SNU 강화학습의 기초(2) MC, TD

MC는 몇 개 랜덤으로 뽑아서 그 Policy를 평가하는 방법이다. 하지만 해당 게임을 다 끝내기 전에 Policy를 Update할 수 없다는 단점이 있다. TD가 이를 보완한 것이다. (다듣고 다시 쓰자)

S1 A1 R1 -> S2 A2 R2 -> ...
이런게 한 Episode이다. 일단, 유한한 State이라 하자. 이 중에서 State E가 있을 수 있다.
First-visit MC이면 처음 E state를 방문한 이후로의 Reward를 계산하는 것이다. 그리고 전체 Episode로 평균을 내는 것이다.
Every-visit MC이면 각 Episode에 방문한 모든 E state의 Reward의 평균을 계산하는 것이다.
Episode간에는 State가 독립적이지만 같은 Episode에서 여러번 나온 E state끼리는 독립적이지 않다. 따라서 Every-visit MC의 증명은 매우 어렵다. 실제로는 Every-visit 이 더 유리하다.

Value Function은 기댓값이었다. MC에서 Value Function은 기댓값이 아니고 경험적인 값이다. 예를 들어,

위의 문제에서 기존의 Value Function은 기댓값이므로 모든 방향을 다 고려했지만, MC에서는 random하게 action을 선택해서 그 값의 평균을 취하는 것이다,

N이 무한대로 가면 수렴한다.
Every-visit은 여기서 두 번째 줄만 다음과 같이 바뀐다.

블랙잭을 예를 들어서, MC의 장점을 설명한다. => 모델이 없어도 계산 가능하다.

DP는 Value Iteration을 사용하여 One-step진행으로 Value function을 평가하고 Policy Update가 가능하다. 하지만 모델이 필요하다.
이에 비해서 MC는 모델이 필요없고 실제 시뮬레이션하면서 그 경험을 토대로 모델을 발전시킬 수 있다. 또한 특정 state에 대한 Value Function을 구하는데 특화되어 있다. Bellman Equation에서는 state간의 연결고리가 있어서 계산과정이 복잡하다.(DP에서는 다른 state의 V를 통해 현 state를 update했다) MC는 이런게 없음.

MC를 Action Value Function에도 적용해 볼 수 있다.
Bellman Equation에서는 V만 알아도 모델을 알고 있기 때문에 Optimal Policy를 구할 수 있다. 하지만 MC는 모델을 모름으로 V보다는 Q를 아는 것이 훨씬 유리하다. Q(S,a)
Q를 알면 a에 대해서 뭐가 최대가 되는지 알 수 있다. 그런데 여기서도 문제가 있다. Optimal Policy를 구하려면 일단, 모든 state에서 모든 action에 대한 Q를 알아야 하는데 MC에서는 경험한 S,A쌍에 대해서만 Q를 구할 수 있다. 또한 A가 이때 까지 이론에 따르면 S에 종속되는데 이걸 풀어서 stochastic한 A를 취해야 더 좋은 Q를 구할 수 있다. 즉, Exploration해야 한다.
딜레마 => Optimal Policy는 Deterministic한데 Data를 General하게 만들기 위해서는 Deterministic한 Policy를 쓰면 안된다. => Balance가 중요.
일단, MC만 써서는 Optimal Policy로 수렴하는지는 증명되지 않았다.
- Policy를 찾아내는 문제 => Control
- Value Function을 찾아내는 문제 => Prediction
* Optimal Policy가 주어질 때 한 state에 대해 한 action만 취하면 된다. 여러 action을 확률적으로 취할 필요가 없어진다.

위에서 말한 딜레마(초반부터 Deterministic를 쓰면 탐험이 안 일어나는 것)는 off Policy를 쓰면 자연스레 해결한다.
Deterministic Policy의 반대는 Stochastice Policy인데 이 Policy의 special case가 Soft Policy이다. state에서 모든 가능한 action에 대한 확률이 0 초과인 Policy이다.
On policy로 위의 딜레마를 해결하려면 1대99 정도로 희박한 확률로 Explore를 하면서 Nondeterministic을 유지하며 Deterministic에 가까이 가면 된다.
On Policy => Behavior Policy = Target Policy
Off Policy => Behavior Policy != Target Policy
Off Policy는 두 Policy를 함께 쓰는 것인데 하나는 exploration하고 하나는 Optimal Policy 찾는 용이다. Off Policy는 더 General하게 쓰일 수 있고 Powerful하지만 수렴에 더 오래 걸린다.
Importance Sampling => 더 쉬운 확률 분포로 바꿔가지고 평균을 다시 취하는 방법론.
Importance Sampling를 가지고 Off Policy에서는 Behavior Policy와 Target Policy를 업데이트한다.

