
1. 데이터베이스 기본 개념
-
데이터베이스 : 일정한 체계 속에 저장된 데이터의 집합
-
데이터 저장 단위 : Table(표)
-
row(행) : 테이블에서의 하나의 개체
-
column(열) : 하나의 개체가 가지는 속성
-
DBMS(Data Base Management System) : 데이터베이스 관리 시스템
2. 테이블 생성하기
-
DATATYPE
-
INT - 정수(Integer)
-
DOUBLE-실수형 데이터 타입
-
TEXT - 문자형
-
-
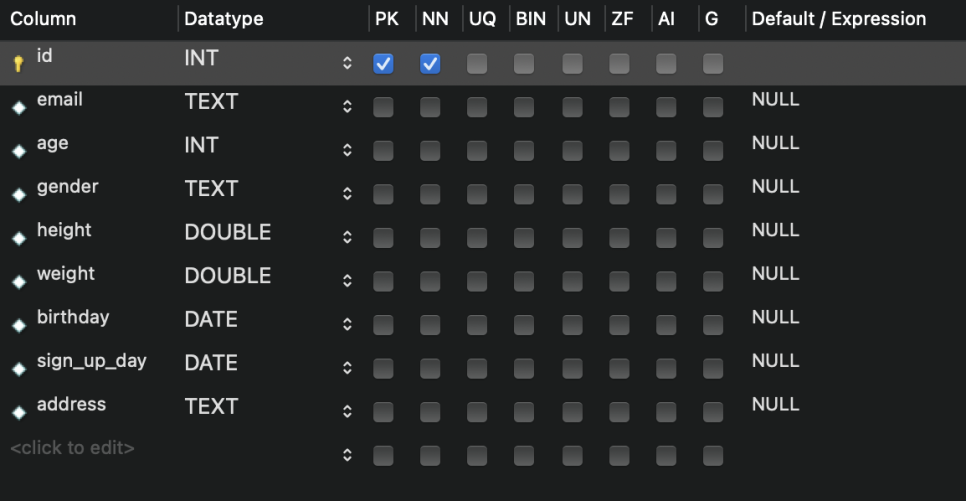
Primary Key(기본키) : 테이블에서 하나의 row를 고유하게 식별할 수 있도록 해주는 column
-
Natural Key : 실제로 어떤 개체가 갖고 있는 속성을 나타내는 컬럼이 Primary Key가 됐을 때
-
Surrogate Key : 어떤 개체의 실제 속성은 아니지만 Primary Key로 쓰기 위해 추가한 컬럼
-
-
Not Null : 이 컬럼에는 반드시 어떤 값이 들어있어야 한다
-
NULL : 값이 존재하지 않는 상태
-
Primary Key는 무조건 NN
-
-
AI(Auto Increment) : 해당 컬럼에 관해서는 DBMS가 '자동으로 증가'하는 값을 넣어줌
- 테이블에서 Auto Increment, AI 이런 표시를 보게 된다면 그것이 Surrogate Key이고 MySQL에 의해 자동으로 관리되고 있는 컬럼이구나라고 생각
-
DATE : 날짜 관련 column


3. 데이터 조회로 기본 다지기
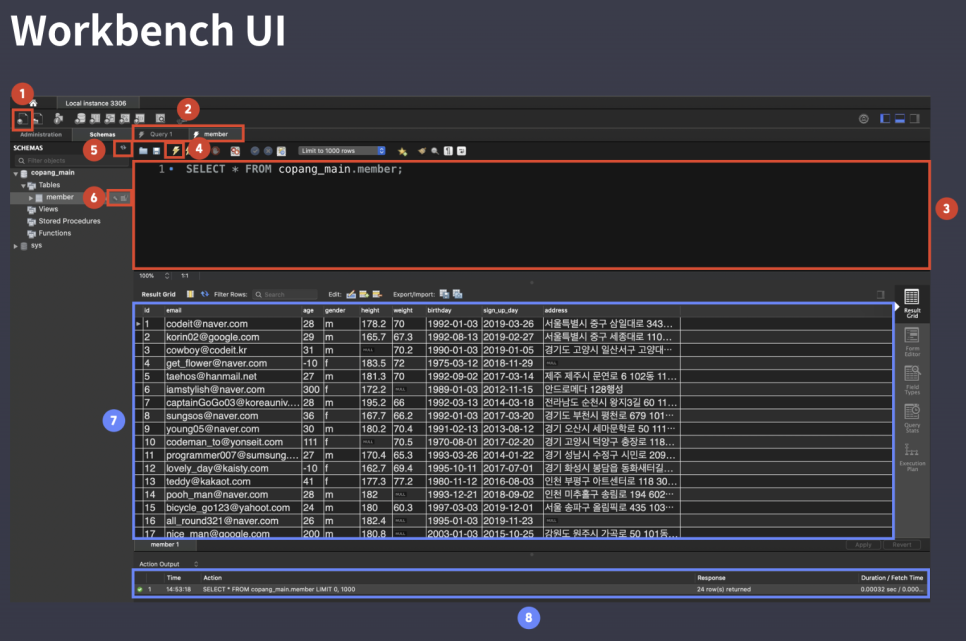
- SELECT : 테이블의 데이터를 조회할 때 사용하는 구문
- * : asterisk, 각 row의 모든 column
- FROM : ~로부터
- WHERE : 특정 조건을 만족하는 row 조회할 때
-
SQL 문 끝에는 항상 세미콜론을 써줘야합니다.
- SQL 문법 상 세미콜론이 하나의 SQL 문을 종결하는 단위
-
SQL 문 안에는 공백이나 개행 등을 자유롭게 넣을 수 있습니다.
- 길이가 긴 SQL 문을 쓸 때는 개행(줄바꿈), 탭 등을 적절하게 활용해서 가독성을 높이는 것이 좋습니다.
-
SQL 문의 대소문자 구분 문자
-
