이 글은 김영근 교수님의 컴퓨터 구조 강의를 듣고 정리한 내용입니다.
메모리의 종류 및 발전 동향
메모리는 데이터에 어떻게 접근하냐에 따라서
① 임의 위치의 데이터에 항상 일정 시간 내에 접근 가능한 Random Access Memory(RAM),
② 순서에 따라서 접근 시간이 달라지는 Non-Random Access Memory
크게 2가지로 나뉘는데, 실제 Processor에서 많이 사용하는 RAM 위주의 내용을 다룰 것이다.
1️⃣ RAM 종류 및 발전
그럼 RAM 에는 어떤 종류가 있고, 어떻게 발전해왔는지 살펴보자.
| 구분 | SRAM | DRAM | Flash Memory |
|---|---|---|---|
| 접근 속도 | 매우 빠름 (DRAM x2~x10) | 느림 | 매우 느림 |
| 비용 | 고비용 | 중간 비용 | 저비용 |
| 휘발성 | 휘발성 | 휘발성 | 비휘발성 |
| 사용처 | Logic, 빠른 속도 및 접근 | 메인 메모리 | Disk, 대용량 데이터 장기 보관 |
| 기술 발전(용량) | 3년 기준 2배 | 3년 기준 4배 | 3년 기준 2배 |
| 기술 발전(속도) | 3년 기준 2배 | 10년 기준 1.4배 | 10년 기준 1.4배 |
2️⃣ 문제점 및 해결책
위의 표를 보면, Logic에 사용되는 SRAM의 속도는 빨라지는 반면
메인 메모리에 사용되는 DRAM의 경우 속도는 상대적으로 느리게 발전되고 있다.
모든 메모리를 가장 빠른 SRAM으로 구성하면 좋겠지만, 비용 때문에 현실적으로 어렵기 때문에 보다 경제적이고 합리적인 해결책으로써 계층 구조 형태의 메모리 설계 방식이 제안되었다.
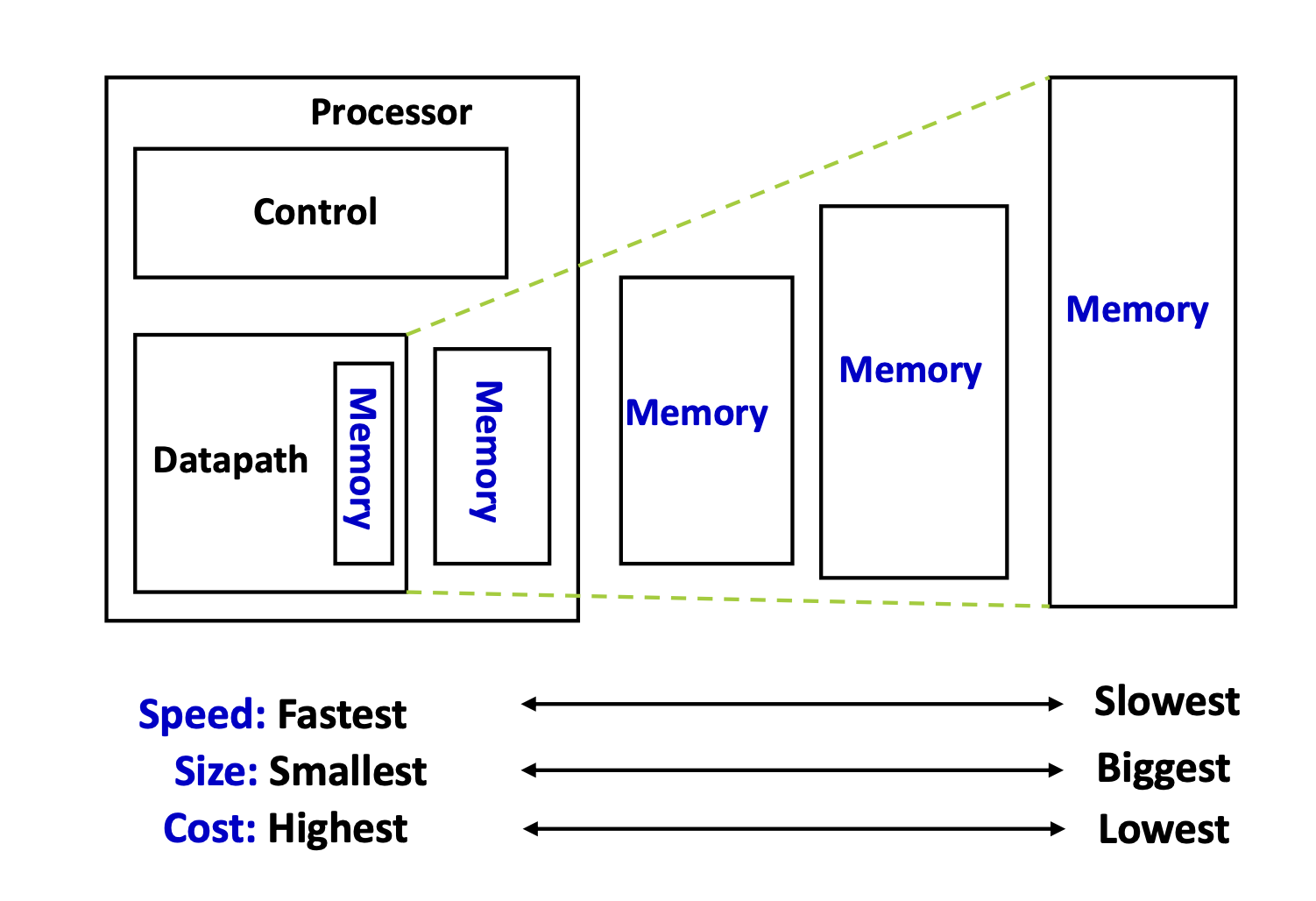