Off Policy에서 확률을 계산할 때 Target Policy와 Behavior Policy 의 비율을 곱해줘야 한다.
필기체 T는 State가 발생한 모든 시간의 집합이고 T는 현재 시간 t로부터 끝나는 시간이다.
Importance Sampling을 통해 V를 계산하는 법을 보자. 그냥 계산하면 Behavior Policy와 Target Policy의 차이가 클 경우 Variance가 너무 커진다. (분자가 엄청 크거나 작아짐) 이 방법을 해결한 것이 Weighted Importance Sampling이다. Weighted Importance Sampling은 Optimal Policy로 수렴하는 게 수학적으로 보장되지는 않는다. 하지만 Variance가 어느정도 작아진다.(분자 분모가 같이 움직이므로)
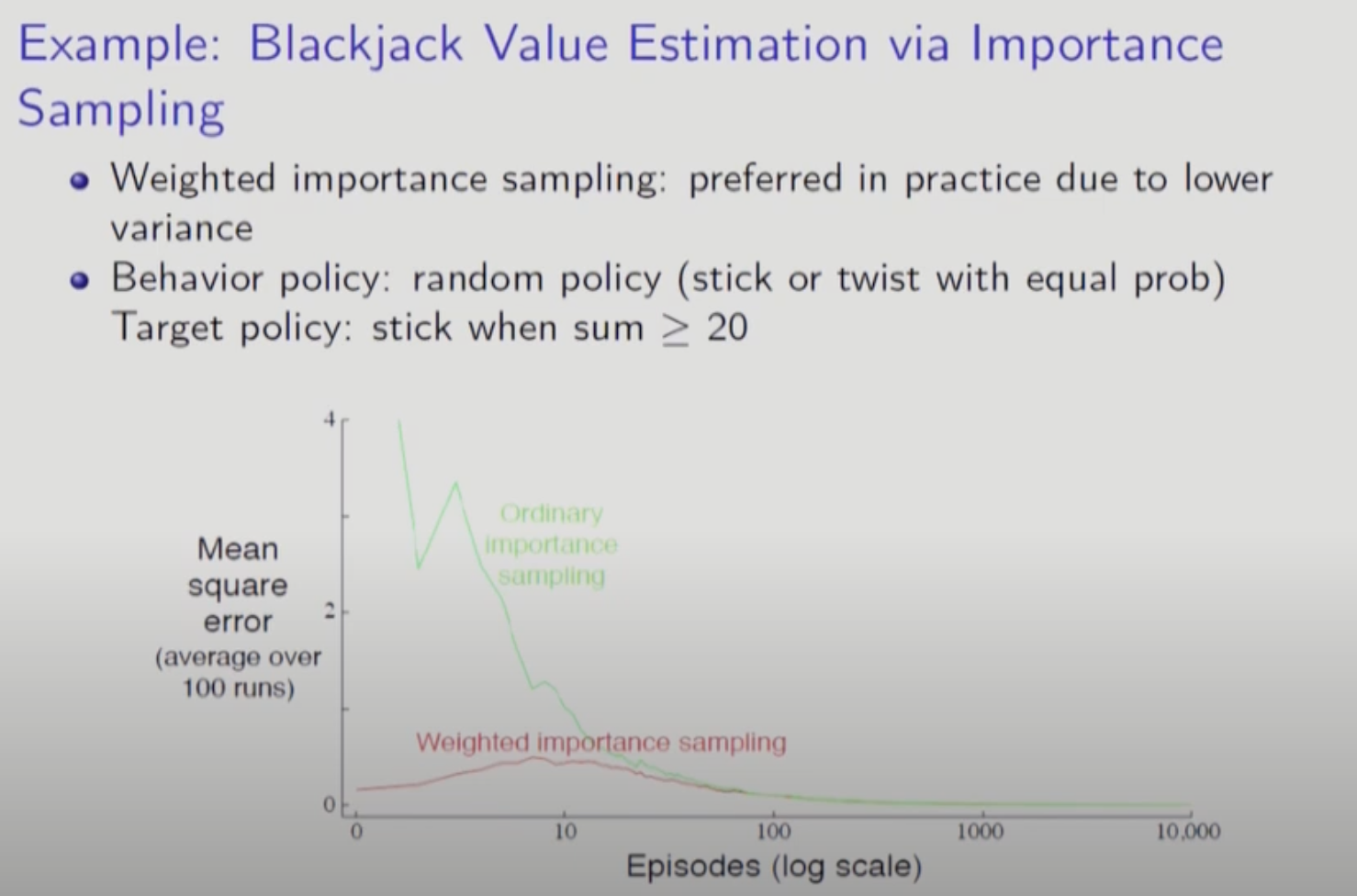

다음 장에서 Temporal Difference를 배울건데 위의 수식을 알아야 한다. 샘플군에 샘플 하나 추가해서 평균 구하는 방식.
이거랑 위에서 배운 Weighted Importance Sampling 방식을 사용한다.

DP와 MC는 정반대에 있는 학습 방식이라 볼 수 있다. DP는 실제로 Simulation을 해볼 필요가 전혀 없다. 모델을 사용한 수학적인 계산으로 Policy를 추론해 낸다.
하지만 현실에 있는 대부분의 문제는 모델이 없거나 있어도 수학적으로 활용하기 힘들정도로 복잡한 모델이 대부분이다. 모델이 없는 상황에서 실제 실행을 통해 학습을 진행하는 MC가 현실에 더 유용한 학습법이라 할 수 있다. Incremental MC update를 보면 Gt는 실제로 실행을 해봐야 얻을 수 있는 값이다. 즉, 끝까지 수행해야 얻을 수 있는 값으로 MC는 실시간 업데이트(Online Update)가 불가능하다. => Offline Update
TD는 MC와 DP를 섞은 방식이라 볼 수 있다. MC는 Gt 대신에 한 번 실행했을 때의 Reward와 Value Function을 사용한 것이다. 정확하게는 한번 실행했을 때의 평균을 구해야하지만 여기서는 한 번 수행한 값을 사용한다. 이게 One-Step TD이다. TD도 수렴함이 수학적으로 증명되어있다.

