이 글은 김승룡 교수님의 AAI107 기계학습 강의를 듣고 정리한 글입니다.
벤치마크 데이터셋 설명 및 수상작들에 대한 성능..
AlexNet
VGG
GoogLeNet
GoogLeNet은 이름 그대로 Google 연구팀에서 개발한 CNN 구조이며,
VGG와 다른 구조를 사용하여 ImageNet 벤치마크에서 더 좋은 성능을 보였다는 점이 주목할 수 있다.
다만 ImageNet 벤치마크에서는 GoogLeNet이 더 좋은 성능을 보이지만, 다른 데이터셋에서는 반대인 경우도 있기 때문에 무조건 GoogLeNet이 더 좋다고 말할 수 없으니 참고하자.
1. 특징
GoogLetNet의 특징을 먼저 말해보자면,
- 계산 효율성을 고려한 Deep Neural Networks (with 22 layers)이다.
이를 위해 1️⃣ Inception module / 2️⃣ Stem / 3️⃣ Global Average Pooling을 사용하였다. - 5 million parameters (12x less than AlexNet)
- ILSVRC' 14 winner
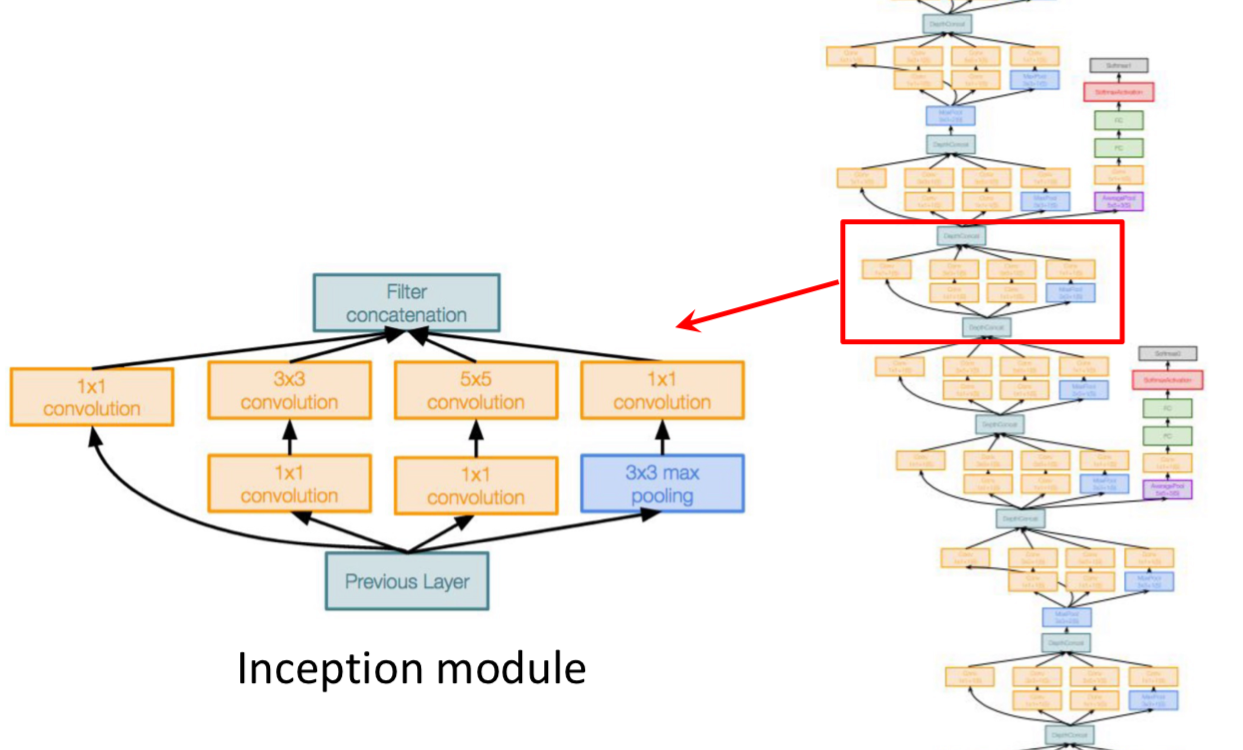
2. Inception Module
GoogLetNet의 가장 큰 특징이라고 할 수 있는 Inception Module에 대해서 알아보자.
