
📌 Notice
Kubernetes Advanced Networking Study (=KANS)
k8s 네트워크 장애 시, 네트워크 상세 동작 원리를 기반으로 원인을 찾고 해결하는 내용을 정리한 블로그입니다.
CloudNetaStudy그룹에서 스터디를 진행하고 있습니다.
Gasida님께 다시한번 🙇 감사드립니다.
EKS 관련 이전 스터디 내용은 아래 링크를 통해 확인할 수 있습니다.

📌 Summary
-
Amazon VPC CNI를 활용해 EKS 클러스터 내 파드가 VPC 네이티브 네트워크에 연결되도록 설정하고, 네트워크 구성 원리를 실습합니다.
-
AWS Load Balancer Controller와 eBPF 기반 네트워크 정책을 통해 Blue/Green 배포, Canary 배포 등 다양한 배포 전략과 통신 제어 방안을 실습합니다.
-
Cilium CNI와 AWS VPC CNI의 혼합 구성을 통해 네트워크 성능 최적화 및 효율적 자원 관리를 실현합니다.
📌 Study
👉 Step 00. AWS VPC CNI 소개
K8S CNI : Container Network Interface 는 k8s 네트워크 환경을 구성해준다 - 링크, 다양한 플러그인이 존재 - 링크
Amazon EKS에서 클러스터 네트워킹은 Amazon VPC Container Network Interface(VPC CNI) 플러그인을 통해 구현됩니다. 이 플러그인은 쿠버네티스 파드(Pod)가 VPC 네트워크와 동일한 IP 주소를 가질 수 있도록 해줍니다. 보다 구체적으로, 파드 내부의 모든 컨테이너는 네트워크 네임스페이스를 공유하며, 로컬 포트를 통해 서로 통신할 수 있습니다.
Amazon VPC CNI의 구성 요소
Amazon VPC CNI는 두 가지 주요 구성 요소로 이루어져 있습니다:
CNI 바이너리 (CNI Binary)
- Pod 간 통신(Pod-to-Pod Communication)을 설정하는 역할을 담당합니다. 이 바이너리는 노드의 루트 파일 시스템에서 실행되며, 새로운 파드가 추가되거나 기존 파드가 제거될 때 kubelet에 의해 호출됩니다.
ipamd
- IP 주소 관리(IPAM) 역할을 하는 노드 로컬 데몬입니다. 지속적으로 실행되며 다음과 같은 역할을 수행합니다:
- 노드에서 ENI(Elastic Network Interface)를 관리합니다.
- 사용 가능한 IP 주소 또는 프리픽스의 워밍 풀(warm pool)을 유지합니다.
ENI 및 warm pool
인스턴스가 생성될 때 EC2는 기본 ENI(primary ENI)를 만들고 이를 기본 서브넷(primary subnet)에 연결합니다. 이 기본 서브넷은 퍼블릭 또는 프라이빗일 수 있습니다. hostNetwork 모드로 실행되는 파드는 노드의 기본 ENI에 할당된 기본 IP 주소를 사용하고 호스트와 동일한 네트워크 네임스페이스를 공유합니다.CNI 플러그인은 노드에서 ENI를 관리하며, 노드가 프로비저닝되면 서브넷에서 기본 ENI로 IP 또는 프리픽스 슬롯의 풀(pool)을 자동으로 할당합니다. 이를 워밍 풀(warm pool)이라고 하며, 크기는 노드의 인스턴스 유형에 따라 결정됩니다. CNI 설정에 따라 슬롯은 IP 주소 또는 프리픽스일 수 있습니다. ENI의 슬롯이 할당되면 CNI는 추가 ENI를 노드에 연결하여 워밍 풀을 유지합니다. 이러한 추가 ENI는 Secondary ENI라고 합니다. 각 ENI는 인스턴스 유형에 따라 지원할 수 있는 슬롯 수가 다릅니다. 필요한 슬롯 수, 즉 파드 수에 따라 CNI는 추가 ENI를 인스턴스에 연결하며, 이 과정은 노드가 추가 ENI를 지원할 수 없을 때까지 계속됩니다. 또한, CNI는 파드의 시작 속도를 높이기 위해 "워밍" ENI와 슬롯을 미리 할당합니다. 각 인스턴스 유형에는 연결할 수 있는 최대 ENI 수가 있으며, 이는 노드당 파드 수(Pod Density)를 제한하는 요소 중 하나입니다.
✅ 인스턴스 유형에 따른 최대 파드 수
사용할 수 있는 네트워크 인터페이스의 최대 수와 슬롯의 수는 EC2 인스턴스 유형에 따라 달라집니다. 각 파드는 슬롯의 IP 주소 하나를 소비하므로, 특정 EC2 인스턴스에서 실행할 수 있는 파드 수는 연결 가능한 ENI 수와 ENI가 지원하는 슬롯 수에 의해 결정됩니다. EKS 사용자 가이드에서 제안하는 최대 파드 수를 설정하면 인스턴스의 CPU 및 메모리 리소스 고갈을 방지할 수 있습니다. hostNetwork를 사용하는 파드는 이 계산에서 제외됩니다. max-pod-calculator.sh 스크립트를 사용하면 인스턴스 유형에 따라 권장되는 최대 파드 수를 계산할 수 있습니다.
👉 Step 01. 노드에서 기본 네트워크 정보 확인
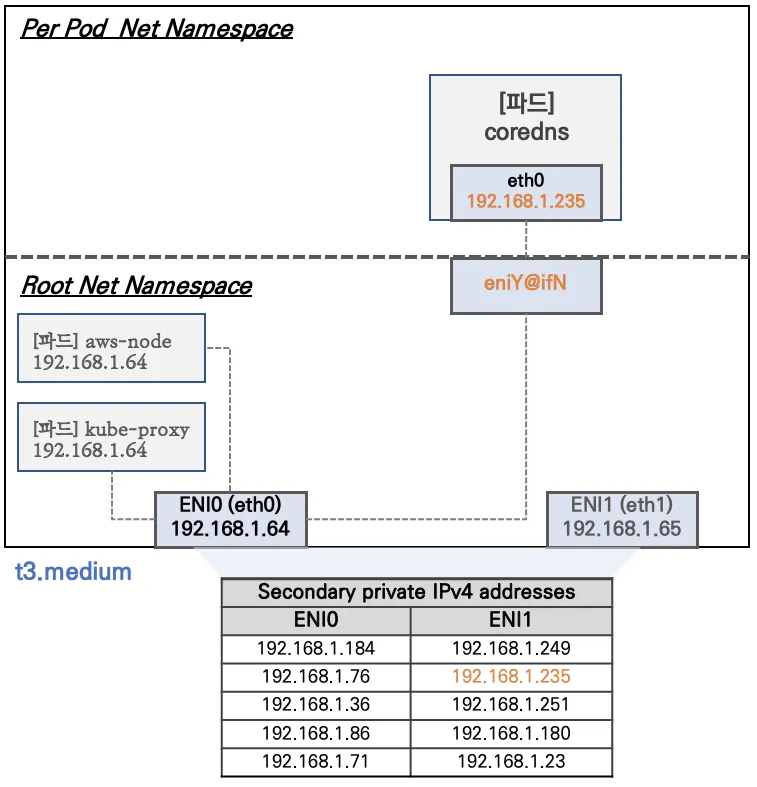
워커 노드1 기본 네트워크 구성 : 워커 노드2 는 구성이 유사하여 생략
 출처 - cloudNet@
출처 - cloudNet@
-
Network 네임스페이스는 호스트(Root)와 파드 별(Per Pod)로 구분된다
-
특정한 파드(kube-proxy, aws-node)는 호스트(Root)의 IP를 그대로 사용한다 ⇒ 파드의 Host Network 옵션
-
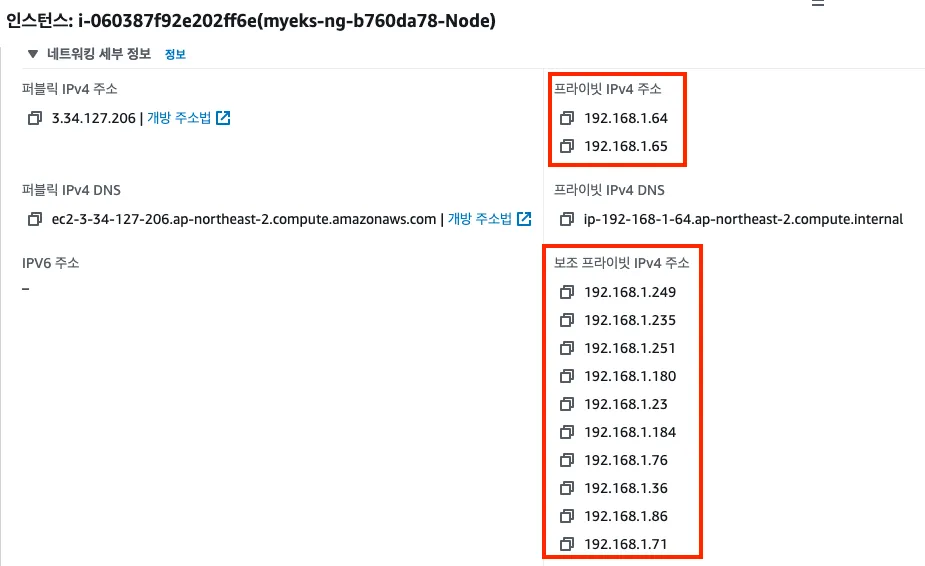
t3.medium 의 경우 ENI 마다 최대 6개의 IP를 가질 수 있다
-
ENI0, ENI1 으로 2개의 ENI는 자신의 IP 이외에 추가적으로 5개의 보조 프라이빗 IP를 가질수 있다
-
coredns 파드는
veth으로 호스트에는eniY@ifN 인터페이스와 파드에eth0과 연결되어 있다
🔥 실습
보조 IPv4 주소를 파드가 사용하는지 확인
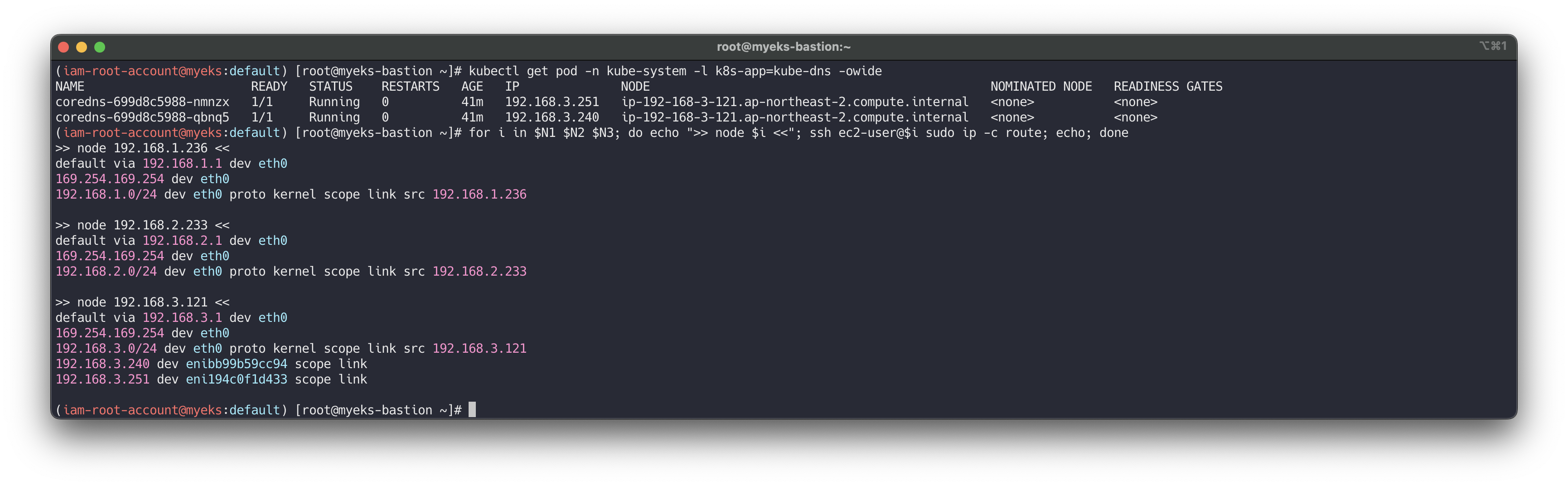
# coredns 파드 IP 정보 확인 kubectl get pod -n kube-system -l k8s-app=kube-dns -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES coredns-6777fcd775-57k77 1/1 Running 0 70m 192.168.1.142 ip-192-168-1-251.ap-northeast-2.compute.internal <none> <none> coredns-6777fcd775-cvqsb 1/1 Running 0 70m 192.168.2.75 ip-192-168-2-34.ap-northeast-2.compute.internal <none> <none> # 노드의 라우팅 정보 확인 >> EC2 네트워크 정보의 '보조 프라이빗 IPv4 주소'와 비교해보자 for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo ip -c route; echo; done
테스트용 파드 생성
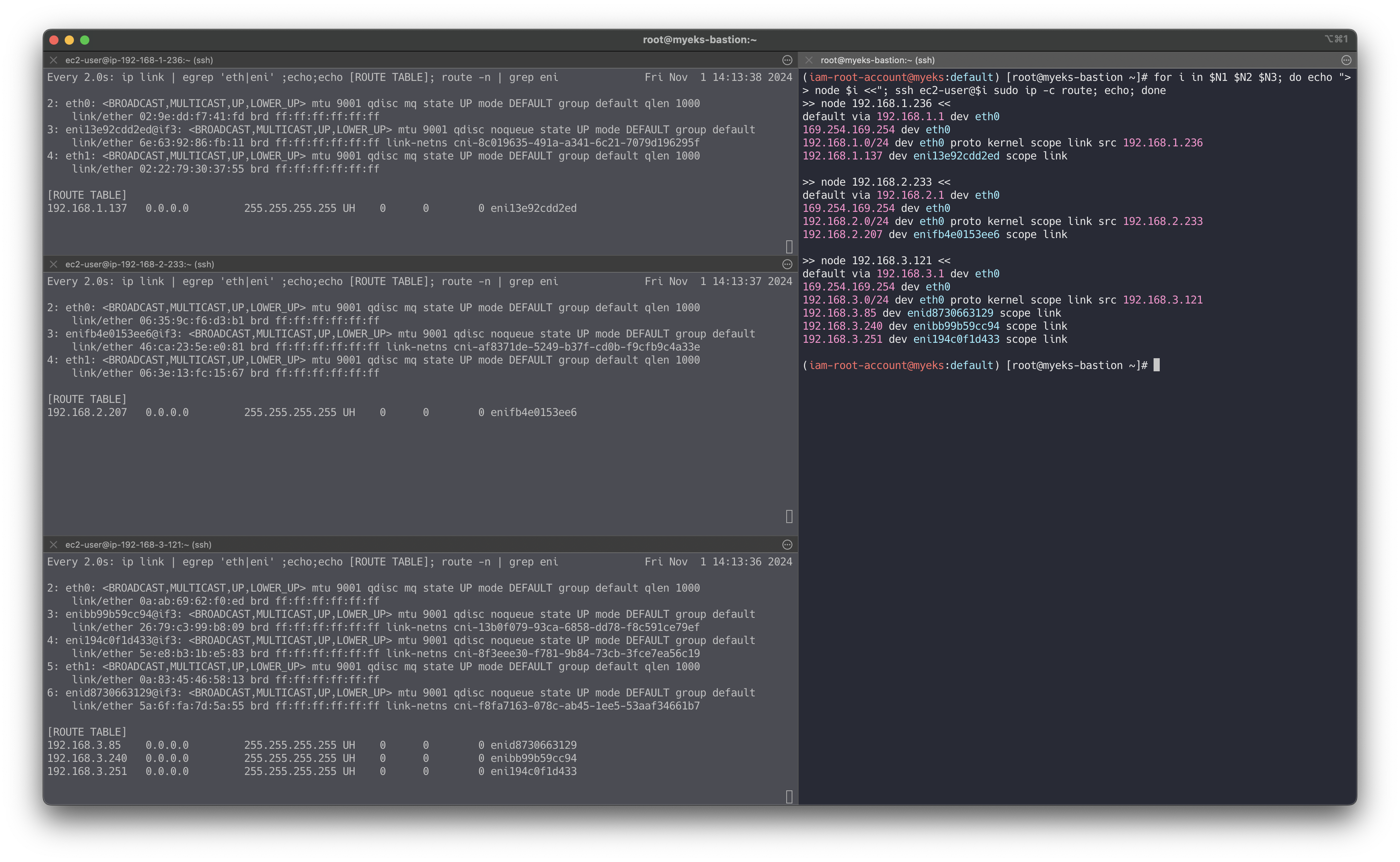
# [터미널1~3] 노드 모니터링 ssh ec2-user@$N1 watch -d "ip link | egrep 'eth|eni' ;echo;echo "[ROUTE TABLE]"; route -n | grep eni" ssh ec2-user@$N2 watch -d "ip link | egrep 'eth|eni' ;echo;echo "[ROUTE TABLE]"; route -n | grep eni" ssh ec2-user@$N3 watch -d "ip link | egrep 'eth|eni' ;echo;echo "[ROUTE TABLE]"; route -n | grep eni" # 테스트용 파드 netshoot-pod 생성 cat <<EOF | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: netshoot-pod spec: replicas: 3 selector: matchLabels: app: netshoot-pod template: metadata: labels: app: netshoot-pod spec: containers: - name: netshoot-pod image: nicolaka/netshoot command: ["tail"] args: ["-f", "/dev/null"] terminationGracePeriodSeconds: 0 EOF # 파드 이름 변수 지정 PODNAME1=$(kubectl get pod -l app=netshoot-pod -o jsonpath={.items[0].metadata.name}) PODNAME2=$(kubectl get pod -l app=netshoot-pod -o jsonpath={.items[1].metadata.name}) PODNAME3=$(kubectl get pod -l app=netshoot-pod -o jsonpath={.items[2].metadata.name}) # 파드 확인 kubectl get pod -o wide kubectl get pod -o=custom-columns=NAME:.metadata.name,IP:.status.podIP # 노드에 라우팅 정보 확인 for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo ip -c route; echo; done
- 파드가 생성되면, 워커 노드에 eniY@ifN 추가되고 라우팅 테이블에도 정보가 추가된다