MC Error는 TD Error을 다 discount factor 곱해서 더한 것과 같다.
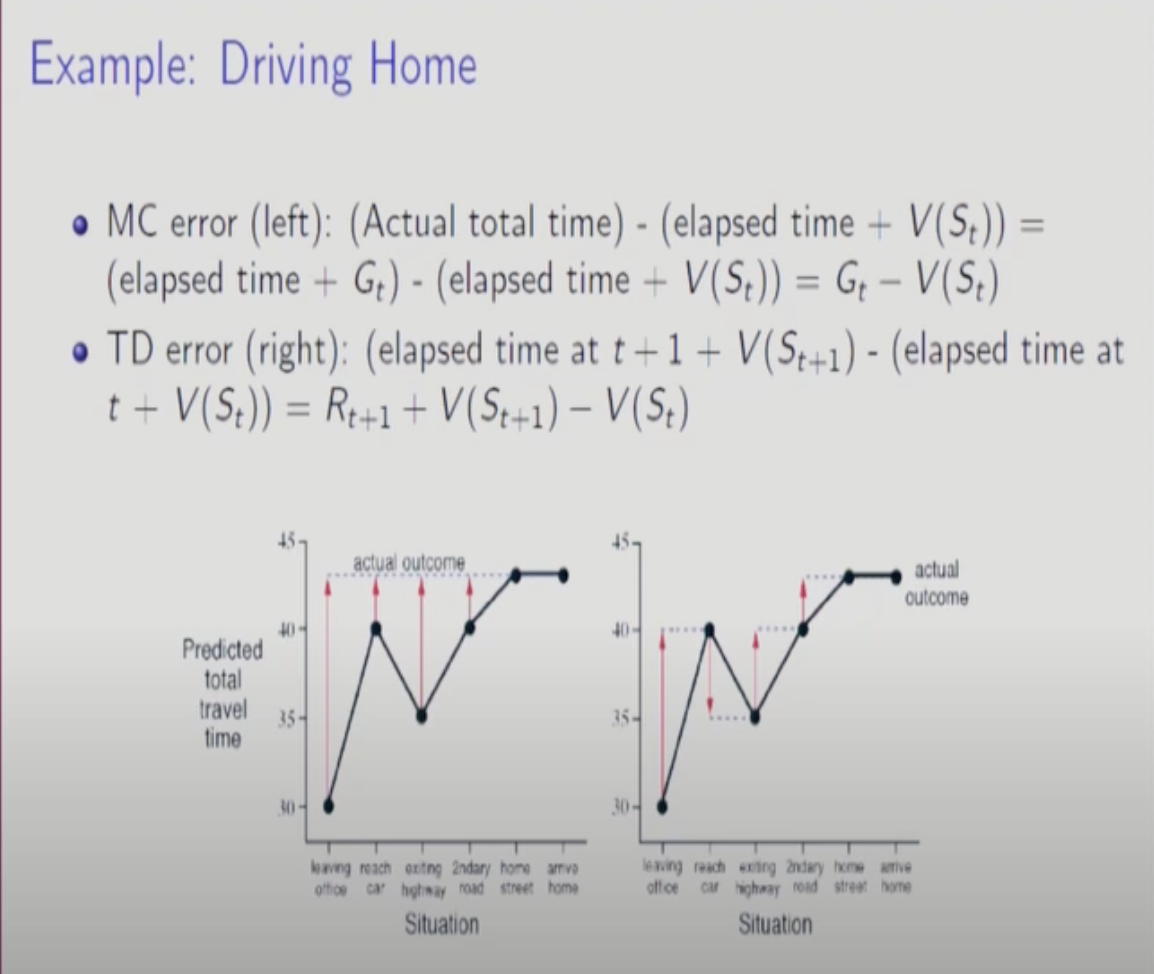
MC는 한 에피소드가 다 끝나야 업데이트 하고 TD는 state가 바뀔 때 마다 업데이트를 한다.