MySQL의 예약어는 대문자로 적는 것이 관례
-
가독성을 위해 ‘예약어’만큼은 꼭 대문자로 쓰는 습관을 들이도록 하세요.
-
-
조건 표현식
-
BETWEEN A AND B : A부터 B까지
-
문자열 패턴 매칭 조건 : WHERE LIKE '%'
-
LIKE : 문자열 패턴 매칭 조건을 걸기 위해 사용되는 키워드
-
% : 임의의 길의를 가진 문자열(0자도 포함)
-
-
같지 않음 : !=, <>
-
이 중에 있는~ : IN
-
한 글자를 나타내는 : _
-
-
DATE 데이터 타입 관련 함수
-
연도, 월, 일 추출하기 : YEAR(), MONTH(), DAYOFMONTH()
-
날짜 간의 차이 구하기 : DATEDIFF(날짜 a, 날짜 b)를 사용하면 '날짜 a - 날짜 b'를 해서 그 차이 일수
-
오늘 날짜를 구하기 : CURDATE()
-
날짜 더하기 빼기 : DATE_ADD(), DATE_SUB() ex.DATE_ADD(sign_up_day, INTERVAL 300 DAY)
-
DATE 타입의 값을 Unix Timestamp로 바꿔주는 함수 : UNIX_TIMESTAMP()
- Unix Timestamp 타입의 값을 DATE로 바꿔주는 함수 : FROM_UNIXTIME()
-
UNIX Timestamp는 특정 날짜의 특정 시간을, 1970년 1월 1일을 기준으로, 총 몇 초가 지났는지로 나타낸 값
-
MySQL 공식 매뉴얼
-
날짜, 시간 관련 데이터 타입 : https://dev.mysql.com/doc/refman/8.0/en/date-and-time-types.html
-
날짜, 시간 관련 함수 : https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html
-
-
-
여러 개의 조건 걸기
-
AND
-
OR
-
주의 사항
-
WHERE id = 1 OR id = 2 라고 적었어야할 부분에, WHERE id = 1 OR 2 라고 적어버리는 실수
-
MySQL에서는 0을 False, 0 이외의 숫자는 모두 True로 간주합니다. 따라서 항상 True가 되어버립니다.
-
-
AND와 OR 간의 우선순위
-
AND가 OR보다 우선순위가 더 높아서 AND가 OR보다 먼저 실행
-
‘먼저 실행되기를 원하는 조건’을 괄호로 씌워주는 게 좋습니다.