- 테스트용 파드 eniY 정보 확인 - 워커 노드 EC2
# 노드3에서 네트워크 인터페이스 정보 확인 ssh ec2-user@$N3 ---------------- ip -br -c addr show ip -c link ip -c addr ip route # 혹은 route -n # 마지막 생성된 네임스페이스 정보 출력 -t net(네트워크 타입) sudo lsns -o PID,COMMAND -t net | awk 'NR>2 {print $1}' | tail -n 1 # 마지막 생성된 네임스페이스 net PID 정보 출력 -t net(네트워크 타입)를 변수 지정 MyPID=$(sudo lsns -o PID,COMMAND -t net | awk 'NR>2 {print $1}' | tail -n 1) # PID 정보로 파드 정보 확인 sudo nsenter -t $MyPID -n ip -c addr sudo nsenter -t $MyPID -n ip -c route exit ----------------
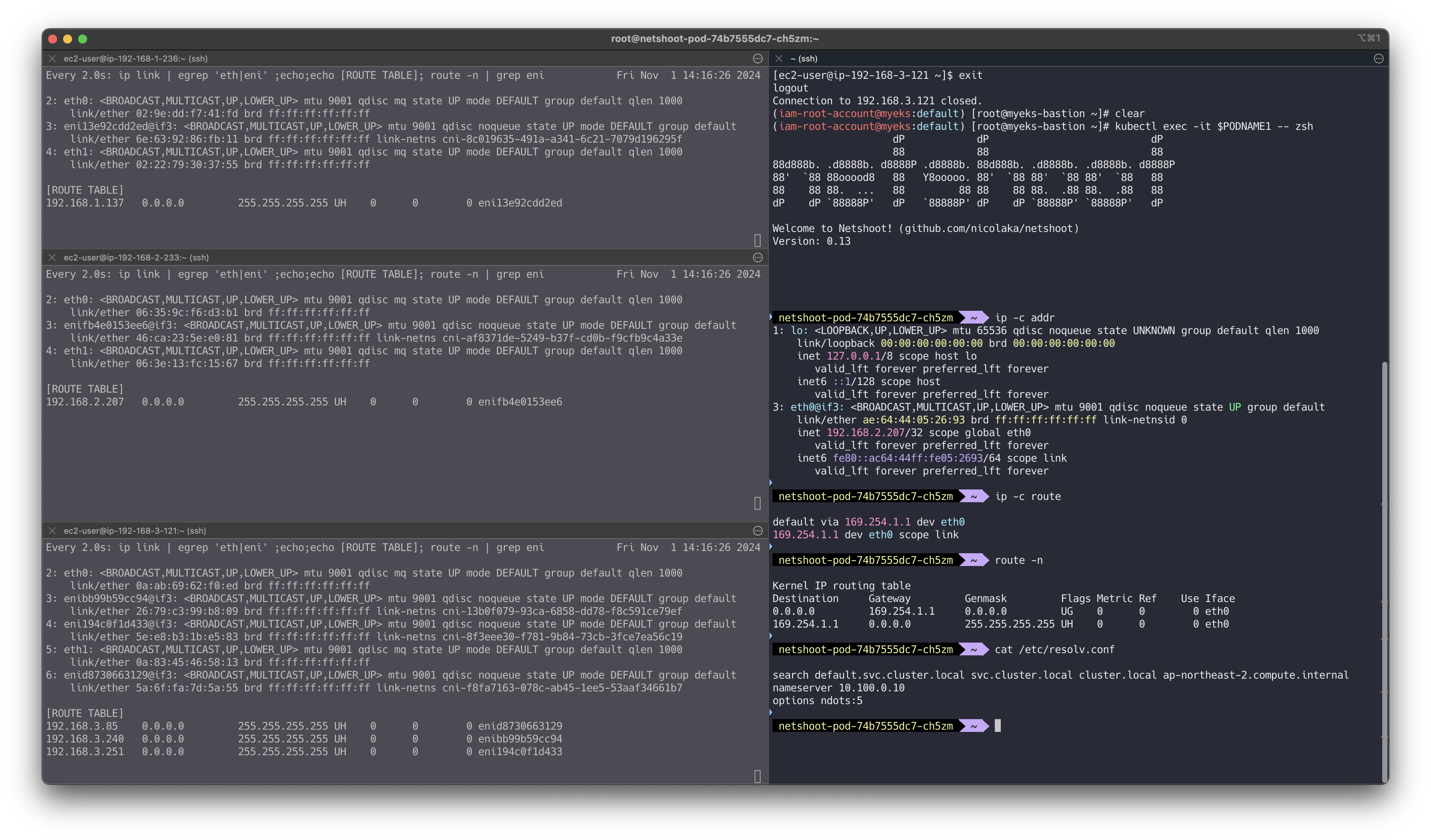
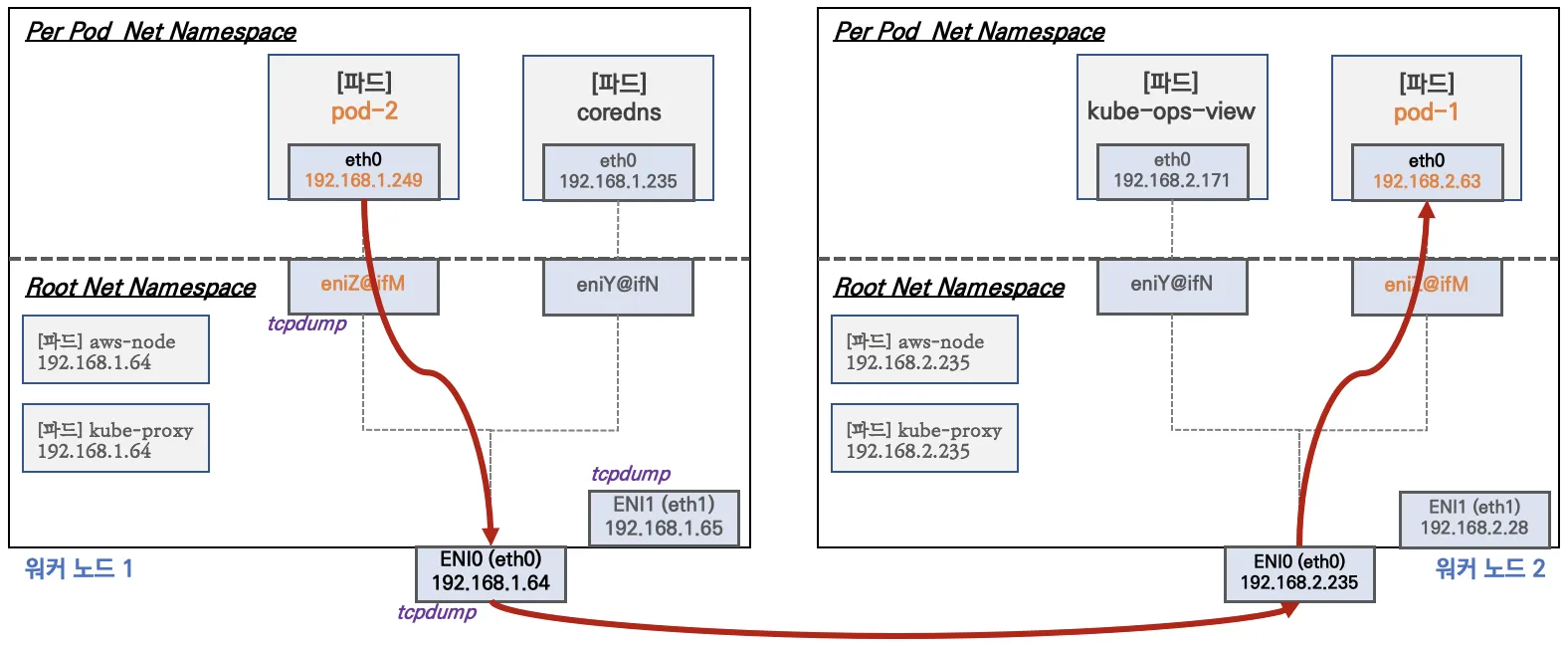
👉 Step 02. 노드 간 파드 통신
파드간 통신 시 tcpdump 내용을 확인하고 통신 과정을 알아보겠습니다.
파드간 통신 흐름 : AWS VPC CNI 경우 별도의 오버레이(Overlay) 통신 기술 없이, VPC Native 하게 파드간 직접 통신이 가능하다
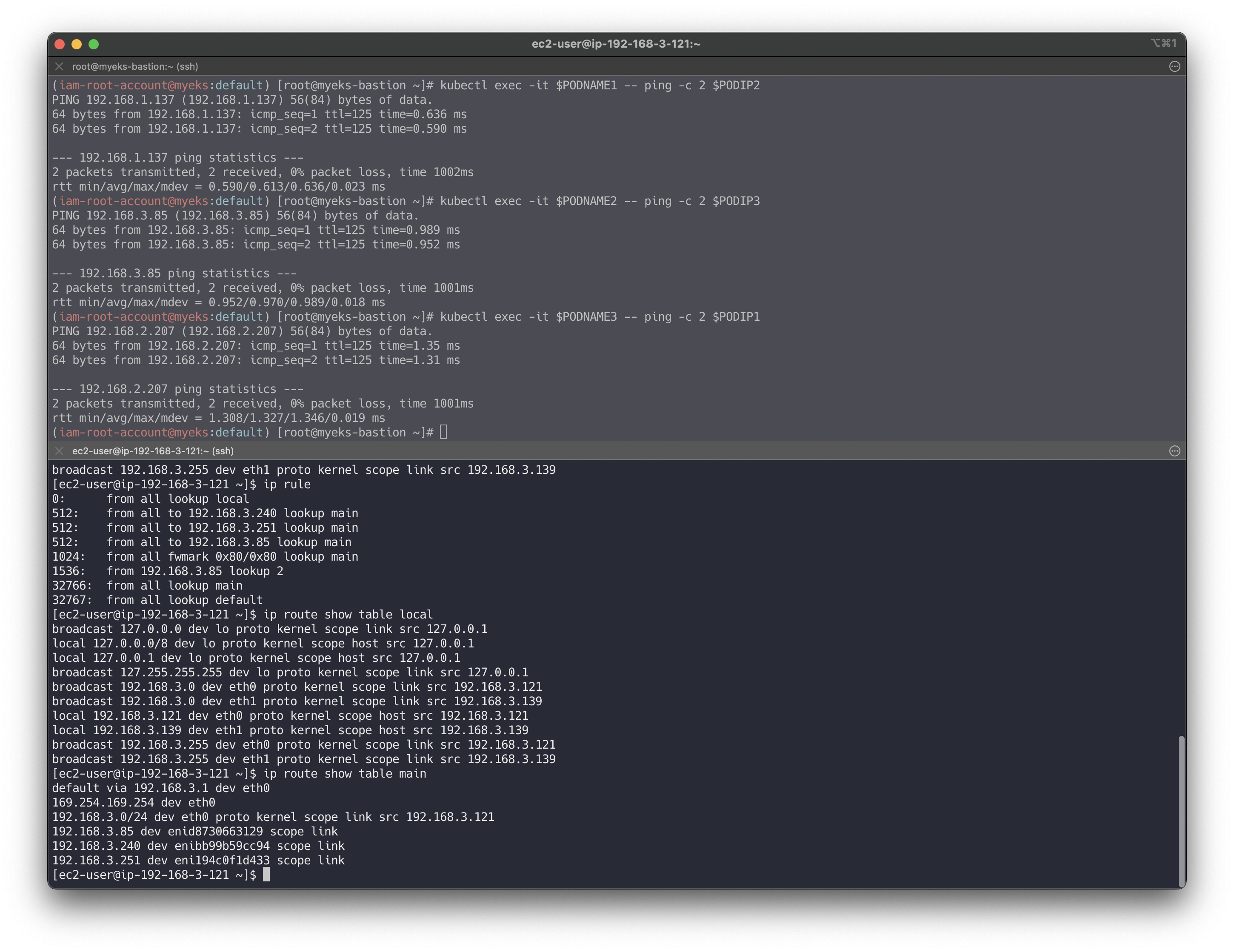
🔥 실습
별도의 NAT 동작 없이 통신 가능!
# 파드 IP 변수 지정 PODIP1=$(kubectl get pod -l app=netshoot-pod -o jsonpath={.items[0].status.podIP}) PODIP2=$(kubectl get pod -l app=netshoot-pod -o jsonpath={.items[1].status.podIP}) PODIP3=$(kubectl get pod -l app=netshoot-pod -o jsonpath={.items[2].status.podIP}) # 파드1 Shell 에서 파드2로 ping 테스트 kubectl exec -it $PODNAME1 -- ping -c 2 $PODIP2 # 파드2 Shell 에서 파드3로 ping 테스트 kubectl exec -it $PODNAME2 -- ping -c 2 $PODIP3 # 파드3 Shell 에서 파드1로 ping 테스트 kubectl exec -it $PODNAME3 -- ping -c 2 $PODIP1 # 워커 노드 EC2 : TCPDUMP 확인 ## For Pod to external (outside VPC) traffic, we will program iptables to SNAT using Primary IP address on the Primary ENI. sudo tcpdump -i any -nn icmp sudo tcpdump -i eth1 -nn icmp sudo tcpdump -i eth0 -nn icmp sudo tcpdump -i eniYYYYYYYY -nn icmp [워커 노드1] # routing policy database management 확인 ip rule # routing table management 확인 ip route show table local # 디폴트 네트워크 정보를 eth0 을 통해서 빠져나간다 ip route show table main default via 192.168.1.1 dev eth0 ...
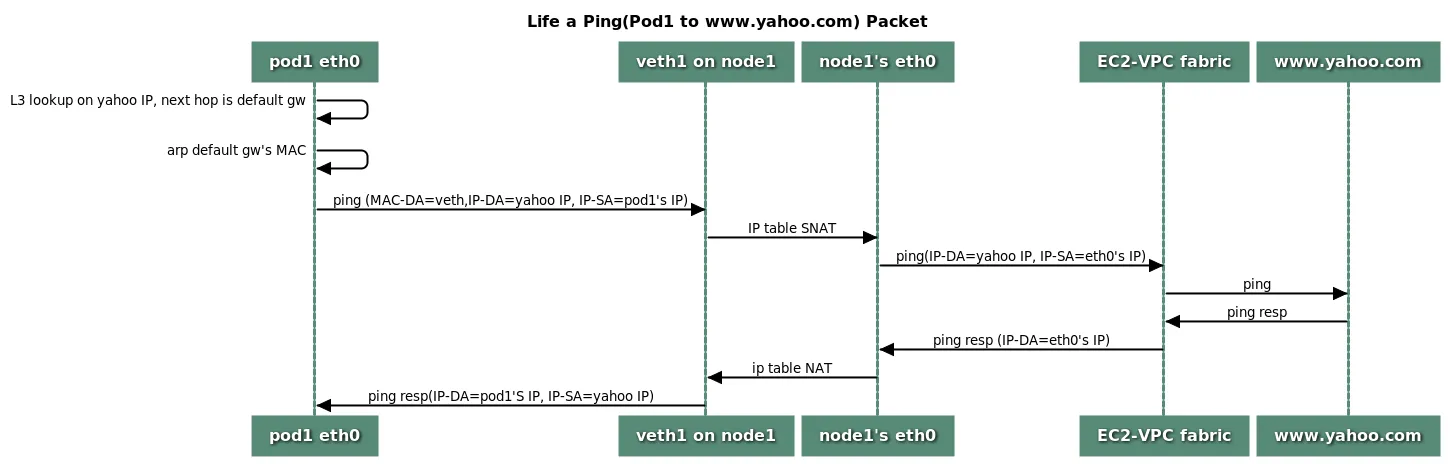
👉 Step 03. 파드에서 외부 통신
파드에서 외부 통신 흐름 : iptable 에 SNAT 을 통하여 노드의 eth0 IP로 변경되어서 외부와 통신됨
 https://github.com/aws/amazon-vpc-cni-k8s/blob/master/docs/cni-proposal.md
https://github.com/aws/amazon-vpc-cni-k8s/blob/master/docs/cni-proposal.md
- VPC CNI 의 External source network address translation (
SNAT) 설정에 따라, 외부(인터넷) 통신 시 SNAT 하거나 혹은 SNAT 없이 통신을 할 수 있다 - 링크
🔥 실습
파드 shell 실행 후 외부로 ping 테스트 & 워커 노드에서 tcpdump 및 iptables 정보 확인
# 작업용 EC2 : pod-1 Shell 에서 외부로 ping kubectl exec -it $PODNAME1 -- ping -c 1 www.google.com kubectl exec -it $PODNAME1 -- ping -i 0.1 www.google.com # 워커 노드 EC2 : TCPDUMP 확인 sudo tcpdump -i any -nn icmp sudo tcpdump -i eth0 -nn icmp # 작업용 EC2 : 퍼블릭IP 확인 for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i curl -s ipinfo.io/ip; echo; echo; done # 작업용 EC2 : pod-1 Shell 에서 외부 접속 확인 - 공인IP는 어떤 주소인가? ## The right way to check the weather - 링크 for i in $PODNAME1 $PODNAME2 $PODNAME3; do echo ">> Pod : $i <<"; kubectl exec -it $i -- curl -s ipinfo.io/ip; echo; echo; done kubectl exec -it $PODNAME1 -- curl -s wttr.in/seoul kubectl exec -it $PODNAME1 -- curl -s wttr.in/seoul?format=3 kubectl exec -it $PODNAME1 -- curl -s wttr.in/Moon kubectl exec -it $PODNAME1 -- curl -s wttr.in/:help # 워커 노드 EC2 ## 출력된 결과를 보고 어떻게 빠져나가는지 고민해보자! ip rule ip route show table main sudo iptables -L -n -v -t nat sudo iptables -t nat -S # 파드가 외부와 통신시에는 아래 처럼 'AWS-SNAT-CHAIN-0' 룰(rule)에 의해서 SNAT 되어서 외부와 통신! # 참고로 뒤 IP는 eth0(ENI 첫번째)의 IP 주소이다 # --random-fully 동작 - 링크1 링크2 sudo iptables -t nat -S | grep 'A AWS-SNAT-CHAIN' -A AWS-SNAT-CHAIN-0 ! -d 192.168.0.0/16 -m comment --comment "AWS SNAT CHAIN" -j RETURN -A AWS-SNAT-CHAIN-0 ! -o vlan+ -m comment --comment "AWS, SNAT" -m addrtype ! --dst-type LOCAL -j SNAT --to-source 192.168.1.251 --random-fully ## 아래 'mark 0x4000/0x4000' 매칭되지 않아서 RETURN 됨! -A KUBE-POSTROUTING -m mark ! --mark 0x4000/0x4000 -j RETURN -A KUBE-POSTROUTING -j MARK --set-xmark 0x4000/0x0 -A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE --random-fully ... # 카운트 확인 시 AWS-SNAT-CHAIN-0에 매칭되어, 목적지가 192.168.0.0/16 아니고 외부 빠져나갈때 SNAT 192.168.1.251(EC2 노드1 IP) 변경되어 나간다! sudo iptables -t filter --zero; sudo iptables -t nat --zero; sudo iptables -t mangle --zero; sudo iptables -t raw --zero watch -d 'sudo iptables -v --numeric --table nat --list AWS-SNAT-CHAIN-0; echo ; sudo iptables -v --numeric --table nat --list KUBE-POSTROUTING; echo ; sudo iptables -v --numeric --table nat --list POSTROUTING' # conntrack 확인 for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo conntrack -L -n |grep -v '169.254.169'; echo; done conntrack v1.4.5 (conntrack-tools): icmp 1 28 src=172.30.66.58 dst=8.8.8.8 type=8 code=0 id=34392 src=8.8.8.8 dst=172.30.85.242 type=0 code=0 id=50705 mark=128 use=1 tcp 6 23 TIME_WAIT src=172.30.66.58 dst=34.117.59.81 sport=58144 dport=80 src=34.117.59.81 dst=172.30.85.242 sport=80 dport=44768 [ASSURED] mark=128 use=1
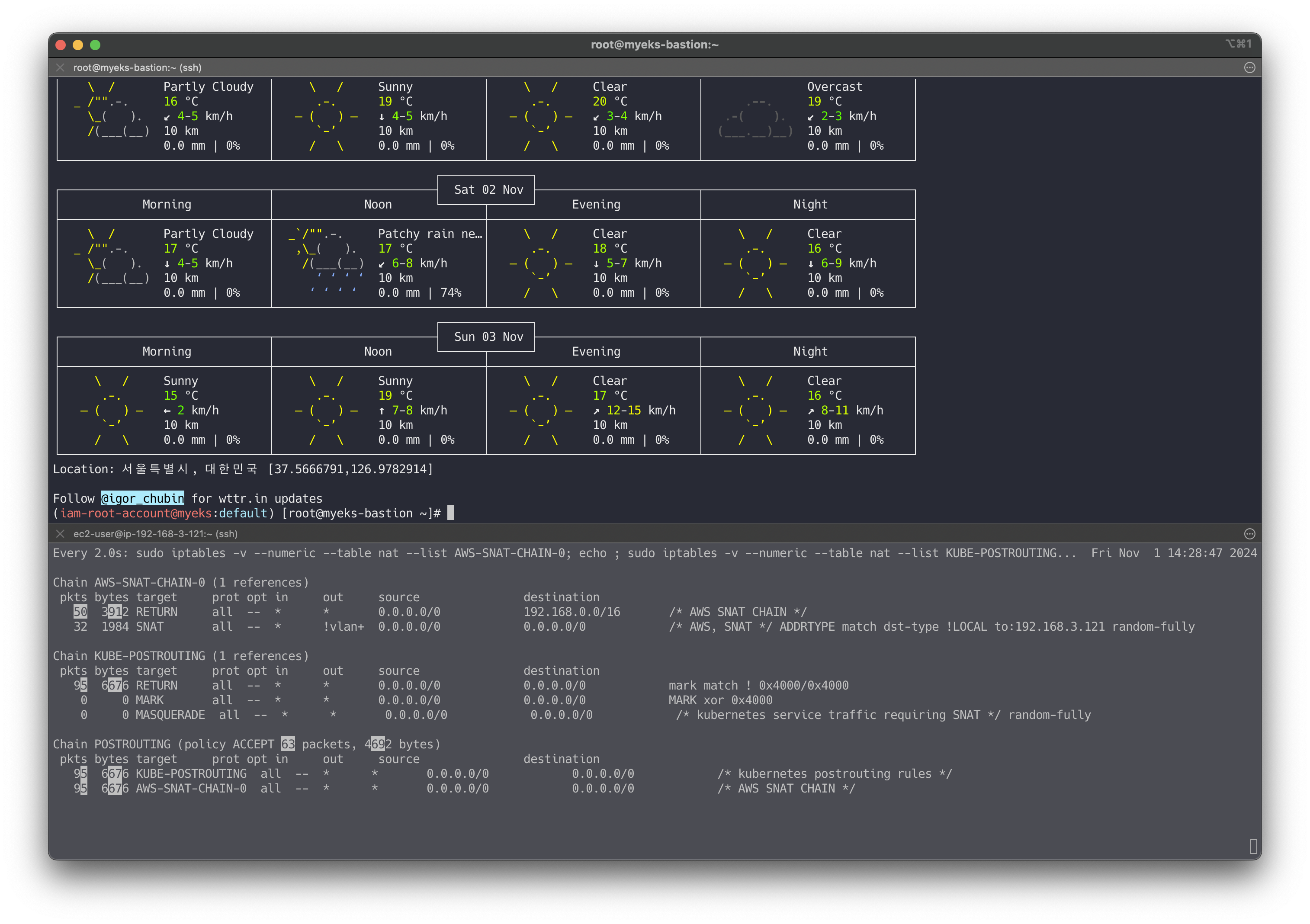
