
[C173] 모니터링 시스템에는 메트릭 수집을 위한 두가지 방식의 메커니즘이 존재합니다. 바로 Pull 방식과 Push 방식입니다. 프로메테우스는 어떤 방식의 메커니즘을 사용하나요? 또한 Pull 방식과 Push 방식은 어떻게 다르며, 장단점은 무엇인지, 또한 해당 방식을 사용하는 모니터링 도구는 어떤 것들이 있는지 연구해보세요.
📌 정리
두 모델 모두 장단점이 있다.
풀 기반 모델은 신뢰성이 약간 더 높고(특히 대규모 배포에 대해 이야기할 때) 가능한 메트릭 수집 사용 사례를 모두 충족하기 위해 필요한 해결 방법이 조금 더 적기 때문에 보다 널리 사용되고 있다.
Borgmon 모니터링 시스템의 후예인 Prometheus와 같은 시스템이 매우 인기를 얻은 데는 이유가 있습니다. 그리고 우리가 알고 있듯이 Borgmon은 나중에 우리 모두가 알고 사랑하는 시스템인 Kubernetes 가 된 Google의 Borg라는 작업 일정 시스템을 모니터링하는 데 사용되었습니다 .
📌 Push vs Pull
메트릭이 모니터링 시스템으로 수집되는 방법은 두가지 방식이 있다.
메트릭이 시스템으로 Push되거나 시스템에서 필요 메트릭을 Pull하는 방식
Push 방식의 모니터링
- Graphite
Pull 방식의 모니터링
- Prometheus
어떤것이 나은지?에 대한 명확한 답은 없으며, 각각의 장단점이 존재한다.
👉 In Favor Of Pull: Easier To Control The Authenticity and Amount of Data
데이터를 가져올 때 서버 자체가 연결을 시작하기 때문에 데이터의 신뢰성을 확신할 수 있습니다.
대부분의 사용자가 공용 IP 주소 뒤에 라우터를 가지고 있기 때문에 데이터 경로를 훨씬 더 명확하게 하고 데이터가 실제로 왔는지 여부에 대해 쉽게 오인할 수 있 다고 생각합니다.
TCP 기반 Pull 시스템에서는 메트릭에 직접 액세스할 수 있어야 합니다.
즉, 메트릭 데이터를 사용할 수 있는 포트는 항상 수신 대기인 반면 푸시 기반 시스템의 경우 매우 빠르게 사라지고 나타나는 임시 연결이 사용됩니다.
또한 메트릭 데이터를 수집할 정확한 대상을 미리 알고 있기 때문에 풀 기반 시스템의 용량을 더 쉽게 계획할 수 있습니다.
반면에 푸시 기반 시스템에서는 모든 종류의 시스템이 메트릭 수집 서버로 푸시할 수 있습니다.
이 문제는 데이터를 수락할 서버의 화이트리스트를 사용하여 해결할 수 있지만 대부분의 푸시 기반 시스템은 이를 지원하지 않습니다. 또한 구현이 아닌 두 가지 다른 모델의 특성을 고려합니다.
👉 In Favor Of Push: Easier To Implement Replication To Different Ingestion Points
모든 것이 클라이언트 자체에 의해 시작되기 때문에 동일한 트래픽을 다른 서버에 복제하는 것이 더 쉬워집니다.
둘 이상의 대상 IP 주소로 전송하기만 하면 됩니다.
또한 모든 수신기가 동일한 정확한 데이터를 얻을 수 있습니다.
HTTP pull 방법을 사용하는 Prometheus의 두 가지 다른 인스턴스를 가동하면 동일한 데이터가 없을 가능성이 큽니다.
- 타임스탬프가 다릅니다.
Graphite의 경우 타임스탬프는 데이터 내부에 인코딩되어야 합니다. (Prometheus에서는 선택 사항) - 스크래핑 시작 시 추가된 지터로 인해 대부분의 시간 스크래핑이 동시에 발생하지 않기 때문에 시계열 값이 다를 가능성이 가장 높습니다.
👉 In Favor Of Push: Easy To Model Shortlived Batch-Jobs
푸시 방법에서는 클라이언트 자체가 메트릭을 서버에 푸시합니다.
