AutoEncoder를 이용한 Image Feature Engineering, 그리고 Clustering
Colab 주소:
https://colab.research.google.com/drive/1BxT6PimzrYCQNIIB1Ipcxhj9ORCUUlVF?usp=sharing
또는 Github Link:
https://github.com/xcellentbird/TOY-PROJECTS/tree/main/Image%20Feature%20Engineering
개요
KDT 프로젝트(이상형 매칭 소개팅 앱 -> 사람 얼굴 이미지에서 이상형을 결정하는 요소는 무엇일까?) 도중, 이미지에 대해서 어떻게 Feature를 뽑아낼 수 있을까 고민을 해왔습니다.
Classification모델에서 Classifier를 떼어내고 이를 Feature 생성기로 쓸 수 있지 않을까 생각했습니다. 하지만 이는 Labeling 과정이 필요하고, 지도 학습이기 때문에, 이미지에서 우리가 모르는 Feature를 발견하는 데에 한계가 있을 것 같다고 생각하여, 비지도학습 모델 방향으로 더 생각해보기로 결정하였습니다.
그리고 '3분 딥러닝 파이토치맛' 도서에서 읽었던 AutoEncoder 모델이 떠올랐고, 다른 글에서 읽었던 Transposed Conv을 사용해 기존에 배웠던 코드보다 성능이 좋은 AutoEncoder를 만들어보기로 하였습니다.
AutoEncoder Modeling
AutoEncoder baseline은 링크의 코드를 참고하였습니다.
# 층을 늘리기보다는 cnn층의 변수 개수를 늘렸을 때, 학습 효과(loss 최소화)가 좋았다. # BatchNorm2d도 사용해보았지만, 효과가 좋지 않았다. class Autoencoder(nn.Module): def __init__(self, classifier_mode=False, num_classes=10): super(Autoencoder, self).__init__() self.classifier_mode = classifier_mode self.encoder = nn.Sequential( nn.Conv2d(1, 32, 3, stride=2, padding=1), nn.SiLU(), nn.Conv2d(32, 128, 3, stride=2, padding=1), nn.SiLU(), nn.Conv2d(128, 512, 7), ) self.decoder = nn.Sequential( nn.ConvTranspose2d(512, 128, 7), nn.SiLU(), nn.ConvTranspose2d(128, 32, 3, stride=2, padding=1, output_padding=1), nn.SiLU(), nn.ConvTranspose2d(32, 1, 3, stride=2, padding=1, output_padding=1), nn.Sigmoid() ) self.classifier = Classifier(in_features=512, num_classes=num_classes) def forward(self, x): encoded = self.encoder(x) decoded = self.decoder(encoded) # 분류기 모드일 경우 out = None if self.classifier_mode: out = encoded.reshape((encoded.size(0), -1)) out = self.classifier(out) return encoded, decoded, out
- 코드 설명: 후에 분류기로도 작동시키기 위해 'classifier_mode' 설정을 넣었습니다. encoder, decoder, classifier결과를 얻을 수 있도록 forward함수를 설계하였습니다.
모델 학습
육안으로도 쉽게 feature cluster 결과를 보고 평가할 수 있어야하기에 MNIST_Fashion 데이터셋을 실험 이미지 데이터셋(train:60000개, test and valid:10000개)으로 선정(숫자 데이터의 경우, 단순하게 곡선과 직선 여부만 Feature가 나올 것으로 예상되어 선정 X)하였고, 다음과 같은 학습 결과를 얻어낼 수 있었습니다.
