이 글은 이소연 교수님의 자료구조 강의를 듣고 정리한 내용입니다.
자료구조 하면 Stack, Queue, List, Tree, Graph와 같이 한번씩 들어봄직한 자료구조들이 떠오를 것이다.
이러한 자료구조들을 하나하나 설명하기에 앞서,
①자료구조는 왜 필요한 것인지부터 시작해서, 자료 구조의 ②표현 방법과 ③성능 확인 방법에 대해 먼저 다룰 것이다.
자료구조와 알고리즘
첫번째 목차가 왜 자료구조와 알고리즘일까? 자료구조와 알고리즘은 떼놓을래야 떼놓을 수 없는 관계이다.
2개 모두 프로그램의 효율성을 높이기 위해 활용되는데, 자료구조는 데이터의 의해서 결정되며, 알고리즘은 자료구조에 따라서 결정된다. 아래에서 각각의 정의와 특징에 대해서 자세히 살펴보자.
1️⃣ 자료구조
먼저 자료구조는 프로그램에서 처리하는 자료를 저장하는 구조를 의미하며
프로그램에서 다루는 자료의 특성에 따라 효율을 높일 수 있는 구조로 정해진다.
대표적인 예로, Stack/Queue/Graph/Tree 등이 존재한다.
2️⃣ 알고리즘
다음 알고리즘은 컴퓨터로 특정 작업을 처리하기 위한 단계적인 절차이며, 작업을 수행하는 유한한 명령어들의 집합을 의미한다.
또한 어떤 알고리즘을 사용할지는, 어떤 자료구조를 사용하나에 따라 결정된다.
대표적인 예로, Stack을 활용한 DFS / Queue를 활용한 BFS 알고리즘이 있다.
알고리즘 조건
알고리즘이라고 말하기 위해선 몇가지 조건이 있는데, 아래 표를 참고하자.
| 조건 | 설명 |
|---|---|
| 입력 | 0개 이상의 입력 존재 |
| 출력 | 1개 이상의 출력 존재 |
| 명백성 | 명령어의 의미가 명확함 |
| 유한성 | 알고리즘이 반드시 끝나야 함 |
| 유효성 | 모든 명령어가 실행 가능한 연산이어야 함 |
알고리즘 기술방법
알고리즘은 앞서 말했듯이 여러 명령어들의 집합인데, 나열된 명령어를 보고 절차를 이해하기는 쉽지 않다. 그래서 알고리즘을 기술하기 위한 다양한 방법들이 있으며, 상황에 따라 다르지만 유사코드가 많이 사용 된다.
| 기술 방법 | 장점 | 단점 |
|---|---|---|
| 자연어 | 이해 쉬움 | 의미 전달의 모호함 |
| 흐름도 | 직관적 표현 | 복잡한 알고리즘의 표현 어려움 |
| 유사 코드 | 주요 내용 집중 | 실제 구현 세부사항 생략 |
| 프로그래밍 언어 | 정확한 기술 | 세부 구현 내용으로 인한 주요 내용 이해 방해 |
※ 유사 코드 예시

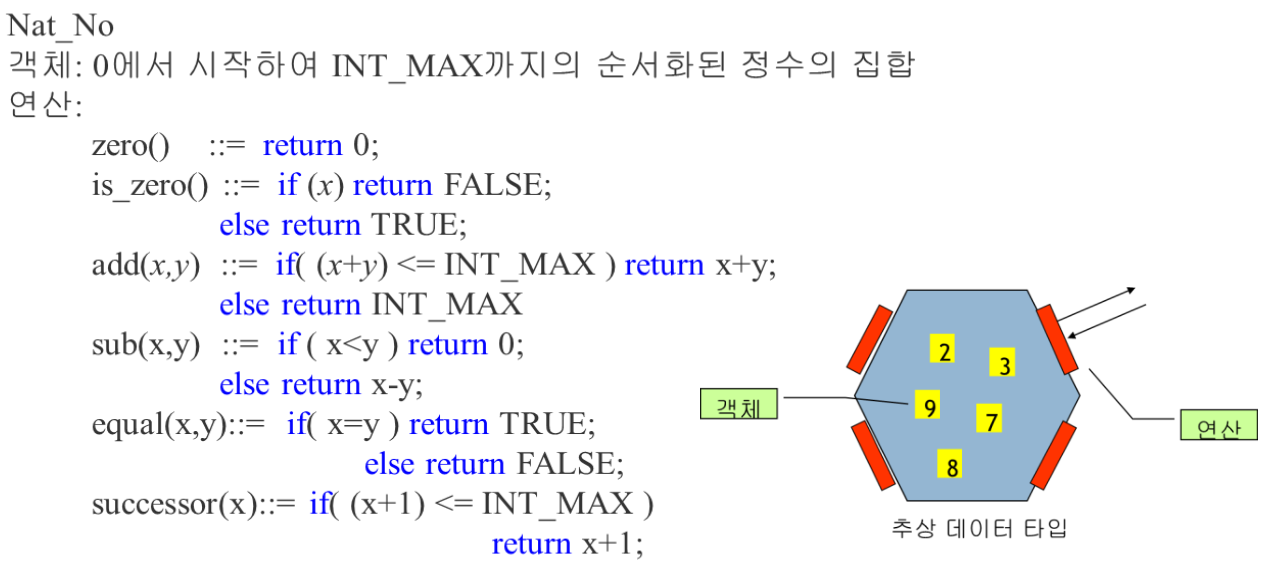
추상 데이터 타입
데이터 타입은 데이터의 종류를 의미하는데, C++에서는 기초 자료형(char,int 등), 파생 자료형(배열, 포인터), 사용자 정의 자료형(구조체, 공용체, 열거형)과 같은 자료형이 존재한다.