여담으로, 영화 Inception의 대사 "We need to go deeper"에 착안하여 여기에도 Inception 이라는 명칭을 붙이게 됐다고 한다.
Inception Module이란,
Network within a network 구조를 통해서 다양한 Convolution/Pooling Layer를 병렬로 사용하여 다양한 의미를 가지는 Feature를 추출하고 이를 쌓아 올리는 방식을 말한다. (Good local network topology)
GoogLeNet에서 사용하고 있는 Inception Module은
1x1, 3x3, 5x5 Convolutional layer / 3x3 Pooling layer 총 4개의 경로로 구성되어 있다.
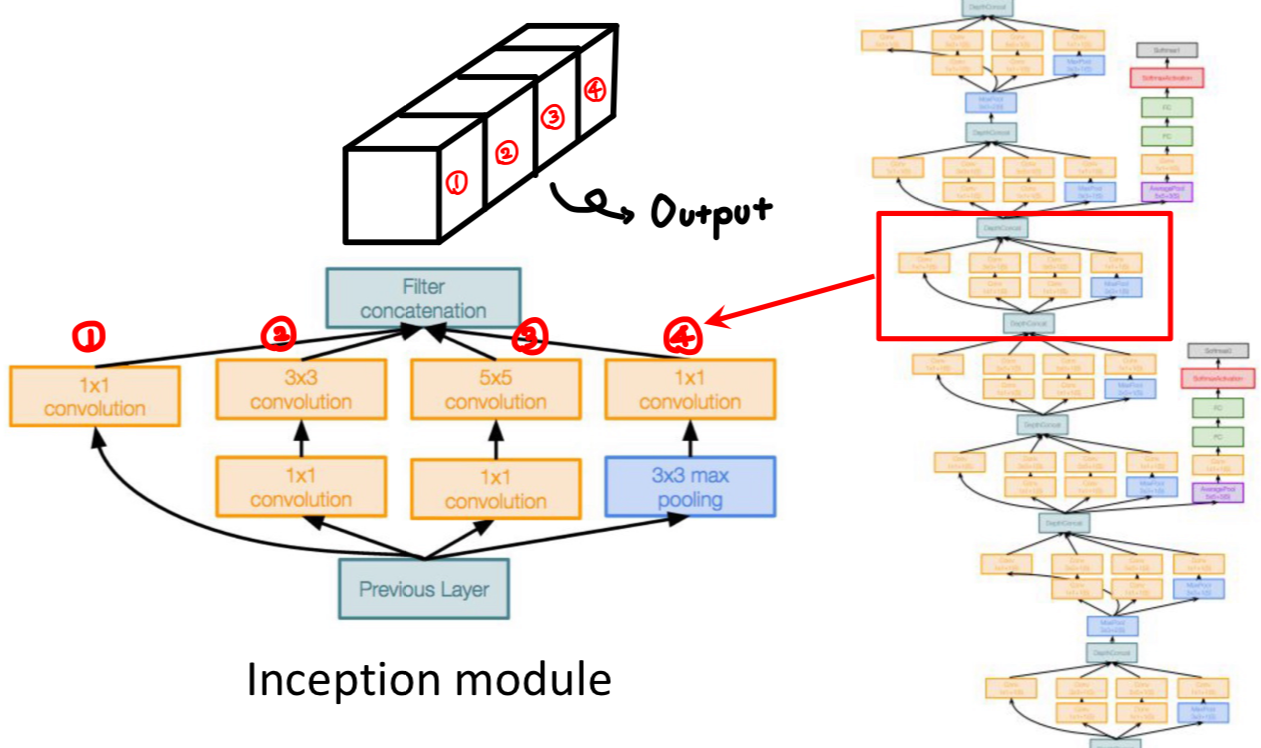
그리고 ②~④ 경로에는 1x1 Convolutional layer가 1개씩 더 추가되어 있는 것을 볼 수 있는데,
이는 Inception Module의 연산량을 줄이기 위한 Bottleneck layers 라고 한다.