반면에 pull 방식에서는 서버가 주기적으로 클라이언트를 조사하고 메트릭을 수집합니다.
프로메테우스에서는 이것을 scrape period이라고 합니다. 클라이언트가 기간보다 오래 생존하지 않으면 메트릭이 손실됩니다. 이 그림은 루프가 어떻게 작동하는지 설명합니다.
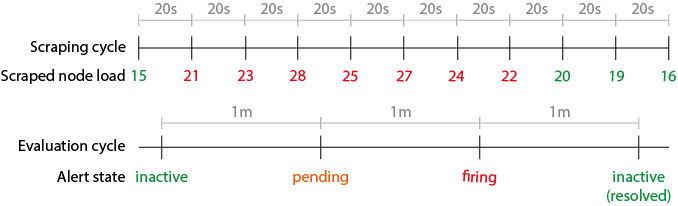
푸시 방식에서는 일괄 작업이 완료될 때마다 메트릭을 보낼 수 있으므로 이에 대한 문제가 없습니다.
물론 프로메테우스는 pushgateway 라는 것으로 이를 해결할 수 있습니다.
기본적으로 Prometheus의 Graphite라고도 하는 Prometheus에 의해 주기적으로 스크랩되는 메트릭 수신기입니다.
이것은 graphite-exporter 와 같은 방식으로 작동합니다.
그럼에도 불구하고 문제는 여전히 존재합니다. 예를 들어 푸시 게이트웨이가 다운되면 메트릭이 사라질 수 있습니다. 또는 클라이언트가 Prometheus가 긁을 수 있는 것보다 빠르게 업데이트하면 메트릭 값이 손실될 수 있습니다. 푸시 방식과 Graphite는 이 문제를 겪지 않습니다.
👉 In Favor Of Pull: Easier To Retrieve Data On Demand (And Debug)
TCP(HTTP) 위에 pull 메서드가 있다는 것은 요청 시 데이터를 검색하고 문제를 디버그하는 것이 매우 쉽다는 것을 의미합니다.
특히 메트릭 데이터가 Prometheus에서 사용하는 형식과 같이 사람이 읽을 수 있고 쉽게 이해할 수 있는 경우 클라이언트 측과 서버 측의 오류를 쉽게 구별할 수 있습니다.
푸시 방법에서는 사용자가 할 수 있는 범위가 제한적이게 됩니다. 그 이유는 어떤 측정항목도 수신하지 못한다면 다음 두 가지 중 하나를 의미하기 때문입니다.
- 네트워크에 문제가 있는 경우
- 클라이언트에 문제가 있는 경우
푸시(TCP/HTTP) 방식으로 웹 브라우저에서 메트릭 데이터를 찾을 수 있는 IP 주소와 포트로 이동하기만 하면 이 둘 사이를 쉽게 확인할 수 있었습니다.
TCP 연결 재설정을 받으면 네트워크는 정상이지만 클라이언트에 문제가 있음을 의미합니다.
응답이 없으면 네트워크에 문제가 있음을 의미합니다.
물론 이것은 포트가 닫힐 때 TCP_RST를 되돌려 보내는 클라이언트에 따라 다르지만 대부분의 기계가 작동하는 방식입니다.
👉 In Favor Of Push: Might Potentially Be More Performant
푸시 방식은 일반적으로 UDP를 사용하는 반면 풀 방식은 TCP(HTTP)를 기반을 사용합니다.
즉, 메트릭스를 추출하는 것보다 잠재적으로 메트릭스를 더 효과적으로 푸시할 수 있습니다.
이는 UDP 연결을 관리하기 위한 오버헤드가 훨씬 적기 때문입니다.
예를 들어 피어에게 보낸 메시지가 실제로 수신되었고 올바른 순서로 수신되었는지 확인할 필요가 없습니다.
그러나 TCP 지원이 대부분의 상용 네트워크 카드에 내장되어 있고 하드웨어 가속을 사용하는 운영 체제가 곳곳에 있기 때문에 오버헤드는 예를 들어 90년대처럼 크지 않을 수 있습니다.
참조 레퍼런스