👉 Step 04. 노드에 파드 생성 갯수 제한
사전 준비 :
kube-ops-view설치# kube-ops-view helm repo add geek-cookbook https://geek-cookbook.github.io/charts/ helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set service.main.type=LoadBalancer --set env.TZ="Asia/Seoul" --namespace kube-system # kube-ops-view 접속 URL 확인 (1.5 배율) kubectl get svc -n kube-system kube-ops-view -o jsonpath={.status.loadBalancer.ingress[0].hostname} | awk '{ print "KUBE-OPS-VIEW URL = http://"$1":8080/#scale=1.5"}'
Secondary IPv4 addresses (기본값) : 인스턴스 유형에 최대 ENI 갯수와 할당 가능 IP 수를 조합하여 선정
워커 노드의 인스턴스 타입 별 파드 생성 갯수 제한
- 인스턴스 타입 별 ENI 최대 갯수와 할당 가능한 최대 IP 갯수에 따라서 파드 배치 갯수가 결정됨
- 단, aws-node 와 kube-proxy 파드는 호스트의 IP를 사용함으로 최대 갯수에서 제외함
출처 - CloudNet@
👉🏻 최대 파드 생성 갯수 : (Number of network interfaces for the instance type × (the number of IP addressess per network interface - 1)) + 2
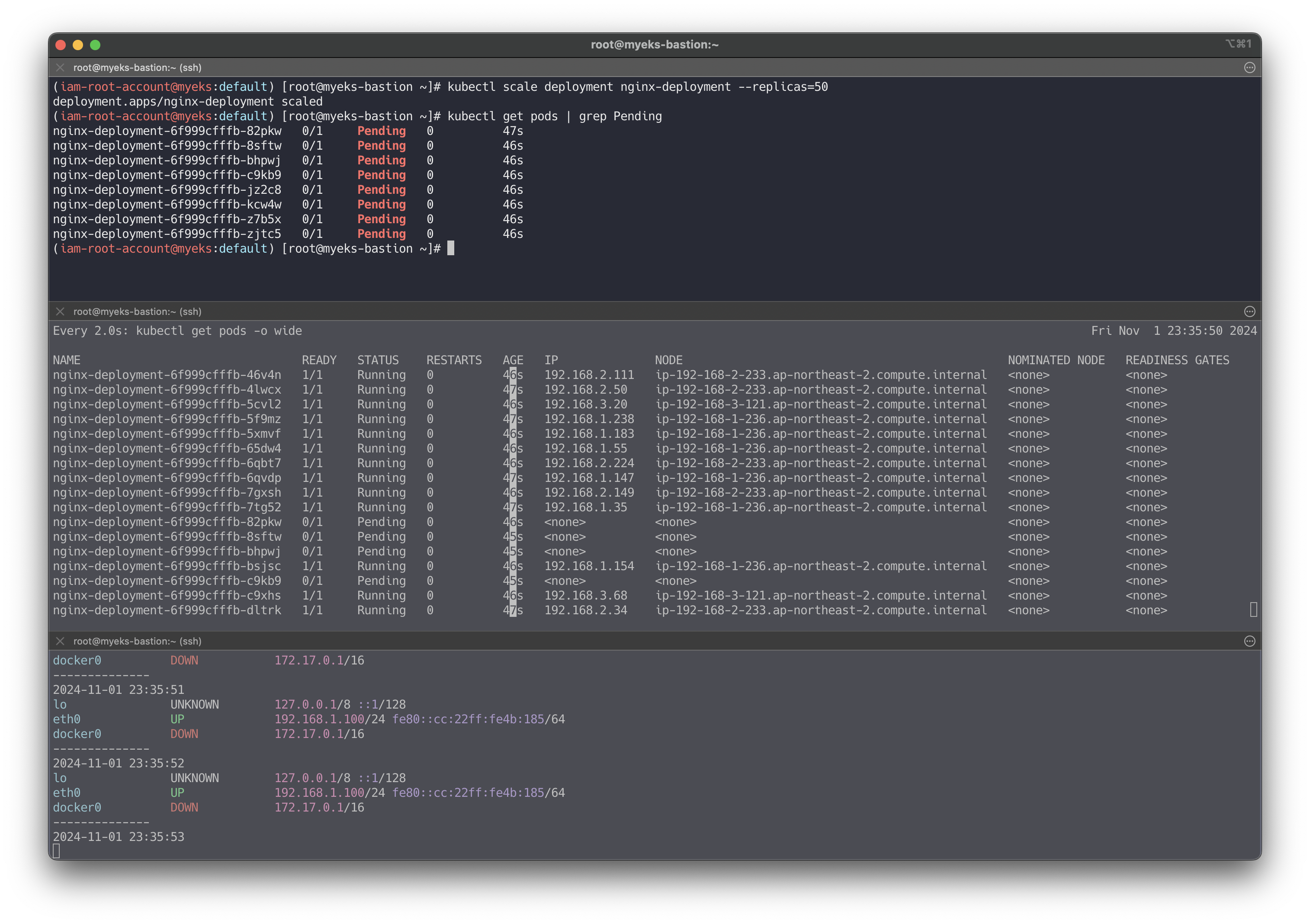
최대 파드 생성 및 확인
# 워커 노드 EC2 - 모니터링 while true; do ip -br -c addr show && echo "--------------" ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; done # 작업용 EC2 - 터미널1 watch -d 'kubectl get pods -o wide' # 작업용 EC2 - 터미널2 # 디플로이먼트 생성 curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/2/nginx-dp.yaml kubectl apply -f nginx-dp.yaml # 파드 확인 kubectl get pod -o wide kubectl get pod -o=custom-columns=NAME:.metadata.name,IP:.status.podIP # 파드 증가 테스트 >> 파드 정상 생성 확인, 워커 노드에서 eth, eni 갯수 확인 kubectl scale deployment nginx-deployment --replicas=8 # 파드 증가 테스트 >> 파드 정상 생성 확인, 워커 노드에서 eth, eni 갯수 확인 >> 어떤일이 벌어졌는가? kubectl scale deployment nginx-deployment --replicas=15 # 파드 증가 테스트 >> 파드 정상 생성 확인, 워커 노드에서 eth, eni 갯수 확인 >> 어떤일이 벌어졌는가? kubectl scale deployment nginx-deployment --replicas=30 # 파드 증가 테스트 >> 파드 정상 생성 확인, 워커 노드에서 eth, eni 갯수 확인 >> 어떤일이 벌어졌는가? kubectl scale deployment nginx-deployment --replicas=50 # 파드 생성 실패! kubectl get pods | grep Pending nginx-deployment-7fb7fd49b4-d4bk9 0/1 Pending 0 3m37s nginx-deployment-7fb7fd49b4-qpqbm 0/1 Pending 0 3m37s ... kubectl describe pod <Pending 파드> | grep Events: -A5 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 45s default-scheduler 0/3 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }, 2 Too many pods. preemption: 0/3 nodes are available: 1 Preemption is not helpful for scheduling, 2 No preemption victims found for incoming pod. # 디플로이먼트 삭제 kubectl delete deploy nginx-deployment
👉 Step 05. Service & AWS LoadBalancer Controller
서비스 종류
ClusterIP 타입
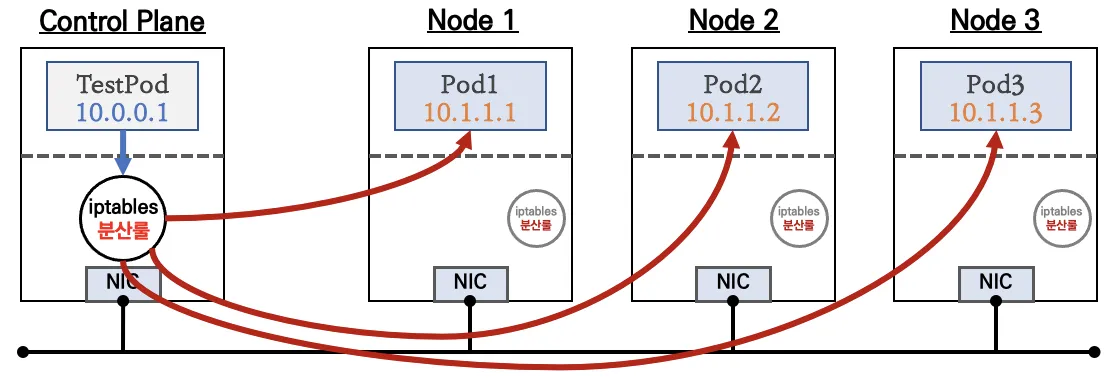 출처 - CloudNet@
출처 - CloudNet@
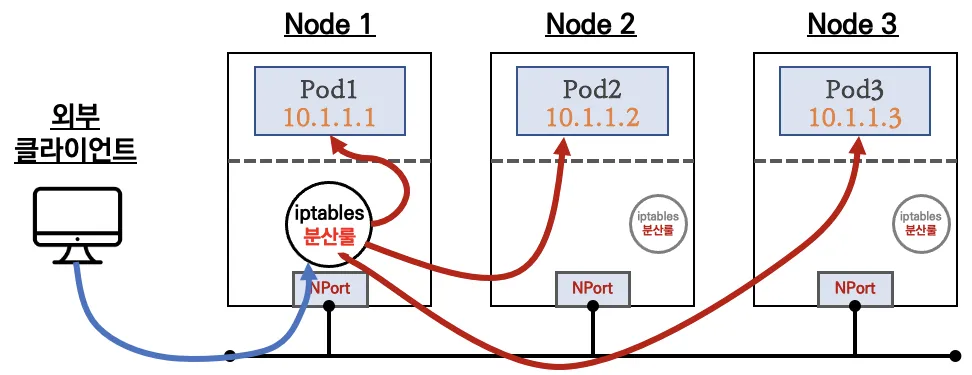
NodePort 타입
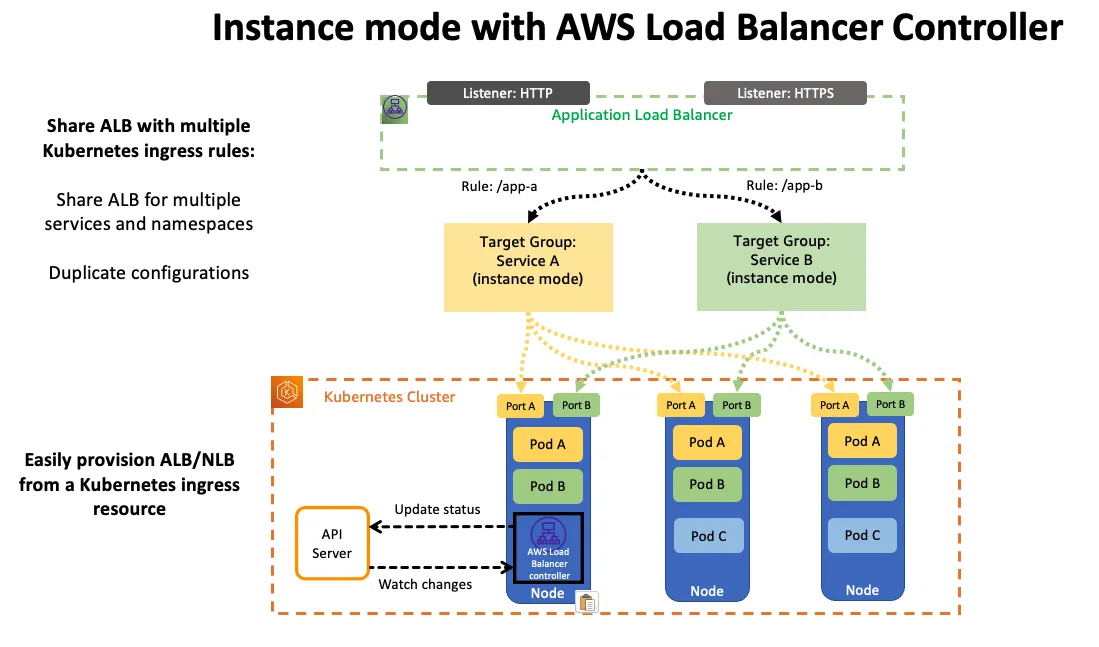
LoadBalancer 타입 (기본 모드) : NLB 인스턴스 유형
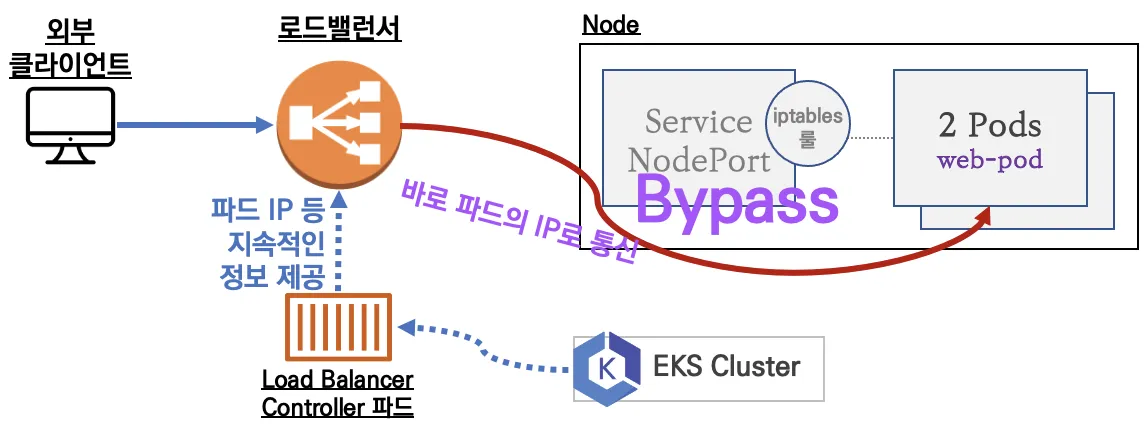
Service (LoadBalancer Controller) : AWS Load Balancer Controller + NLB IP 모드 동작 with AWS VPC CNI
NLB 모드 전체 정리
-
인스턴스 유형
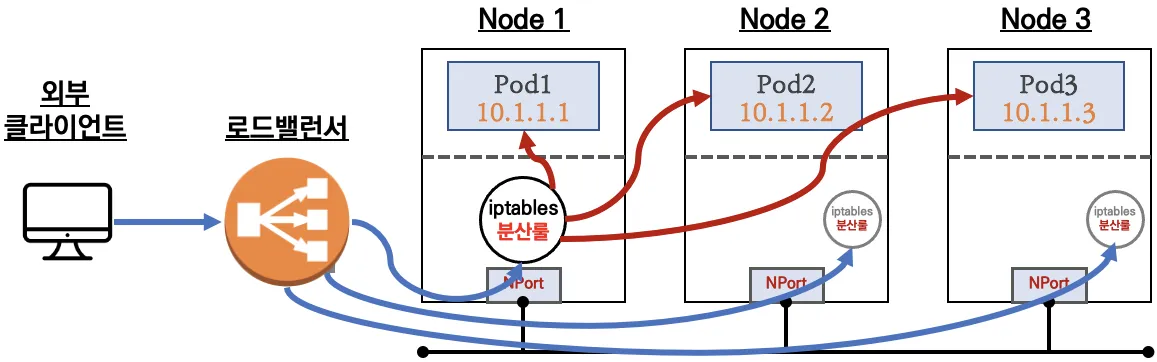
externalTrafficPolicy: ClusterIP ⇒ 2번 분산 및 SNAT으로 Client IP 확인 불가능 ←LoadBalancer타입 (기본 모드) 동작externalTrafficPolicy: Local ⇒ 1번 분산 및 ClientIP 유지, 워커 노드의 iptables 사용함
상세 설명 - (통신 흐름)
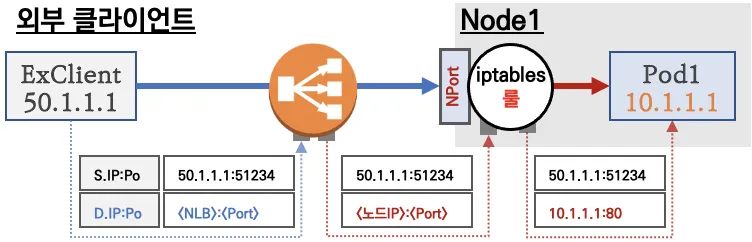
요약 : 외부 클라이언트가 '로드밸런서' 접속 시 부하분산 되어 노드 도달 후 iptables 룰로 목적지 파드와 통신됨
- 노드는 외부에 공개되지 않고 로드밸런서만 외부에 공개되어, 외부 클라이언트는 로드밸랜서에 접속을 할 뿐 내부 노드의 정보를 알 수 없다
- 로드밸런서가 부하분산하여 파드가 존재하는 노드들에게 전달한다, iptables 룰에서는 자신의 노드에 있는 파드만 연결한다 (
externalTrafficPolicy: local)- DNAT 2번 동작 : 첫번째(로드밸런서 접속 후 빠져 나갈때), 두번째(노드의 iptables 룰에서 파드IP 전달 시)
- 외부 클라이언트 IP 보존(유지) : AWS NLB 는 타켓이 인스턴스일 경우 클라이언트 IP를 유지, iptables 룰 경우도
externalTrafficPolicy로 클라이언트 IP를 보존
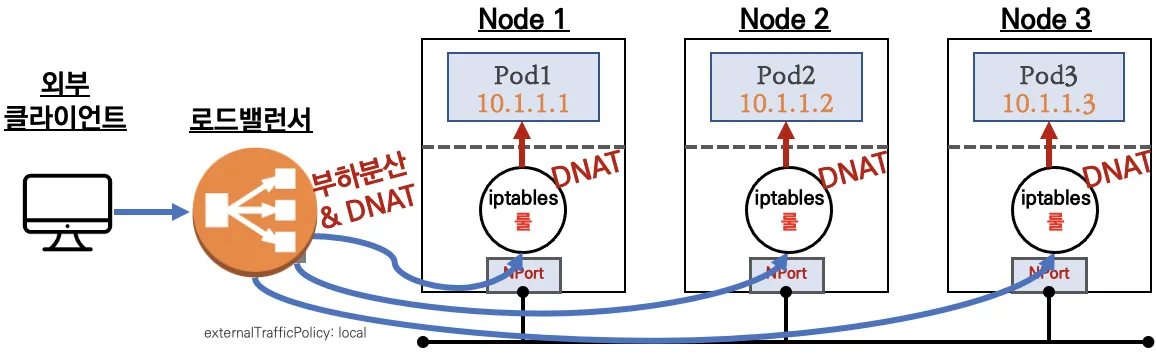
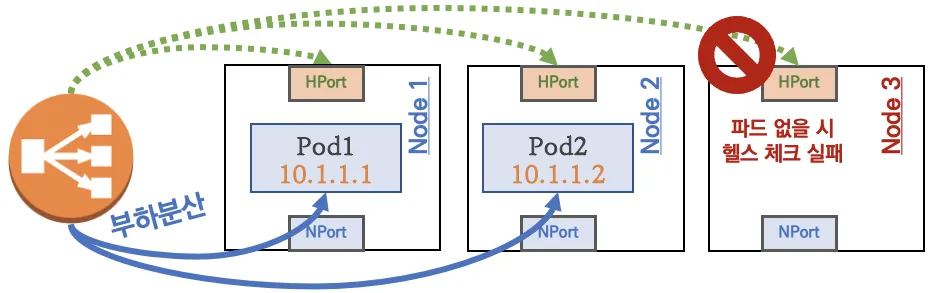
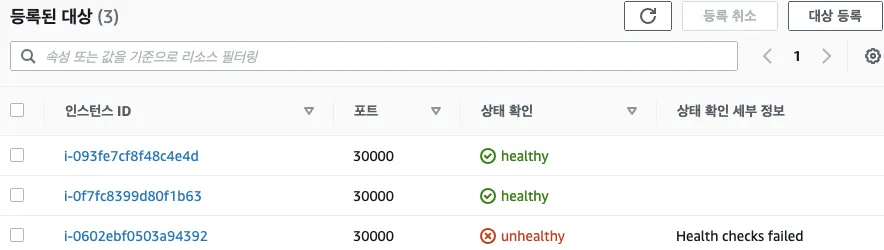
부하분산 최적화 : 노드에 파드가 없을 경우 '로드밸런서'에서 노드에 헬스 체크(상태 검사)가 실패하여 해당 노드로는 외부 요청 트래픽을 전달하지 않는다
3번째 인스턴스(Node3)은 상태 확인 실패로 외부 요청 트래픽 전달하지 않는다
-
IP 유형 ⇒ 반드시 AWS LoadBalancer 컨트롤러 파드 및 정책 설정이 필요함!