-
-
-
문자열 패턴 매칭 조건을 사용할 때 주의할 점
-
이스케이핑
-
어떤 문자가 그것에 부여된 특정한 의미, 기능으로 해석되는 게 아니라 그냥 단순한 문자 하나로 해석되도록 하는 것
-
원래 특정 의미('임의의 길이를 가진 문자열')를 나타내던 문자(%)를 그 특정 의미가 아니라, 일반적인 문자처럼 취급하는 행위
-
이미 특수한 기능(의미)을 갖고 있는 문자를, 그 특수한 기능(의미)이 아닌, 문자 그대로 해석하고 싶을 때
-
MySQL에서 이스케이핑을 하는 방법은 해당 문자 앞에 역슬래쉬를 붙여주는 것
-
-
대소문자 구분 문제
- BINARY : BINARY를 붙이는 건 단지 알파벳 비교 뿐만 아니라 대소문자 구분까지 할 수 있도록 0과 1을 보는 수준까지 문자열 비교를 하라는 뜻
-
-
데이터 정렬해서 보기
-
정렬 : row들을 특정 컬럼을 기준으로 순서대로 출력
-
ORDER BY
- 이름을 먼저 쓴 컬럼을 우선으로 해서 정렬이 차례대로 수행된다
-
ASC(ascending) or 생략 : 오름차순
-
DESC(descending) : 내림차순
-
문자열 데이터 정렬
-
숫자값이 담긴 컬럼을 정렬 기준으로 할 때는 그 컬럼의 데이터 타입이 숫자형인지, 문자열형인지를 잘 살펴봐야 함
-
INT 타입의 값은 숫자의 대소(크고 작음)를 기준으로 정렬이 수행
-
TEXT 타입의 값은 숫자의 대소가 아니라 한 문자, 한 문자씩 그 문자 순서를 비교해서 정렬이 수행
-
CAST() : 어떤 변수의 데이터 타입을 바꿀 때 사용
-
CAST(data AS signed) : data 컬럼에 존재하는 값들의 데이터 타입을 일시적으로 signed라는 데이터 타입으로 변환하라는 뜻
-
signed는 양수와 음수를 포함한 모든 정수를 나타낼 수 있는 데이터 타입
-
문자열 타입으로 저장된 숫자값에 소수점이 포함되어 있다면 signed 대신 decimal(소수점이 있는 수를 나타내는 타입)을 적어주고 사용
-
-
-
데이터 일부만 추려보기
-
LIMIT
-
LIMIT n : n개만
-
LIMIT m, n : m번째 row 부터 n개만(row는 0부터 세니까 주의!)
-
-
4. 데이터 분석 단계로 나아가기
-
집계함수(Aggregate Function)
-
어떤 컬럼의 값들을 대상으로 원하는 특징값을 구해주는 함수
-
특정 컬럼의 여러 row의 값들을 동시에 고려해서 실행되는 함수
-
OUNT() : 개수, 조회되는 row의 개수를 구해주는 표현식
-
MAX() : 최댓값
-
MIN() : 최솟값
-
AVG() : 평균값 - NULL 제외
-
SUM() : 모든 값의 합
-
STD() : 모든 값의 표준편차
-
-
산술함수(Mathematical Function)
-
특정 컬럼의 각 row의 값마다 실행되는 함수
-
ABS() 함수 - 절대값을 구하는 함수
-
SQRT() 함수 - 제곱근을 구하는 함수
-
CEIL() 함수 - 올림 함수
-
FLOOR() 함수 - 내림 함수
-
ROUND() 함수 - 반올림 함수
-
-
NULL을 다루는 방법
-
COALESCE
-
IS NULL 과 = NULL은 다르다.
- NULL은 어떤 값이 아니기 때문에 애초에 등호(=)를 사용해서 어떤 값과 비교할 수 있는 대상이 아닙니다. 그래서 = NULL은 절대 TRUE일 수가 없죠.
-
NULL에는 어떤 연산을 해도 결국 NULL이다.
- NULL에는 뭘 더하든, 빼든, 곱하든, 나누든지 간에 항상 NULL입니다. NULL이라는 것 자체가 값이 없음을 나타내는데 그것에 어떤 처리를 해봤자 결국 또 NULL일 수밖에 없는 거죠.
