머신러닝에서 모델을 학습하다 보면, 학습 데이터에는 잘 맞지만 새로운 데이터에선 성능이 떨어지는 경우를 자주 겪게 된다.
이 현상이 바로 우리가 오늘 알아볼 오버피팅(Overfitting)이다.
이 글에서는
- 오버피팅이란?
- 왜 발생하는가?
- 모델 평가 지표 (R², AIC, BIC)
- 변수 선택 기법 (Forward, Backward, Stepwise)
- 정규화 방법 (L1, L2)
- MLE vs MAP
에 대해 다루고자 한다.
1. 과적합 (Overfitting)
💡 과적합(Overfitting)이란?
학습 데이터에 너무 과하게 최적화된 결과, 일반화 성능이 떨어지는 현상
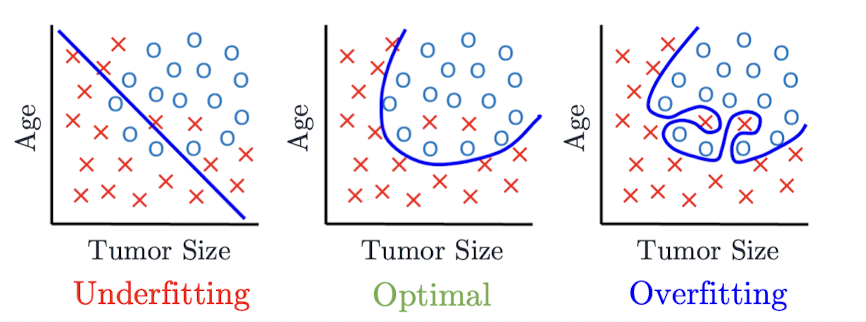
- 왼쪽: 과소적합(Underfitting) – 너무 단순한 모델
- 가운데: 적절하게 학습된 모델
- 오른쪽: 과적합(Overfitting) – 너무 복잡한 모델이 데이터에 과하게 맞춰짐
👉 즉, 모델이 데이터의 패턴을 학습한 것이 아니라, 우연한 노이즈까지 외워 새로운 데이터를 만나면 제대로 예측하지 못하는 상태
오버피팅의 다양한 원인 & 해결법
- 데이터가 부족할 때 → 데이터를 더 모은다
- 모델이 너무 복잡할 때 (파라미터가 많을 때)
- 불필요한 입력 변수가 너무 많을 때 → Variable Selection
- 가중치가 너무 클 때 → Regularization
이 중 Variable Selection과 Regularization에 대해 집중적으로 살펴보자.
2. Variable Selection
어떻게 모델의 성능을 측정할까?
cost function으로? (SSE, Cross Entropy 등)
‼️ 이 값들은 명확한 해석을 주지 않는다.
오버피팅 확인 방법: 평가 지표
(1) R² (결정 계수)
(Linear regression에 대한 해결법)
📌 배경 개념:
- SST: 실제값과 평균값의 차이 제곱합
- SSR: 선형 모델이 설명한 부분
- SSE: 실제값과 예측값의 차이 제곱합
→ SST = SSR + SSE
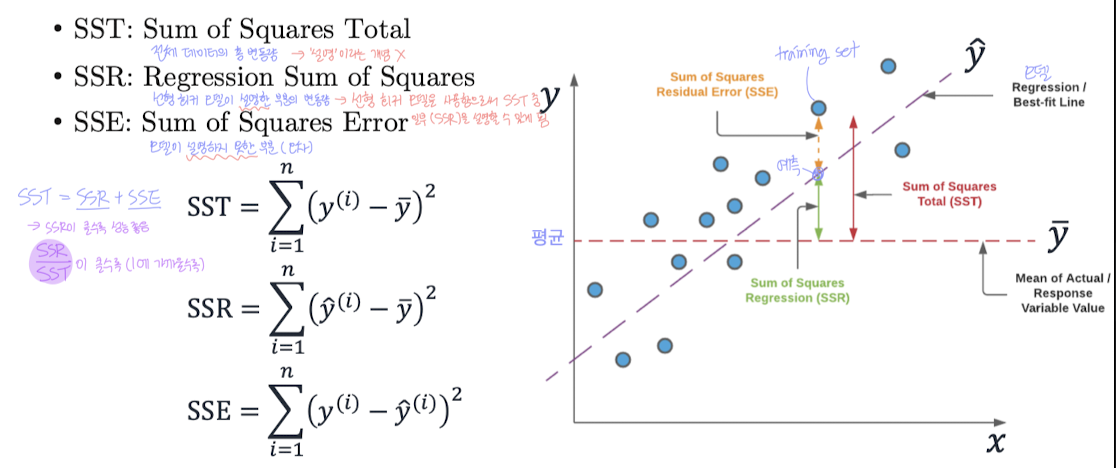
📌
- 0~1 사이 값
- 모델이 설명하는 부분이 많아질수록 SSR은 SST와 비슷해질 것
👉 클수록 모델이 데이터를 잘 설명한다는 뜻
‼️ 하지만 변수를 많이 넣을수록 R²는 무조건 올라감 → 오버피팅 발생 가능!
(2) Adjusted R² (수정된 R²)
: R²의 단점을 보완한 지표
- n: 샘플 수
- p: 변수 수
p가 증가하면
- SSE는 감소하지만,
- 가 증가함 → 패널티
👉 변수 수가 늘어나도 무작정 오르지 않고, 진짜 유의미한 변수만 반영될 때 상승
(3) Penalty methods
: 모델 복잡도와 성능의 균형을 평가하는 지표들
- Adjusted R² (수정된 R²)
- AIC (Akaike Information Criterion):
- BIC (Bayesian Information Criterion):
- L: 최대우도
Variable Selection
모든 변수를 쓰면 오히려 모델 성능이 나빠질 수 있다:
- 과적합 가능
- 다중공산성(Multicollnearity) : 입력 변수끼리 강하게 상관되어있는
- 비용(Cost) 증가 : 수집해야하는 정보가 많아지므로
👉 그래서 중요한 변수만 선택해야한다
어떻게?
간단하게 생각하면,
변수의 모든 조합에 대한 Penalty method를 계산해서 비교하면 되는거 아니야? 라고 생각할 수 있다.
‼️ 그러나 변수가 많아지면 경우의 수가 기하급수적으로 커지기 때문에 비효율적이다.
👉 중요한 변수만 선택하는 greedy 기법들에 대해 살펴보자.
(1) Forward Selection
변수 없이 시작 → 하나씩 추가해가며 성능 가장 좋아지는 변수만 선택

