*2021. 7. 11. 23:43 에 작성한 글
드디어 시각화다!
시각화와 그래프
시각화의 두 가지 목적
-
분석에 도움이 된다.
-
리포팅에 도움이 된다.
*주피터 노트북에서 그래프를 그리기 전에 해야하는 세팅!
%matplotlib inline
선그래프
: 변화를 보여주는 데 효과적
.plot()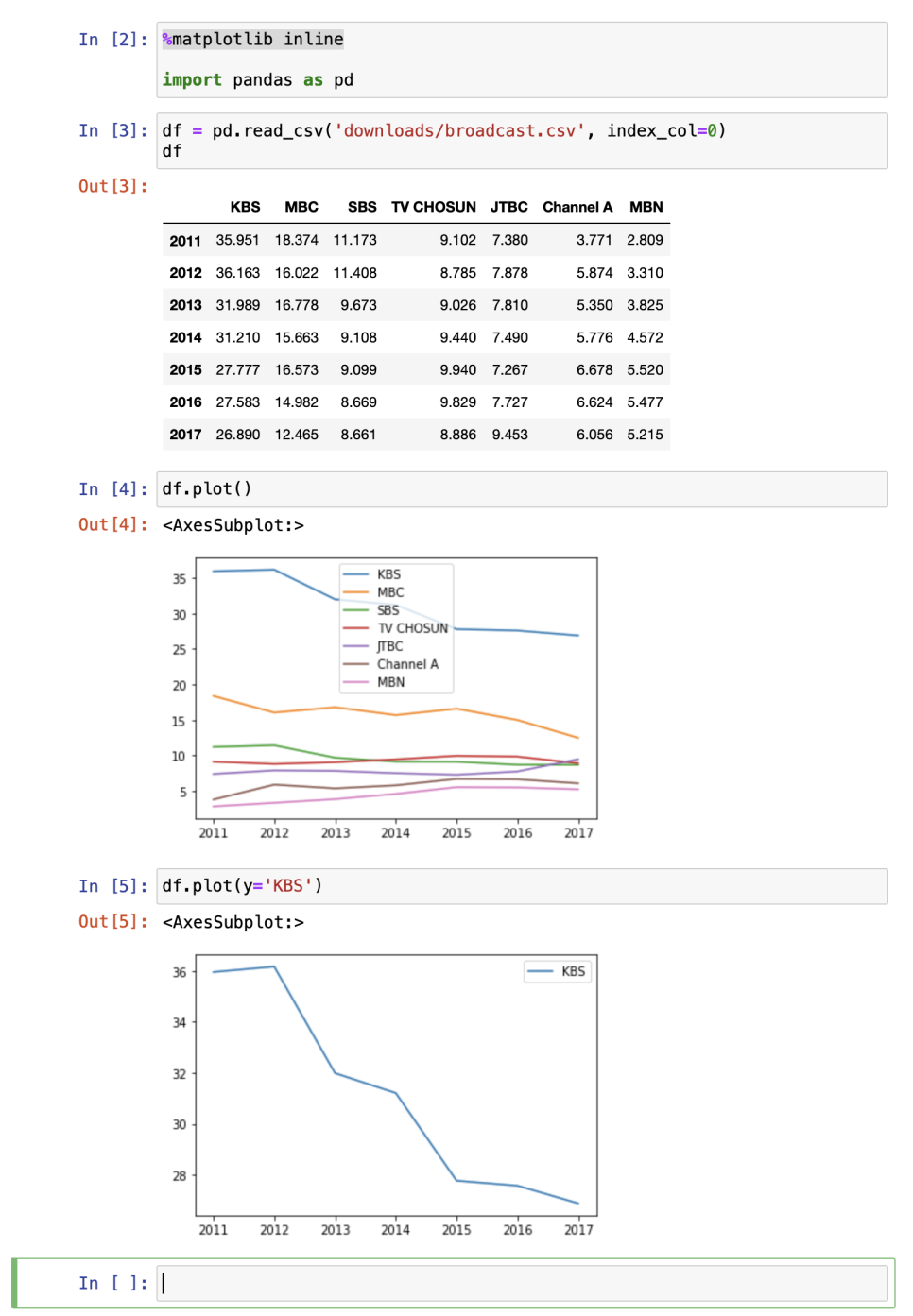
대박이다...흑흑.. 너무 재미있어...ㅠㅠ
막대그래프
: 카테고리 비교를 위해 사용
.plot(kind='bar')
.plot(kind='barh') - 가로형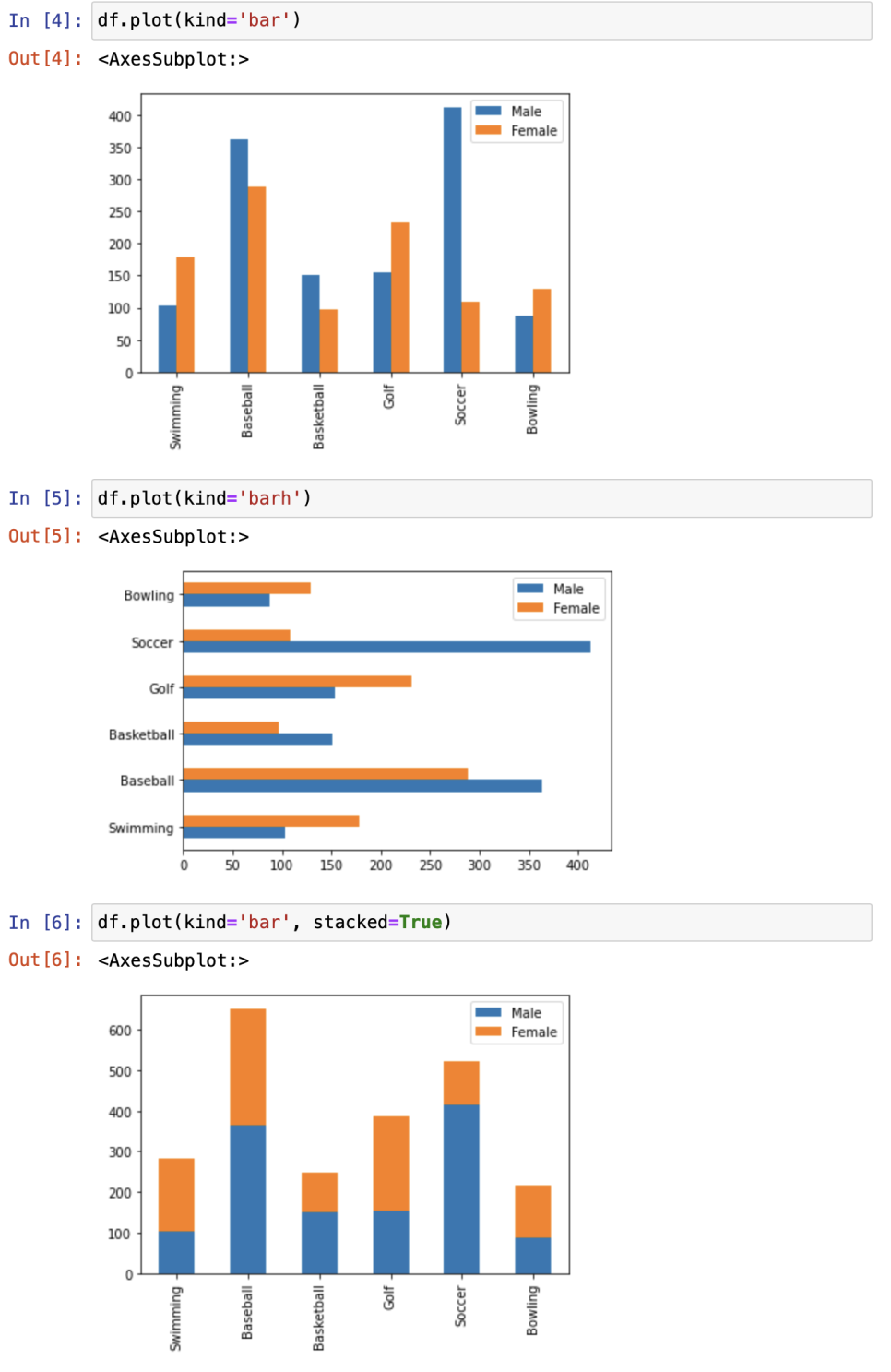