-
-
컬럼끼리 계산하기
-
+, -, *, /, %
-
NULL이 포함된 계산식의 결과는 항상 NULL
-
-
컬럼에 alias(별명, 별칭) 붙이기
-
AS
-참고
SELECT name,
price,
price/cost,
(CASE
WHEN price/cost >= 1 AND price/cost < 1.5 THEN 'C. 저효율 메뉴'
WHEN price/cost >= 1.5 AND price/cost < 1.7 THEN 'B. 중효율 메뉴'
WHEN price/cost >= 1.7 THEN 'A. 고효율 메뉴'
END
) AS efficiency
FROM pizza_price_cost
ORDER BY efficiency DESC, price ASC
LIMIT 6;
-
CONCAT : 여러 컬럼의 값을 연결하여 하나의 컬럼으로 표현 가능
-
DISTINCT : 고유값만 보기, 특정 칼럼에 어떤 값들이 존재하는지 확인 가능
-
문자열 관련 함수들
-
SUBSTRING() : 문자열의 일부를 추출하는 함수
-
LENGTH() : 문자열의 길이 구해주는 함수
-
UPPER() : 문자열을 모두 대문자로 바꿔서 보여주는 함수
-
LOWER() : 문자열을 모두 소문자로 바꿔서 보여주는 함수
-
LPAD() : 문자열의 왼쪽을 특정 문자열로 채워주는 함수
-
RPAD() : 문자열의 오른쪽을 특정 문자열로 채워주는 함수
-
RPAD(age, 10, ’0’)는 age 컬럼의 값을, 오른쪽에 문자 0을 붙여서 총 10자리로 만드는 함수
-
보통 어떤 숫자의 자릿수를 맞출 때 자주 사용하는 함수
-
-
문자열에 존재하는 공백 제거 함수
-
TRIM() : 왼쪽, 오른쪽 양쪽 다 공백 삭제
-
LTRIM() : 왼쪽 공백 삭제
-
RTRIM() : 오른쪽 공백 삭제
-
-
-
그루핑해서 보기
-
GROUP BY
-
HAVING : ~을 가지고 있는, 여러 그룹 중에 보고 싶은 그룹만
-
GROUP BY를 사용할 때는, SELECT 절에
-
GROUP BY 뒤에서 사용한 컬럼들 또는
-
COUNT(), MAX() 등과 같은 집계 함수만
-
GROUP BY 뒤에 쓰지 않은 컬럼 이름을 SELECT 뒤에 쓸 수는 없다.
-
GROUP BY 뒤에 쓰지 않은, 그러니까 그루핑 기준으로 사용하지 않은 컬럼명을 SELECT 절 뒤에 써서 조회하려고 하면,각 그룹의 row들 중에서 해당 컬럼의 값을 어느 row에서 가져와야할지 결정할 수가 없다.
-
GROUP BY 절 뒤에 쓴 컬럼 이름들만, SELECT 절 뒤에도 쓸 수 있다.
-
대신 SELECT 절 뒤에서 집계 함수에 그 외의 컬럼 이름을 인자로 넣는 것은 허용된다.
-
-
ROLLUP
- 세부 그룹들을 좀더 큰 단위의 그룹으로 중간중간에 합쳐준다
-
-
SELECT문의 작성 순서
-
SELECT
-
FROM
-
WHERE
-
GROUP BY
-
HAVING
-
ORDER BY
-
LIMIT
-
-
SELECT문의 실행 순서
-
FROM
-
WHERE
-
GROUP BY
-
HAVING
-
SELECT
-
ORDER BY
-
LIMIT
-
FROM: 어느 테이블을 대상으로 할 것인지를 먼저 결정합니다.
-
WHERE: 해당 테이블에서 특정 조건(들)을 만족하는 row들만 선별합니다.
-
GROUP BY: row들을 그루핑 기준대로 그루핑합니다. 하나의 그룹은 하나의 row로 표현됩니다.
-
HAVING: 그루핑 작업 후 생성된 여러 그룹들 중에서, 특정 조건(들)을 만족하는 그룹들만 선별합니다.