제안된 방안은 위의 그림과 같이 Processor에서 많이 활용되는 데이터일수록 용량은 작지만 속도는 빠른 메모리에 저장하고, 나머지는 속도는 비교적 느리지만 용량이 큰 메모리에 저장하는 방법이다.
위 구조에서 사용되는 빠른 메모리를 우리는 캐시(Cache)라 부르고,
이를 통해 비용은 저렴하지만 전체 시스템이 속도가 빠른 메모리로 구성된 것처럼 효과를 낼 수 있다.
3️⃣ 메모리 계층 구조
메모리 계층 구조에서는 Processor와 가까울수록 상위 계층, 멀어질수록 하위 계층이라고 표현한다.
일반적으로 상위 계층(캐시 메모리)에는 속도가 상대적으로 빠른 메모리를 사용하는데, 하위 계층(메인 메모리) 대비 용량이 더 적기 때문에 모든 데이터를 저장하는것이 아닌 Processor에서 비교적 많이 활용되는 데이터를 상위 계층에 저장한다.
Processor는 필요한 데이터를 상위 계층 메모리로부터 가져오고(Hit) 만약 없는 경우 더 많은 비용을 사용해서 하위 계층 메모리로부터 데이터를 가져오게 된다(Miss).
아래는 이러한 과정에 대한 용어를 정리해둔 표이다.
| 용어 | 설명 |
|---|---|
| Block | 메모리 계층 간 데이터를 주고받는 최소 단위 |
| Hit | 데이터가 상위 계층(캐시)에 존재할 때 발생 |
| Miss | 데이터가 상위 계층에 없어 하위 계층에서 가져와야 할 때 발생 |
| Hit rate | 상위 계층에서 접근이 성공한 비율 |
| Miss rate | 1 - 히트율, 접근 실패한 비율 |
| Hit time | 캐시 등 상위 계층에서 데이터 접근 시 걸리는 시간 |
| Miss penalty | 하위 계층에서 데이터를 가져오는 데 걸리는 시간 (히트 시간보다 훨씬 김) |
평균 접근 시간 (Average Access Time)
특정 계층의 메모리로부터 데이터를 가져오는 평균 접근 시간은 Hit/Miss에 의해 결정되는데
수식으로 나타내면 아래와 같다.
