JPEG 이미지 압축 방식은 CNN 모델에 어떠한 영향을 끼치는가?
0. Intro
이미지 데이터를 정리하면서 "어떻게 하면 효율적으로 데이터를 관리할 수 있을까" 생각하던 중, image format이 CNN 모델에 어떤 영향을 끼치는지 궁금해졌습니다. 그래서 자주 쓰이는 JPEG(jpg)와 PNG에 대해서 더 알아보기로 하였습니다~
1. PNG와 JPEG
PNG 압축이란?
PNG(Portable Network Graphics) 압축은 무손실 압축으로 알려져 있으며, 트루 컬러(8비트)를 지원하기 때문에 RGB에 각각 1 byte(0~255)씩 할당하게 됩니다. 그 외로 8비트 외에 24비트, 32비트를 지원하는 PNG-24, PNG-32 방식이 있습니다. 장점으로는 손실이 없다는 것이고, 단점으로는 조금 더 큰 용량을 차지한다는 것입니다. 보통 딥러닝 학습을 할 때, RGB채널 8비트 공간을 사용하기 때문에 PNG 압축은 우리가 알고 있는 성능과 크게 달라질 게 없어보이네요...!
JPEG 압축이란?
출처: 블로그 bskyvision
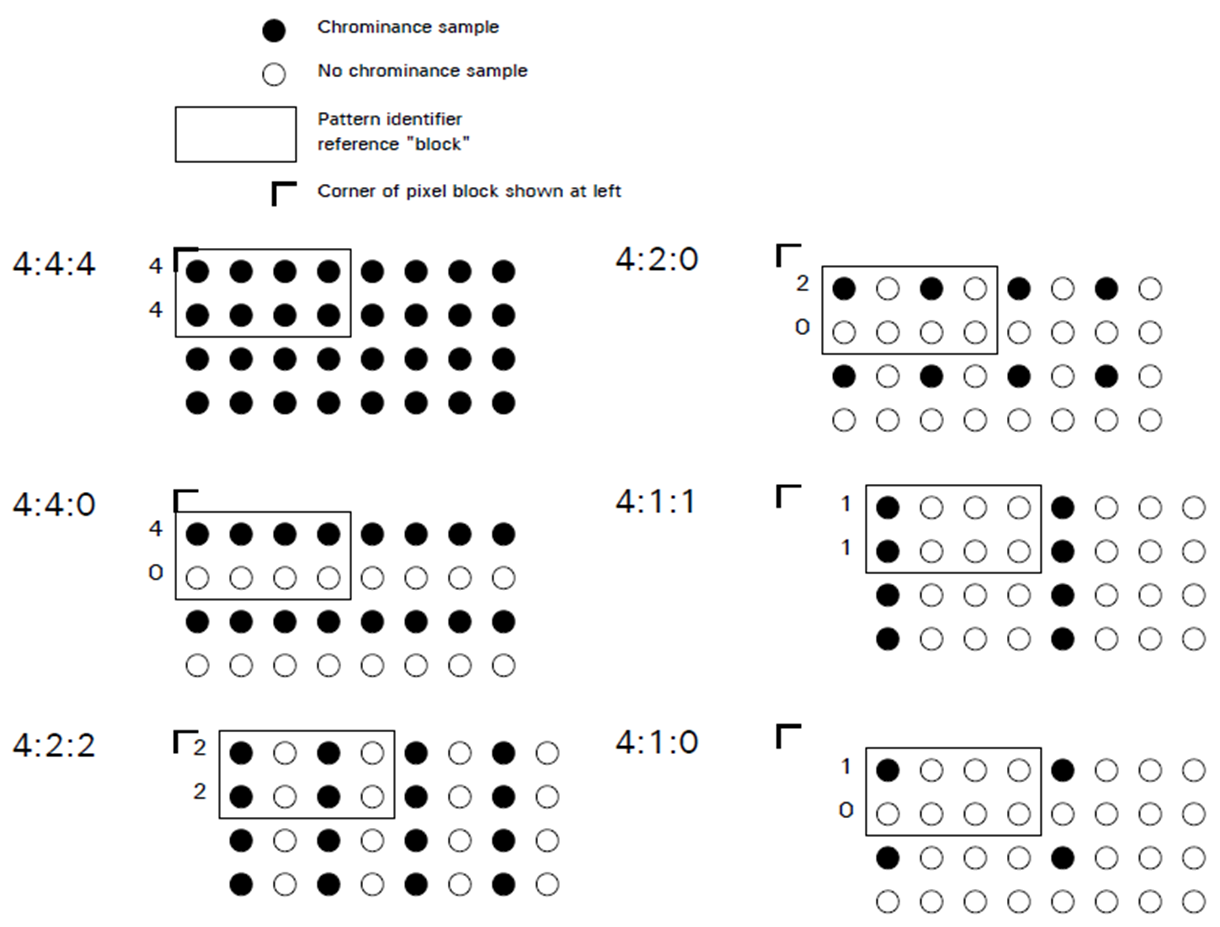
JPEG는 흔히 JPG 압축이라고 많이 불립니다. 그리고 대부분의 이미지가 default로 jpg 포맷으로 저장되죠. jpg는 이미지를 YCbCr 색공간(Y: 밝기 성분, Cb/Cr: 색차 성분)으로 바꾸고 Cb/Cr 정보를 줄이는 방향으로 서브샘플링을 진행합니다. 그 이유는 사람에게는 색정보보다 밝기 정보보다 색 정보가 덜 중요하기 때문이라고 하네요. 당연히 Y채널에서는 서브샘플링을 진행하지 않습니다.