-
SELECT: 모든 컬럼 또는 특정 컬럼들을 조회합니다. SELECT 절에서 컬럼 이름에 alias를 붙인 게 있다면, 이 이후 단계(ORDER BY, LIMIT)부터는 해당 alias를 사용할 수 있습니다.
-
ORDER BY: 각 row를 특정 기준에 따라서 정렬합니다.
-
LIMIT: 이전 단계까지 조회된 row들 중 일부 row들만을 추립니다.
-
-
WITH ROLLUP
: 부분총계를 추가해주는 것, 세부 그룹들을 더 큰 단위의 그룹으로 중간중간에 합쳐준다#region을 기준으로 부분 총계를 제공 SELECT SUBSTRING(address, 1, 2) as region, gender, COUNT(*) FROM member GROUP BY SUBSTRING(address, 1, 2), gender WITH ROLLUP HAVING region IS NOT NULL ORDER BY region ASC, gender DESC; ```
-
GROUP BY 뒤 기준들의 순서에 따라 WITH ROLLUP의 결과도 달라진다.
-
이 NULL이 1) 실제로 NULL을 나타내기 위해서 쓰인 건지, 2) 부분 총계를 나타내기 위해 쓰인 건지, 구분하고 싶다면 GROUPING 함수를 사용
5. 테이블 조인을 통한 깊이있는 데이터 분석
-
Foreign Key(외래키)
-
다른 테이블의 특정 row를 식별할 수 있게 해주는 컬럼
-
참조를 하는 테이블 ‘자식 테이블'
-
참조를 당하는 테이블 ‘부모 테이블'
-
Foreign Key는 다른 테이블의 특정 row를 식별할 수 있어야 하기 때문에 주로 다른 테이블의 Primary Key를 참조할 때가 많다.
-
JOIN
-
LEFT OUTER JOIN : 왼쪽 테이블 기준으로 JOIN
-
RIGHT OUTER JOIN : 오른쪽 테이블 기준으로 JOIN
-
INNER JOIN : 두 테이블 간의 교집합, 기준이 되는 테이블이 따로 없음
-
조인할 때 테이블에 alias 붙이기
-
컬럼의 alias는 각 컬럼 이름이 실제로 우리에게 그 alias로 변환되어서 보여지게 하기 위한 용도
-
테이블의 alias는 조회 결과에서 보기 위한 게 아니라 SQL 문의 전체 길이를 줄여서 가독성을 높이기 위해 사용
-
-
예시문제
-
조인을 통해 생성된 결과 중에서 pizza_price_cost 테이블의 name 컬럼과, sales 테이블의 sales_volume 컬럼만 조회하세요.
-
이때 sales_volume 컬럼에는 '판매량'이라는 alias를 붙이고, sales_volume이 NULL인 row의 경우에는 ‘판매량 정보 없음’으로 표시하세요.
-
SELECT p.name,
COALESCE(s.sales_volume, '판매량 정보 없음') AS '판매량'
FROM pizza_price_cost AS p LEFT OUTER JOIN sales AS s ON p.id = s.menu_id;-
해설
-
일단 pizza_price_cost 테이블을 기준으로 sales 테이블을 LEFT OUTER JOIN하세요. 이때 기준 테이블의 id 컬럼과 sales 테이블의 menu_id 컬럼을 조인 기준으로 하면 되겠죠?
-
그 다음 COLEASE() 함수로 sales_volume 컬럼이 NULL이면 '판매량 정보 없음'이라고 표시하고 이 컬럼에는 AS로 '판매량'이라는 alias를 붙이세요.
-
-
테이블을 합치는 연산
-
결합 연산 : 테이블을 가로 방향으로 합치는 것에 관한 연산 - 조인
-
집합 연산 : 테이블을 세로 방향으로 합치는 것에 관한 연산
-
A ∩ B (INTERSECT 연산자 사용)
-
A - B (MINUS 연산자 또는 EXCEPT 연산자 사용)
-
B - A (MINUS 연산자 또는 EXCEPT 연산자 사용)
-
A U B (UNION 연산자 사용)
-
-
-
ON : 조인 조건 설정할 때 사용
-
USING : 조인 조건으로 쓰인 두 컬럼의 이름이 같으면 ON 대신 USING을 쓰는 경우도 있다.