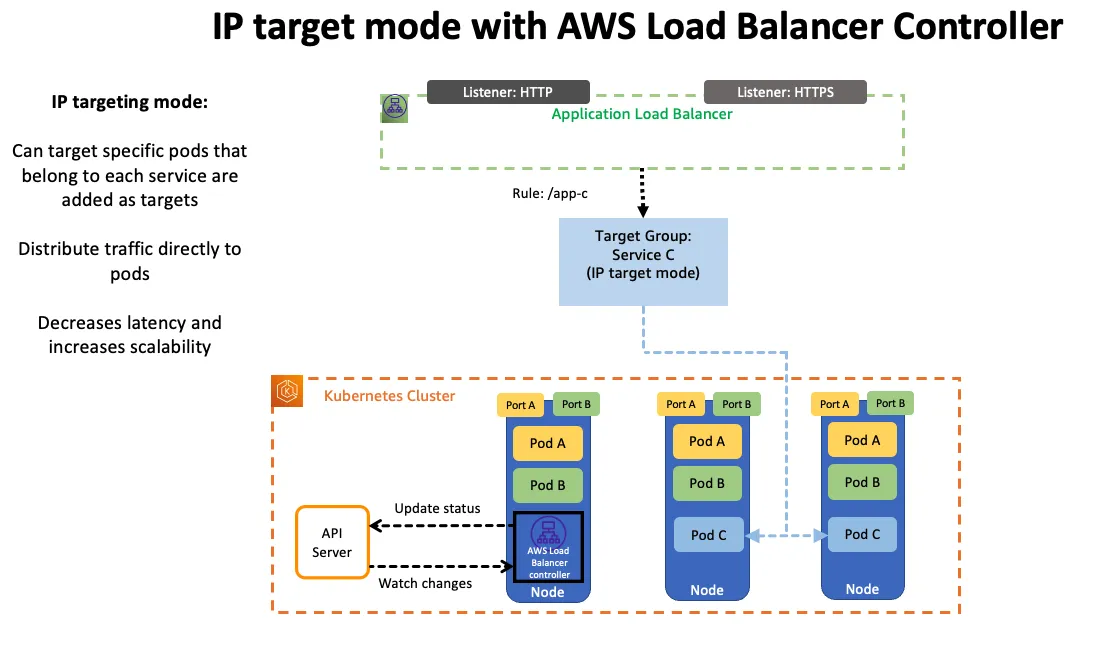 https://aws.amazon.com/blogs/networking-and-content-delivery/deploying-aws-load-balancer-controller-on-amazon-eks/
https://aws.amazon.com/blogs/networking-and-content-delivery/deploying-aws-load-balancer-controller-on-amazon-eks/-
Proxy Protocol v2 비활성화⇒ NLB에서 바로 파드로 인입, 단 ClientIP가 NLB로 SNAT 되어 Client IP 확인 불가능 -
Proxy Protocol v2 활성화⇒ NLB에서 바로 파드로 인입 및 ClientIP 확인 가능(→ 단 PPv2 를 애플리케이션이 인지할 수 있게 설정 필요)
-
👉 Step 06. Ingress
인그레스 소개 : 클러스터 내부의 서비스(ClusterIP, NodePort, Loadbalancer)를 외부로 노출(HTTP/HTTPS) - Web Proxy 역할
-
Exposing Kubernetes Applications, Part 1: Service and Ingress Resources - 링크
-
Exposing a Service : In-tree Service Controller
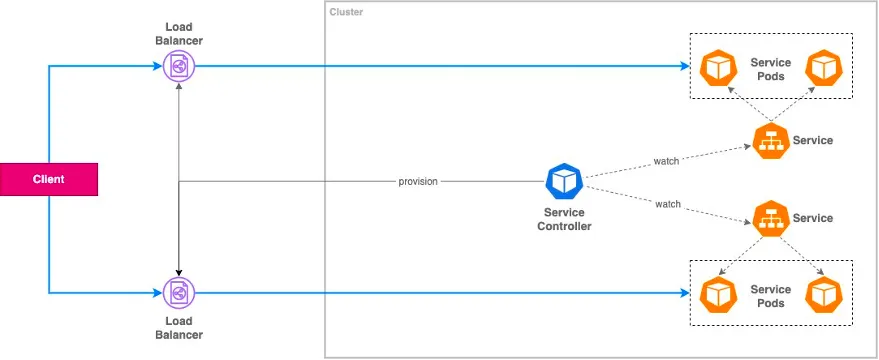
-
Ingress Implementations : External Load Balancer
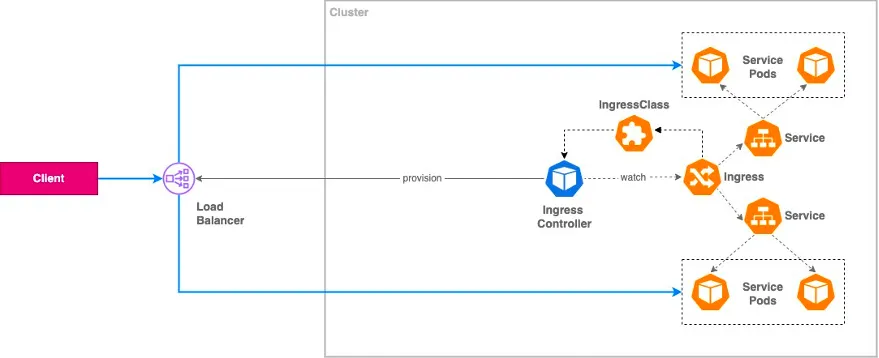
-
Ingress Implementations : Internal Reverse Proxy
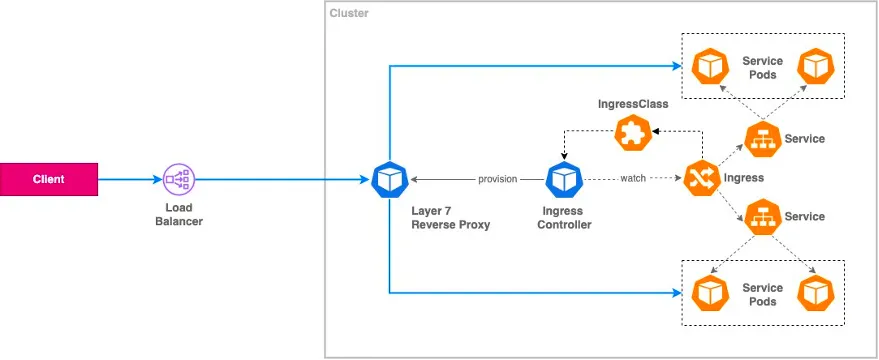
-
Kubernetes Gateway API
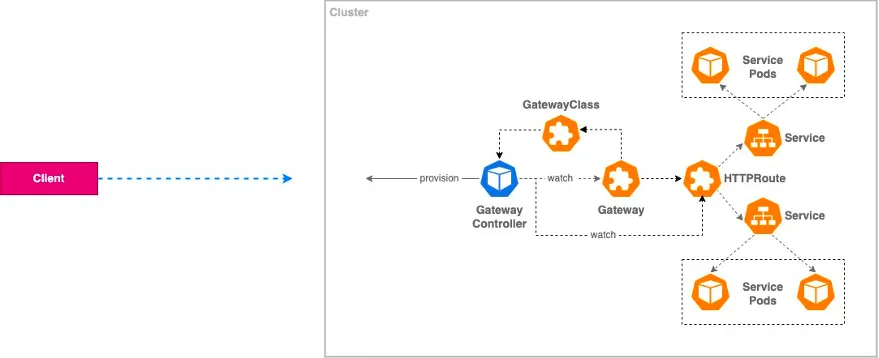
-
👉 Step 07. ExternalDNS
소개 : K8S 서비스/인그레스 생성 시 도메인을 설정하면, AWS(Route 53), Azure(DNS), GCP(Cloud DNS) 에 A 레코드(TXT 레코드)로 자동 생성/삭제
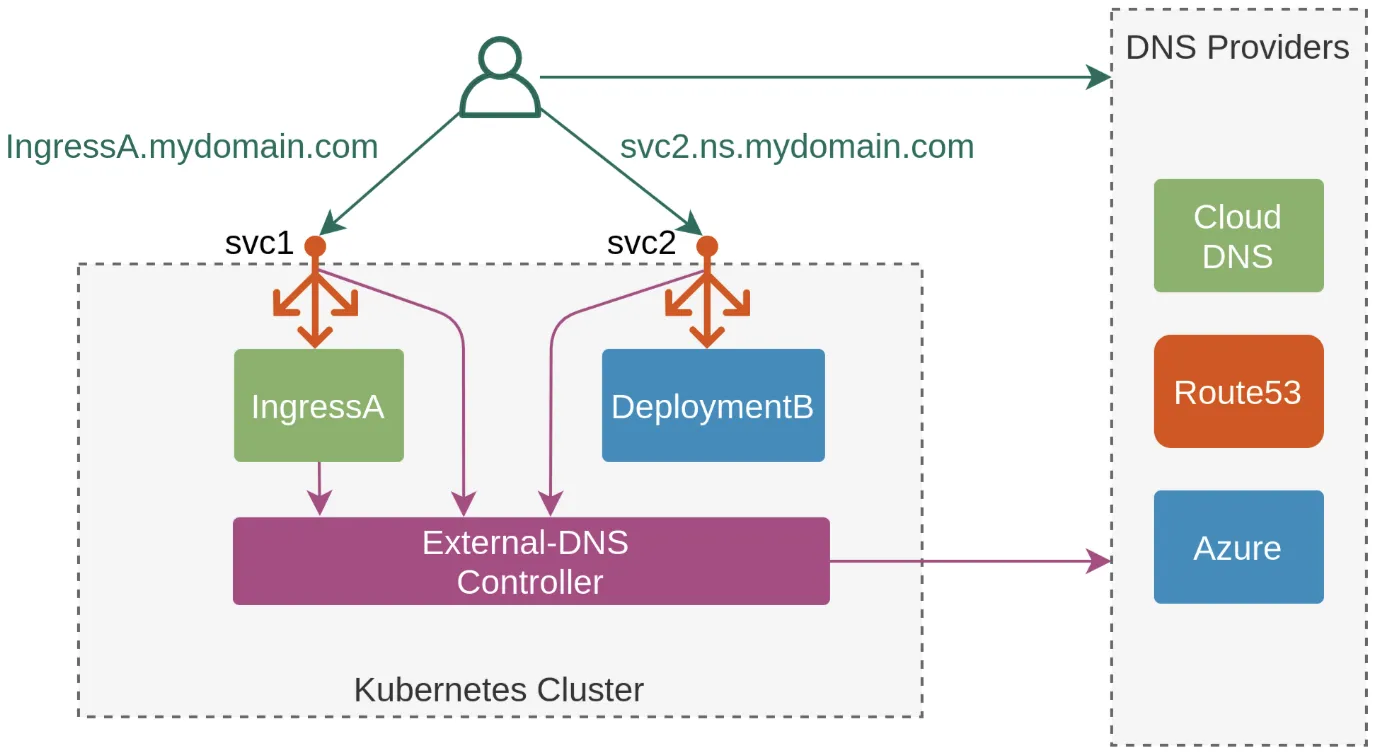 https://edgehog.blog/a-self-hosted-external-dns-resolver-for-kubernetes-111a27d6fc2c
https://edgehog.blog/a-self-hosted-external-dns-resolver-for-kubernetes-111a27d6fc2c
- ExternalDNS CTRL 권한 주는 방법 3가지 : Node IAM Role, Static credentials, IRSA
AWS Route 53 정보 확인 & 변수 지정 : Public 도메인 소유를 하고 계셔야 합니다!
# 자신의 도메인 변수 지정 : 소유하고 있는 자신의 도메인을 입력하시면 됩니다 MyDomain=<자신의 도메인> MyDomain=xgro.link echo "export MyDomain=gasida.link" >> /etc/profile # 자신의 Route 53 도메인 ID 조회 및 변수 지정 aws route53 list-hosted-zones-by-name --dns-name "${MyDomain}." | jq aws route53 list-hosted-zones-by-name --dns-name "${MyDomain}." --query "HostedZones[0].Name" aws route53 list-hosted-zones-by-name --dns-name "${MyDomain}." --query "HostedZones[0].Id" --output text MyDnzHostedZoneId=`aws route53 list-hosted-zones-by-name --dns-name "${MyDomain}." --query "HostedZones[0].Id" --output text` echo $MyDnzHostedZoneId # (옵션) NS 레코드 타입 첫번째 조회 aws route53 list-resource-record-sets --output json --hosted-zone-id "${MyDnzHostedZoneId}" --query "ResourceRecordSets[?Type == 'NS']" | jq -r '.[0].ResourceRecords[].Value' # (옵션) A 레코드 타입 모두 조회 aws route53 list-resource-record-sets --output json --hosted-zone-id "${MyDnzHostedZoneId}" --query "ResourceRecordSets[?Type == 'A']" # A 레코드 타입 조회 aws route53 list-resource-record-sets --hosted-zone-id "${MyDnzHostedZoneId}" --query "ResourceRecordSets[?Type == 'A']" | jq aws route53 list-resource-record-sets --hosted-zone-id "${MyDnzHostedZoneId}" --query "ResourceRecordSets[?Type == 'A'].Name" | jq aws route53 list-resource-record-sets --hosted-zone-id "${MyDnzHostedZoneId}" --query "ResourceRecordSets[?Type == 'A'].Name" --output text # A 레코드 값 반복 조회 while true; do aws route53 list-resource-record-sets --hosted-zone-id "${MyDnzHostedZoneId}" --query "ResourceRecordSets[?Type == 'A']" | jq ; date ; echo ; sleep 1; done
👉 Step 08. CoreDNS
Kubernetes에서 DNS 다루는 방법 - 도메인을 찾아서
쿠버네티스 DNS 쿼리 Flow - 링크
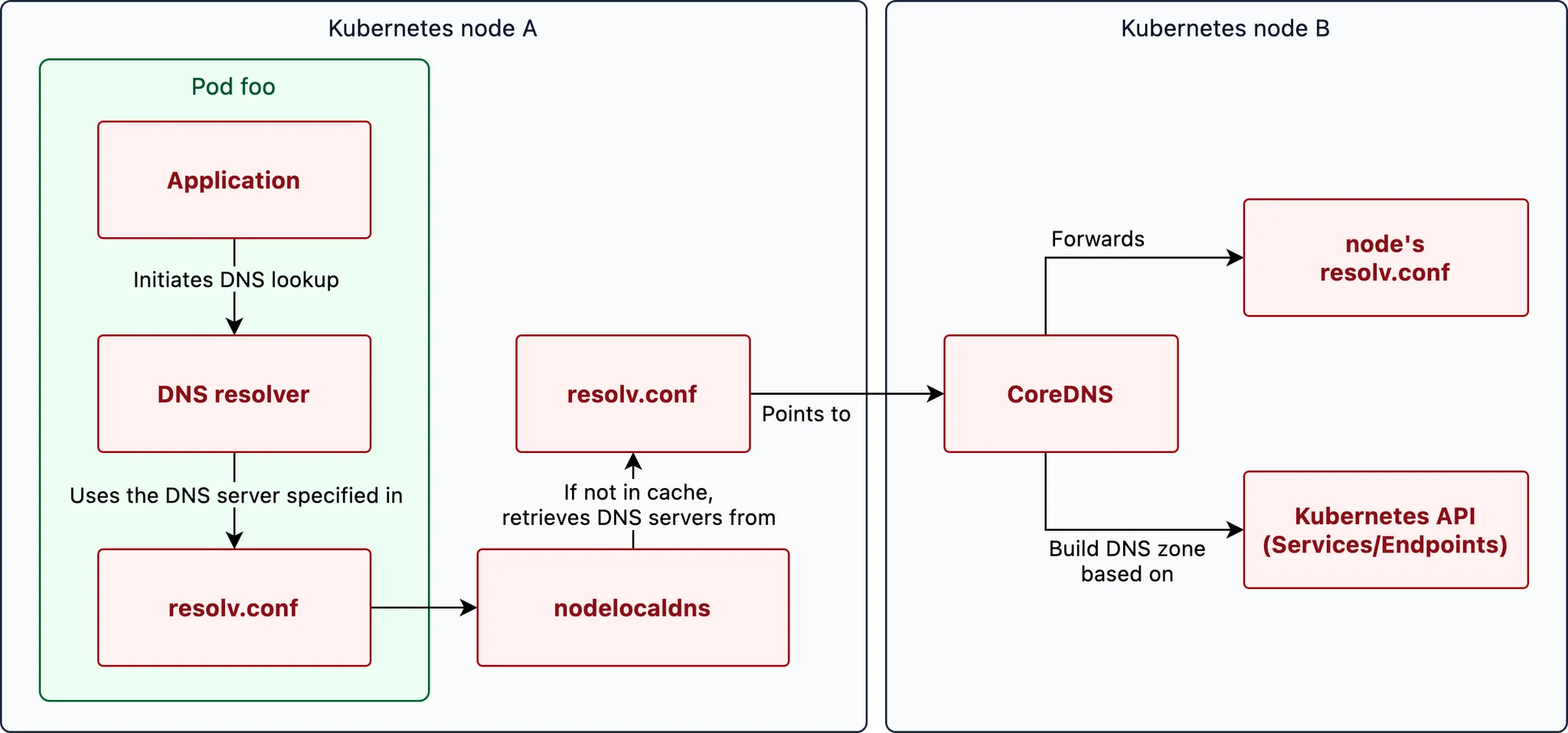
https://www.nslookup.io/learning/the-life-of-a-dns-query-in-kubernetes/
👉 Step 09. Topology Aware Routing
토폴로지 인식 라우팅(Topology Aware Routing)은 네트워크 트래픽을 원래 발생한 영역 내에 유지하는 데 도움이 되는 메커니즘을 제공합니다.
