면 해당 부분이 나온다.

그리고 Vn+1 = TVn에 양변에 lim 씌우면 위에서 구한 사실과 가정에 의해 v는 Fixed Point가 된다.
fixed point의 unique함은 서로 다른 Fixed point가 있다고 가정하면 모순이 생겨서 증명이 된다.

정의에 의해 간단하게 증명된다.

Policy Iteration과 Value Iteration에 위에서 배운 이론을 적용 및 증명할 것이다.
Bellman Expectation Equation을 수행하는 Operator T파이를 정의한다.
추가로, T파이가 감마-contraction임을 보일 수 있다.
=> fixed point threome을 증명하자.

T파이를 적용하는 각 step이 policy evaluation과 같다.
앞의 Bellman Expectation Equation과 다른 것은 action을 greedy하게 고르는 점이다.
- Policy(Value) Evaluation은 Belman Equation을 무한번 적용하는 것
밑에 감마-contraction에서 사용되는 정의 ||U||무한대 = max s|U(s)|

Greedy한 Update(현 시점의 state에서만 action을 수정하고 미래 시점에는 이전 policy 그대로 사용)가 Value Function을 증가시킴을 다른 방법으로 확인.
앞에서 policy evaluation이 감마-contraction임을 보였으므로 fixed point가 존재한다.(Greedy Policy이므로 앞의 Policy Evaluation과 같아진다) 그리고 그 fixed point는 optimal point가 된다.
증명) V파이 <= V스타 는 수학적으로 엄밀하지 않다. 여기서 벡터끼리의 부등호는 벡터의 모든 element에 대해서
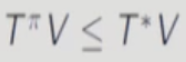
위의 부등식을 만족함을 의미한다.
정의를 사용해서 증명하는데 알 필요는 없어보인다. 포인트는 policy evaluation이 fixed point로 수렴한다는 것이다. 그리고 T*(Bellman optimality operator)를 적용하면 V값은 커진다는 것이다.

어떤 Policy 파이제로에 대해 T*을 적용할 때 V파이제로가 같은게 아니라 strictly 하게 커진다면 V파이는 V파이제로보다 크다. 이 뜻은 진짜로 해당 state에서는 Bellman Optimal Equation에 의해 Value Function이 증가한다는 것이다. 그리고 V가 fixed point에 다다르면 V는 T의 Fixed Point가 된다.