-
학습 Loss 그래프
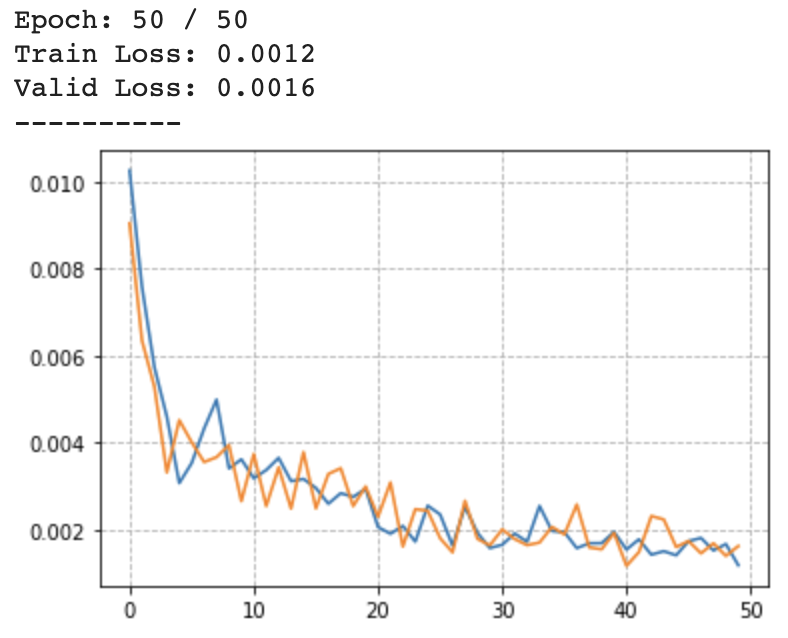
-
입력 이미지와 Decoder 출력 이미지 비교

Feature Engineering
model을 eval()모드로 바꾸고, 10000개의 test 이미지를 Encoder에 넣어, 아래와 같이 512개의 출력값을 feature로 선정하였습니다.
Clustering
Class를 통한 유의미한 Cluster 결과 도출
얻은 feature를 KMeans 군집화 모델(일단, n_clusters=2)에 넣어 아래와 같이 cluster 결과를 얻을 수 있었습니다.
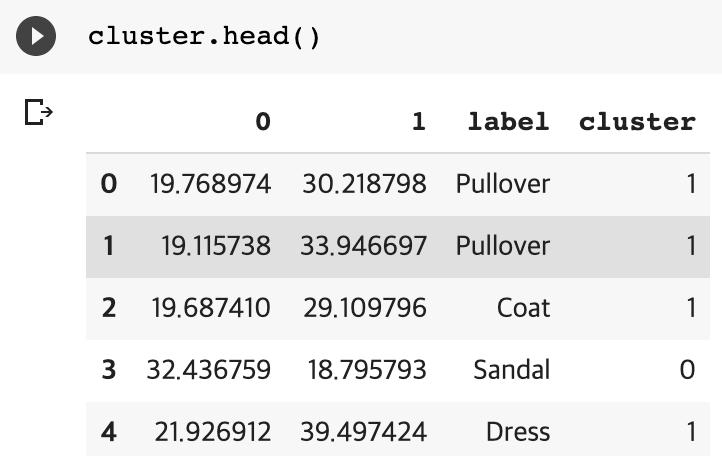
그리고 class와 cluster의 관계를 추정해보기로 결정하였습니다.
일단, 해당 class에서 많이 나온 cluster를 이용하여 관계를 유추하는 방법보다는, cluster의 분포도를 보고 판단하기 위해 아래와 같이 describe 함수를 이용하여 표를 출력하였습니다.