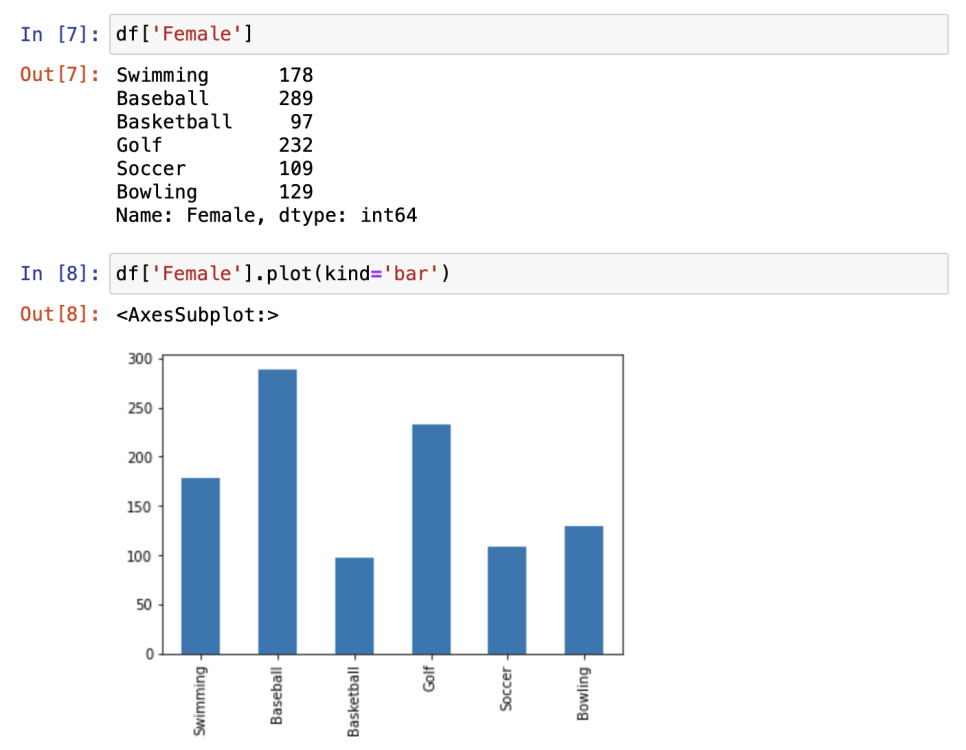
*특정 정보만 가져와서 시각화 하고 싶을 때
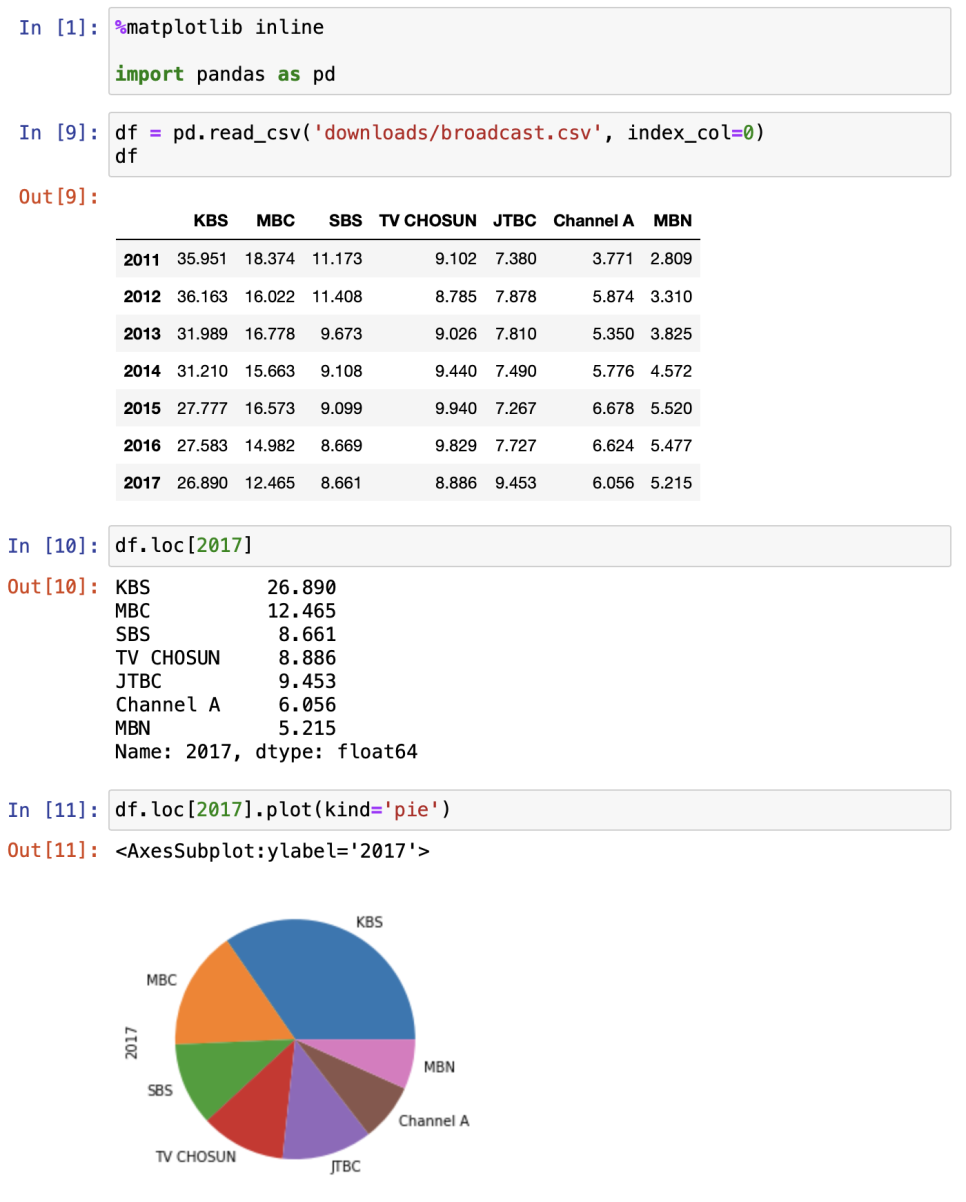
파이그래프
: 절대적인 수치보다는 비율을 나타내는 그래프
히스토그램
: 대략적인 값들의 분포를 한 눈에
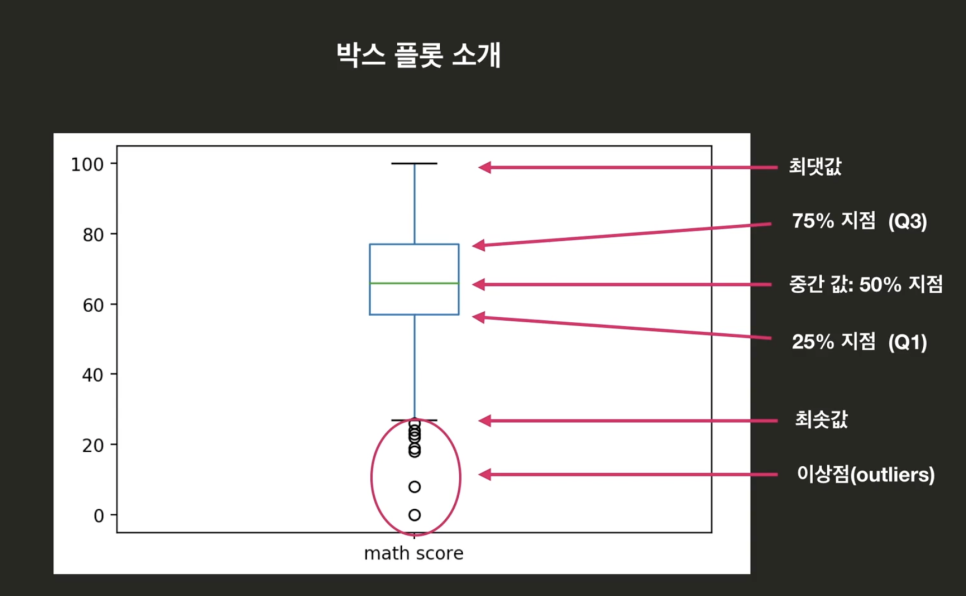
박스플롯
: 어떤 데이터셋에 대한 통계 정보를 시각화
최댓값, 75%지점(Q1), 중간값(50%지점, Q2), 25%지점(Q1), 최솟값
이상점(outliers)

산점도(scatter plot)