추상적 데이터 타입(Abstract Data Type, ADT)이란, 데이터 타입을 추상화하여 데이터나 연산이 무엇인지만을 정의하고 실제로 어떻게 구현되는지는 생략하는 것을 의미한다.
ADT 에는 객체와 연산 2가지가 정의되는데,
① 객체는 실제 추상적 데이터 타입에 속하는 개체를 의미하고
② 연산은 객체들 간의 연산을 의미하며 ADT와 외부를 연결하는 인터페이스 역할을 한다.
아래는 자연수(Nat_No)에 대한 ADT를 정의한 예시이다.
알고리즘의 성능 분석
알고리즘의 성능은 프로그램의 효율과 직결되기 때문에 사용하고자 하는 알고리즘의 성능이 어느정도 수준인지 분석하는 것이 중요하다. 따라서 성능을 분석하는 여러가지 기법에 대해서도 다루고자 한다.
1️⃣ 성능 분석 기법
성능을 분석하는 기법에는 ① 수행 시간을 측정하는 방안과 ② 알고리즘의 복잡도를 분석하는 방안 2가지가 있다.
수행 시간을 측정하는 경우는 결과가 직관적이지만, 알고리즘을 실제로 구현해야하고 하드웨어 환경을 동일하게 구성해야 하기 때문에 많은 제약이 있다.
반면 알고리즘의 복잡도를 분석하는 경우, 알고리즘 수행 시 필요로 하는 연산의 횟수를 측정하는 방식인 시간복잡도와 자원의 크기를 계산하는 공간 복잡도 2가지 유형이 있으며, 시간 복잡도를 많이 사용한다.
2️⃣ 시간 복잡도
시간 복잡도를 계산하는, 즉 연산의 횟수를 어떤식으로 측정하는지 살펴보자.
복잡도를 계산할때는 산술/대입/비교/이동 연산과 같은 기본적인 연산의 수행횟수만을 고려한다.
아래의 예와 같이 루프 제어 시의 연산은 제외됨을 기억하자.
예시에서는 최초에 수행되는 1번의 대입 연산과, 루프 내에서 n-1번의 비교 / n-1번의 대입 연산이 일어나며 마지막으로 1번의 반환 연산이 수행된다. 이를 모두 더하면 총 연산의 수는 2n임을 알 수 있다.
구해진 시간복잡도를 보면 입력의 수(n)에 의해 계산됨을 알 수 있다.
이를 다르게 표현하면 시간복잡도는 입력에 대한 함수이며, 이를 과 같이 표현한다.

3️⃣ 빅오 표기법
시간 복잡도는 2n, 3n, 6n² 등 다양하게 산출될 수 있는데,
이를 대략적(점근적)으로 표기한 것이 바로 빅오 표기법이다.
예를 들어 2n 또는 3n의 시간복잡도를 가지는 경우, O(n)으로 표기할 수 있으며
6n² 또는 n²의 시간복잡도를 가지는 경우, O(n²)으로 표기할 수 있다.