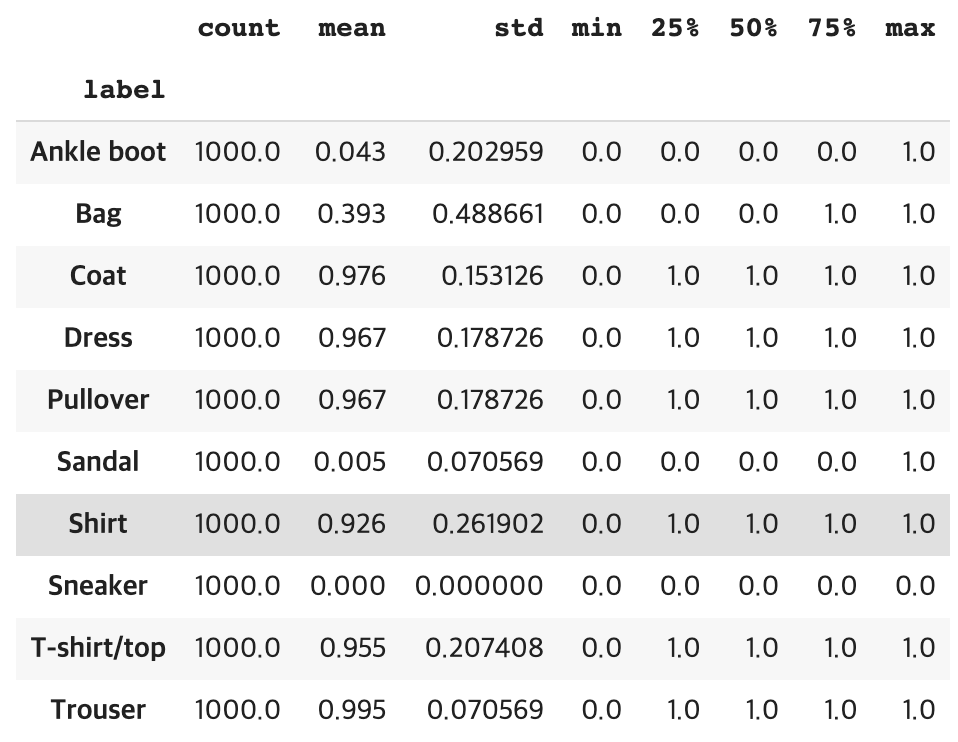
표에서 유의미한 값이라 생각된 것은 mean(평균값)과 std(분산값)입니다.
- mean(평균)은 연속성(Continuous)을 가지며, 해당 class가 주로 어느 cluster로 형성되었는지 알 수 있습니다.
- std(분산)는 cluster을 얼마나 특정지을 수 있는가를 알 수 있게 해줍니다. 해당 class의 std가 다른 class의 std보다 상대적으로 높다면, 이는 여러 cluster로 분포되어 있다는 뜻으로, 군집화가 확실하게 이루어지지 않는다는 것으로 추측할 수 있습니다.
일단 std보다 mean가 더 유의미한 값이라 생각하였고, 이 값을 이용하여 한번 더 KMeans(n_clusters 값은 이전과 같다.)를 이용해 군집화를 수행하였습니다.
+) mean과 std값으로 clustering을 수행한 결과, 크게 달라지지 않는 것을 한두번 확인하였지만, 실험 데이터 부족으로 결과를 확신할 수 없었다.
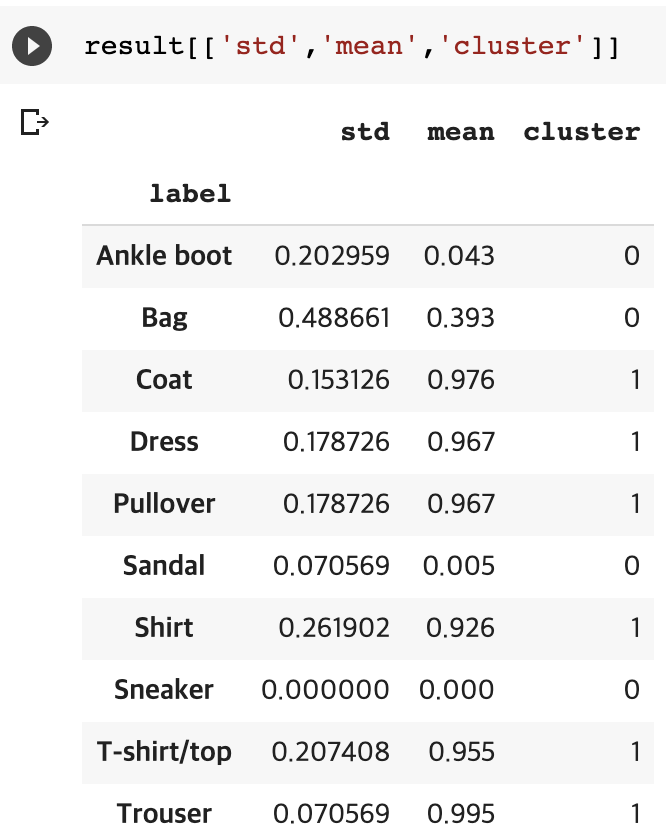
위는 mean값을 이용해 다시 cluster를 수행한 결과입니다.