끝이 없는 문제 (주식투자) 같은 경우에는 TD를 사용해야 한다.
MC는 variance가 크고(끝까지 다 더하니까) bias가 적다. TD는 반대다. MC가 이론적으로는 수렴도 쉽지만 실용적으로는 사용하기 힘들다. TD가 MC보다 실험적으로 더 빨리 수렴한다.
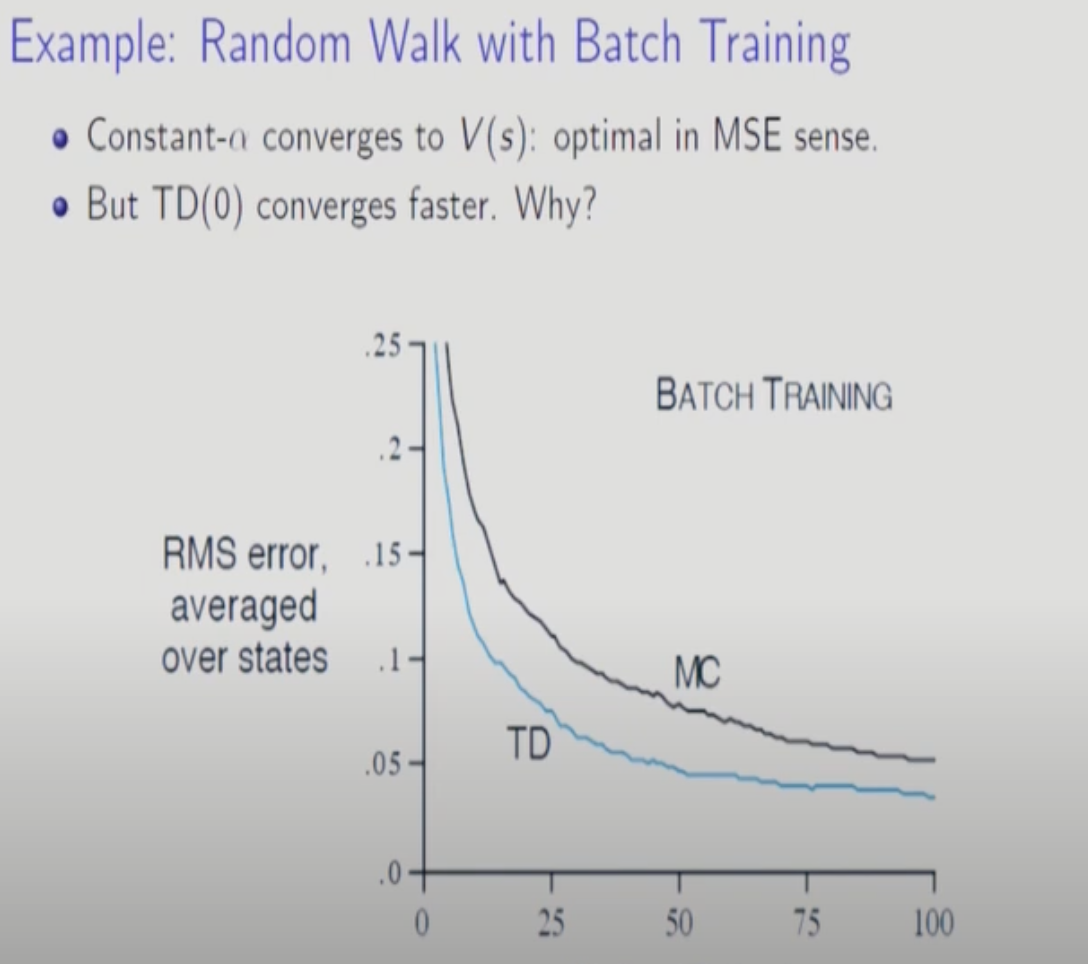
MC랑 TD랑 수렴지점이 다를 수 있다.

TD는 MDP를 따르지 않는 모델에서는 사용할 수 없다. 하지만 MDP를 따르지 않는 모델에 대해서도 MDP를 따른다고 해석한 지점으로 수렴한다. MC는 MDP를 따르지 않아도 된다. data만 보고 해석하기 때문이다. 즉, MC가 더 general한 학습방법이라 볼 수 있다. MC는 MDP와 상관없이 Mean Square Error를 Min하는 지점으로 수렴한다.

MC로 다음 문제를 풀게되면 A에 대해서는 A,0에 대한 Data 하나만 봄으로 A=0으로 Value Function을 측정한다. 하지만 TD는 MDP를 가정하므로 B와의 관계를 계속 추측해낸다. 따라서 TD를 사용하면 A의 Value Function이 0이 아니다.