(2) Backward Elimination
모든 변수를 넣고 시작 → 하나씩 제거하며 성능 개선 여부 확인

(3) Stepwise
- Forward와 Backward의 절충형
- 추가와 제거를 반복하며 최적 변수 조합 탐색
- 시작점 다양하게 설정 가능
- ‼️ 시간은 더 걸린다

3. 정규화 (Regularization)
variable selection에 이어서 과적합의 두 번째 해결법이다.
💡 정규화(Regularization)란?
학습 과정에서 파라미터의 크기 자체에 제약을 걸어 모델을 단순화시키는 것
예를 들어 다음과 같은 결정 경계를 학습했다고 가정해보자:
- 모델 1:
파라미터를 2배로 하면?
- 모델 2 (모든 파라미터를 2배):
두 모델의 결정 경계(= wx + b = 0)는 동일하지만,
모델 2는 입력이 조금만 달라져도 출력 확률이 훨씬 더 급격하게 바뀐다.
즉, score의 기울기가 더 가파르다 = 더 민감하게 반응 = 더 불안정한 모델
‼️ 이러한 민감한 모델은 작은 노이즈에도 확률이 크게 요동치기 때문에
오히려 성능이 나빠질 수 있다.
👉 그래서 정규화를 통해 파라미터(가중치)가 너무 커지지 않도록 한다.
📌 수식:
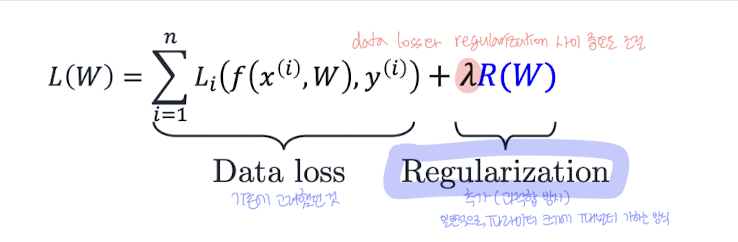
- Loss: 예측값과 실제값 사이의 오차 (예: Cross Entropy, SSE 등)
- λ: 정규화 강도 (크면 규제가 강해짐)
- R(W): 파라미터의 크기를 측정하는 정규화 항 (예: L1, L2 Norm)
이때, R(W)가 어떻게 생겼냐에 따라 L2/L1 Regularization으로 구분된다.
L2 정규화 : Ridge Regression
가장 많이 쓰이는 정규화 기법 중 하나는 L2 Regularization다.