- 서브샘플링(Subsampling): (2*J) 픽셀공간에서 N(=a+b)개의 픽셀을 샘플링하고, 나머지 픽셀 정보를 버리는 압축 방법입니다. 자세한 방법은 출처의 블로그를 참고하시면 됩니다.
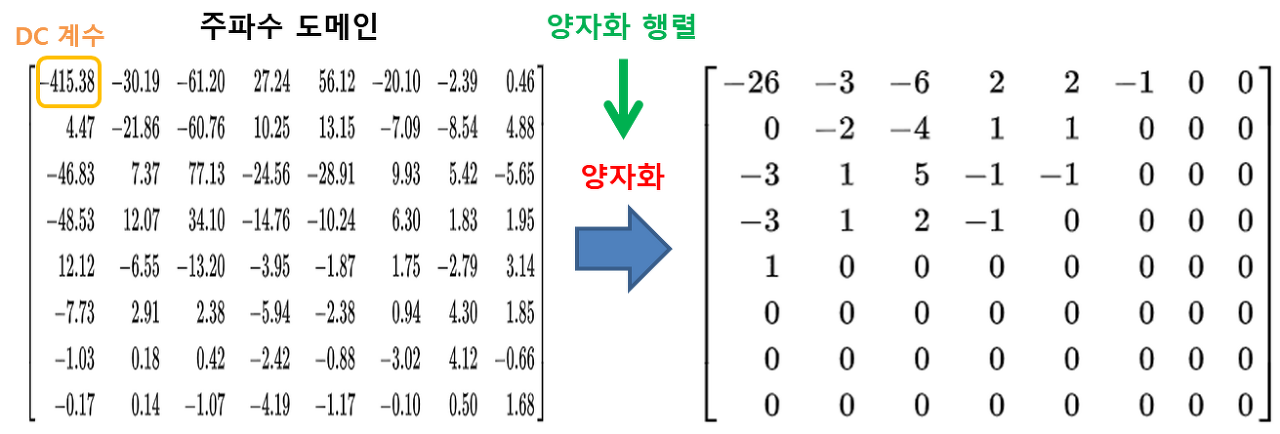
이렇게 샘플링된 정보를 [0, 255]에서 128을 빼서 [-128, 127] 사이값으로 만들고, 2D 이산코사인변환(DCT)를 적용하여 주파수 도메인으로 변경합니다. 맨 왼쪽 위의 숫자는 DC 계수(coefficient)로 저주파 성분과 관련되어 있으며 명도를 결정하는 정보를 담고 있습니다. 그리고 나머지 계수는 모두 AC 계수로 고주파와 관련되어 있습니다. 사람은 고주파에는 둔하고, 저주파에는 더 민감하기 때문에, jpg 포맷은 고주파 정보를 일부 제거하는 방법으로 압축을 진행합니다.

DC 계수에는 작은 수로 나누고, 나머지 AC 계수에는 큰 수로 나눈 다음, 반올림 하는 방법으로 양자화(quantization)을 진행합니다. 아래 그림처럼 0으로 변한 AC 계수가 많다는 것은 그만큼 고주파 정보를 손실시켰다는 의미입니다.
그 후, zipzag scaning을 통해 1차원 벡터로 만들고, DC,AC 계수를 부호화하는 방식으로 압축하게 됩니다. JPEG 압축에서 중요한 포인트는 다음과 같이 양자화 단계에서 고주파 성분을 제거하는 것입니다. 그렇다면 고주파 정보를 없애게 되면 모델에는 어떠한 영향을 있을까요?