클러스터의 Pod 간에 동일 영역 트래픽을 선호하는 것은 안정성, 성능(네트워크 지연 및 처리량) 또는 비용에 도움이 될 수 있습니다.
https://kubernetes.io/docs/concepts/services-networking/topology-aware-routing/
테스트를 위한 디플로이먼트와 서비스 배포
# 현재 노드 AZ 배포 확인 kubectl get node --label-columns=topology.kubernetes.io/zone NAME STATUS ROLES AGE VERSION ZONE ip-192-168-1-225.ap-northeast-2.compute.internal Ready <none> 70m v1.24.11-eks-a59e1f0 ap-northeast-2a ip-192-168-2-248.ap-northeast-2.compute.internal Ready <none> 70m v1.24.11-eks-a59e1f0 ap-northeast-2b ip-192-168-3-228.ap-northeast-2.compute.internal Ready <none> 70m v1.24.11-eks-a59e1f0 ap-northeast-2c # 테스트를 위한 디플로이먼트와 서비스 배포 cat <<EOF | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: deploy-echo spec: replicas: 3 selector: matchLabels: app: deploy-websrv template: metadata: labels: app: deploy-websrv spec: terminationGracePeriodSeconds: 0 containers: - name: websrv image: registry.k8s.io/echoserver:1.5 ports: - containerPort: 8080 --- apiVersion: v1 kind: Service metadata: name: svc-clusterip spec: ports: - name: svc-webport port: 80 targetPort: 8080 selector: app: deploy-websrv type: ClusterIP EOF # 확인 kubectl get deploy,svc,ep,endpointslices kubectl get pod -owide kubectl get svc,ep svc-clusterip kubectl get endpointslices -l kubernetes.io/service-name=svc-clusterip kubectl get endpointslices -l kubernetes.io/service-name=svc-clusterip -o yaml # 접속 테스트를 수행할 클라이언트 파드 배포 cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: netshoot-pod spec: containers: - name: netshoot-pod image: nicolaka/netshoot command: ["tail"] args: ["-f", "/dev/null"] terminationGracePeriodSeconds: 0 EOF # 확인 kubectl get pod -owide
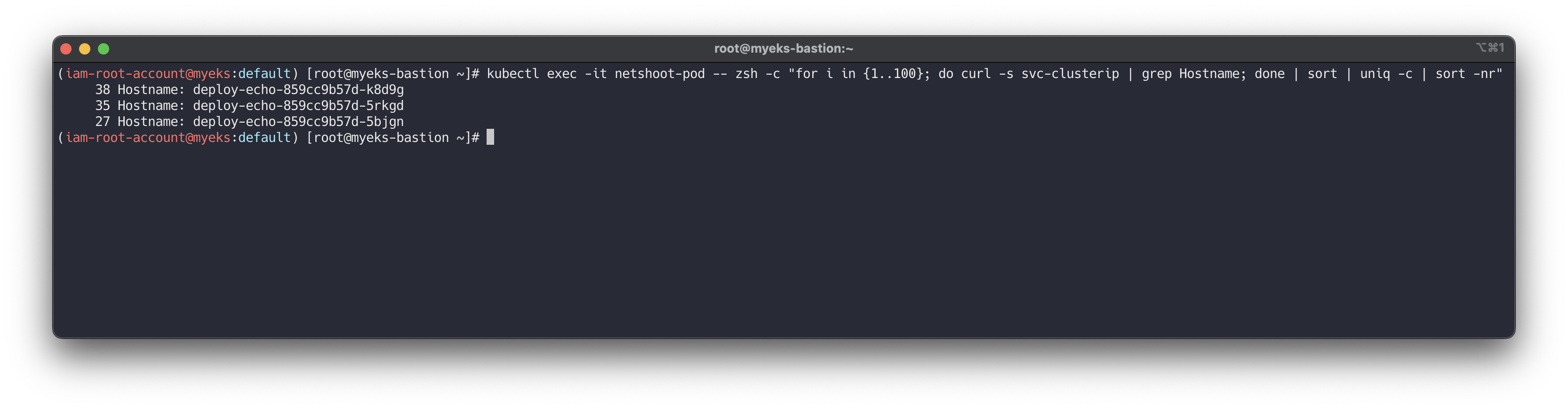
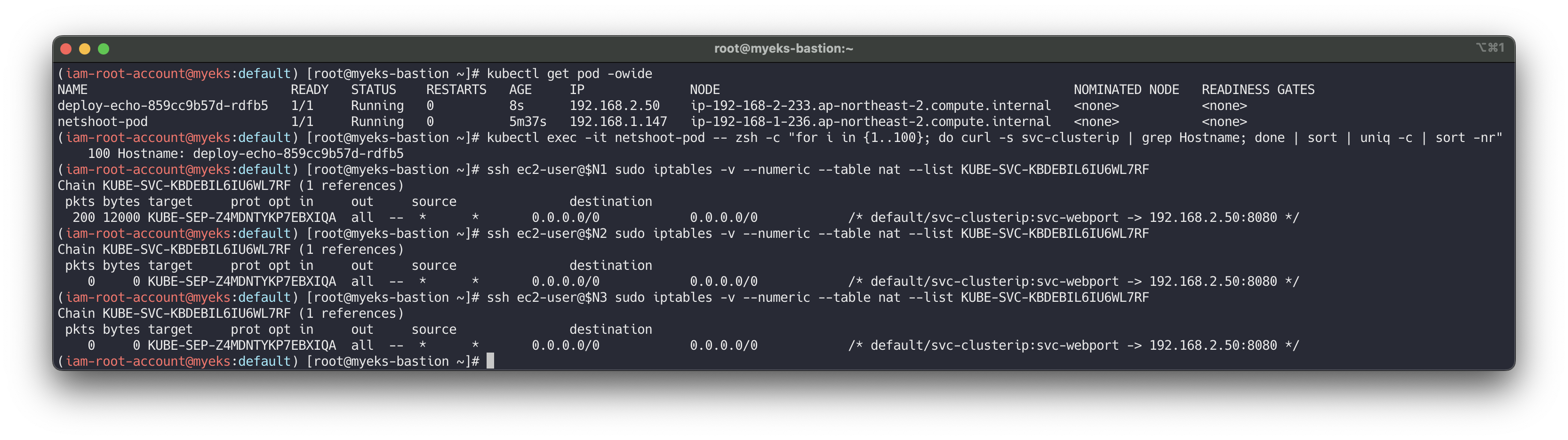
테스트 파드(netshoot-pod)에서 ClusterIP 접속 시 부하분산 확인 : AZ(zone) 상관없이 랜덤 확률 부하분산 동작
# 디플로이먼트 파드가 배포된 AZ(zone) 확인 kubectl get pod -l app=deploy-websrv -owide # 테스트 파드(netshoot-pod)에서 ClusterIP 접속 시 부하분산 확인 kubectl exec -it netshoot-pod -- curl svc-clusterip | grep Hostname Hostname: deploy-echo-7f67d598dc-h9vst kubectl exec -it netshoot-pod -- curl svc-clusterip | grep Hostname Hostname: deploy-echo-7f67d598dc-45trg # 100번 반복 접속 : 3개의 파드로 AZ(zone) 상관없이 랜덤 확률 부하분산 동작 kubectl exec -it netshoot-pod -- zsh -c "for i in {1..100}; do curl -s svc-clusterip | grep Hostname; done | sort | uniq -c | sort -nr" 35 Hostname: deploy-echo-7f67d598dc-45trg 33 Hostname: deploy-echo-7f67d598dc-hg995 32 Hostname: deploy-echo-7f67d598dc-h9vst
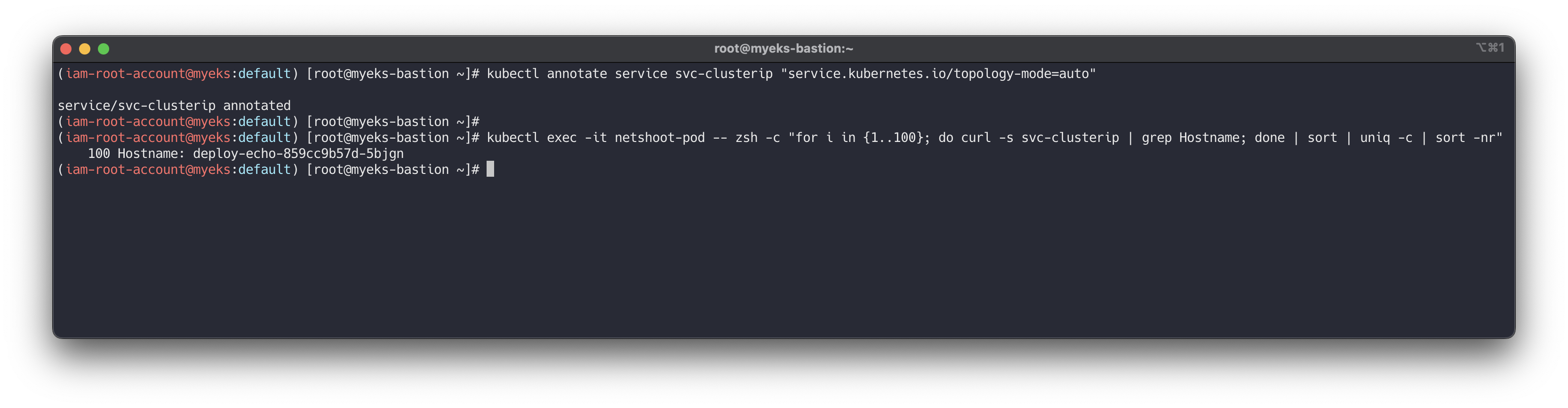
Topology Mode(구 Aware Hint) 설정 후 테스트 파드(netshoot-pod)에서 ClusterIP 접속 시 부하분산 확인 : 같은 AZ(zone)의 목적지 파드로만 접속
https://docs.aws.amazon.com/eks/latest/best-practices/cost-opt-networking.html
# Topology Aware Routing 설정 : 서비스에 annotate에 아래처럼 추가 kubectl annotate service svc-clusterip "service.kubernetes.io/topology-mode=auto" # 100번 반복 접속 : 테스트 파드(netshoot-pod)와 같은 AZ(zone)의 목적지 파드로만 접속 kubectl exec -it netshoot-pod -- zsh -c "for i in {1..100}; do curl -s svc-clusterip | grep Hostname; done | sort | uniq -c | sort -nr" 100 Hostname: deploy-echo-7f67d598dc-45trg # endpointslices 확인 시, 기존에 없던 hints 가 추가되어 있음 >> 참고로 describe로는 hints 정보가 출력되지 않음 kubectl get endpointslices -l kubernetes.io/service-name=svc-clusterip -o yaml apiVersion: v1 items: - addressType: IPv4 apiVersion: discovery.k8s.io/v1 endpoints: - addresses: - 192.168.3.13 conditions: ready: true serving: true terminating: false hints: forZones: - name: ap-northeast-2c nodeName: ip-192-168-3-228.ap-northeast-2.compute.internal targetRef: kind: Pod name: deploy-echo-7f67d598dc-hg995 namespace: default uid: c1ce0e9c-14e7-417d-a1b9-2dfd54da8d4a zone: ap-northeast-2c - addresses: - 192.168.2.65 conditions: ready: true serving: true terminating: false hints: forZones: - name: ap-northeast-2b nodeName: ip-192-168-2-248.ap-northeast-2.compute.internal targetRef: kind: Pod name: deploy-echo-7f67d598dc-h9vst namespace: default uid: 77af6a1b-c600-456c-96f3-e1af621be2af zone: ap-northeast-2b - addresses: - 192.168.1.240 conditions: ready: true serving: true terminating: false hints: forZones: - name: ap-northeast-2a nodeName: ip-192-168-1-225.ap-northeast-2.compute.internal targetRef: kind: Pod name: deploy-echo-7f67d598dc-45trg namespace: default uid: 53ca3ac7-b9fb-4d98-a3f5-c312e60b1e67 zone: ap-northeast-2a kind: EndpointSlice ...
(추가 테스트) 만약 파드 갯수를 1개로 줄여서 같은 AZ에 목적지 파드가 없을 경우?
# 파드 갯수를 1개로 줄이기 kubectl scale deployment deploy-echo --replicas 1 # 동일 AZ일 경우 0 -> 1 시도 kubectl scale deployment deploy-echo --replicas 0 kubectl scale deployment deploy-echo --replicas 1 # 파드 AZ 확인 : 아래 처럼 현재 다른 AZ에 배포 kubectl get pod -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES deploy-echo-7f67d598dc-h9vst 1/1 Running 0 18m 192.168.2.65 ip-192-168-2-248.ap-northeast-2.compute.internal <none> <none> netshoot-pod 1/1 Running 0 66m 192.168.1.137 ip-192-168-1-225.ap-northeast-2.compute.internal <none> <none> # 100번 반복 접속 : 다른 AZ이지만 목적지파드로 접속됨! kubectl exec -it netshoot-pod -- zsh -c "for i in {1..100}; do curl -s svc-clusterip | grep Hostname; done | sort | uniq -c | sort -nr" 100 Hostname: deploy-echo-7f67d598dc-h9vst ssh ec2-user@$N1 sudo iptables -v --numeric --table nat --list KUBE-SERVICES # 아래 3개 노드 모두 SVC에 1개의 SEP 정책 존재 ssh ec2-user@$N1 sudo iptables -v --numeric --table nat --list KUBE-SVC-KBDEBIL6IU6WL7RF Chain KUBE-SVC-KBDEBIL6IU6WL7RF (1 references) pkts bytes target prot opt in out source destination 100 6000 KUBE-SEP-XFCOE5ZRIDUONHHN all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/svc-clusterip:svc-webport -> 192.168.2.65:8080 */ ssh ec2-user@$N2 sudo iptables -v --numeric --table nat --list KUBE-SVC-KBDEBIL6IU6WL7RF Chain KUBE-SVC-KBDEBIL6IU6WL7RF (1 references) pkts bytes target prot opt in out source destination 0 0 KUBE-SEP-XFCOE5ZRIDUONHHN all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/svc-clusterip:svc-webport -> 192.168.2.65:8080 */ ssh ec2-user@$N3 sudo iptables -v --numeric --table nat --list KUBE-SVC-KBDEBIL6IU6WL7RF Chain KUBE-SVC-KBDEBIL6IU6WL7RF (1 references) pkts bytes target prot opt in out source destination 0 0 KUBE-SEP-XFCOE5ZRIDUONHHN all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/svc-clusterip:svc-webport -> 192.168.2.65:8080 */ # endpointslices 확인 : hint 정보 없음 kubectl get endpointslices -l kubernetes.io/service-name=svc-clusterip -o yaml
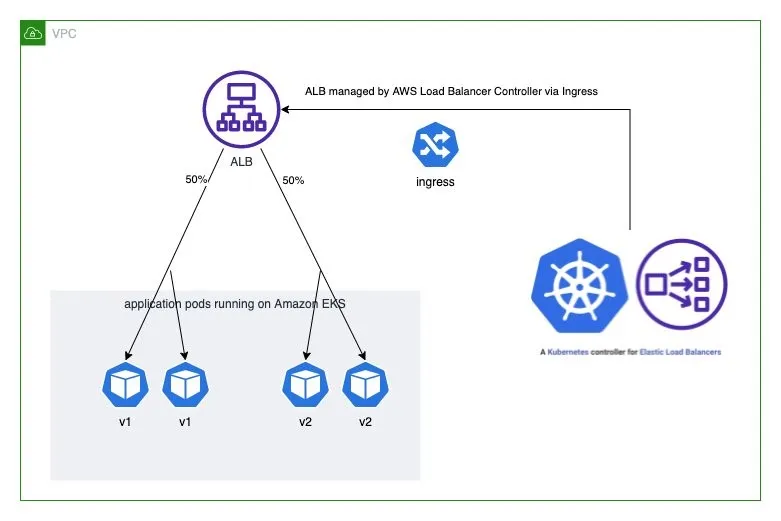
👉 Step 10. Using AWS Load Balancer Controller for blue/green deployment, canary deployment and A/B testing
ALB 동작 소개
- Weighted target group 가중치가 적용된 대상 그룹
- AWS 고객이 블루/그린 및 카나리아 배포와 A/B 테스트 전략을 채택할 수 있도록 돕기 위해 AWS는 2019년 11월에 애플리케이션 로드 밸런서에 대한 가중 대상 그룹을 발표했습니다. 여러 대상 그룹을 리스너 규칙 의 동일한 전달 작업 에 연결 하고 각 그룹에 대한 가중치를 지정할 수 있습니다.
- 이를 통해 개발자는 트래픽을 여러 버전의 애플리케이션에 분산하는 방법을 제어할 수 있습니다. 예를 들어, 가중치가 8과 2인 두 개의 대상 그룹이 있는 규칙을 정의하면 로드 밸런서는 트래픽의 80%를 첫 번째 대상 그룹으로, 20%를 다른 대상 그룹으로 라우팅합니다.
- Advanced request routing 고급 요청 라우팅
- AWS는 가중치가 적용된 대상 그룹 외에도 2019년에 고급 요청 라우팅 기능을 발표했습니다 . 고급 요청 라우팅은 개발자에게 표준 및 사용자 지정 HTTP 헤더와 메서드, 요청 경로, 쿼리 문자열, 소스 IP 주소를 기반으로 규칙을 작성하고 트래픽을 라우팅할 수 있는 기능을 제공합니다.
- 이 새로운 기능은 라우팅을 위한 프록시 플릿의 필요성을 없애 애플리케이션 아키텍처를 간소화하고, 로드 밸런서에서 원치 않는 트래픽을 차단하며, A/B 테스트를 구현할 수 있도록 합니다.
- AWS Load Balancer Controller AWS 로드 밸런서 컨트롤러
- AWS Load Balancer Controller 는 Kubernetes 클러스터의 Elastic Load Balancer를 관리하는 데 도움이 되는 컨트롤러입니다. 애플리케이션 로드 밸런서를 프로비저닝하여 Kubernetes 인그레스 리소스를 충족합니다.