Operations in inception module
만약 Bottleneck layers가 없는 Inception module을 사용한다면, 연산량이 너무 크다는 문제점이 있다.
Bottleneck layers가 없는 Naive inception module의 연산량을 한번 계산해보자.

Max Pooling의 연산량은 크지 않기 때문에 이를 제외하고 Convoloution의 연산량을 살펴보면,
입력이 28 X 28 X 256 일 때, 854 million의 연산이 필요하다.
또한, 입력의 채널 수는 256이지만 출력의 채널 수는 672으로 늘어난 것을 알 수 있다.
Max Pooling에서는 기존의 채널 수를 그대로 보존하여 출력으로 전달하고 있기 때문에
다음 Inception Module을 거쳐갈수록 Convolution 연산량은 계속 늘어날 것이다.
Bottleneck layers
연산량과 관련된 문제를 해결하기 위한 것이 바로 Bottleneck layers 이다.
이는 1x1 Convolutional layer에서 Filter 개수를 조절함으로써 출력의 채널 수를 조절하는 방법이다.
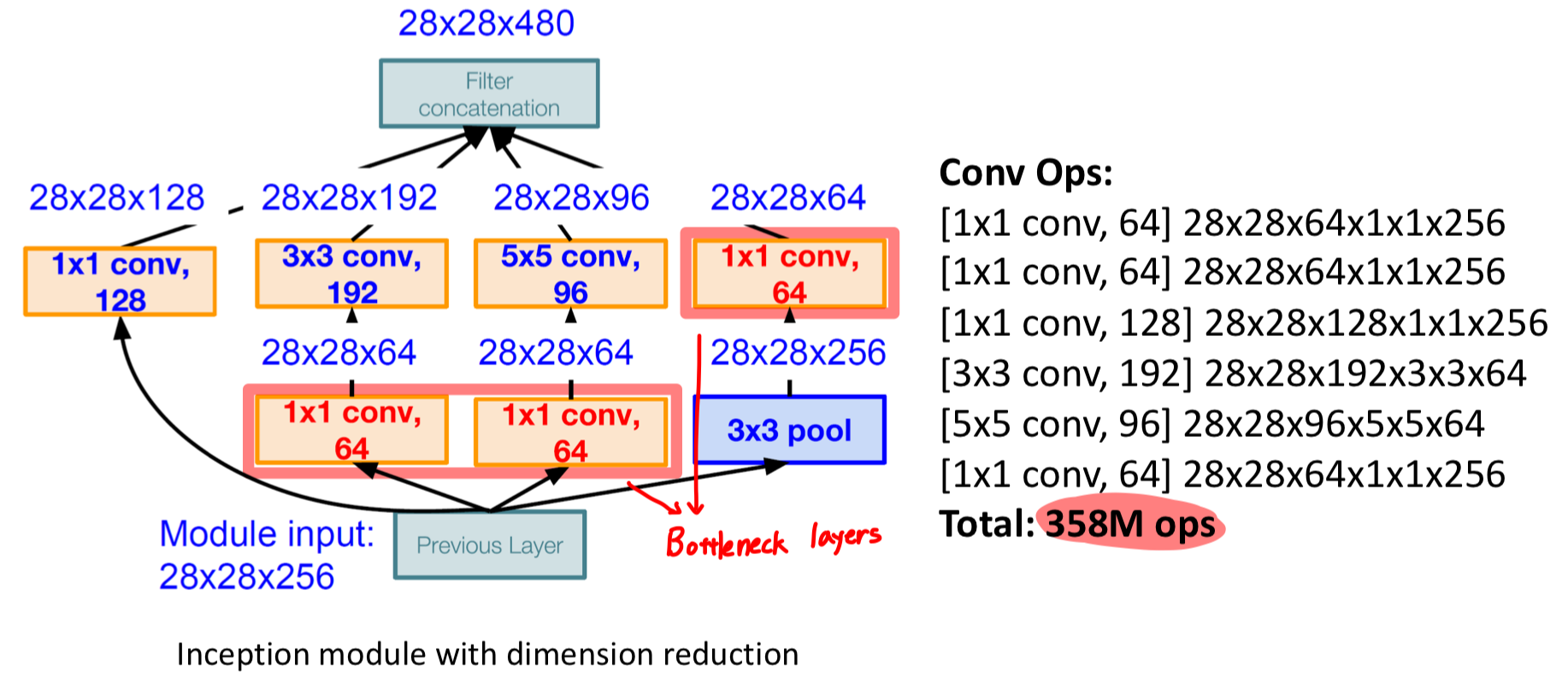
위의 그림에서처럼, 연산량은 Bottleneck layers 추가 전 854M ↔︎ 추가 후 358M 으로
연산량이 58% 가량 감소된 것을 확인할 수 있다.