: 상관관계를 보여주기 위해 적합
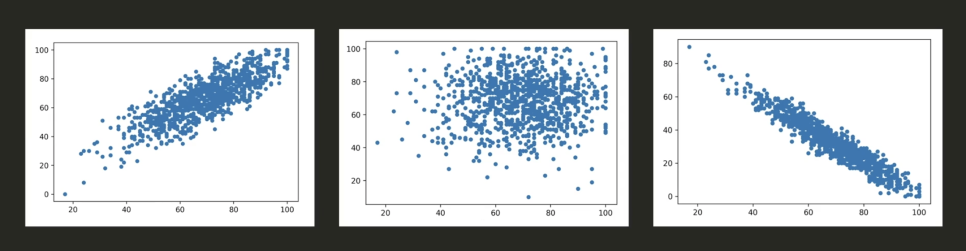
1) 아주 강한 연관성 2) 약한 연관성 3) 아주 강한 연관성이지만 그 특성이 반대
Seaborn 시각화
Seaborn Library
: Statistical Data Visualization(통계를 기반으로 한 데이터 시각화)
PDF(Probability Density Function)
: 확률 밀도 함수
1) 확률 밀도 함수는 데이터셋의 분포를 나타낸다.
2) 특정 구간의 확률은 그래프 아래 그 구간의 면적과 동일하다.
3) 그래프 아래의 모든 면적을 더하면 1이 된다.