- Kubernetes 인그레스 객체에 주석을 추가하여 프로비저닝된 애플리케이션 로드 밸런서의 동작을 사용자 지정할 수 있습니다. 이를 통해 개발자는 애플리케이션 로드 밸런서를 구성하고 Kubernetes 기본 의미 체계를 사용하여 블루/그린, 카나리아 및 A/B 배포를 실현할 수 있습니다.
예를 들어, 다음 인그레스 주석은 애플리케이션 로드 밸런서를 구성하여 두 버전의 애플리케이션 간에 트래픽을 분할합니다.
annotations: ... alb.ingress.kubernetes.io/actions.blue-green: | { "type":"forward", "forwardConfig":{ "targetGroups":[ { "serviceName":"hello-kubernetes-v1", "servicePort":"80", "weight":50 }, { "serviceName":"hello-kubernetes-v2", "servicePort":"80", "weight":50 } ] } }
🔥 실습
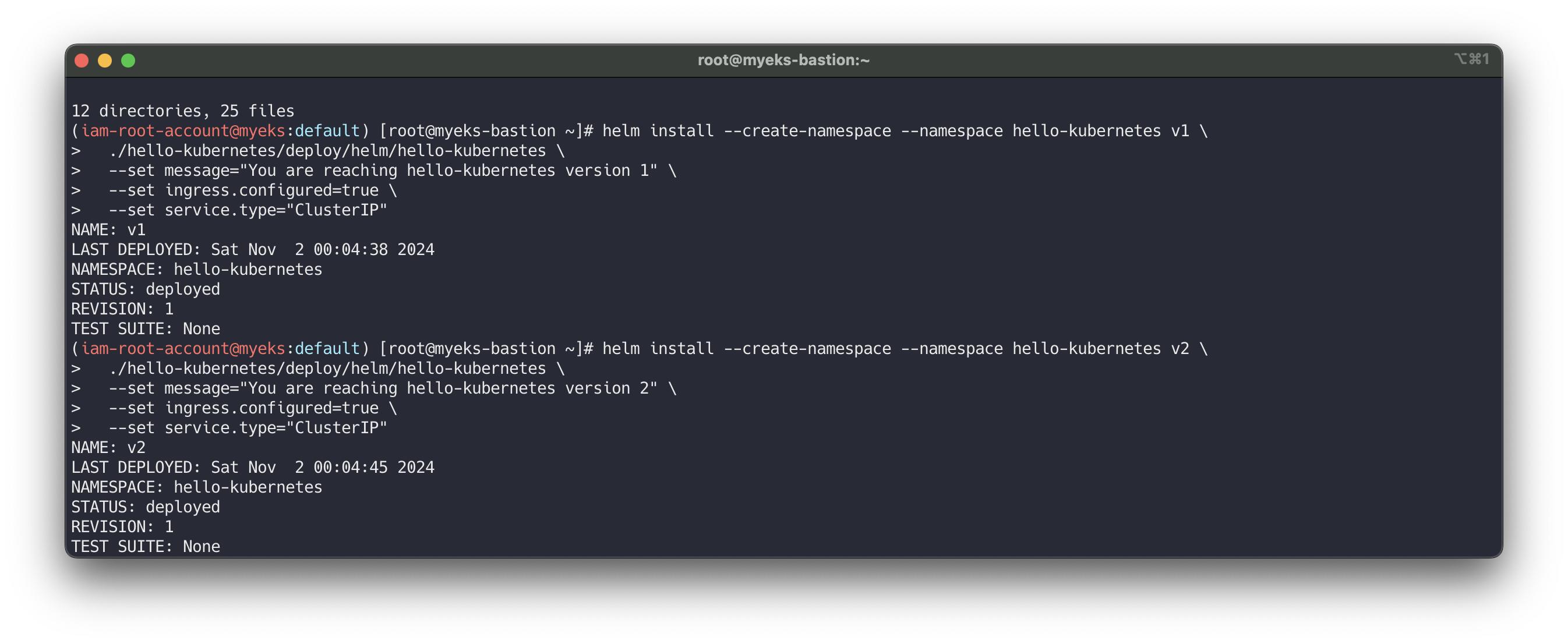
Deploy the sample application version 1 and version 2
# git clone https://github.com/paulbouwer/hello-kubernetes.git tree hello-kubernetes/ # Install sample application version 1 helm install --create-namespace --namespace hello-kubernetes v1 \ ./hello-kubernetes/deploy/helm/hello-kubernetes \ --set message="You are reaching hello-kubernetes version 1" \ --set ingress.configured=true \ --set service.type="ClusterIP" # Install sample application version 2 helm install --create-namespace --namespace hello-kubernetes v2 \ ./hello-kubernetes/deploy/helm/hello-kubernetes \ --set message="You are reaching hello-kubernetes version 2" \ --set ingress.configured=true \ --set service.type="ClusterIP" # 확인 kubectl get-all -n hello-kubernetes kubectl get pod,svc,ep -n hello-kubernetes kubectl get pod -n hello-kubernetes --label-columns=app.kubernetes.io/instance,pod-template-hash
Deploy ingress and test the blue/green deployment
Ingress의alb.ingress.kubernetes.io/actions.${action-name}annotation을 사용하면 Application Load Balancer(ALB) 리스너에 대해 사용자 정의 동작을 설정할 수 있습니다. 이 설정으로 리디렉션 동작, 포워드 동작 등의 동작을 구성할 수 있으며, 포워드 동작에서는 서로 다른 가중치를 가진 여러 타겟 그룹을 정의할 수 있습니다.AWS Load Balancer Controller는 해당 annotation을 기준으로 타겟 그룹을 생성하고 리스너 규칙을 구성하여 트래픽을 지정된 서비스로 전달합니다.
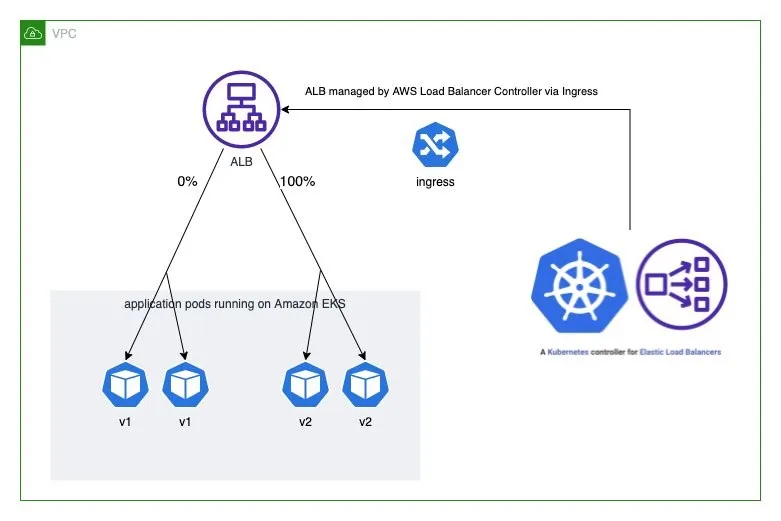
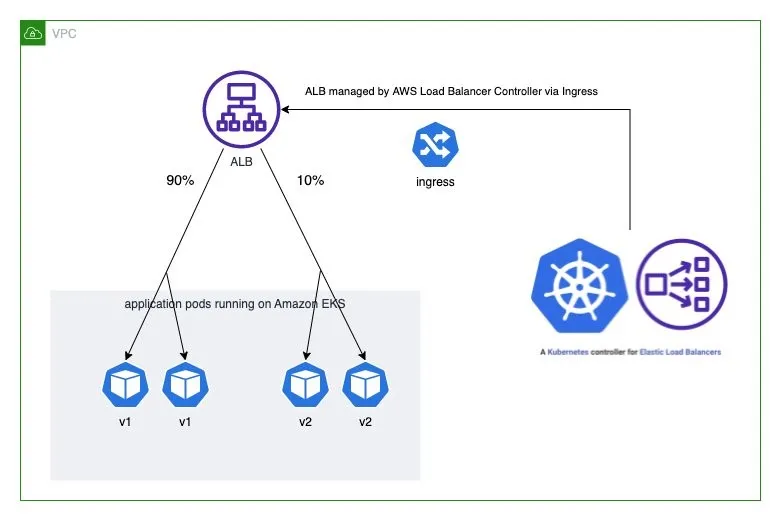
예를 들어, 아래의 Ingress 리소스는 ALB가 모든 트래픽을 hello-kubernetes-v1 서비스로 전달하도록 설정합니다(가중치: 100 vs. 0).
주의 사항
애노테이션에서 사용된 action-name은 Ingress 규칙의 serviceName과 일치해야 합니다.
servicePort는 반드시 use-annotation으로 설정되어야 합니다.# cat <<EOF | kubectl apply -f - apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: "hello-kubernetes" namespace: "hello-kubernetes" annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/target-type: ip alb.ingress.kubernetes.io/actions.blue-green: | { "type":"forward", "forwardConfig":{ "targetGroups":[ { "serviceName":"hello-kubernetes-v1", "servicePort":"80", "weight":100 }, { "serviceName":"hello-kubernetes-v2", "servicePort":"80", "weight":0 } ] } } labels: app: hello-kubernetes spec: ingressClassName: alb rules: - http: paths: - path: / pathType: Prefix backend: service: name: blue-green port: name: use-annotation EOF # 확인 kubectl get ingress -n hello-kubernetes kubectl describe ingress -n hello-kubernetes ... Rules: Host Path Backends ---- ---- -------- * / blue-green:use-annotation (<error: endpoints "blue-green" not found>) Annotations: alb.ingress.kubernetes.io/actions.blue-green: { "type":"forward", "forwardConfig":{ "targetGroups":[ { "serviceName":"hello-kubernetes-v1", "servicePort":"80", "weight":100 }, { "serviceName":"hello-kubernetes-v2", "servicePort":"80", "weight":0 ... # 반복 접속 확인 ELB_URL=$(kubectl get ingress -n hello-kubernetes -o=jsonpath='{.items[0].status.loadBalancer.ingress[0].hostname}') while true; do curl -s $ELB_URL | grep version; sleep 1; done You are reaching hello-kubernetes version 1 You are reaching hello-kubernetes version 1 ...

Blue/green deployment
To perform the blue/green deployment, update the ingress annotation to move all weight to version 2:# cat <<EOF | kubectl apply -f - apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: "hello-kubernetes" namespace: "hello-kubernetes" annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/target-type: ip alb.ingress.kubernetes.io/actions.blue-green: | { "type":"forward", "forwardConfig":{ "targetGroups":[ { "serviceName":"hello-kubernetes-v1", "servicePort":"80", "weight":0 }, { "serviceName":"hello-kubernetes-v2", "servicePort":"80", "weight":100 } ] } } labels: app: hello-kubernetes spec: ingressClassName: alb rules: - http: paths: - path: / pathType: Prefix backend: service: name: blue-green port: name: use-annotation EOF # 확인 kubectl describe ingress -n hello-kubernetes # 반복 접속 확인 : 적용에 약간의 시간 소요 ELB_URL=$(kubectl get ingress -n hello-kubernetes -o=jsonpath='{.items[0].status.loadBalancer.ingress[0].hostname}') while true; do curl -s $ELB_URL | grep version; sleep 1; done You are reaching hello-kubernetes version 2 You are reaching hello-kubernetes version 2 ...

Deploy Ingress and test the canary deployment
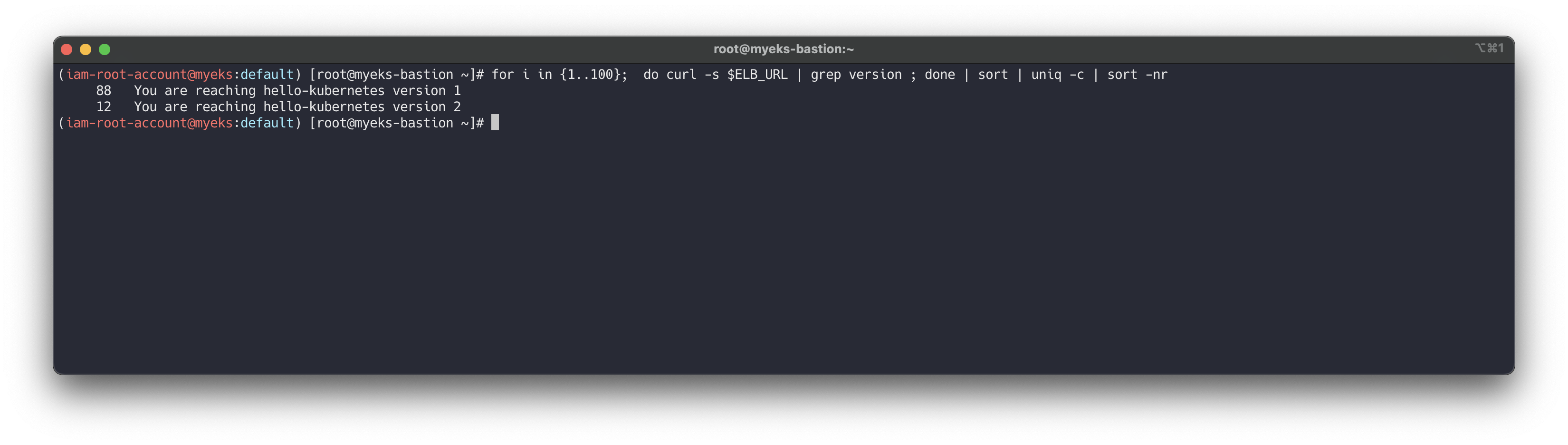
Instead of moving all traffic to version 2, we can shift the traffic slowly towards version 2 by increasing the weight on version 2 step by step. This allows version 2 to be verified against a small portion of the production traffic before moving more traffic over. The following example shows that 10 percent of the traffic is shifted to version 2, while 90 percent of the traffic remains with version 1.# cat <<EOF | kubectl apply -f - apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: "hello-kubernetes" namespace: "hello-kubernetes" annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/target-type: ip alb.ingress.kubernetes.io/actions.blue-green: | { "type":"forward", "forwardConfig":{ "targetGroups":[ { "serviceName":"hello-kubernetes-v1", "servicePort":"80", "weight":90 }, { "serviceName":"hello-kubernetes-v2", "servicePort":"80", "weight":10 } ] } } labels: app: hello-kubernetes spec: ingressClassName: alb rules: - http: paths: - path: / pathType: Prefix backend: service: name: blue-green port: name: use-annotation EOF # 확인 kubectl describe ingress -n hello-kubernetes # 반복 접속 확인 : 적용에 약간의 시간 소요 ELB_URL=$(kubectl get ingress -n hello-kubernetes -o=jsonpath='{.items[0].status.loadBalancer.ingress[0].hostname}') while true; do curl -s $ELB_URL | grep version; sleep 1; done # 100번 접속 for i in {1..100}; do curl -s $ELB_URL | grep version ; done | sort | uniq -c | sort -nr
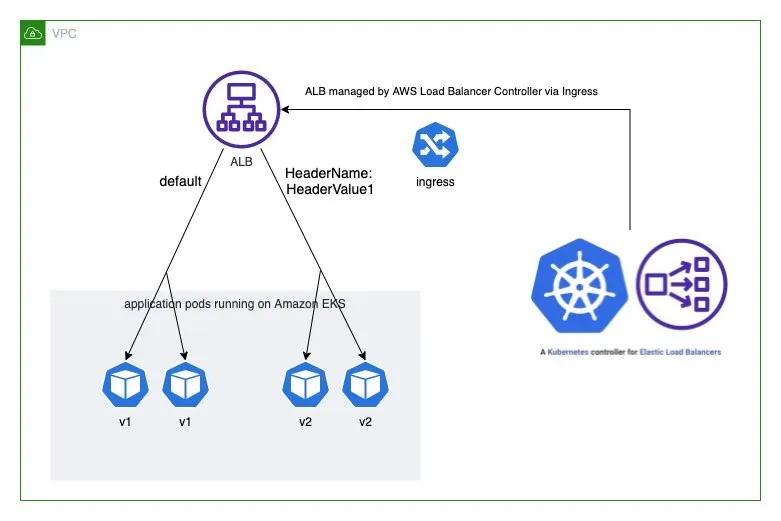
Deploy ingress and test the A/B testing
# cat <<EOF | kubectl apply -f - apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: "hello-kubernetes" namespace: "hello-kubernetes" annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/target-type: ip alb.ingress.kubernetes.io/conditions.ab-testing: > [{"field":"http-header","httpHeaderConfig":{"httpHeaderName": "HeaderName", "values":["kans-study-end"]}}] alb.ingress.kubernetes.io/actions.ab-testing: > {"type":"forward","forwardConfig":{"targetGroups":[{"serviceName":"hello-kubernetes-v2","servicePort":80}]}} labels: app: hello-kubernetes spec: ingressClassName: alb rules: - http: paths: - path: / pathType: Prefix backend: service: name: ab-testing port: name: use-annotation - path: / pathType: Prefix backend: service: name: hello-kubernetes-v1 port: name: http EOF # 확인 kubectl describe ingress -n hello-kubernetes # 반복 접속 확인 : 적용에 약간의 시간 소요 ELB_URL=$(kubectl get ingress -n hello-kubernetes -o=jsonpath='{.items[0].status.loadBalancer.ingress[0].hostname}') while true; do curl -s $ELB_URL | grep version; sleep 1; done ... while true; do curl -s -H "HeaderName: kans-study-end" $ELB_URL | grep version; sleep 1; done ... # 100번 접속 for i in {1..100}; do curl -s $ELB_URL | grep version ; done | sort | uniq -c | sort -nr for i in {1..100}; do curl -s -H "HeaderName: kans-study-end" $ELB_URL | grep version ; done | sort | uniq -c | sort -nr

👉 Step 11. Network Policies with VPC CNI
- AWS EKS fully supports the upstream Kubernetes Network Policy API, ensuring compatibility and adherence to Kubernetes standards.
동작: eBPF로 패킷 필터링 동작 - Network Policy Controller, Node Agent, eBPF SDK
사전 조건 : EKS 1.25 버전 이상, AWS VPC CNI 1.14 이상, OS 커널 5.10 이상 EKS 최적화 AMI(AL2, Bottlerocket, Ubuntu)
Network Policy Controller : v1.25 EKS 버전 이상 자동 설치, 통제 정책 모니터링 후 eBPF 프로그램을 생성 및 업데이트하도록 Node Agent에 지시
Node Agent : AWS VPC CNI 번들로 ipamd 플러그인과 함께 설치됨(aws-node 데몬셋). eBPF 프래그램을 관리
eBPF SDK : AWS VPC CNI에는 노드에서 eBPF 프로그램과 상호 작용할 수 있는 SDK 포함, eBPF 실행의 런타임 검사, 추적 및 분석 가능
→ AWS SG for Pods 와 함께 사용하면 더욱 좋습니다!