('Ankle boot', 'Bag', 'Sandal', 'Sneaker') :
('Coat', 'Dress', 'Pullover', 'Shirt', 'T-shirt/top', 'Trouser')
여러 번 cluster를 수행해도 같은 군집화 패턴을 얻을 수 있었습니다. 먼저 눈에 띈 것은 의류와 잡화로 나눠졌다는 것입니다. 이를 통해 팔/발 소매의 여부를 먼저 판단한 게 아닐까 추측할 수 있었습니다.
n_clusters를 2보다 높게 설정
그리고 n_cluster를 2보다 높게 설정하여 다양한 결과를 얻을 수 있었지만, cluster를 수행할 때마다 결과는 달라졌고, 이는 신뢰할 수 없는 cluster 결과라고 판단하였습니다.
n_clusters = 10
마지막으로 n_cluster를 class의 수와 같이 10으로 설정하여 군집화를 수행한 결과 다음과 같은 결과를 얻을 수 있었습니다.
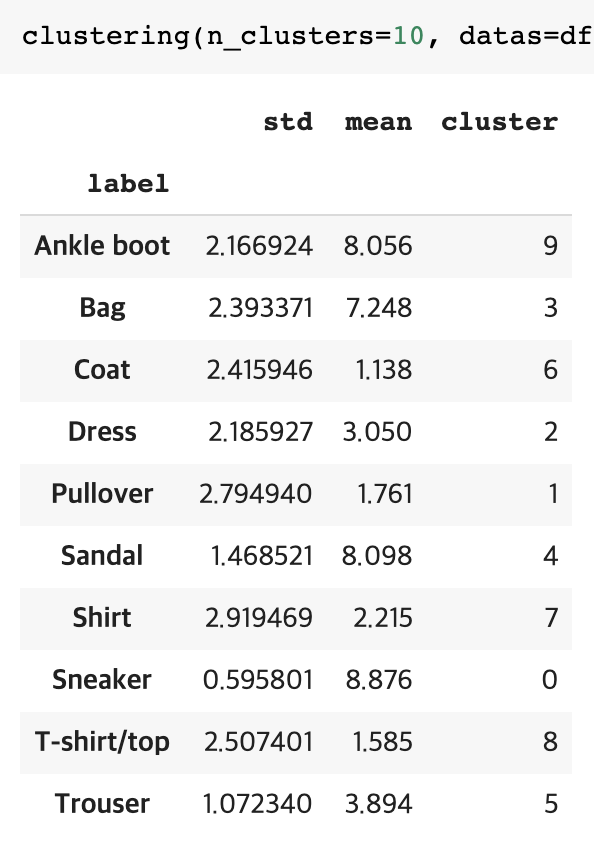
mean를 통해 같은 cluster로 군집화가 이루어진 class도 많다는 것을 알 수 있었지만, 이를 통해 다시 cluster한 결과가 class수와 같이 제 각각 다른 cluster를 이루어지는 것을 관찰할 수 있었습니다. 이는 여러번 cluster를 수행해도 같은 패턴의 군집화 결과를 얻을 수 있었습니다.
결과 고찰
개인적으로 더욱이나 신기했던 것은, AutoEncoder나 Cluster 모델에 Target Label을 지도해주지 않았음에도 불구하고class에 중점(편향)을 두고 결과를 고찰하긴 했지만, 다음과 같이 class 수만큼 각각 다른 cluster가 형성된 것을 볼 수 있었습니다.