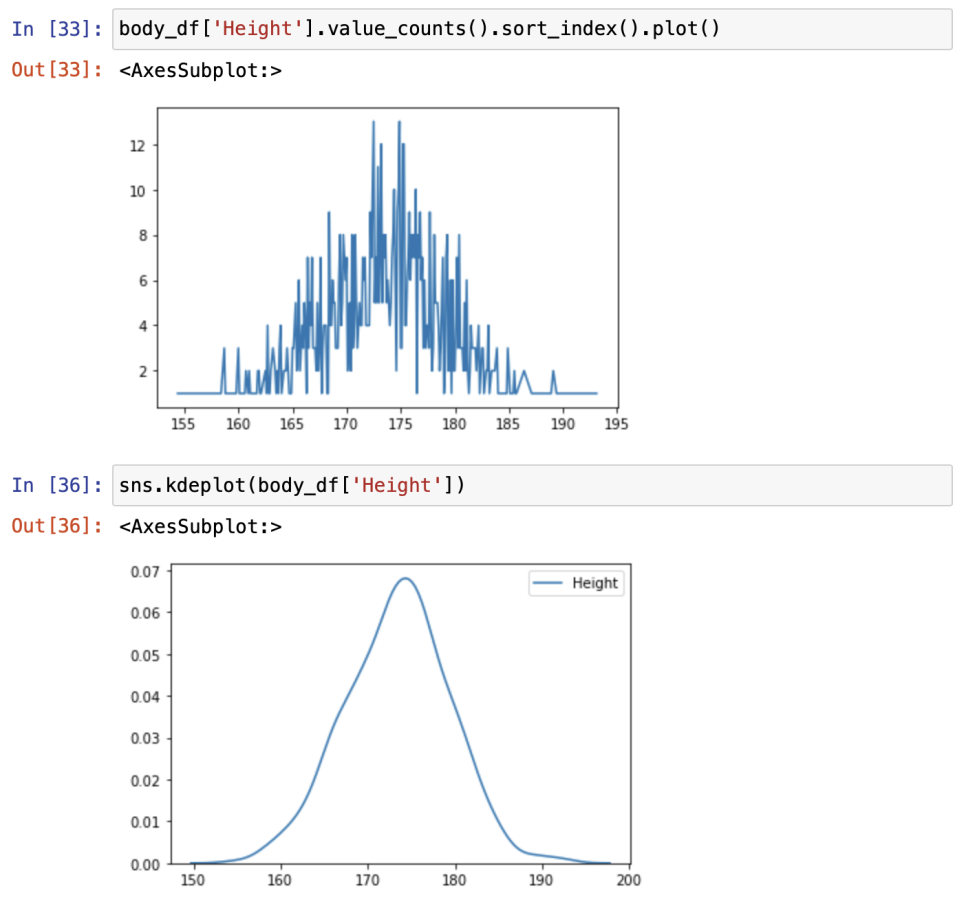
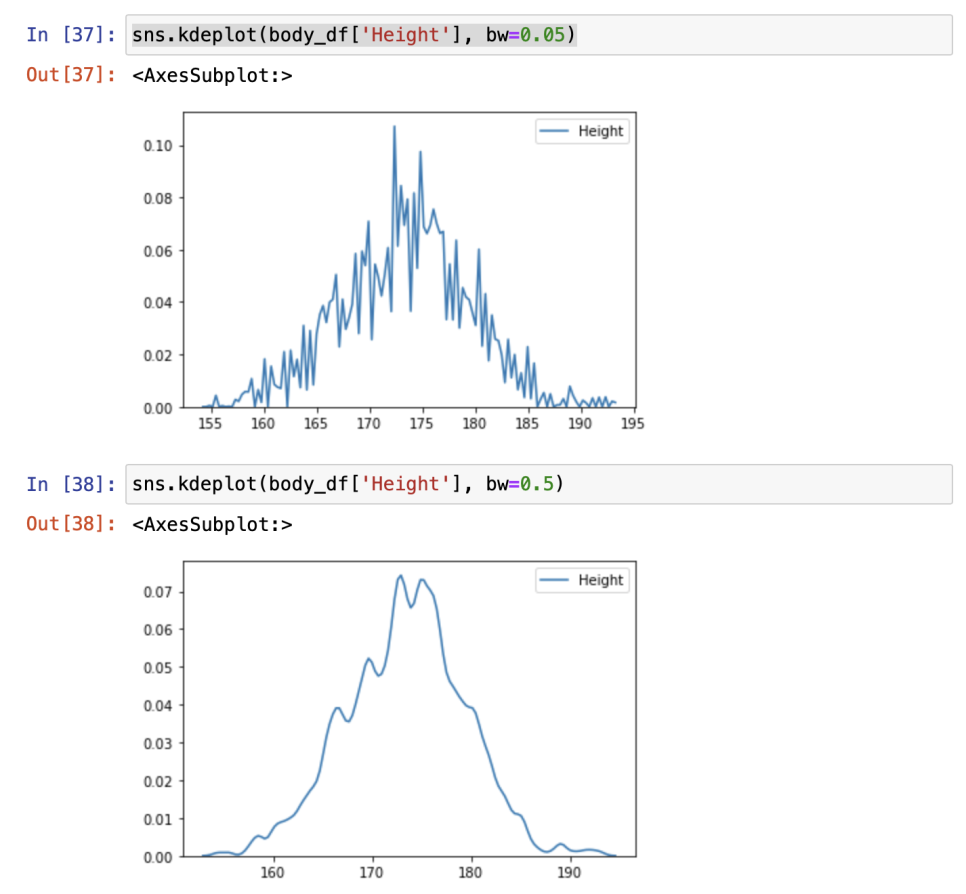
KDE(Kernel Density Estimation)
: 데이터를 기반으로 추측해서 그림에 가까운 데이터 셋 가능
.lmplot -> 회귀선
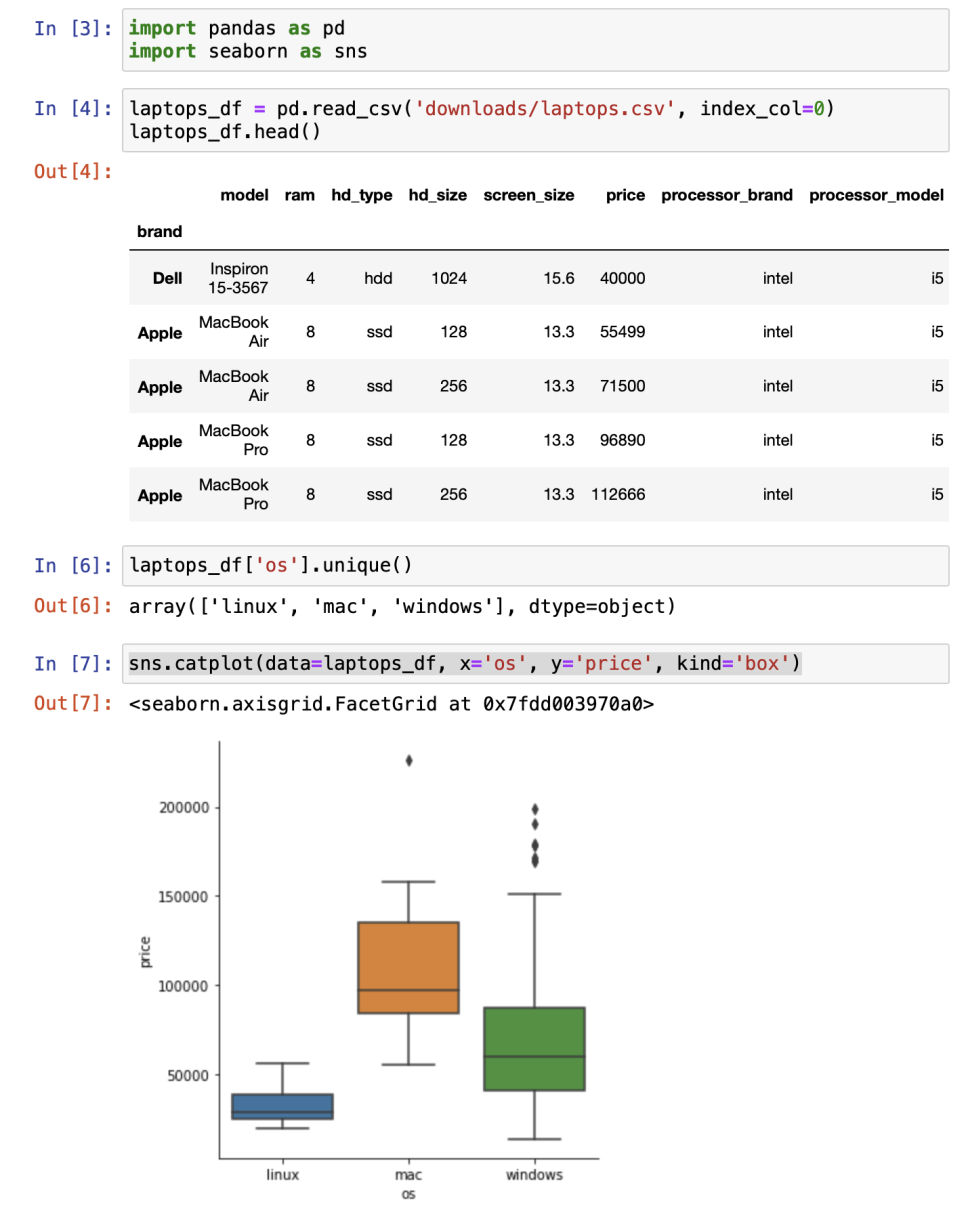