사전 준비 및 기본 정보 확인
# Network Policy 기본 비활성화되어 있어, 활성화 필요 : 실습 환경은 미리 활성화 설정 추가되어 있음 tail -n 11 myeks.yaml addons: - name: vpc-cni # no version is specified so it deploys the default version version: latest # auto discovers the latest available attachPolicyARNs: - arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy configurationValues: |- enableNetworkPolicy: "true" # Node Agent 확인 : AWS VPC CNI 1.14 이상 버전 정보 확인 kubectl get ds aws-node -n kube-system -o yaml | k neat ... - args: - --enable-ipv6=false - --enable-network-policy=true ... volumeMounts: - mountPath: /host/opt/cni/bin name: cni-bin-dir - mountPath: /sys/fs/bpf name: bpf-pin-path - mountPath: /var/log/aws-routed-eni name: log-dir - mountPath: /var/run/aws-node name: run-dir ... kubectl get ds aws-node -n kube-system -o yaml | grep -i image: kubectl get pod -n kube-system -l k8s-app=aws-node kubectl get ds -n kube-system aws-node -o jsonpath='{.spec.template.spec.containers[*].name}{"\n"}' aws-node aws-eks-nodeagent # EKS 1.25 버전 이상 확인 kubectl get nod # OS 커널 5.10 이상 확인 ssh ec2-user@$N1 uname -r 5.10.210-201.852.amzn2.x86_64 # 실행 중인 eBPF 프로그램 확인 for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo /opt/cni/bin/aws-eks-na-cli ebpf progs; echo; done ... Programs currently loaded : Type : 26 ID : 6 Associated maps count : 1 ======================================================================================== Type : 26 ID : 8 Associated maps count : 1 ======================================================================================== # 각 노드에 BPF 파일 시스템을 탑재 확인 ssh ec2-user@$N1 mount | grep -i bpf none on /sys/fs/bpf type bpf (rw,nosuid,nodev,noexec,relatime,mode=700) ssh ec2-user@$N1 df -a | grep -i bpf none 0 0 0 - /sys/fs/bpf
🔥 실습
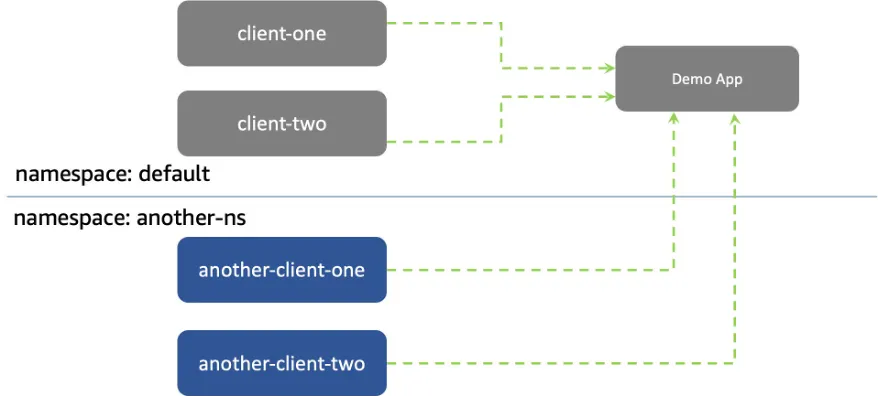
샘플 애플리케이션 배포 및 네트워크 정책 적용 실습 - Link
https://aws.amazon.com/ko/blogs/containers/amazon-vpc-cni-now-supports-kubernetes-network-policies/# git clone https://github.com/aws-samples/eks-network-policy-examples.git cd eks-network-policy-examples tree advanced/manifests/ kubectl apply -f advanced/manifests/ # 확인 kubectl get pod,svc kubectl get pod,svc -n another-ns # 통신 확인 kubectl exec -it client-one -- curl demo-app kubectl exec -it client-two -- curl demo-app kubectl exec -it another-client-one -n another-ns -- curl demo-app kubectl exec -it another-client-one -n another-ns -- curl demo-app.default kubectl exec -it another-client-two -n another-ns -- curl demo-app.default.svc
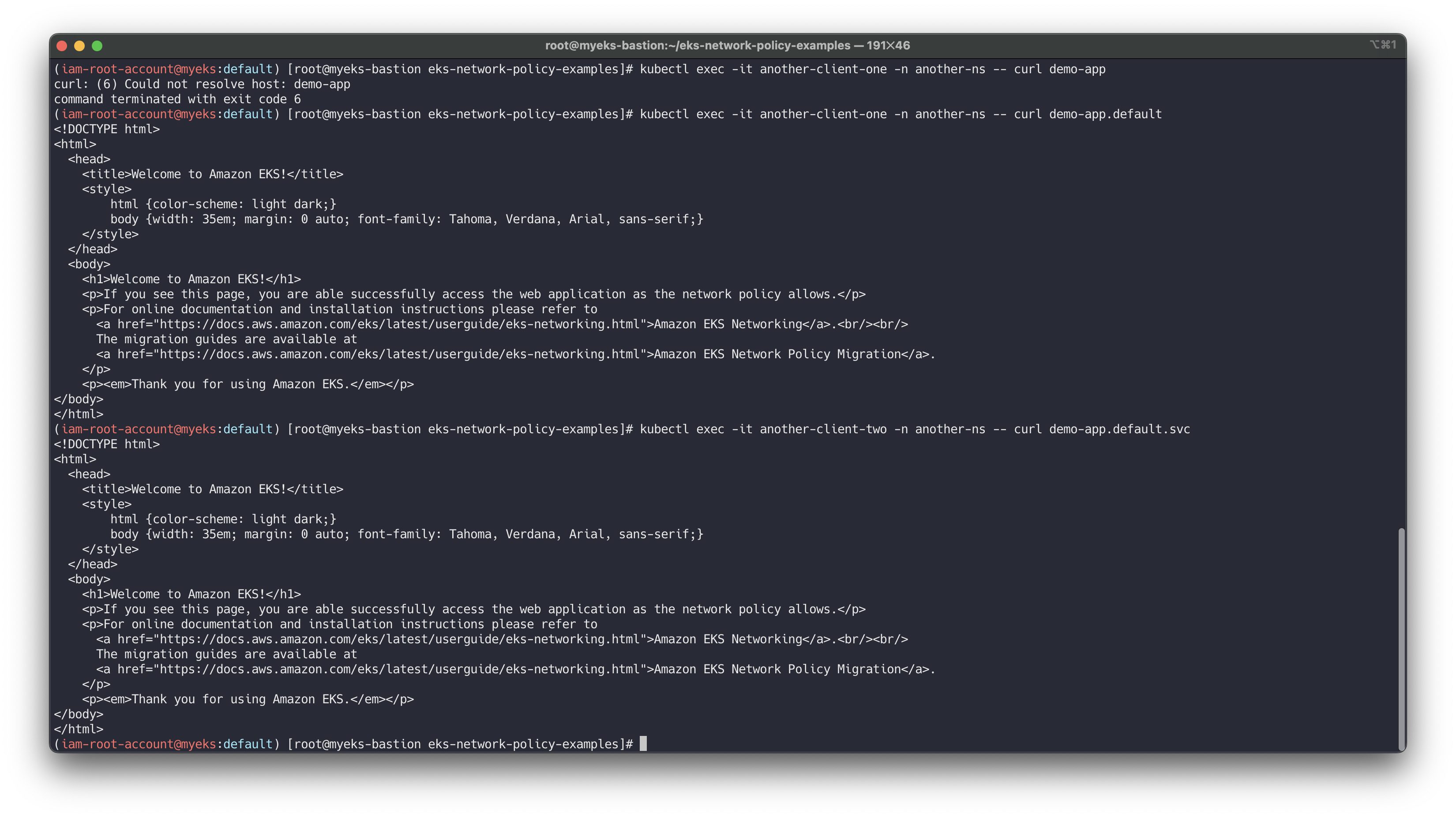
모든 트래픽 거부
# 모니터링 # kubectl exec -it client-one -- curl demo-app while true; do kubectl exec -it client-one -- curl --connect-timeout 1 demo-app ; date; sleep 1; done # 정책 적용 cat advanced/policies/01-deny-all-ingress.yaml kubectl apply -f advanced/policies/01-deny-all-ingress.yaml kubectl get networkpolicy # 실행 중인 eBPF 프로그램 확인 for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo /opt/cni/bin/aws-eks-na-cli ebpf progs; echo; done for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo /opt/cni/bin/aws-eks-na-cli ebpf loaded-ebpfdata; echo; done ... > node 192.168.3.201 << PinPath: /sys/fs/bpf/globals/aws/programs/demo-app-6fd76f694b-default_handle_ingress Pod Identifier : demo-app-6fd76f694b-default Direction : ingress Prog ID: 9 Associated Maps -> Map Name: ingress_map Map ID: 7 Map Name: policy_events Map ID: 6 Map Name: aws_conntrack_map Map ID: 5 ======================================================================================== PinPath: /sys/fs/bpf/globals/aws/programs/demo-app-6fd76f694b-default_handle_egress Pod Identifier : demo-app-6fd76f694b-default Direction : egress Prog ID: 10 Associated Maps -> Map Name: aws_conntrack_map Map ID: 5 Map Name: egress_map Map ID: 8 Map Name: policy_events Map ID: 6 ======================================================================================== ssh ec2-user@$N3 sudo /opt/cni/bin/aws-eks-na-cli ebpf dump-maps 5 ssh ec2-user@$N3 sudo /opt/cni/bin/aws-eks-na-cli ebpf dump-maps 9 ssh ec2-user@$N3 sudo /opt/cni/bin/aws-eks-na-cli ebpf dump-maps 10 # 정책 다시 삭제 kubectl delete -f advanced/policies/01-deny-all-ingress.yaml for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo /opt/cni/bin/aws-eks-na-cli ebpf loaded-ebpfdata; echo; done # 다시 적용 kubectl apply -f advanced/policies/01-deny-all-ingress.yaml
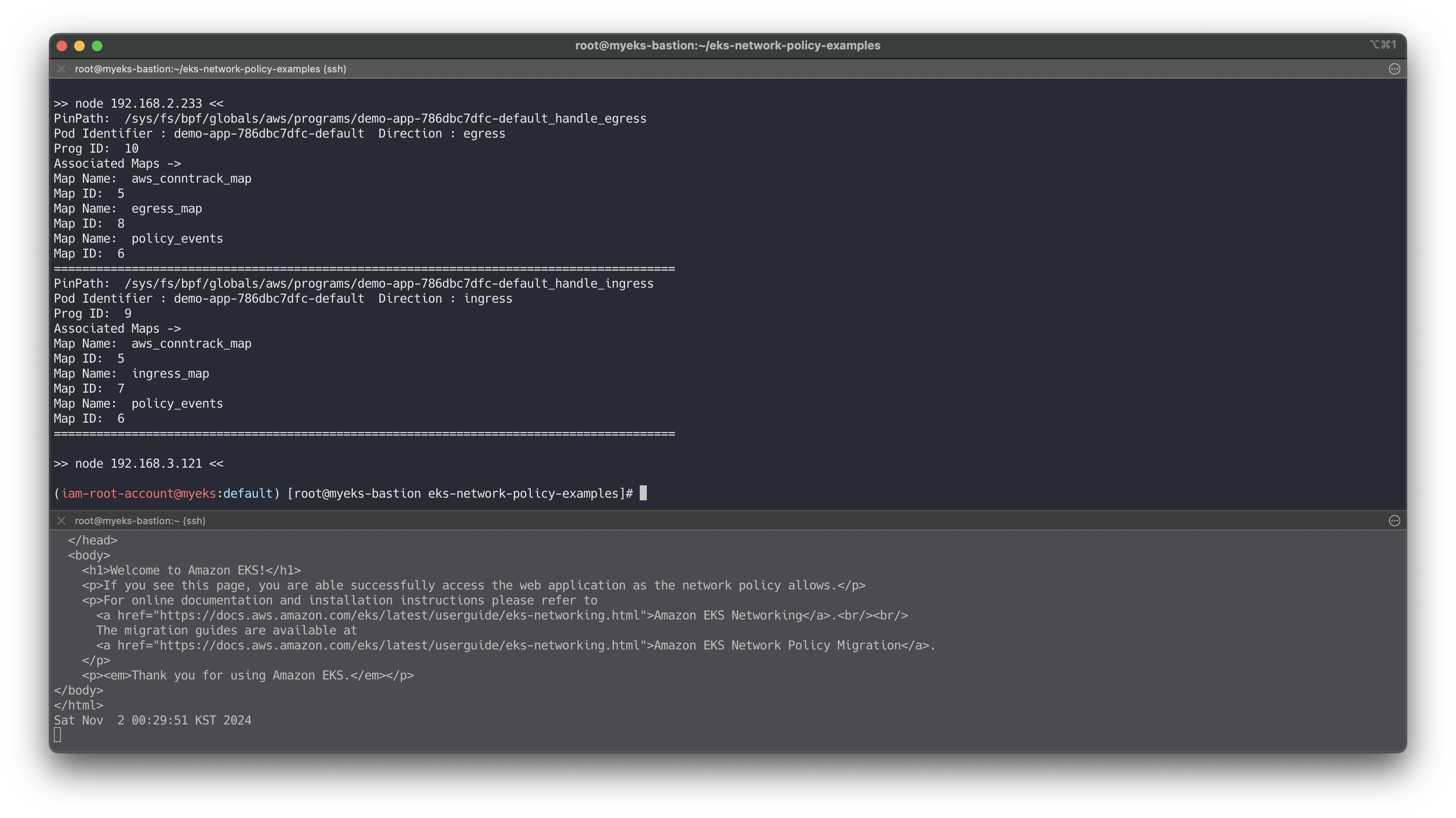
동일 네임스페이스 + 클라이언트1 로부터의 수신 허용
# cat advanced/policies/03-allow-ingress-from-samens-client-one.yaml kubectl apply -f advanced/policies/03-allow-ingress-from-samens-client-one.yaml kubectl get networkpolicy for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo /opt/cni/bin/aws-eks-na-cli ebpf loaded-ebpfdata; echo; done ssh ec2-user@$N3 sudo /opt/cni/bin/aws-eks-na-cli ebpf dump-maps 5 ssh ec2-user@$N3 sudo /opt/cni/bin/aws-eks-na-cli ebpf dump-maps 9 ssh ec2-user@$N3 sudo /opt/cni/bin/aws-eks-na-cli ebpf dump-maps 10 # 클라이언트2 수신 확인 kubectl exec -it client-two -- curl --connect-timeout 1 demo-app
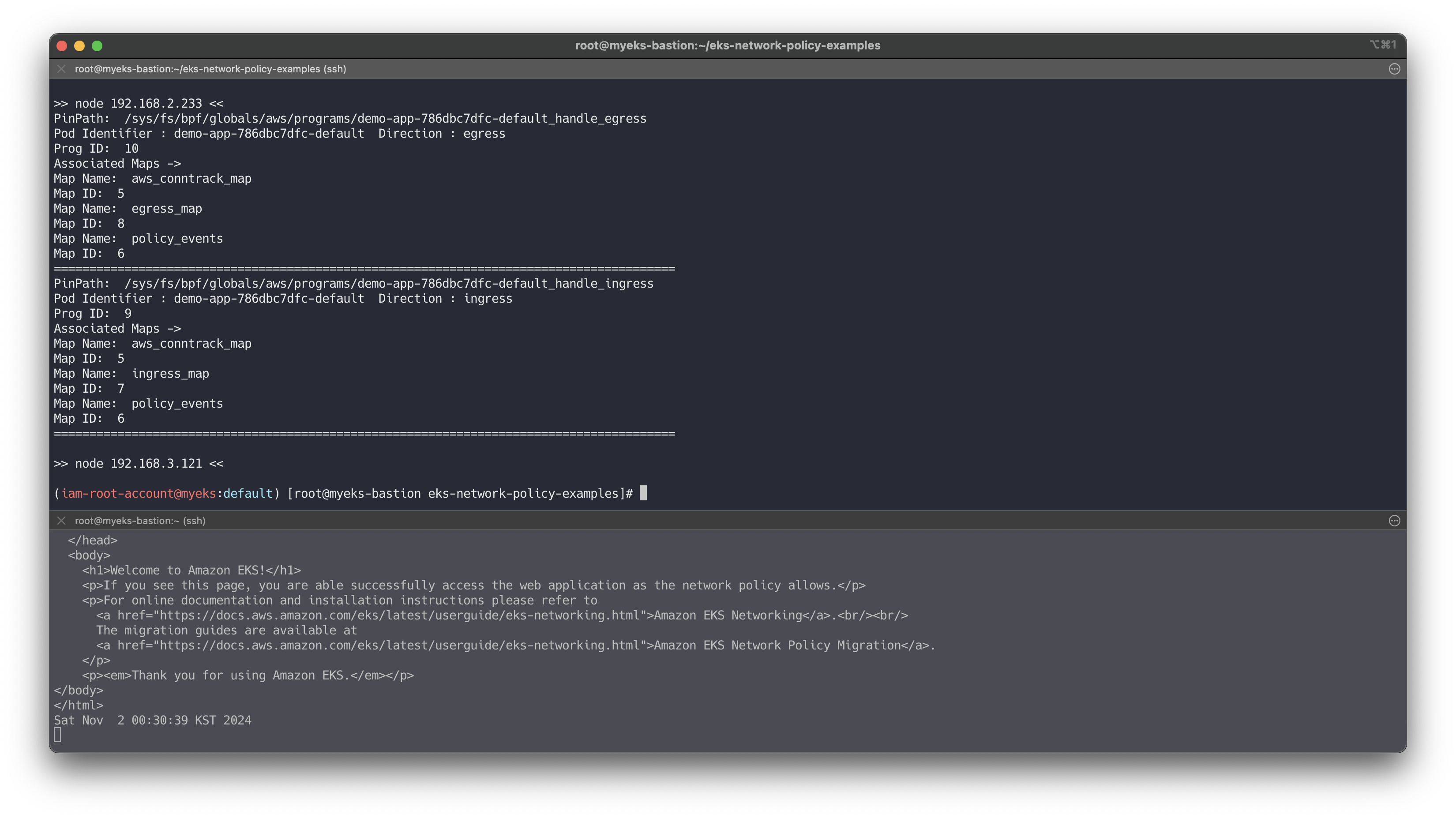
