
이번에는 다나와 사이트를 통해 페이지 전환 및 전환된 페이지를 출력하고, 스크린샷으로 저장해보겠습니다.
🕹 selenium 설정
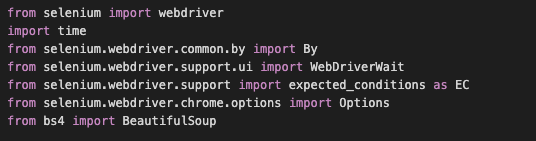
1)from selenium import webdriver
webdriver을 사용하기 위해 selenium내의 webdriver을 import 합니다
나머지 부분은 밑에서 같이 설명하겠습니다.
🕹 headless모드
일반모드는 webdriver가 자동으로 브라우저를 제어하여 창을 열고 닫고 했는데 headless모드는 이러한 것을 가상으로 하기 때문에 아무런 일도 일어나지 않습니다.

Options()를 열고 add_argument()내의 "--headless"를 써줌으로 headless설정이 완료되었습니다. 그리고 이제 webdriver을 사용하기 위해 broswer변수에 webdriver.Chorme('webdriver위치')를 저장합니다. 여기까지는 일반모드입니다. 즉, 브라우저가 자동으로 창을 열고 닫습니다. 근데 webdriver.Chorme('webdriver위치'), options = chrome_options와 같이 위에서 설정한 chrome_options를 넣어주면 브라우저가 headless모드로 변경됩니다.
🕹 브라우저 사이즈, 페이지 이동
이제 브라우저 사이즈 및 자동으로 브라우저가 url에 해당하는 사이트로 이동하는 코드를 구현하겠습니다.

🕹 제조사별 더 보기 클릭
다나와 사이트를 보면 제조사를 더보기 위해서는 오른쪽 +버튼을 눌러야합니다. 이 부분을 selenium을 통해 코드로 구현하겠습니다.

WebDriverWait(browser, 3).until(EC.presence_of_element_located((By.XPATH,'//*[@id="dlMaker_simple"]/dd/div[2]/button[1]'))).click().until(EC.presence_of_element_located((By.XPATH,'//[@id="dlMaker_simple"]/dd/div[2]/button[1]')))는 XPATH형태의 코드인 '//[@id="dlMaker_simple"]/dd/div[2]/button[1]'가 다나와 사이트내의 표시될때까지 기다립니다. 위에서 보시게되면 WebDriverWait(browser, 3)로 설정했기 때문에 3초를 기다립니다. 그러나 3초 이후에도 표시 되지않으면 에러를 발생합니다.click()부분은 에러가 발생하지 않으면 해당하는 부분을 click합니다.
이제 제조사별 맨 오른쪽에 +가 click된 것을 확인할 수 있습니다.
🕹 원하는 모델 카테고리 클릭(APPLE)
+를 click하면 나타나는 제조사 카테고리중에 APPLE카테고리를 click하는 코드를 구현하겠습니다
WebDriverWait(browser, 2).until(EC.presence_of_element_located((By.XPATH,'//*[@id="selectMaker_simple_priceCompare_A"]/li[13]/label'))).click()이 코드도 위에 제조사별 더보기 클릭과 거의 비슷합니다.
다나와 사이트 내의 APPLE카테고리에 해당하는 xpath형식의 코드를 복사하여 .until(EC.presence_of_element_located((By.XPATH,''))에 ''부분에 넣어주고 실행하여 APPLE카테고리를 가져왔고, .click을 통해 APPLE카테고리를 눌러준 것입니다.
이제 APPLE카테고리의 내가 설정한 페이지수에 해당하는 내용을 출력하고 screen shot으로 저장해보겠습니다.
🕹 페이지수 설정

다나와 사이트에 해당하는 페이지 수입니다. 저는 자동으로 1페이지부터 5페이지까지 넘기면서 각 페이지에 해당하는 내용을 스크린샷으로 저장하고 출력해보겠습니다.
일단 현재 페이지수와 마지막 페이지 수를 설정합니다.

🕹 각 페이지에 해당하는 내용 출력과 스크린샷 저장
while 문을 통해 curpage가 target_crawl_num이 될 때까지 계속 실행되는 코드를 만들고, 각페이지에 해당하는 내용을 가져오기 위해 BeautifulSoup를 통해 페이지의 해당하는 page_source를 'html.parser'를 통해 가져와 soup변수에 저장합니다.

그리고 각 페이지의 내용에 해당하는 soup변수에 원하는 부분인 메인 상품 리스트를 css select를 통해 가져옵니다.