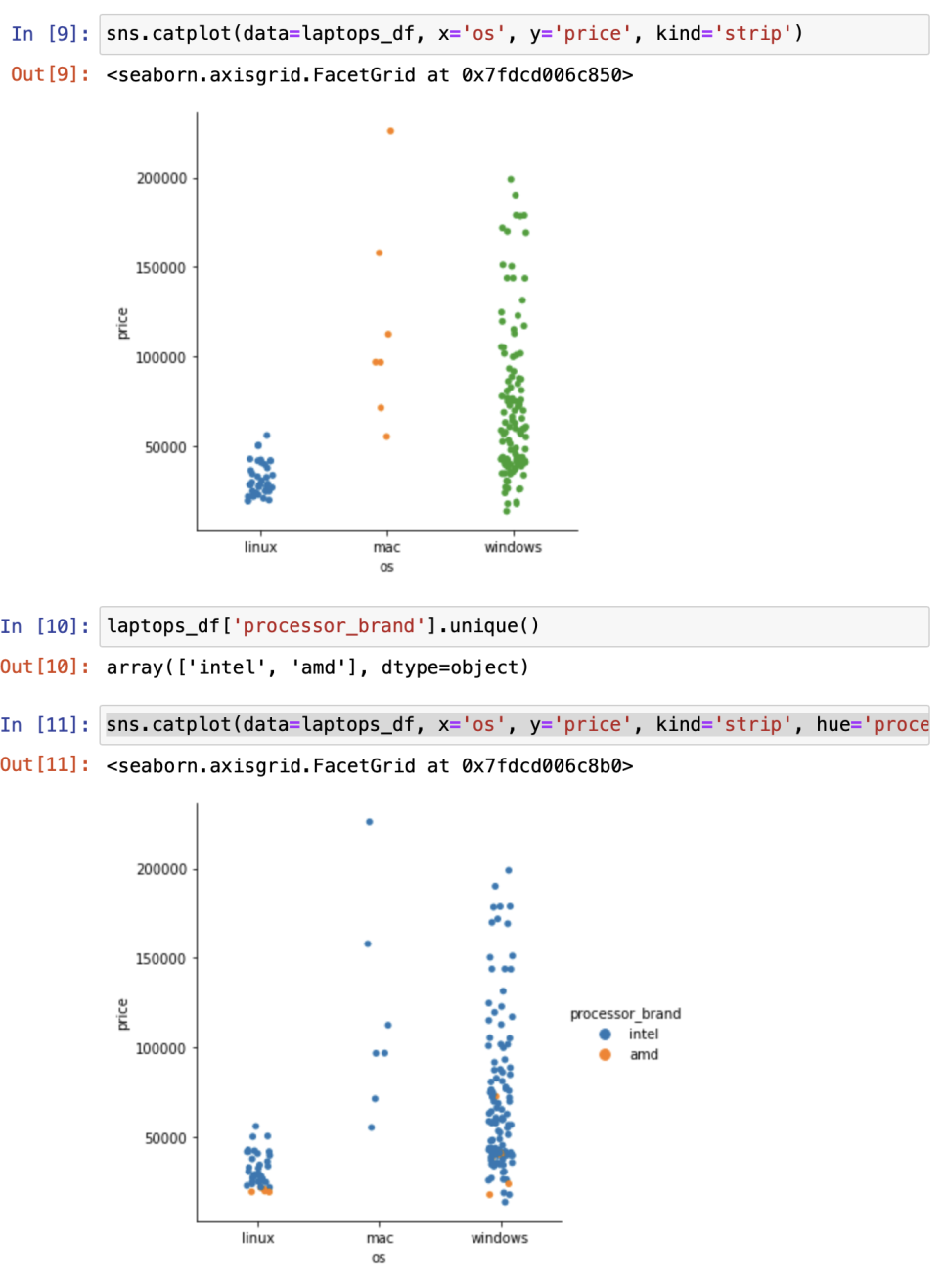
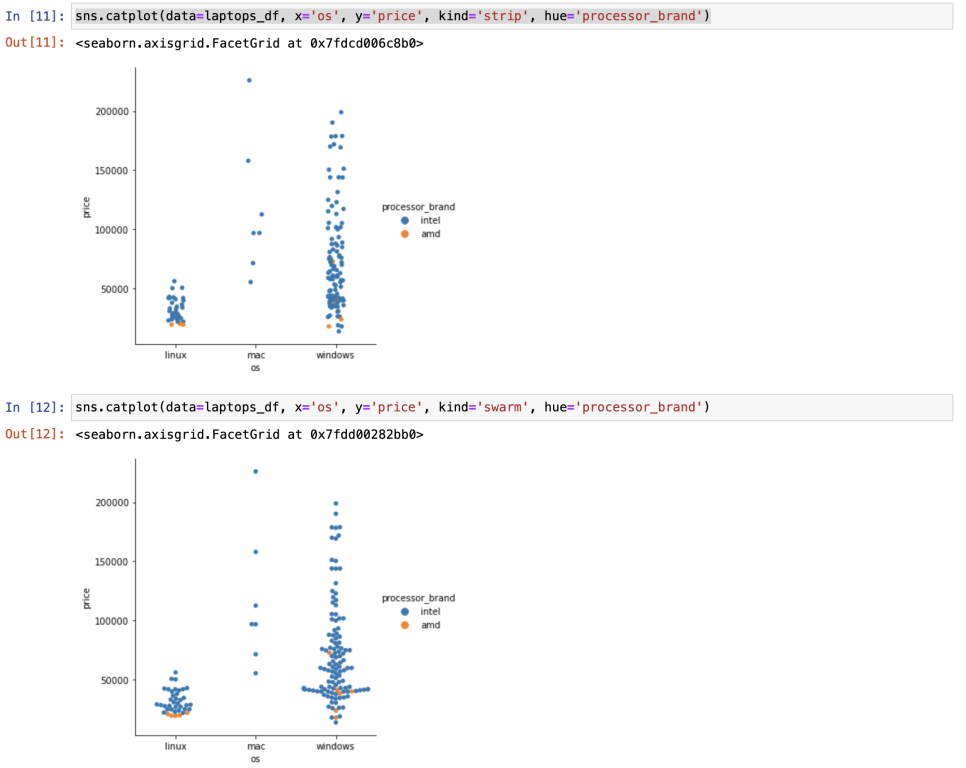
카테고리별 시각화
통계 기본 상식
평균(Mean)
: 데이터들의 합/데이터 개수
중간값(Median)
: 데이터셋에서 딱 중간에 있는 값
상관계수(Correlation Coefficient)
: 두 값의 연관성을 수치적으로 표현
피어슨 상관계수(Pearson Correation Coefficient)