2. 이미지의 Frequency는 모델에 어떠한 영향을 주는 걸까?

결론부터 말해서, 논문:High-frequency Component Helps Explain the Generalization of Convolutional Neural Networks에 의하면, 이미지의 저주파 성분, 고주파 성분 모두 모델에 영향을 준다고 합니다. 위의 사진은 논문에 나오는 사진의 일부입니다. 첫번째 열은 원래의 이미지고, 두번째는 저주파 성분만 남겨놓은 사진, 세번째는 저주파 성분을 모두 제거하고, 고주파 성분만 남겨놓은 사진입니다. 그리고 두번째 행은 이전에 학습된 모델을 이용하여 위쪽 행의 사진들을 추론한 결과입니다.
위 사진만으로도 인간의 눈은 저주파 성분에 더 예민하며, 고주파 성분에 둔감하다는 것을 알 수 있습니다. 하지만, AI 모델의 입장은 다른가 봅니다. 고주파든 저주파든 주파수가 바뀌는 것만으로도 모델 성능에 영향을 끼친다는 것을 알 수 있습니다.
저는 너무나도 몇 가지 사실을 간과한 체로 'JPEG 압축 포맷은 고주파 성분을 해치니까, 당연하게 모델에 영향을 끼치게 되는 게 아닐까?'라는 결론을 내렸었습니다... 하지만, 다른 논문을 보면서 생각을 금방 고칠 수 있었죠.
3. 어느 정도의 JPEG quality가 모델에 영향을 크게 주게 될까?
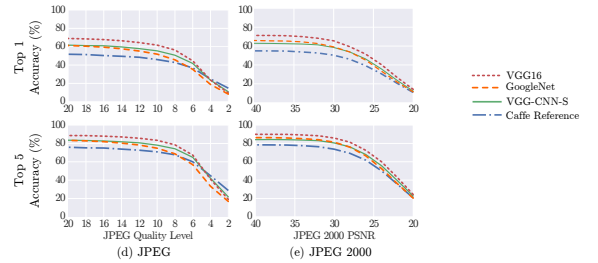
이번에도 결론부터 말하자면, 논문:Understanding How Image Quality Affects Deep Neural Networks의 내용에 따르면, JPEG quality 20미만부터 모델에 영향을 조금씩 끼친다고 합니다. JPEG quality는 '이미지가 JPEG 압축에 의해 손상된 후, 어느 정도의 quality를 유지하고 있는가'를 뜻합니다. 다시 말하자면, 일단은 JPEG quality를 20이상만 유지한다면 모델에는 큰 영향을 주지 못한다는 것입니다.그렇다면 우리가 보통 쓰고 있는 JPEG 압축은 어느 정도의 JPEG quality를 가지고 있을까요?

모듈을 모두 뒤져볼 순 없으니... 일단 PIL 모듈에서 제공하는 이미지 포맷 문서를 뒤져보도록 하겠습니다. 위의 글을 해석하자면 quality 75를 기본으로 하고 있다는군요. 일단은 안심하고 PIL 모듈에서 jpg형식으로 이미지를 저장할 수 있겠네요.
하나 더... JPEG 포맷이 이미지 파일 크기를 줄인다고 했는데, 얼마나 줄이는 걸까요? 그리고 이미지 데이터 저장소를 구축한다고 했을 때, 최대한 어느 정도까지 압축을 할 수 있는 걸까요?
4. 이미지 파일 크기를 최대한 줄이면서 모델에 영향을 주지 않은 JPEG quality는?

이미지 출처:https://code.flickr.net/2015/09/25/perceptual-image-compression-at-flickr/
위의 도표를 보아, 2048 픽셀 이미지 기준으로 JPEG quality를 75로만 설정해도 원래 이미지의 1/5~1/8만큼 이미지 파일 사이즈를 줄일 수 있다는 것을 알 수 있습니다. 이미지를 더 이상 압축하지 않을 것이고, 오직 Classification 모델의 이미지 학습 용으로 쓰겠다는 가정하에 JPEG quality 20로 압축하면 거의 원래 이미지의 1/16만큼 파일 크기를 줄일 수 있겠네요.
++) Image의 bbox 영역만 학습하는 Detection 모델의 경우엔 어떻게 이미지를 보관하는 게 좋을까요? 제 의견으로는, bbox 영역 이미지의 high frequency가 너무 낮지 않다는 가정 하에, JPEG의 subsampling을 하지 않은(J×2 = a×b) 채로 이미지를 보관해야겠다는 생각이 드네요.