Bootstraping: 미래의 추정치를 현재의 추정치에 반영. Backup은 미래의 정보를 현재에 반영하는 것으로 Bootstraping의 더 general한 개념이다.
Sample을 쓰는 것은 모델이 없다는 것이고 Sample을 안쓴다는 것은 모델이 있다는 뜻이다.
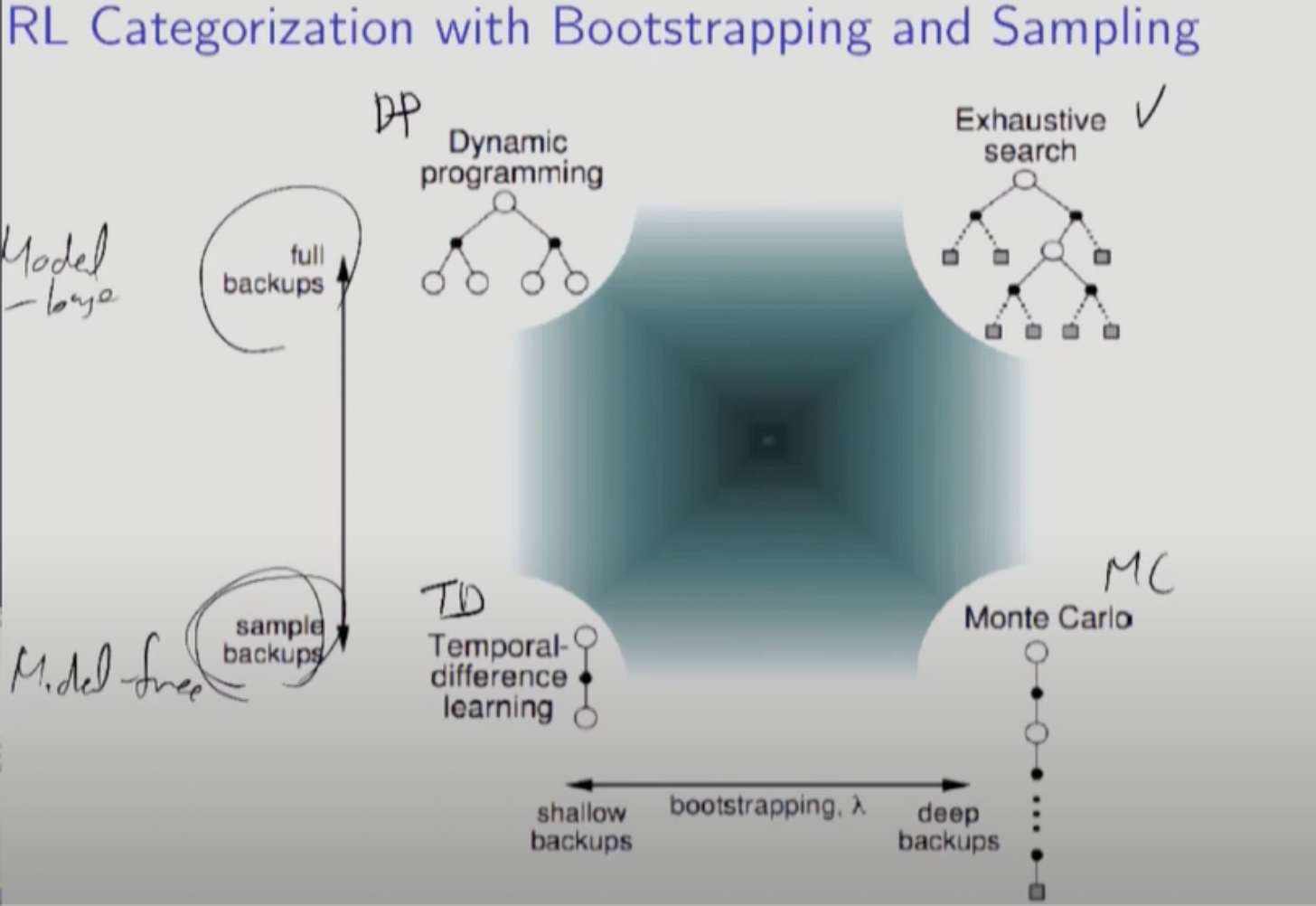
다음과 같이 나타낼 수 있다. Exhaustive search는 이론적으로만 존재하고 실제로는 잘 안쓴다.

N-Step TD 의 장점은 Step이 많아질수록 True Value에 가까워 진다는 것이다. 에러가 줄어든다.

N-Step TD에 대한 점화식이다.
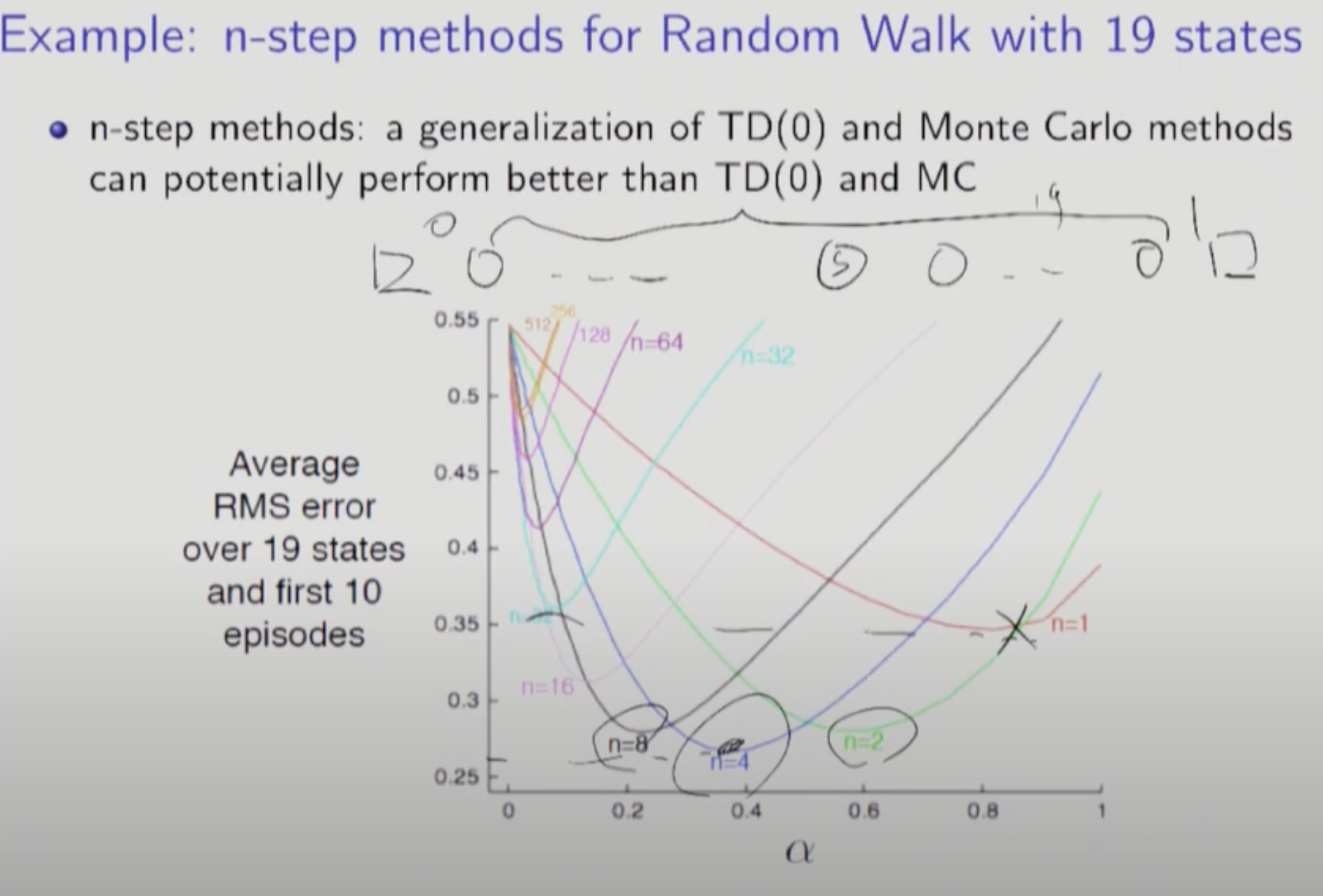
N이 커질수록 에러를 최저로 만드는 알파가 작아지는데 이는 가까이 예측할 수록 더 많이 반복해야 함을 의미한다.