3. Full Architecture
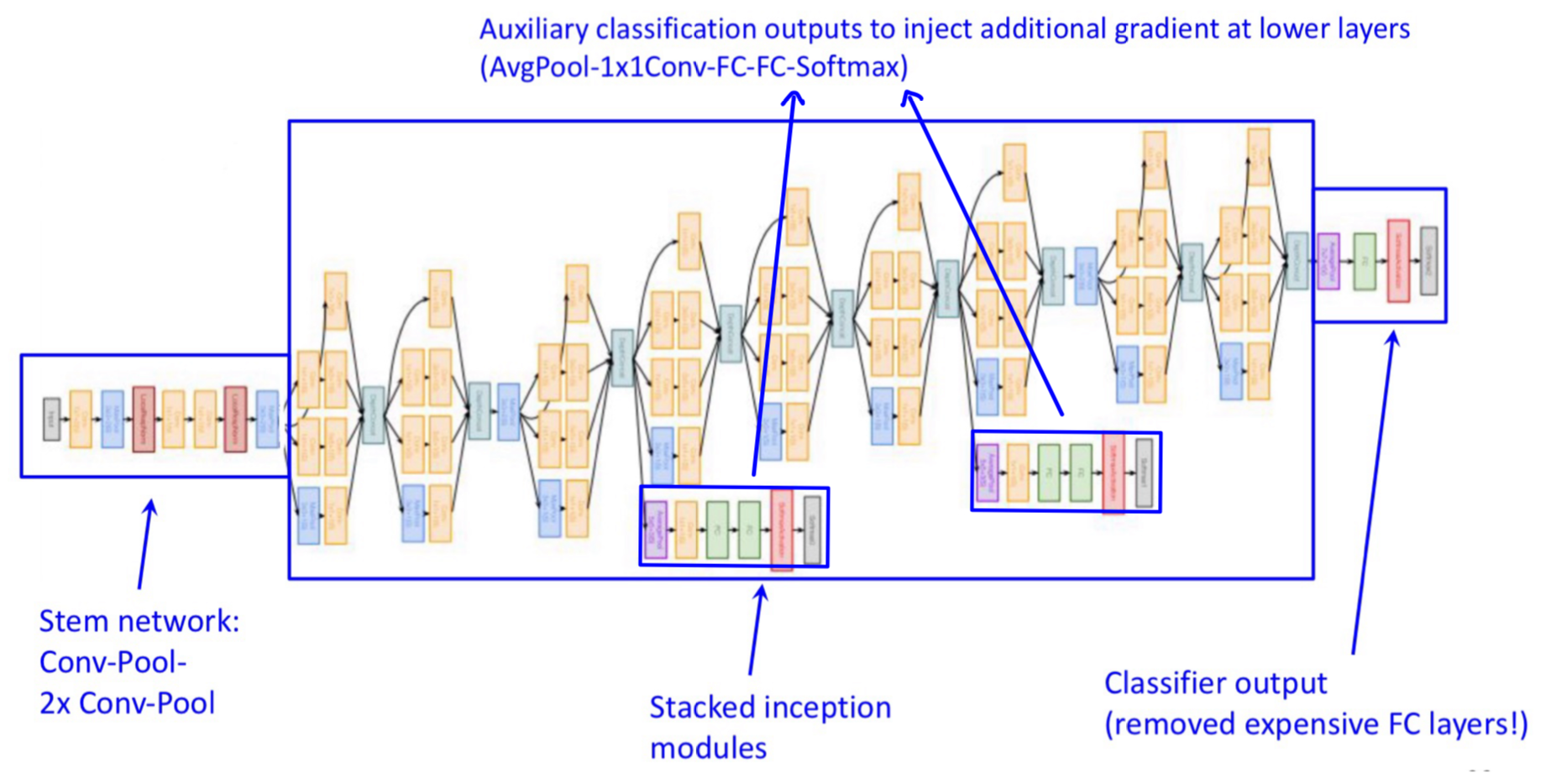
위의 그림은 GoogLeNet의 전체 구조이다.