이러한 점을 통해, KMeans Cluster 모델도 Classifier 기능을 수행할 수 있다는 것을 유추할 수 있었습니다.
또한 n_clusters를 늘려서 여러번 clustering을 수행했을 때, 일정한 cluster 패턴을 보인다면, 이는 유의미한 cluster 또는 classification이라 판단할 수 있을 것으로 여겨집니다.
Encoder 전이 학습
저는 더 나아가 전이 학습처럼, classification모델을 학습(epochs=40)시킨 후, classifier를 떼어내고 decoder를 붙여 적은 epoch(=10)로 좋은 autoencoder 학습 결과를 얻을 수 있을지 실험하였고, 이전 autoencoder(epoch=50)만큼 좋은 결과를 얻을 수 있음을 시각화를 통해 확인할 수 있었습니다. 그리고 이는 classification 모델처럼 autoencoder모델도 전이학습이 가능하다는 것을 알 수 있었습니다.
다른 의미로, 비지도 학습 모델과 지도 학습 모델 간의 전이 학습이 가능할 것이라는 가정을 할 수 있었습니다.
- 전이 학습 autoencoder 결과 시각화

다 끝나고 나서야 하는 Feedback
- 조금 더 복잡한 데이터셋을 이용했을 때, 더 다양한 feature와 cluster 결과를 확인할 수 있을 것 같다.
- 더 많은 n_clusters로 유의미한 cluster 결과를 찾아보는 것도 좋을 것 같다. 이는 class를 통해 확인할 수 있는 것이 아닌, 같은 cluster의 이미지 시각화를 통해 어떤 의미를 갖는 지 확인할 수 있을 것으로 보인다.
- Encoder와 Decoder성능이 다를 경우 어떠한 결과가 나올까? 예를 들어 EfficientNet에 내가 만든 작은 규모의 Decoder를 붙이면?
- 이틀(적어도 26시간...)동안 Feature Engineering 실험을 해보면서, Python언어와 PyTorch, Scikit-learn, Matplotlib 모듈의 이해도를 높일 수 있었다.
- std값만으로 따로 clustering을 하거나, std와 mean값을 이용했을 때, cluster를 수행하면 다른 유의미한 cluster 결과를 얻을 수 있었을까?
진짜 마지막으로 결론
- tranposed_convolution을 이용한 AutoEncoder 모델 제작 완료하였습니다.
- mnist fashion dataset으로 feature 512개 추출 후 Kmeans Cluster(n_clusters = 2)모델에 넣었을 때, 의류 / 잡화로 나눠지는 것을 확인하였습니다.
- 전이 학습된 classification 모델에서 classifier를 떼어내어 encoder를 만들고 decoder를 붙여 autoencoder 비지도 학습을 시킨 결과, 적은 epoch로 전이 학습 효과를 낼 수 있었음을 확인할 후 있었습니다. 또한 비지도 학습 모델, 지도 학습 모델 간 전이 학습이 가능하다는 가설을 세울 수 있었습니다.
- n_clusters를 class 수만큼 설정하였을 때, 정확히 각기 다 다른 군집으로 나눠지는 것을 확인할 수 있었습니다. => Kmeans Cluster모델을 Classifier로 사용할 수도 있음을 유추할 수 있었습니다.
- ★ 결론 of 결론: AutoEncoder를 통해 image feature engineering을 수행 후, n_clusters를 늘리고, 여러번 군집화(random_state=None) 시켰을 때 같은 패턴의 군집으로 나눠진다면, 이는 의미있는 cluster 또는 classification으로 유추할 수 있을 것 같습니다. 그리고 cluster 내의 이미지를 모두 시각화하여 확인해봄으로써, 해당 feature(s)가 어떠한 의미를 갖는지 추측할 수 있을 것으로 보입니다.