MC - [DP의 중간] -> TD(0) - [N Step] -> N-Step TD - [각 스텝에 대해 평균] -> TD(람다)

만약 Terminal State가 없다면 Gt감마를 계산할 수 없으므로 사용이 불가능한 알고리즘이다.
따라서 Terminal State를 가정하고 사용해보자.
위의 그래프에서 감마가 T-t-1(T는 터미널 state)가 되는 뒷부분을 빼주면 된다.
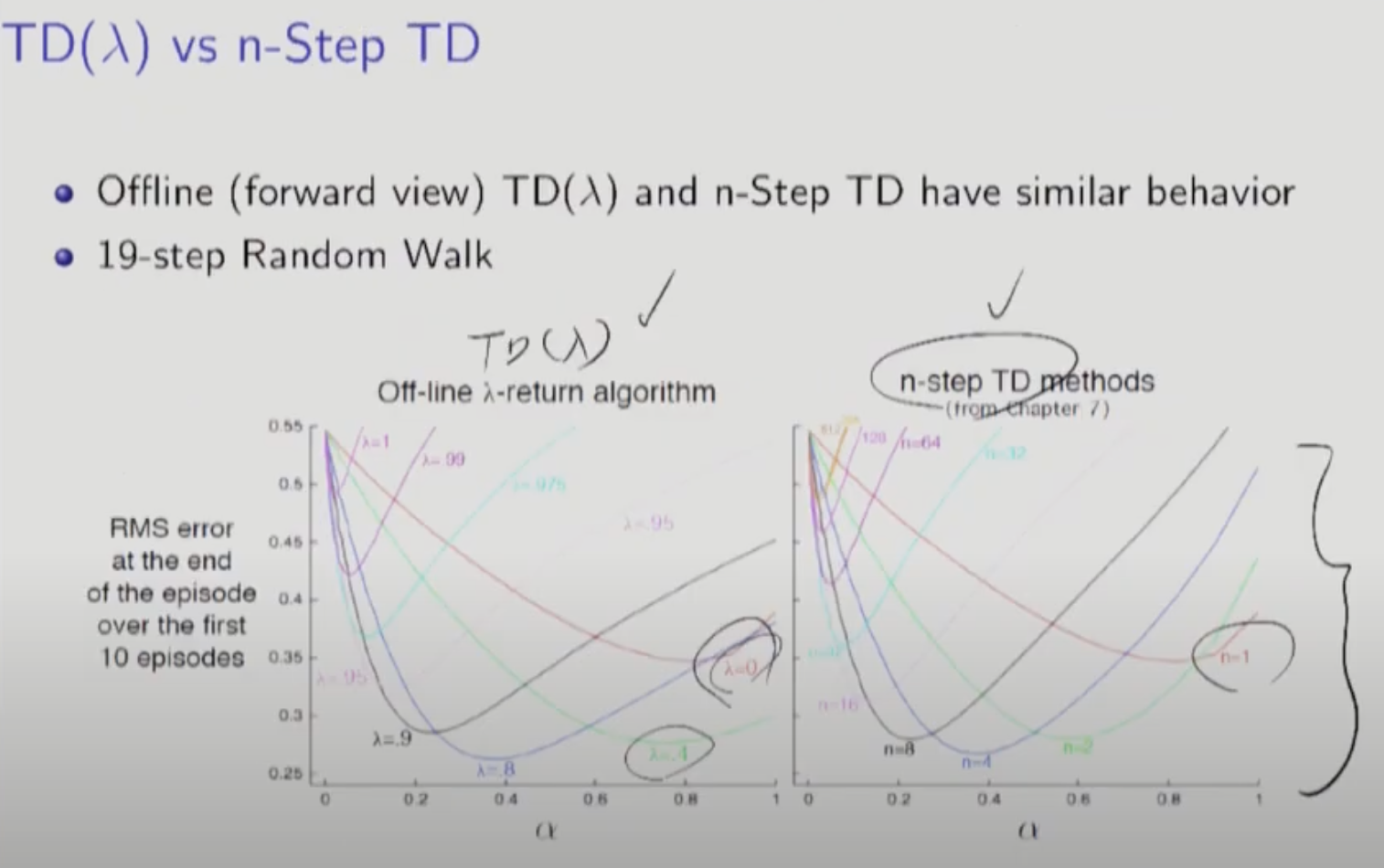
TD(람다)와 N-Step TD 그래프가 비슷한 양상을 띄는 이유는 람다가 크다는 것이 결국 먼 미래를 많이 반영한다는 뜻으로 n이 큰 것과 똑같은 의미이기 때문이다.