여기서는 3가지 특징을 살펴볼 수 있는데 이는 앞선 CNN Architecture들의 문제점을 보완한다.
1) Stem network
입력이 크다면 초기에 사용되는 메모리 크기 또한 많이 요구되는데, VGG에서도 이러한 문제점이 존재한다.
GoogLeNet에서는 Stride를 활용하여 초기 입력의 크기를 224 X 224 → 56 X 56까지 줄이는데
이를 Stem network라고 말하고, 이후 Inception module을 통한 연산을 수행한다.
이는 초기 메모리 사용량을 확연히 줄일 수 있다는 장점이 있다.
2) Classifier output
GoogLeNet 이전의 Architecture를 살펴보면, Convolutional layer 이후 Fully-connected layer를 적용하여 여기에서 필요한 parameter가 굉장히 많은 것을 알 수 있다.
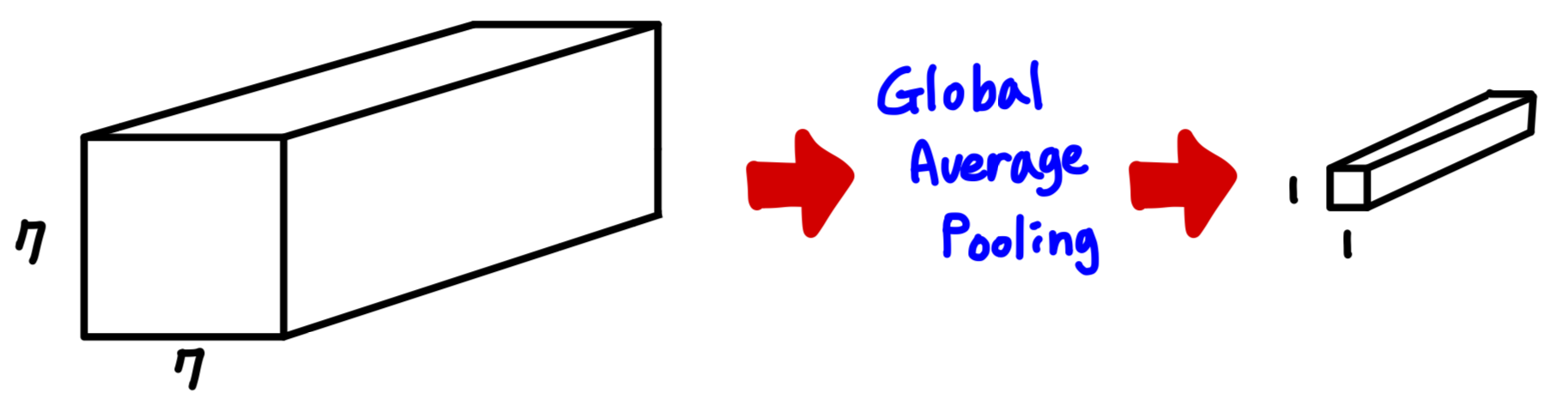
GoogLeNet에서는 이러한 문제를 해결하기 위해 "Global Average Pooling"을 수행한다.
각각 채널별로 Average pooling을 수행하여 채널별로 1개의 데이터만 남기고,
이후 Fully-connected layer를 수행하여 필요한 parameter를 줄이는 방법이다.
3) Auxiliary classification outputs
Neural networks의 Layer가 많아질수록,
Gradient Vanishing(Backpropagation 과정에서 특정 Local Gradient가 0과 유사한 값이 나오면 이후 layer의 학습이 제대로 되지 않는 현상) 문제가 많아졌다.
이러한 문제를 해결하기 위해, 전체 구조의 중간에 2개의 Classification output layer를 추가하여
학습 과정에서 각각의 output layer에 대해 (총 3개) Loss를 구하고 Backpropagation 과정에 사용함으로써, Gradient vanishing 문제를 일부 보완하였다.