: ~1부터 1까지의 값 가질 수 있음
0 - 연관성 X
|1|에 가까워 질수록 연관성 높음
|1|이면 확실한 연관성
상관계수 시각화
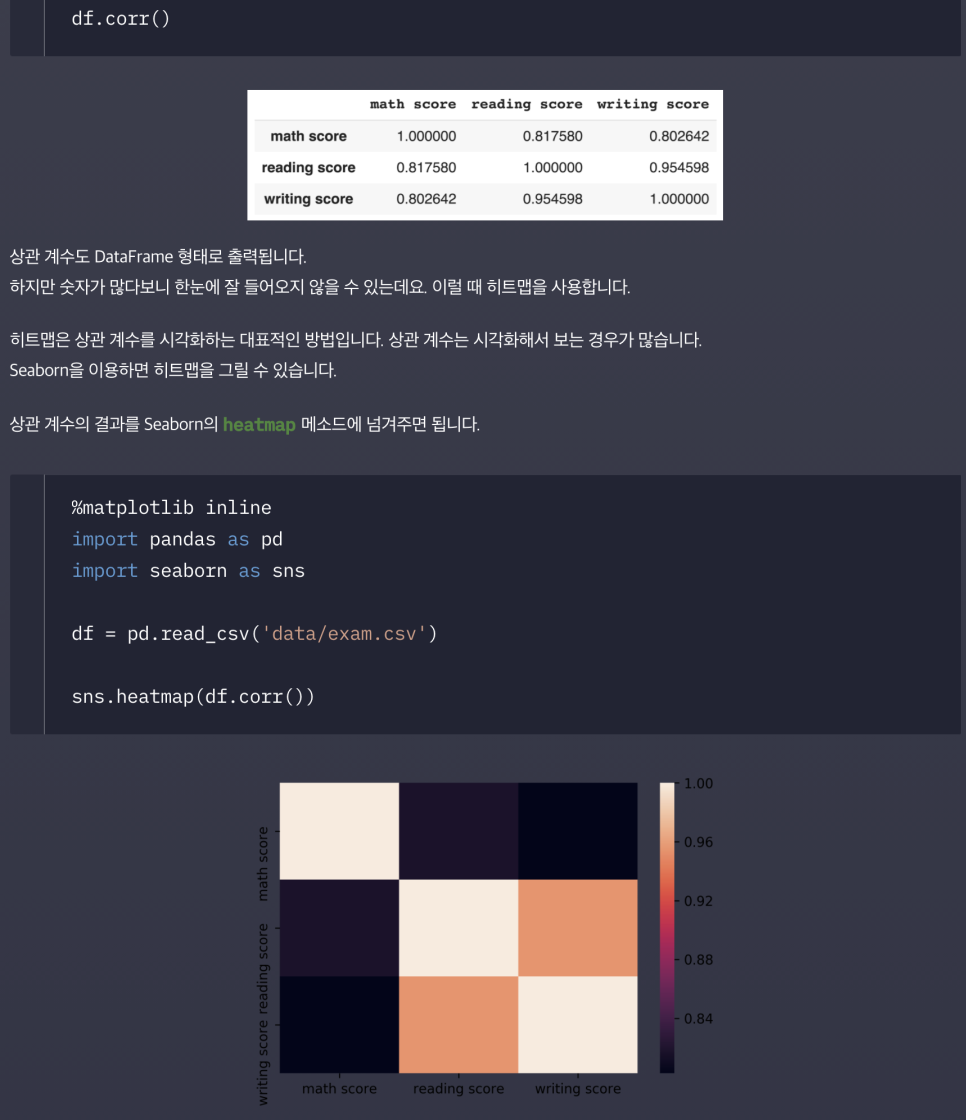
여기에 annot=True 추가하면 색상과 함께 숫자도 표시
Exploratory Data Analysis
EDA(Exploratory Data Analysis)란?