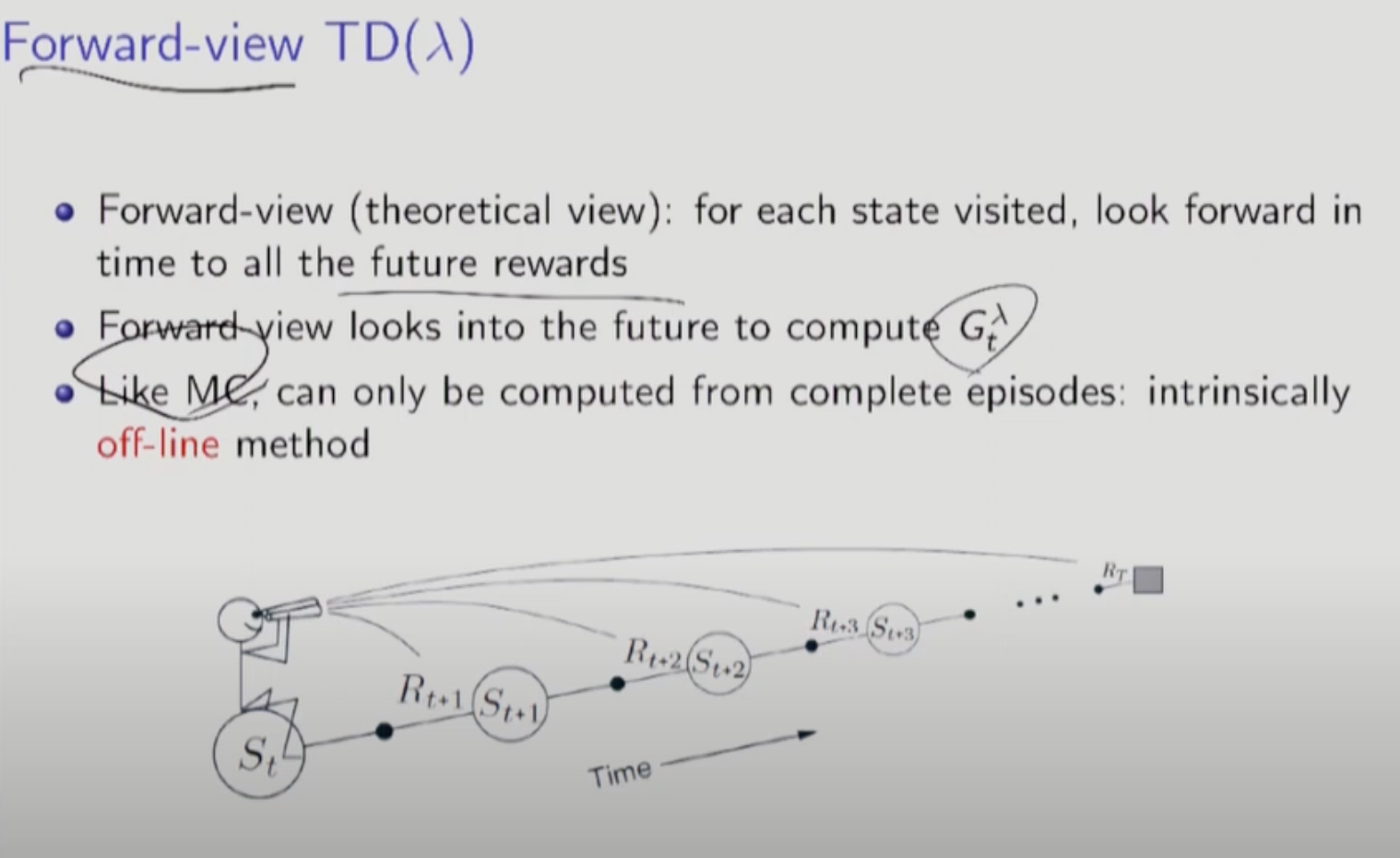
Forward-view TD(람다)는 에피소드가 끝날 때까지 평균을 취하는 TD(람다)알고리즘으로 에피소드가 끝나야 업데이트 할 수 있다는 것이 MC와 비슷하다. 오프라인 방법(다 저장해 놨다가 끝나고 계산)이다. 성능은 좋아지지만 바로 업데이트 할 수 없는 단점이 있다. 실용적이지 않다.
반대로 TD(0)는 온라인 방법(바로바로 업데이트)에 해당한다.

Eligibility Trace를 사용해서 MC를 Online으로 만들 수 있다. Forward-view(noncasual method)를 이 방법을 사용하여 Backward-view(casual method)로 만들 수 있다.