Auxiliary classification outputs은 학습에만 활용하고, 실제 사용할때는 제거한다.
ResNet
ResNet은 앞서 말했던 Gradient Vanishing 문제에 집중하여 이를 해결함으로써,
Layer 수를 확연히 증가시키고 성능을 끌어올린 CNN Architecture이다.
1. 특징
ResNet의 특징은,
- Skip(Identity) connection을 이용한 Very Deep Networks (with 152 layers)
- ILSVRC' 15 winner
사실 특징이랄게 많이 없어보이지만,
Skip connection의 발견 하나로 Deep Learning에서의 굉장히 큰 혁신을 이끌었다고 말할 수 있다.
2. Skip Connection
Skip connection은 Residual/Identity connection으로도 명칭되며,
본문에서는 Skip connection 용어로 설명하고자 한다.
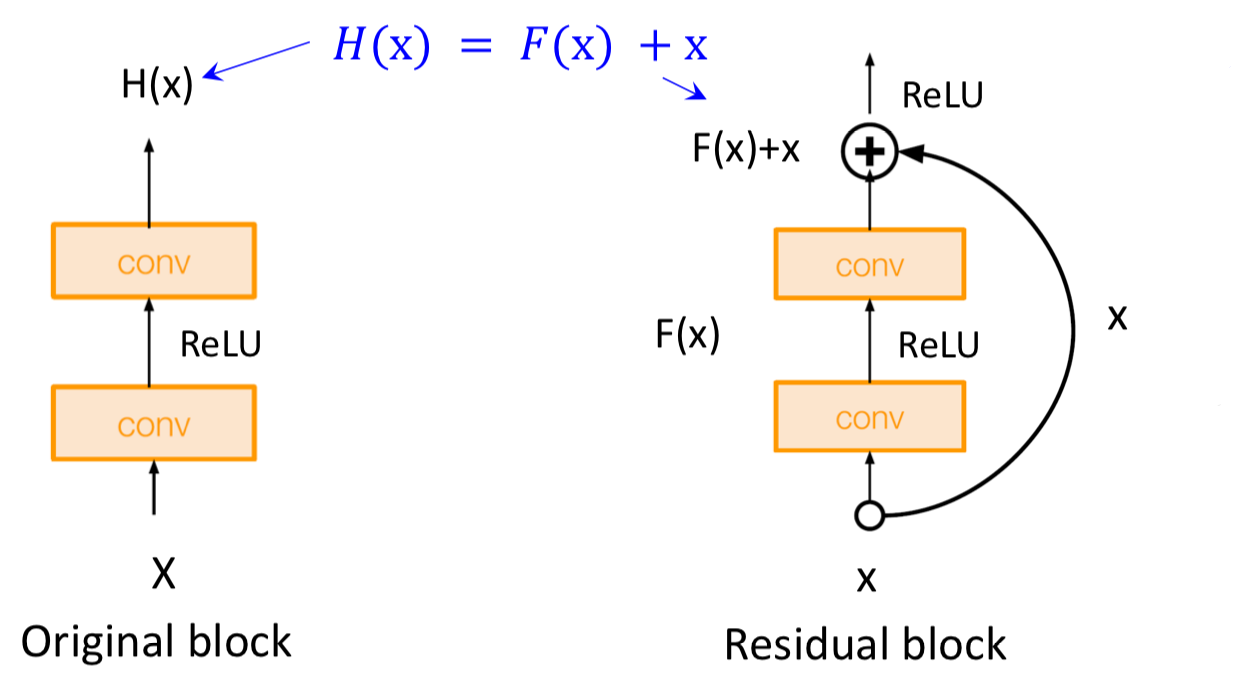
먼저 기존 구조와 ResNet에서 활용되는 구조인 Residual Block을 비교해보자.
Residual Block의 출력은 기존 구조의 출력에 입력을 더한 값임을 알 수 있다.
Backpropagation 과정을 살펴보면 이 구조가 어떻게 Gradient vanishing 문제를 극복하였는지 알 수 있다.
Backpropagation in ResNet