: 탐색적 데이터 분석, 주어진 데이터셋을 다양한 관점에서 살펴보고 탐색하면서 인사이트를 찾는 것!
ex) 각 row, columns은 무엇을 의미하는지?, 각 column은 어떤 분포를 보이는지, 두 column은 어떤 연관성이 있는지
EDA에는 공식이 없다! 뭐가 됐든 다양한 방법으로 데이터 분석을 해보자.
상관 관계 분석(Correlation Analysis)
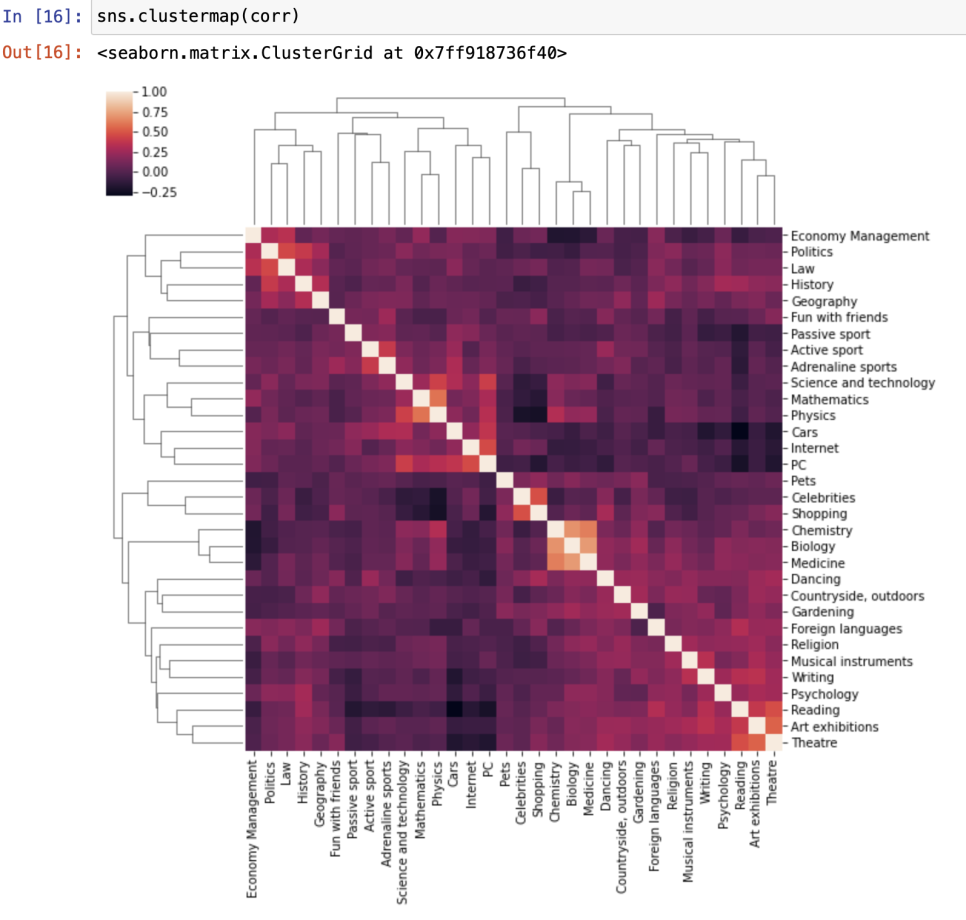
클러스터 분석(Cluster Analysis)
: 데이터를 무리로 나누는 것
새로운 인사이트 발견하기
값 더해서 콜럼 추가한 다음에 그걸 또 시각화 가능
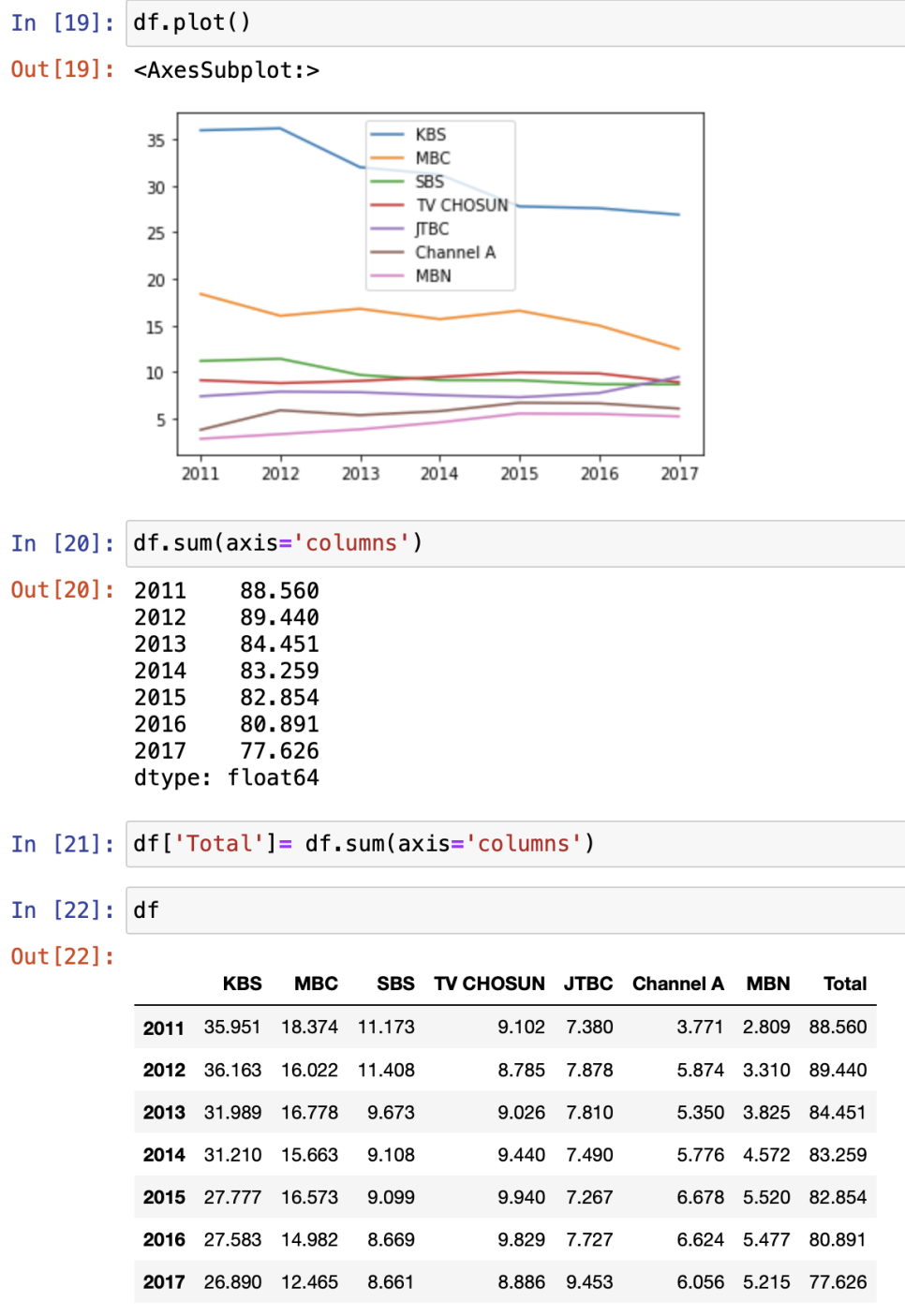
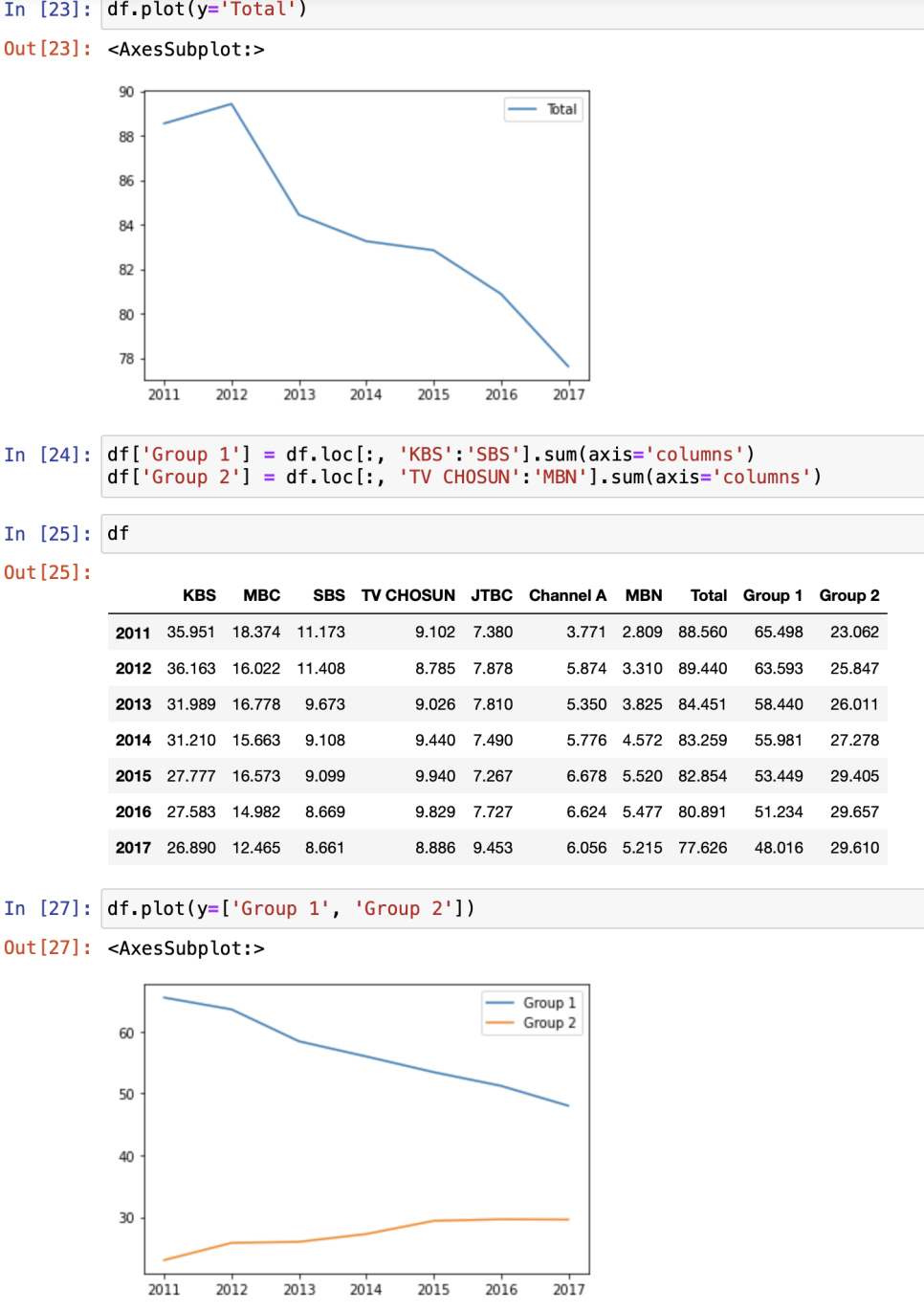