일반적으로 Miss penalty 시간이 훨씬 크기 때문에, Miss Rate/Penalty가 평균 접근 시간에 큰 영향을 끼친다고 할 수 있다.
캐시 메모리
캐시 메모리는 현재 컴퓨터 구조에서 Processor 속도와 메모리 속도 차이에 대한 문제를 해결해주는 굉장히 핵심적인 역할을 하고 있다. 앞에서는 캐시가 왜 중요한지 설명하기 위한 내용이었다면, 이제 본격적으로 캐시에 대한 내용을 다뤄보고자 한다.
1️⃣ 캐시 저장 기준(Locality)
앞서 캐시 메모리에는 Processor에서 많이 활용되는 데이터를 저장한다고 했는데,
많이 활용되는지를 어떻게 판단할 수 있을까? 우리가 작성한 Program을 보면 사용하는 데이터는 비교적 소수 영역의 데이터만을 사용하는데, 이를 지역성 원리(Principle of Locality)라고 한다.
Locality에는 2가지 유형이 있고, 이러한 기준에 의해 캐시 메모리에 저장될 데이터가 선별된다.
| 유형 | 특징 | 활용 방법 |
|---|---|---|
| 시간적(Temporal) 지역성 | 최근에 사용한 데이터가 다시 사용될 가능성이 높음 | 최근 사용한 데이터를 캐시에 저장 |
| 공간적(Spatial) 지역성 | 최근에 사용한 데이터의 주변 데이터가 다시 사용될 가능성이 높음 | 사용한 데이터의 인접 데이터를 블록 단위로 미리 캐시에 저장 |
2️⃣ 캐시 배치 방식
하위 계층의 데이터를 캐시 메모리에 배치/저장(Cache Arrangement)하는 방식에도 여러 가지가 있는데,
대표적으로 아래의 3가지 방식이 존재하며, 아래에서 각각의 방식과 장단점에 대해서 더 살펴보자.
- Direct Mapped : 하위 계층 메모리의 주소가 매핑된 캐시의 특정 위치에 배치 가능
- Fully Associative : 하위 계층 메모리의 주소가 캐시의 모든 위치에 배치 가능
- Set Associative : 하위 계층 메모리의 주소가 캐시의 특정 Set 내 여러 위치 중 하나에 배치 가능
Direct Mapped
Direct Mapped 방식에서는, 하위 계층 메모리의 주소마다 매핑되어 있는 캐시의 특정 주소가 존재한다.
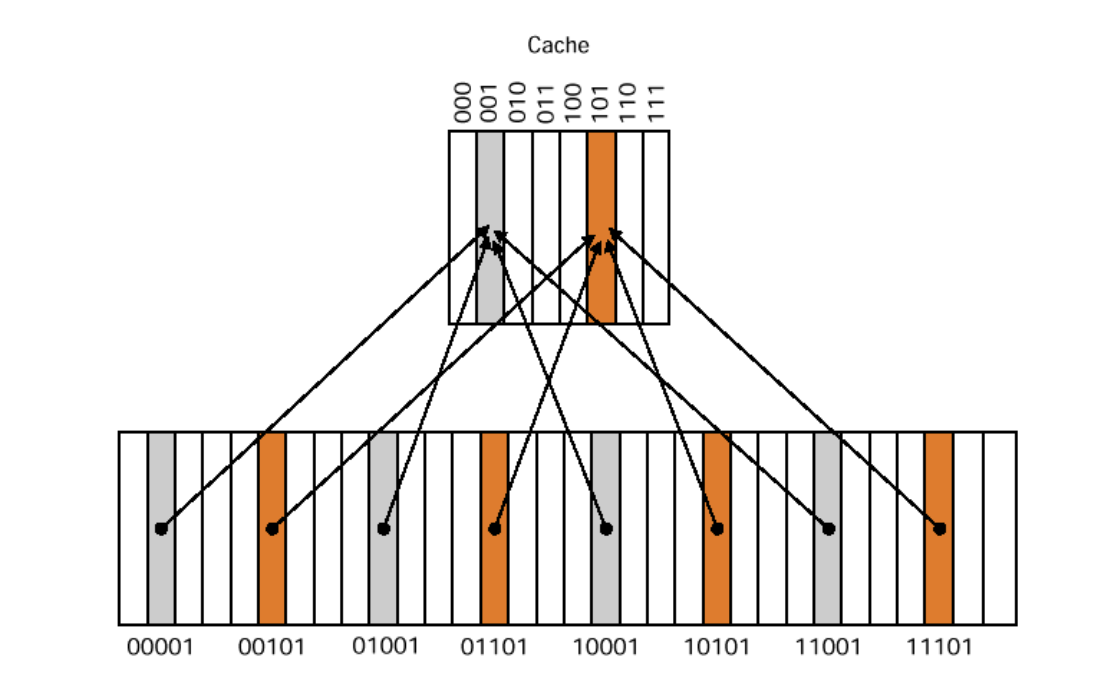
일반적으로 하위 계층의 메모리의 용량이 캐시보다 크기 때문에,
위의 그림과 같이 하위 계층 N개 주소가 캐쉬의 1개 주소에 매핑되어 데이터를 배치하는 방식이다.