- ex. ON old.id = new.id 와 USING(id)의 의미는 같다.
-
UNION
-
서로 다른 종류의 테이블도, 조회하는 컬럼을 일치시키면 집합 연산이 가능
-
총 컬럼의 수와, 각 컬럼의 데이터 타입만 일치하면 UNION 연산이 가능
-
UNION은 두 테이블이 공통적으로 갖고 있는 원소들, 두 테이블의 교집합에 해당하는 영역의 row들은 중복을 제거하고, 그냥 딱 하나의 row만 보여준다.
-
UNION ALL은 UNION처럼 두 테이블의 합집합을 보여준다는 점은 같다. 하지만 겹치는 것을 중복 제거하지 않고, 겹치는 것들을 그대로 둘다 보여준다는 차이
-
UNION : 중복을 제거하고 깔끔하게 보는 것이 중요한 경우
-
UNION ALL : 중복을 제거하게 되면 정보 누락이 발생할 수 있는 경우
-
-
NATURAL JOIN
-
두 테이블에서 같은 이름의 컬럼을 찾아서 자동으로 그것들을 조인 조건을 설정하고, INNER JOIN을 해주는 조인
-
우리말로는 자연 조인
-
조인 조건을 자동으로 설정해주기 때문에 ON 절을 쓸 필요가 없다.
-
두 테이블에 같은 이름의 컬럼이 있더라도 NATURAL JOIN을 쓰기보다는 조인을 쓰고 ON 절에 조인 조건을 명시해주는 것이 좋다.
-
-
CROSS JOIN
-
한 테이블의 하나의 row에 다른 테이블의 모든 row들을 매칭하고, 그 다음 row에서도 또, 다른 테이블의 모든 row들을 매칭하는 것을 반복함으로써 두 테이블의 row들의 모든 조합을 보여주는 조인
-
두 집합의 모든 원소들의 조합을 나타내는 것을 수학의 집합 이론에서 카르테시안 곱(Cartesian Product), CROSS JOIN은 두 테이블의 Cartesian Product를 구하는 조인
-
-
SELF JOIN
-
테이블이 자기 자신과 조인을 하는 경우
-
조인 대상이 같은 테이블을 마치 별도의 테이블인 것처럼 간주하고 진행된다는 점에서 특색이 있는 조인
-
-
FULL OUTER JOIN
-
FULL OUTER JOIN은 두 테이블의 LEFT OUTER JOIN 결과와 RIGHT OUTER JOIN 결과를 합치는 조인
-
대신, 이때 두 결과에 모두 존재하는 row들(두 테이블에 공통으로 존재하던 row들)은 한번만
-
-
Non-Equi JOIN
- 동등 조건이 아닌 다른 종류의 조건을 사용해서 조인
6.서브쿼리와 뷰를 활용한 유연한 데이터 분석
-
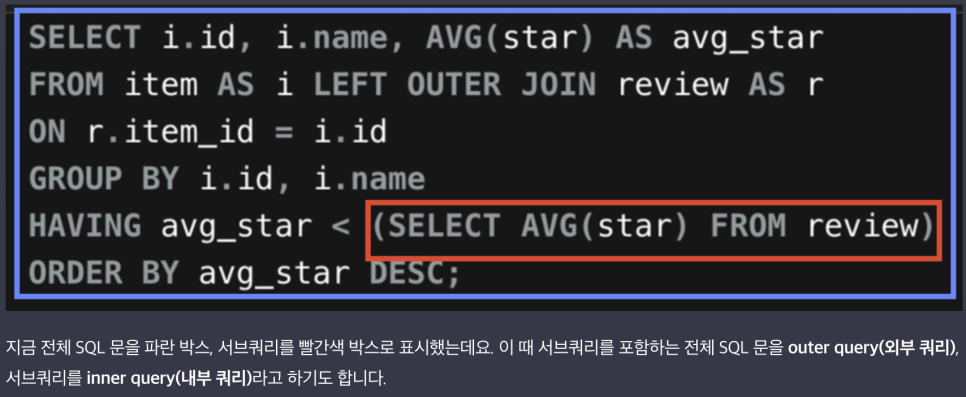
서브쿼리 : SQL 문 안에 '부품'처럼 들어가는 SELECT 문
-
IN
-
ANY : WHERE 절에서 사용될 때는, 서브쿼리의 결과에 있는 각 row의 값들 중 하나라도 조건을 만족하는 경우가 있으면 TRUE를 리턴
-
SOME : 서브쿼리의 결과에 있는 각 row의 값들 중 하나라도 조건을 만족하면 TRUE를 리턴
-
ALL : 모든 경우에 대해서 해당 조건이 성립해야 TRUE를 리턴
-
-
단일값을 리턴하는 서브쿼리
-