즉, 모든 가중치들의 제곱합을 최소화하려는 방식이다.
📌 이렇게 L2 정규화를 사용하는 선형 회귀 모델을 특히
Ridge Regression이라고 부른다.
📌 Ridge 회귀 수식:
- SSE + 가중치 제곱 합
L1 정규화 : Lasso Regression

📌 이 L1 정규화를 사용하는 회귀 모델을
Lasso(Least Absolute Shrinkage and Selection Operator) 라고 한다.
Lasso vs Ridge
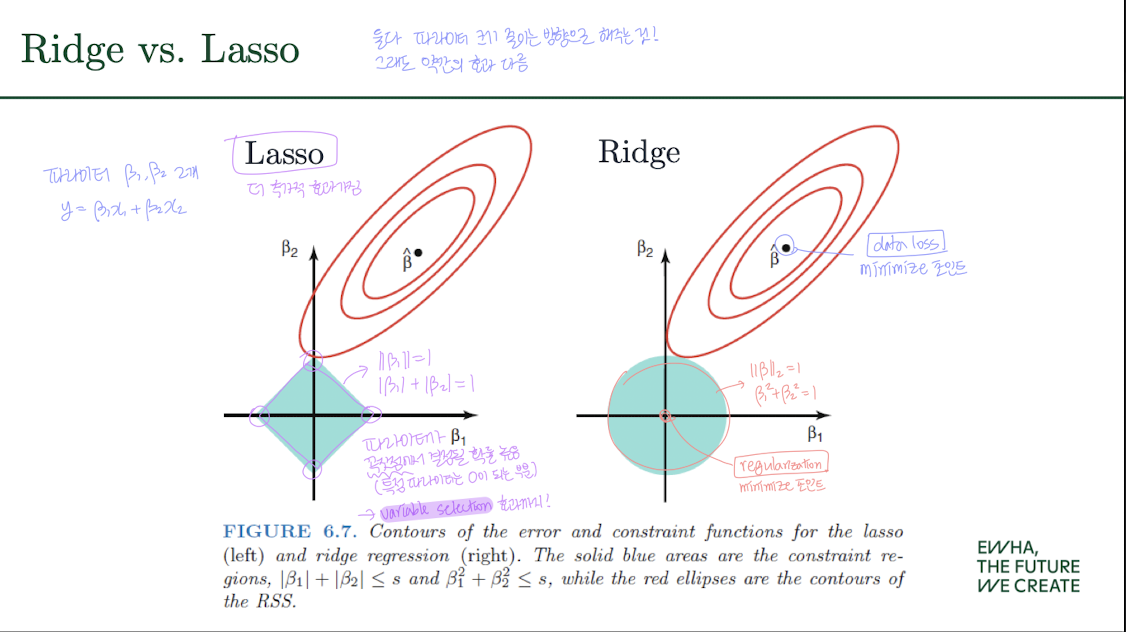
- L2는 모든 weight를 작게 만들려고 하지만,
- L1은 일부 weight를 아예 0으로 만들어버릴 수 있다
👉 즉, L1 정규화는 자동으로 변수 선택(variable Selection) 효과까지 준다
그런데, 위의 Lasso나 Ridge의 정규화 항들은 어디서 왔을까?
왜 나 같은 꼴이 되는지를 이해하려면
MLE와 MAP이라는 개념으로 넘어가야 한다.
정규화 항의 본질은 사전 정보(Prior)를 고려한 학습이다.
이것을 설명하는 게 바로 MLE (Maximum Likelihood Estimation) 와 MAP (Maximum A Posteriori Estimation) 이다.
MLE vs MAP : 파라미터 추정의 두 가지 방식
(1) MLE (Maximum Likelihood Estimation)
관측된 데이터를 가장 잘 설명하는 우도를 최대화하는 파라미터를 찾는 방법
👉 데이터만 고려
(2) MAP (Maximum A Posteriori)
MLE가 오직 데이터에만 집중한다면,
MAP은 prior(사전확률)을 고려해서 더 안정적인 추정값을 만든다.
- : 우도 (Likelihood) → 데이터에 대한 설명력
- : 사전확률 (Prior) → 우리가 가진 사전 지식
→ log 취하면:
👉 데이터 + Prior 정보 함께 고려
우리가 앞서 배운 정규화(Regularization) 개념과 MAP은 사실 같은 수식 구조를 갖고 있다.
MAP에서는 다음과 같은 loss를 최소화한다:
- 앞 부분: Data loss
- 뒷 부분: Regularization term (가중치의 크기 제어)
👉 이 구조는 Ridge Regression과 완전히 동일하다!
즉, MAP은 Regularization의 이론적 기반이 된다.
📌 MAP에서의 λ 값 해석 :
MAP에서는 다음과 같이 로 표현된다.
- : 데이터의 노이즈(불확실성)
- : 파라미터에 대한 prior의 불확실성
👉 데이터의 노이즈가 클수록, 정규화 항이 작아진다
👉 prior의 확신이 클수록, 정규화 강도가 커진다