이러한 방식은 간단한 구현 / 낮은 비용 / 빠른 접근 시간이라는 장점을 가지지만,
여러 메모리의 주소가 1개 캐시 주소를 공유하기 때문에 충돌이 빈번하게 발생한다는 단점이 있다.
Fully Associative
Direct Mapped 방식과 반대로, Fully Associative 방식은 하위 계층 메모리의 각각의 주소는 캐시의 모든 주소에 데이터를 배치할 수 있다.
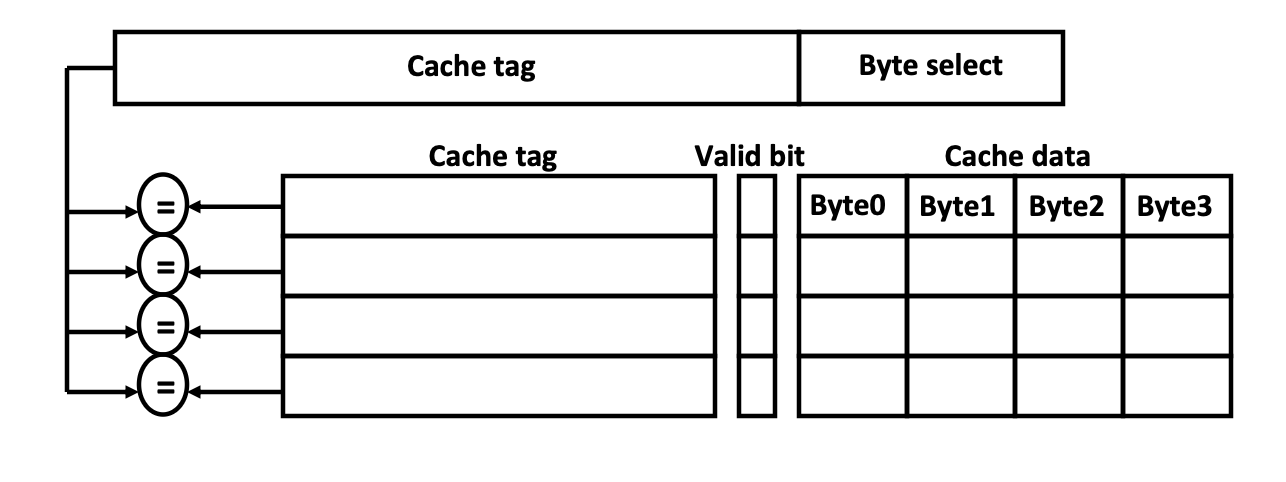
이는 데이터의 충돌이 발생할 일은 없겠지만,
각각의 캐시 주소를 모든 하위 계층 메모리의 주소에 연결해야하기 때문에 하드웨어 구조도 복잡해질 뿐더러, 캐시에 특정 주소에 접근할때 모든 메모리 주소에 대한 유효성 검사를 거쳐야하기 때문에 접근 시간이 더 길어진다는 단점이 존재한다.