Eligibility Trace의 방법은 두 가지가 있다. 많이 나온 것을 따라가는 방법과 최근에 나온 것을 따라가는 방법.
State가 A가 계속 나오다가 마지막에 B가 나오고 Reward 1을 얻었을 때 Reward를 받은 것은 A덕분으로 볼 지, B덕분으로 볼 지 정하는 것.
t시간에서의 E는 t-1 시간에서의 E에다가 감마,람다를 곱한 뒤 1(St=s)를 더해서 구한다.
- 감마: Discount Factor
- 람다: TD람다에서 Weighted Average에 곱하는 값
- 1(St=s): t에서 state가 s이면 1 아니면 0
여기서 첫 번째 항(감마,람다)은 Recency전략을 반영하고 1은 Frequency 전략을 반영한다.
그래프를 보면 state s가 등장할 때 1이 추가돼서 계단식으로 증가하고 state s가 등장안할 때 감마,람다에 의해 decaying된다.
=> 이 방법을 통해 NonCasual한 Method를 Casual한 Method로 전환할 수 있다.

TD람다의 Backward View를 먼저 정의한다. 기존 TD람다와 비교하면 알파*TD-error 에다가 Eligibility Trace E를 곱한 것이 다르다.
델타t를 계산하기 위해 t+1(한 스텝) 만큼만 미래를 보고 나머지는 다 과거 Data기반인 것을 알 수 있다.
여기서 알파에 1을 대입하면 MC를 Online으로 학습시킬 수 있는 것이다.
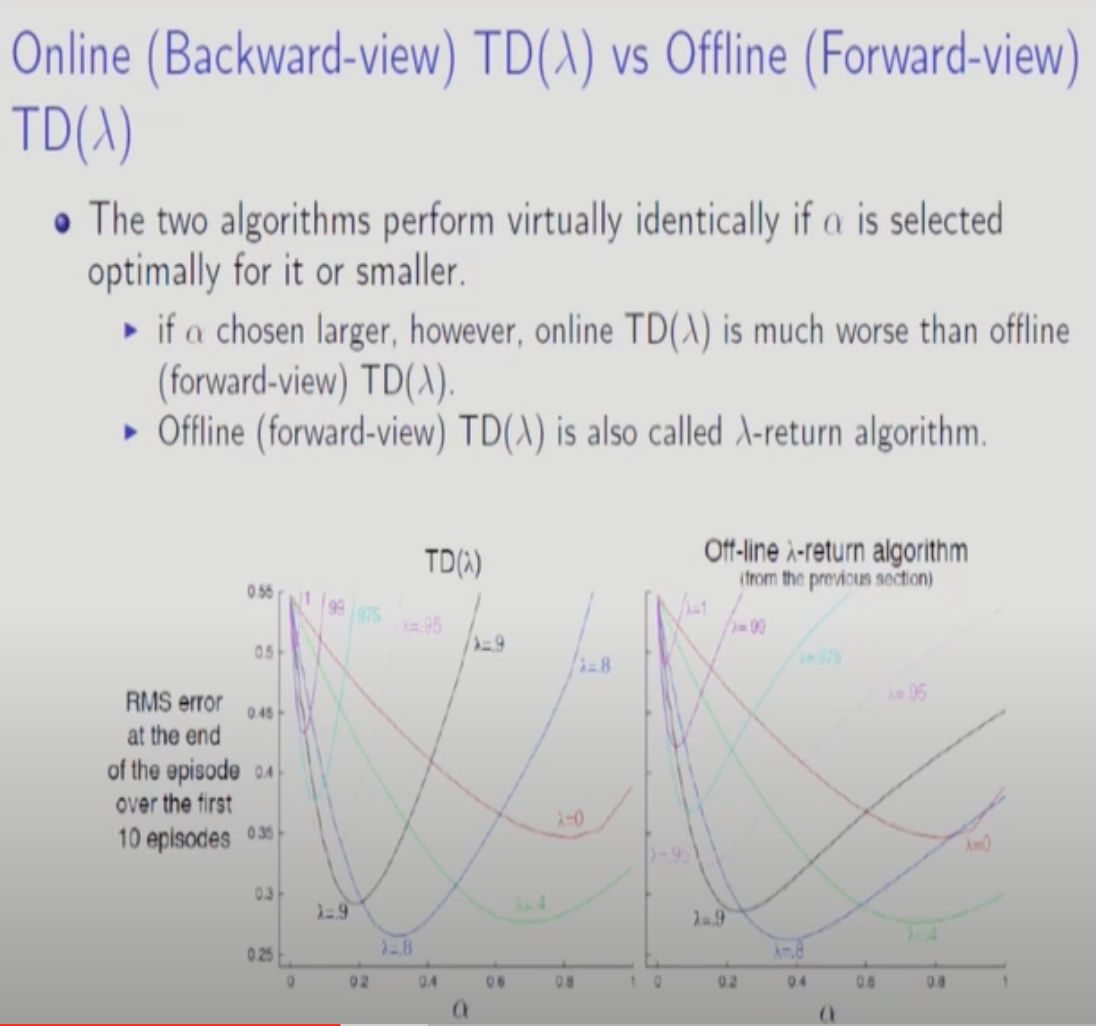
Online TD람다와 Offline TD람다를 보면 거의 비슷한 양상으로 진행됨을 알 수 있다. Online도 t마다 update하지 않고 모았다가 Off-line처럼 한번에 진행하면 수학적으로 동일함이 증명된다. 위의 두 그래프가 살짝 다른것은 실제로는 Online TD람다는 t마다 update하기 때문이다. 그래도 거의 비슷한 양상으로 진행된다.