문자열 필터링
특정 문자 포함하는 열 추출해서 시각화 가능
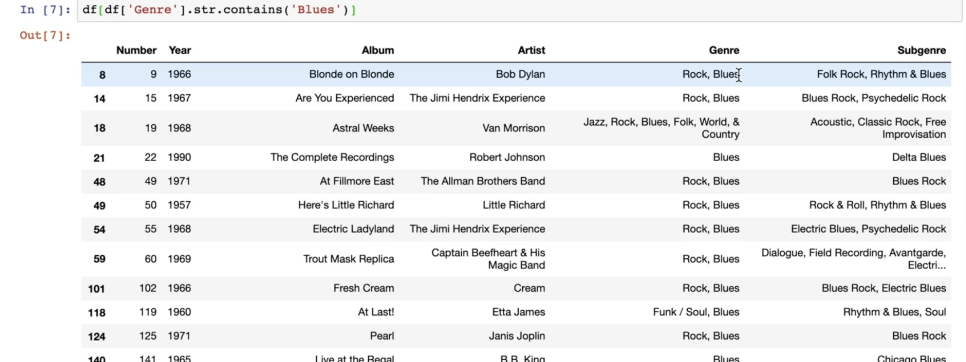
#포함
.str.contains('Blues')
#앞에 위치
.str.startswith('Blues')문자열 분리
.str.split()groupby
: .map으로 묶은 카테고리별 비교분석 용이
.groupby()데이터 합치기
: pandas merge
.merge(df1, df2, on='기준', how='방법')-
inner join
-
left outer join
-
right outer join
-
full outer join
와 역시 눈에 보이니까 더 재미있다

'데이터 사이언스 입문' 3.데이터 분석과 시각화|작성자 Index