스칼라 서브쿼리 스칼라(수학, 물린 분야에서의 단일값)
-
SELECT 절에서 하나의 컬럼처럼 WHERE 절에서 =, > 등의 조건 표현식과 비교하는 값으로 사용 가능
-
-
하나의 column에 여러 row들이 있는 형태의 결과를 리턴하는 서브쿼리
- IN, ANY(SOME), ALL 등의 키워드와 함께 사용 가능
-
하나의 테이블 형태의 결과(여러 column, 여러 row)를 리턴하는 서브쿼리
-
derived table : 서브쿼리로 일시적으로 탄생한 테이블 (Oracle에서는 inline view)
-
derived table에는 alias를 붙여줘야 한다는 규칙!
-
-
비상관 서브쿼리(Non-correlated Subquery)
-
outer query와 상관 관계가 없는 서브쿼리
-
이 서브쿼리가 그것을 둘러싼 outer query와 별개로, 독립적으로 실행
-
-
상관 서브쿼리(Correlated Subquery)
-
outer query와 상관 관계가 있는 서브쿼리
-
서브쿼리가 outer query에 적힌 테이블 이름 등과 상관 관계를 갖고 있어서 그 단독으로는 실행되지 못하는 서브쿼리
-
EXIST, NOT EXISTS
-
-
뷰 : 조인 등의 작업을 해서 만든 '결과 테이블'이 가상으로 저장된 형태
-
CREATE VIEW '뷰 이름' AS SELECT 문;
-
뷰는 테이블과 달리 데이터가 물리적으로 컴퓨터에 저장되어 있는 건 아니다.
-
뷰는, 우리가 뷰를 사용할 때, DBMS가 그 뷰를 생성하는 SQL 문을 재실행하는 방식으로 가상의 테이블을 만들어주는 것
-
테이블처럼 컴퓨터에서 데이터 크기만큼의 물리적인 용량을 차지하고 있는 것은 아니라는 뜻
-
뷰는 사용자에게 높은 편의성을 제공해줍니다.
-
각 직무별 데이터 수요에 알맞은, 다양한 구조의 데이터 분석 기반을 구축해둘 수 있습니다.
- 뷰를 사용하면 각자에게 적합한 구조로 데이터들을 준비해둘 수 있기 때문에 회사 입장에서도 기존의 테이블 구조를 건드리지 않고, 풍부한 데이터 분석 기반을 준비할 수 있게 됩니다.
-
뷰는 데이터 보안을 제공합니다.
-
-
DESCRIBE '테이블 이름;
- 굳이 테이블 전체 데이터를 조회하지 않고 테이블의 컬럼 구조만 간단하게 파악 가능
-
데이터베이스의 현황을 파악하려면 일단 기본적으로 회사 서버 조사해야함
-
어떤 데이터베이스들이 있는지 : SHOW DATABASES;
-
각 데이터베이스 안에 어떤 테이블들이 있는지** : SHOW FULL TABLES IN 테이블 이름;
-
각 테이블의 컬럼 구조는 어떻게 되는지** : DESCRIBE 테이블 이름;
-
테이블들 간의 Foreign Key 관계는 어떤지**
-
두 테이블의 각 컬럼 간에 Foreign Key 관계가 성립한다고 해도 관리자가 그것을 Foreign Key로 설정하지 않는 경우도 많다.
-
Foreign Key 관계가 논리적으로 성립해도 실제로 DBMS 상에서 설정되어 있지 않은 경우도 많다는 걸 기억
-
-
SQL로 하는 데이터 분석|작성자 Index