N-Way Set Associative
앞서 언급한 2가지 방식 모두 비효율적인 방식이기 때문에,
이 2가지를 조합한 Hybrid 방식이 바로 N-Way Set Associative 방식이다.
이는 캐시 메모리를 여러 개의 Set으로 나누고 하위 계층 메모리의 주소를 1개 Set에 매핑하는 방식이며, N은 하나의 Set에 포함되어있는 캐시 주소의 개수를 의미한다.
하위 계층 메모리의 관점에서는 데이터를 배치할 수 선택지가 여러 개이기 때문에
Direct Mapped 방식 대비 데이터 충돌이 적고 Fully Associative 방식 대비 하드웨어 구조가 간단하다는 장점이 있다. 또한 N이 커질수록 충돌이 더 감소되지만 하드웨어 구조는 더 복잡해진다는 단점이 있다.
이러한 N-Way Set Associative 방식은 가장 널리 쓰이고 있는 효율적인 방식이다.
3️⃣ 캐시 Miss
앞서 캐시에 필요한 데이터가 존재하면 Hit, 없으면 Miss로 표현한다고 언급하였는데
캐시 Miss는 어떤 원인에 의해 발생하였는지에 따라 아래의 3가지로 나눌 수 있다.
- Cold Start(Compulsory)
- 해당 데이터에 처음 접근할때 발생하는 Miss
- 해결 방안 : Block Size 증가
- Capacity
- 캐시의 용량 부족으로 발생하는 Miss
- 해결 방안 : 캐시의 용량 증가
- Conflict
- 하위 계층의 여러 데이터가 캐시의 같은 위치에 매핑되어 발생하는 Miss
- 해결 방안 : Set에 포함되는 캐시 주소 증가 또는 캐시의 용량 증가
4️⃣ 캐시의 교체 및 쓰기 정책
캐시 교체 정책(Replacement Policy)
캐시에 저장할 데이터를 선별할때는 Locality 기준을 활용했었다.
그런데 만약 캐시에 데이터 가득 차 있다면? 그럼 어떤 데이터를 교체해야할까?
바로 아래의 2가지 기준이 캐시의 데이터 교체 정책이다.
- LRU (Least Recently Used)
- 가장 오랫동안 사용하지 않은 데이터를 교체하는 방식
- 시간적 지역성(Temporal Locality)에 적합하지만 구현 복잡성이 높다.
- Random
- 무작위로 데이터를 교체하는 방식
- 구현이 간단하며 실제 성능이 LRU와 큰 차이가 없기 때문에 종종 사용된다.
캐시 쓰기 정책(Write Policy)
데이터를 캐시에 배치하여 사용하는 경우, 캐시의 데이터는 원본 데이터가 아니기 때문에
실제 데이터가 저장되어 있는 메인 메모리와의 일관성을 유지할 필요가 있다.
캐시 쓰기 정책은 이와 관련된 정책이며 아래와 같은 방식이 있다.
- Write-through
- 캐시와 메모리를 동시에 업데이트, 구현 자체는 단순하지만 처리 속도가 느리다.
- Write-back
- 캐시만 업데이트하고 필요 시 메모리에 반영, 처리 속도는 빠르지만 데이터 일관성이 유지되지 않을 수 있다.
5️⃣ 캐시 성능 향상
캐시의 성능은 위에서 언급한 평균 접근 시간으로 나타낼 수 있고
Hit Time, Miss Penalty, Miss Rate 3가지에 의해 결정된다.
그럼 성능을 향상시키기 위해선, 위의 3가지 요소를 개선하면 되는데 각각 아래와 같은 방안이 있다.
- Hit Time 감소
- 캐시 크기 감소 (단 Miss Rate 증가, Capacity Miss)
- Direct Mapped 사용 (단 Miss Rate 증가, Conflict Miss)
- Miss Penalty 감소
- 캐시 크기 증가 (단 Hit Time 증가)
- Block 크기 증가 (단 Miss Penalty 증가)
- Associativity 사용 (단 Hit Time 증가)
- Hit Time 감소
- Multi-level 캐시 사용