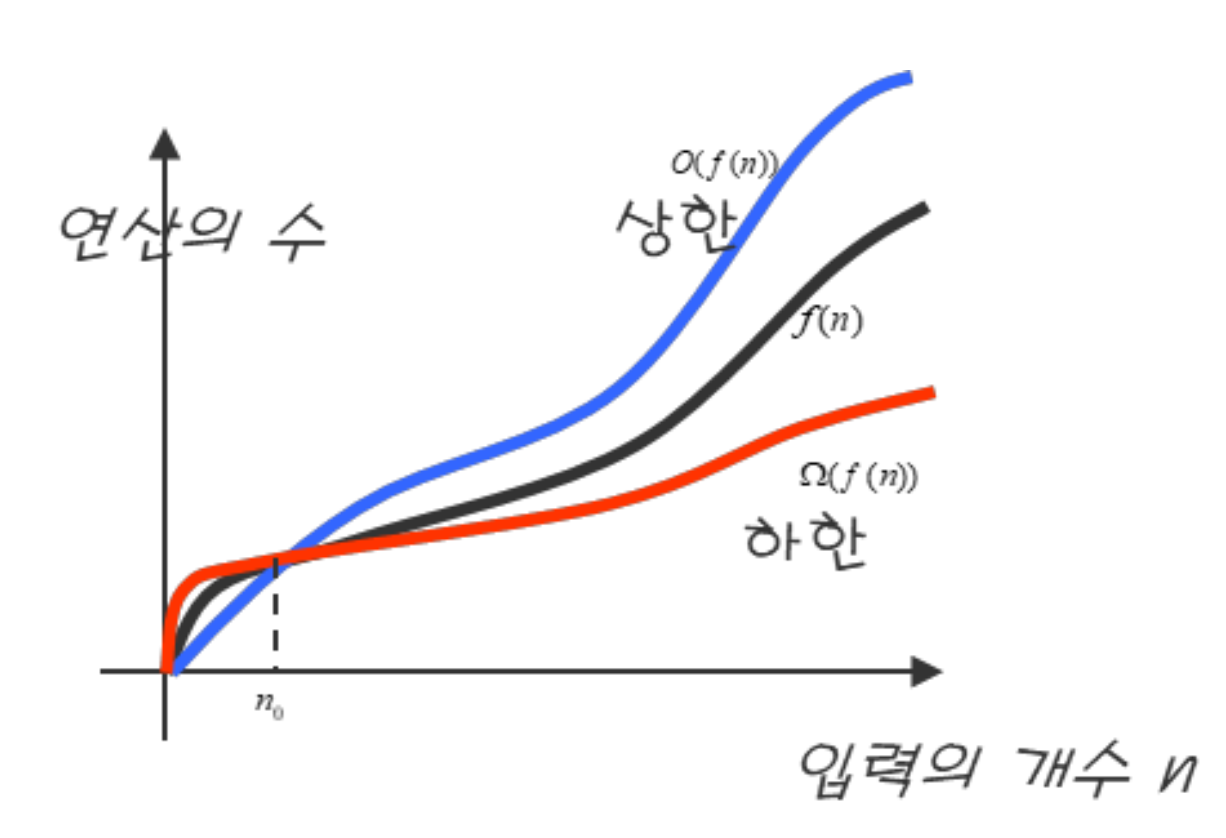
시간복잡도는 입력의 크기가 동일해도 알고리즘의 유형에 따라 실제 수행하는 연산의 수가 달라질 수 있는데, 빅오 표기법의 경우 최악의 경우를 가정한 연산의 수행 횟수라고 볼 수 있다.
반면 아래 그림과 같이, 최선의 경우를 가정하는 경우 빅오메가 표기법과
평균적인 경우를 가정하는 빅세타 표기법도 있으나, 실제로는 빅오 표기법을 가장 많이 사용한다.
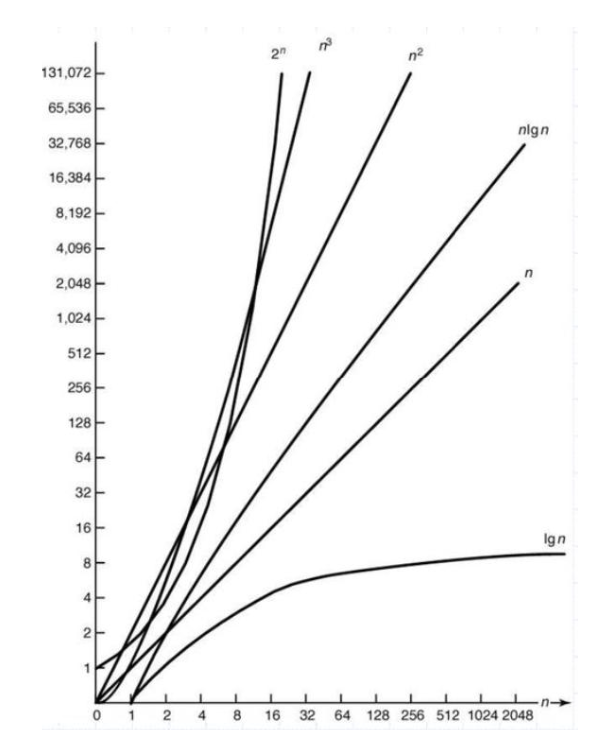
빅오 표기법의 종류
빅오 표기법의 주요한 유형을 시간 복잡도가 낮은 순서대로 나열하면, 아래 표와 같다.
| 구분 | O(1) | O(log n) | O(n) | O(n log n) | O(n²) | O(n³) | O(2ⁿ) | O(n!) |
|---|---|---|---|---|---|---|---|---|
| 설명 | 상수 시간 | 로그 시간 | 선형 시간 | 로그 선형 시간 | 2차형 시간 | 3차형 시간 | 지수 시간 | 팩토리얼 시간 |
표의 시간복잡도를 연산의 수행횟수(Y축)과 각각 입력의 수 n(X축)에 따라 차트로 표현한 것이 아래 그림이다. 현실적으로 입력의 수가 굉장히 작은 경우가 아니라면, 수행횟수가 지수적으로 증가하는 O(2ⁿ), O(n!)의 시간복잡도를 가지는 알고리즘은 사용하기 어렵고, O(n log n) 이하의 시간복잡도를 가지는 알고리즘은 성능이 좋다고 볼 수 있다.