
*2021. 7. 13. 23:45 에 작성한 글
그냥 데이터 말고
좋은 데이터!
좋은 데이터의 기준
완결성, 유일성, 통일성, 정확성
완결성(Completeness)
: 필수적인 데이터는 모두 기록되어 있어야 함
*데이터 완결성은 어떻게 알 수 있을까?
- 결측값(채워져야 하는데 비어 있는 값) 확인 필수
결측값 = NaN(Not a Number)
- 결측값은 없는 것이 제일 좋다.
- 자주 발생한다면 원인을 파악해야 한다.
유일성(Uniqueness)
: 동일한 데이터가 불필요하게 중복되어 있으면 안 됨
통일성(Conformity)
: 데이터가 동일한 형식으로 저장돼 있어야 함
*형식(데이터 타입, 단위, 포맷 등)
정확성(Accuracy)
: 데이터가 정확해야 함
데이터 클리닝
완결성
-
결측값은 없는 것이 제일 좋다.
-
자주 발생한다면 원인을 파악해야 한다.
어쩔 수 없이 결측값이 발생한다면?
1) .isnull()로 결측값을 파악한 다음에
2) .fillna()로 값을 채우거나 특정값을 모를 경우, 평균- .mean(), .median(), 등의 값으로 채우기
유일성
- 중복되는 값들을 찾아서 제거
1) row가 중복되는 경우
.drop_duplicates()
2)column이 중복되는 경우
#로우와 콜럼의 위치를 바꾼 다음
.T
#제거
.T.drop_duplicates()
#다시 돌아갓
.T.drop_duplicates().T
정확성
이상점(Outlier) : 다른 값들과 너무 동떨어져 있는 데이터 - 확인 필수!
-
이상점이 잘못된 데이터라면?
- 고치거나 제거한다 -
이상점이 제대로 된 데이터라면?
-분석에 방해가 되면 제거하고, 의미있는 정보라면 그냥 둔다
-> 상황에 맞게 판단해야 하는 부분
기준 예시)
IQR(Interquartile Range)
박스 플롯에서 25% 지점(Q1) ~ 75% 지점(Q3)
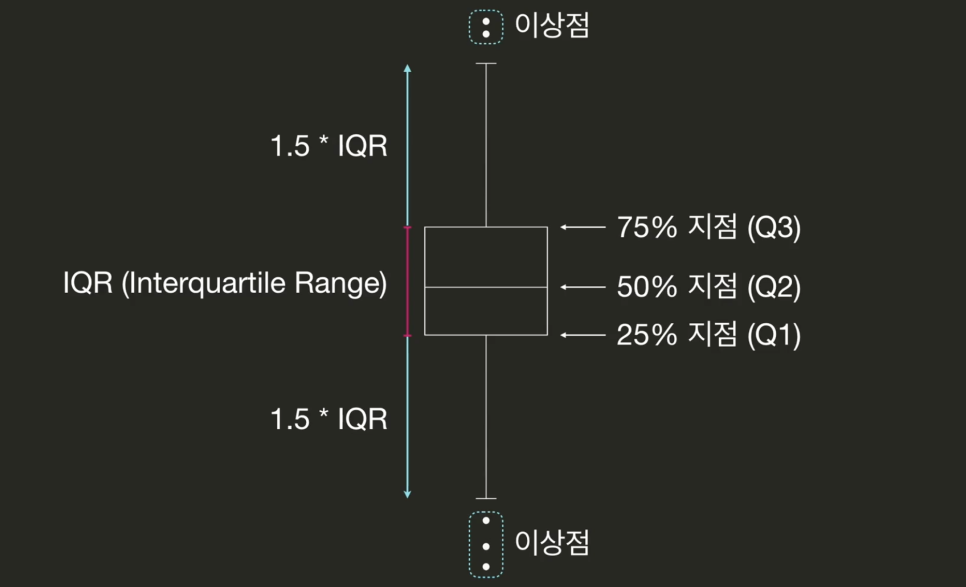
but 절대적인 기준은 無
이상점 지우는 방법
#25% 지점 파악
df[''].quantile(0.25)
#75% 지점 파악
df[''].quantile(0.75)
#각각의 값 정의
q1 = df[''].quantile(0.25)
q2 = df[''].quantile(0.75)
iqr = q3 - q1
# 이상점 찾기
(df[''] < q1 - 1.5 * iqr | (df['abv'] >q3 +1.5*iqr)
# 이상점 제거하기
df.drop()
관계적 이상점(Relational Outlier)
: 두 변수의 관계를 고려했을 때 이상한 데이터
집콕할 생각에 기분 다운...ㅠㅠ
내일부터는 아침운동도 추가해서 하루에 두 번 운동해야겠다...
에너지 올려서 공부도 빠릿빠릿!
'데이터 사이언스 입문' 4.데이터 퀄리티 높이기|작성자 Index