another-ns 네임스페이스로부터의 수신 허용
# 모니터링 # kubectl exec -it another-client-one -n another-ns -- curl --connect-timeout 1 demo-app.default while true; do kubectl exec -it another-client-one -n another-ns -- curl --connect-timeout 1 demo-app.default ; date; sleep 1; done # cat advanced/policies/04-allow-ingress-from-xns.yaml kubectl apply -f advanced/policies/04-allow-ingress-from-xns.yaml kubectl get networkpolicy for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo /opt/cni/bin/aws-eks-na-cli ebpf loaded-ebpfdata; echo; done ssh ec2-user@$N3 sudo /opt/cni/bin/aws-eks-na-cli ebpf dump-maps 5 ssh ec2-user@$N3 sudo /opt/cni/bin/aws-eks-na-cli ebpf dump-maps 9 ssh ec2-user@$N3 sudo /opt/cni/bin/aws-eks-na-cli ebpf dump-maps 10 # kubectl exec -it another-client-two -n another-ns -- curl --connect-timeout 1 demo-app.default
eBPF 관련 정보 확인
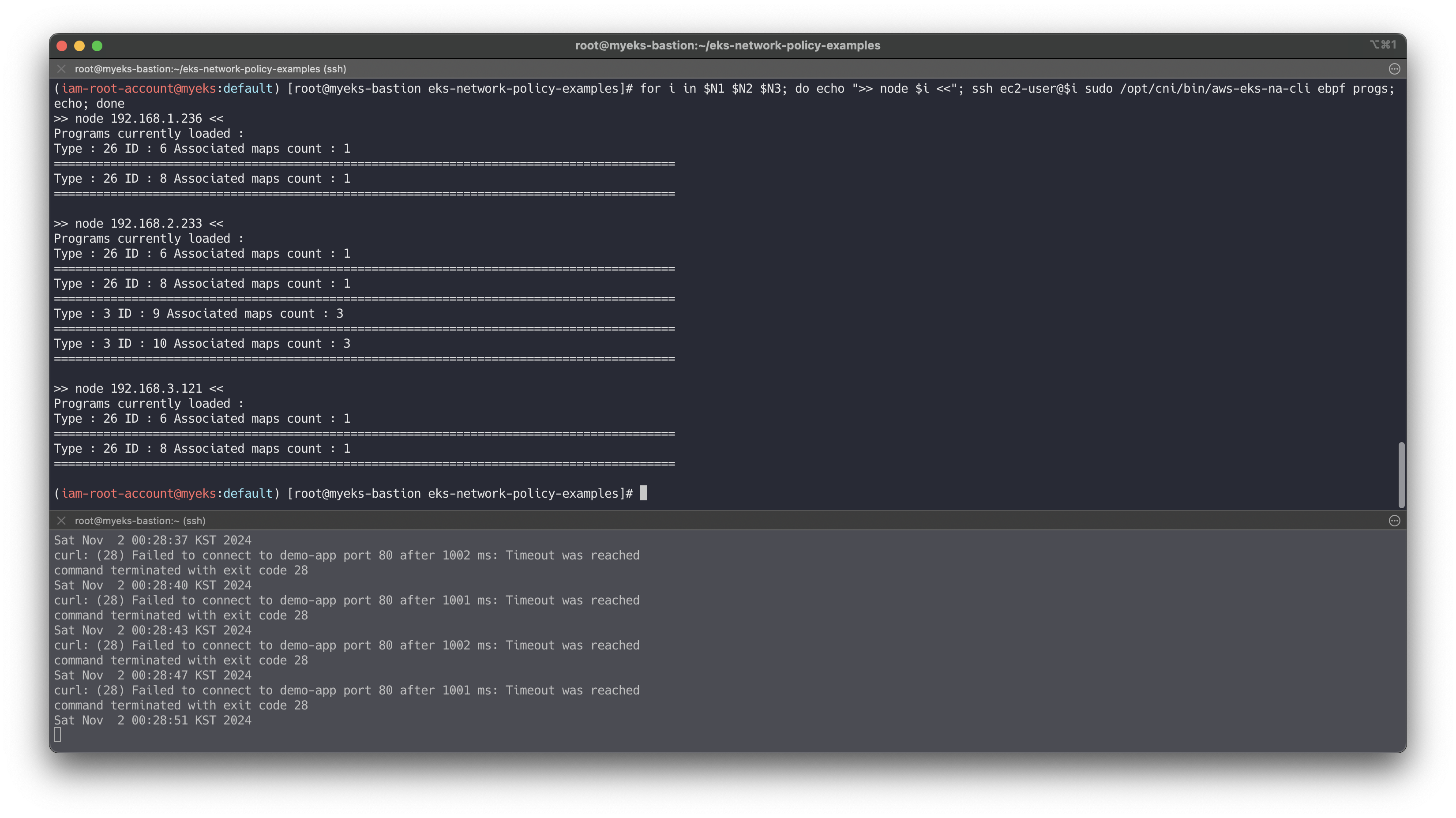
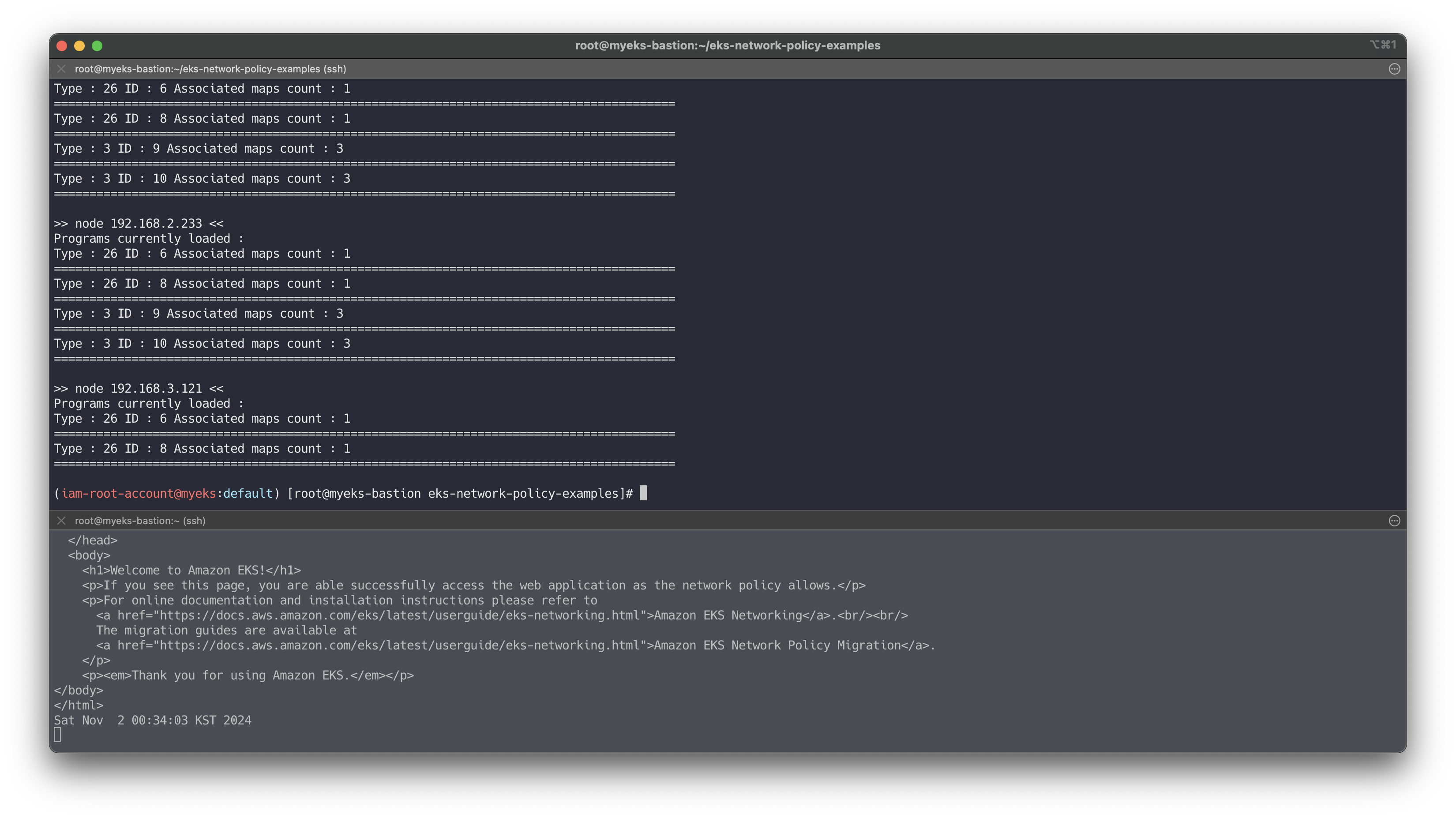
# 실행 중인 eBPF 프로그램 확인 for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo /opt/cni/bin/aws-eks-na-cli ebpf progs; echo; done # eBPF 로그 확인 for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo cat /var/log/aws-routed-eni/ebpf-sdk.log; echo; done for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo cat /var/log/aws-routed-eni/network-policy-agent; echo; done
송신 트래픽 거부 : 기본 네임스페이스의 클라이언트-1 포드에서 모든 송신 격리를 적용
# 모니터링 while true; do kubectl exec -it client-one -- curl --connect-timeout 1 google.com ; date; sleep 1; done # cat advanced/policies/06-deny-egress-from-client-one.yaml kubectl apply -f advanced/policies/06-deny-egress-from-client-one.yaml kubectl get networkpolicy for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo /opt/cni/bin/aws-eks-na-cli ebpf loaded-ebpfdata; echo; done ssh ec2-user@$N3 sudo /opt/cni/bin/aws-eks-na-cli ebpf dump-maps 5 ssh ec2-user@$N3 sudo /opt/cni/bin/aws-eks-na-cli ebpf dump-maps 9 ssh ec2-user@$N3 sudo /opt/cni/bin/aws-eks-na-cli ebpf dump-maps 10 # kubectl exec -it client-one -- nslookup demo-app
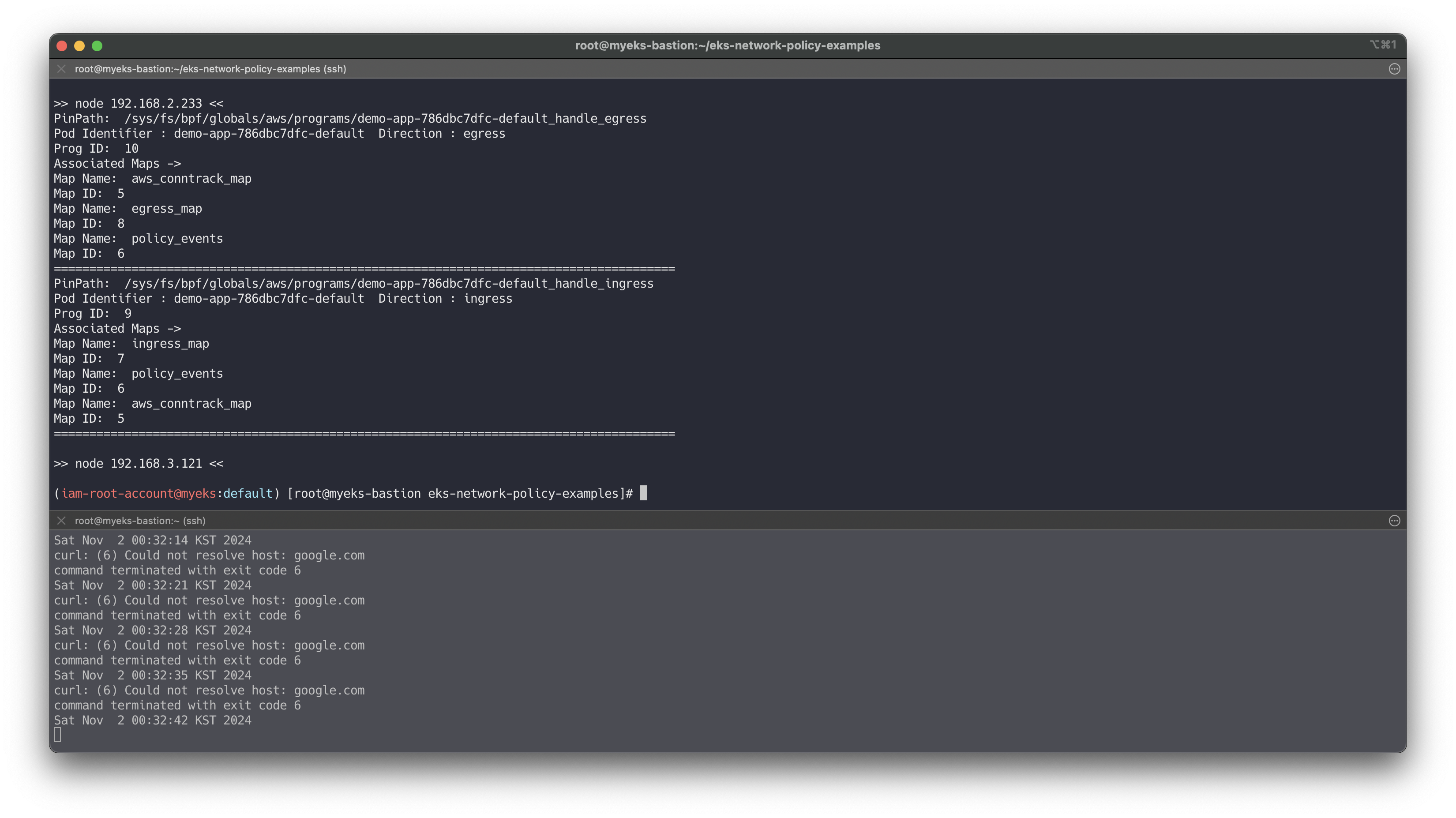
송신 트래픽 허용 : DNS 트래픽을 포함하여 여러 포트 및 네임스페이스에서의 송신을 허용
# 모니터링 while true; do kubectl exec -it client-one -- curl --connect-timeout 1 demo-app ; date; sleep 1; done # cat advanced/policies/08-allow-egress-to-demo-app.yaml | yh kubectl apply -f advanced/policies/08-allow-egress-to-demo-app.yaml kubectl get networkpolicy
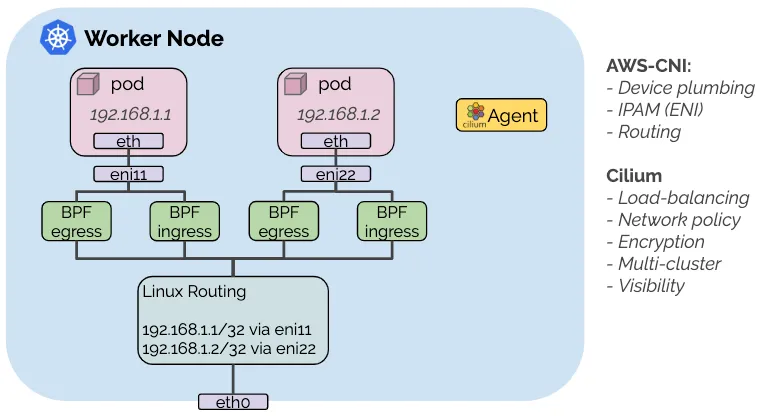
👉 Step 12. AWS VPC CNI + Cilium CNI : Hybrid mode
구성 방안 : 각 CNI의 강점을 조합하여 사용 - AWS VPC CNI(IPAM, Routing 등), Cilium(LB, Network Policy, Encryption, Visibility) - Docs
 https://docs.cilium.io/en/stable/installation/cni-chaining-aws-cni/
https://docs.cilium.io/en/stable/installation/cni-chaining-aws-cni/
- In this hybrid mode, the AWS VPC CNI plugin is responsible for setting up the virtual network devices as well as for IP address management (IPAM) via ENIs.
- After the initial networking is setup for a given pod, the Cilium CNI plugin is called to attach eBPF programs to the network devices set up by the AWS VPC CNI plugin in order to enforce network policies, perform load-balancing and provide encryption.
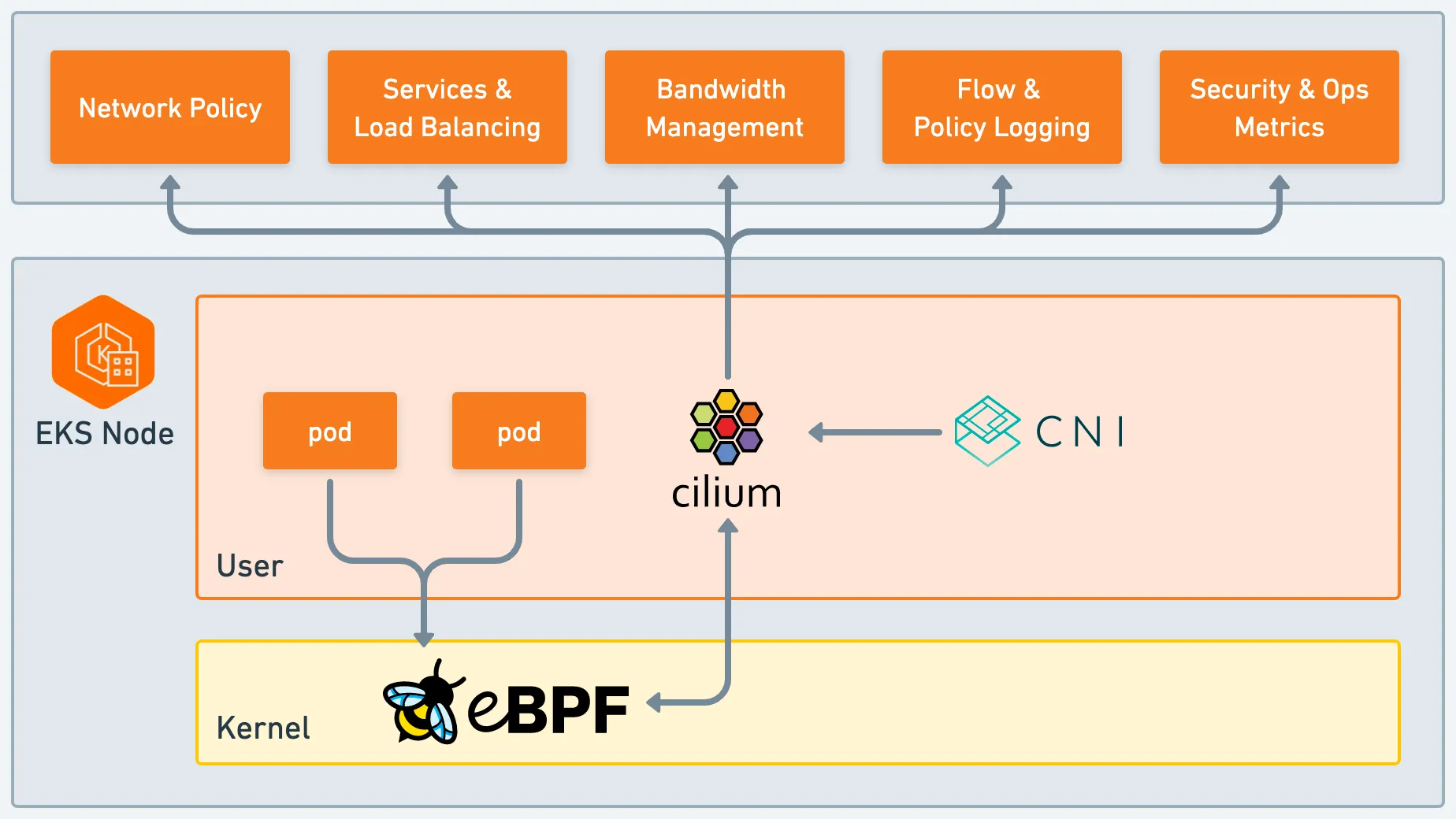
- 제약 사항 : Layer 7 Policy (see GitHub issue 12454) , IPsec Transparent Encryption (see GitHub issue 15596)
- 다만, Cilium Full 기능 사용을 위해서는 AWS VPN CNI를 제거하고 Fully to Cilium 사용을 권장함 - Youtube
(참고) Cilium CNI 설치 → 기존 배치 파드는 Restart 필요
# Cilium CNI 설치 helm repo add cilium https://helm.cilium.io/ helm install cilium cilium/cilium --version 1.16.3 \ --namespace kube-system \ --set cni.chainingMode=aws-cni \ --set cni.exclusive=false \ --set enableIPv4Masquerade=false \ --set routingMode=native \ --set endpointRoutes.enabled=true ## This will enable chaining with the AWS VPC CNI plugin. ## It will also disable tunneling, as it’s not required since ENI IP addresses can be directly routed in the VPC. ## For the same reason, masquerading can be disabled as well.
📌 Conclusion
Kubernetes 네트워크 스터디를 통해 Amazon VPC CNI를 활용한 네트워크 구성과 관리 방법을 심층적으로 학습하였습니다.
파드와 ENI 할당을 이해하고, 네트워크 정책을 통해 파드 간 통신을 제어하면서 eBPF 기반의 정책 적용 과정을 경험할 수 있었습니다.
AWS Load Balancer Controller를 통해 Blue/Green 배포와 Canary 배포 방식을 구현하며, 로드밸런서의 역할을 학습하였습니다. 또한, Cilium CNI와 AWS VPC CNI를 하이브리드로 구성하여 eBPF 기반 네트워크 정책의 유연성을 높이는 방법을 실습하였습니다. 이를 통해 클러스터 네트워크 성능 최적화와 효율적 자원 관리를 실현할 수 있음을 확인했습니다.
9주간의 스터디를 통해 다양한 네트워크 관련 주제를 밀도 있게 다룰 수 있어 매우 유익했습니다.
🔗 Reference