페이지가 헷갈리지 않게 해당 페이지를 출력합니다.

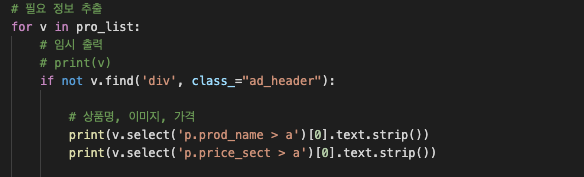
가져온 메인 상품 리스트에서 원하는 부분을 추출합니다. 저는 메인 상품 리스트에서 상품이름과 상품가격을 가져왔습니다.
가져온 메인 상품 리스트에서 불필요한 부분을 if not v.find('div', class_"ad_header")통해 제거시켜주었고, 상품명과 가격을 출력하였습니다.
각 페이지별로 스크린샷으로 저장하겠습니다.

save_screenshot(파일이름)을 통해 저장합니다.
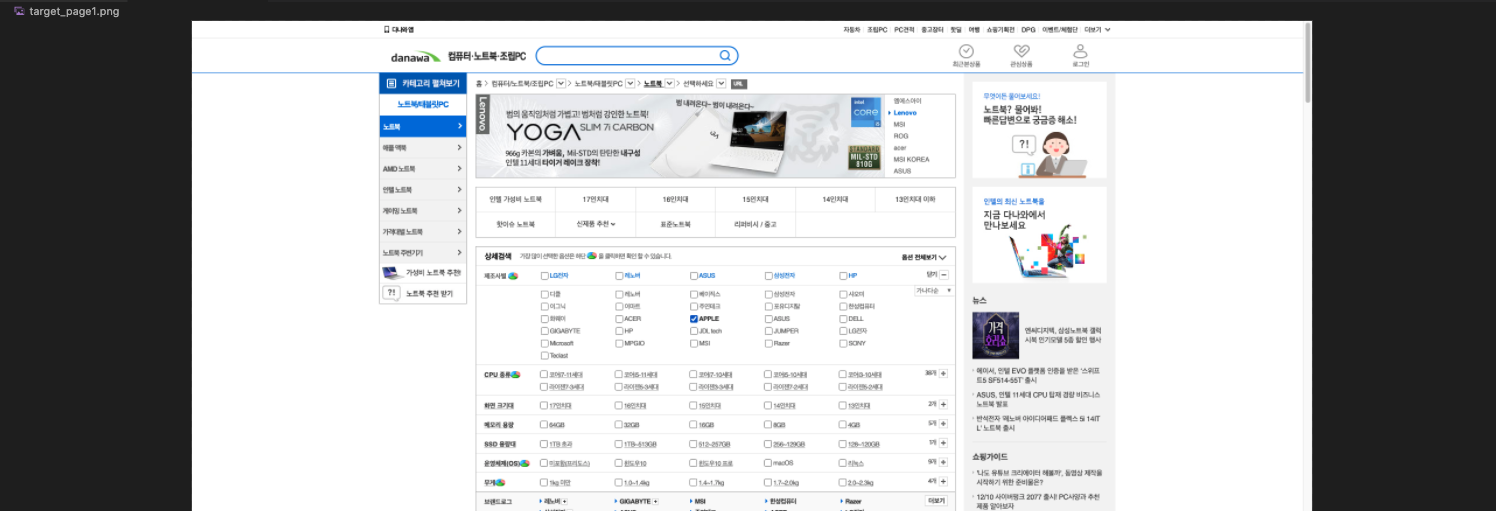 를 보시면 target_page1.png에 파일이 저장된 것을 확인할 수 있습니다.
를 보시면 target_page1.png에 파일이 저장된 것을 확인할 수 있습니다.
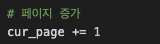
다음 페이지를 출력하기 위해 현재페이지를 1씩 증가합니다.
그리고 다음 페이지의 해당하는 내용을 보기위해서는 다음 페이지를 클릭하여야 합니다.
# 페이지 이동 클릭
WebDriverWait(browser,2).until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.number_wrap > a:nth-child({})'.format(cur_page)))).click()
다음 페이지에 해당하는 코드를 copy_selector를 통해 가져와서 .until(EC.presence_of_element_located((By.CSS_SELECTOR,''))))의 ''부분의 넣어줍니다. 그리고 가져온 부분을 .click을 통해 click해줍니다. 그러면 다음 페이지로 넘어가게 되고 while문을 통해 전페이지와 동일하게 내용과 스크린샷이 저장되게 됩니다.
🕹 브라우저 종료

마지막에는 해당 브라우저를 종료시킵니다.
