이전 글에서 우리는 선형 회귀(Linear Regression)를 통해 연속적인 수치 예측을 배웠다.
하지만 현실에서는 다음과 같은 문제들이 더 많다:
- 이메일이 스팸인지 아닌지?
- 환자가 질병에 걸렸는지 아닌지?
- 손글씨 숫자가 7인지 1인지?
👉 즉, 결과가 범주형(classification)인 문제들!
범주형 문제는 다음과 같은 방식으로 예측한다 :
- Logistic Regression : 이진 분류 문제를 해결하기 위한 모델
- Softmax Regression : 다중 분류 문제를 해결하기 위한 모델
이번 글에서는 이처럼 범주형 문제를 다루는
로지스틱 회귀(Logistic Regression)와 소프트맥스 회귀(Softmax Regression)
에 대해 정리하고자 한다.
1. Classification Model
분류 문제에서 선형 회귀는 왜 안 될까?
target 값이 2개의 class(0또는 1)인 이진 분류 문제일 경우,
모델이 예측해야 하는 건 :
즉, 입력 x가 주어졌을 때 클래스 1일 확률
그런데 선형 회귀 모델을 그대로 사용하면 이렇게 된다:
→ 실수 전체 에서 값을 가짐
→ ‼️ 확률처럼 해석할 수 없음! (확률은 반드시 [0, 1] 범위)
👉 그래서 출력을 [0,1]로 제한하는 함수가 필요하다.
확률 예측을 위한 비선형 함수 도입
그러기 위해, 선형 함수에 비선형 함수 σ(t)를 통과시키자
📌 목표:
linear regression 결과에 “확률 해석을 위한 activation function()”을 씌우자
조건 :
- 미분 가능하며,
- 출력값이 항상 [0, 1]에 있는 함수여야 한다.
종류 :
- Logistic model : (가장 널리 쓰임. 계산 빠름)
- Gompertz model :
- Probit model : : 정규분포의 누적분포함수 (CDF)
가장 널리 쓰이는 인 Logistic Function (= Sigmoid Function)에 대해 알아보자.
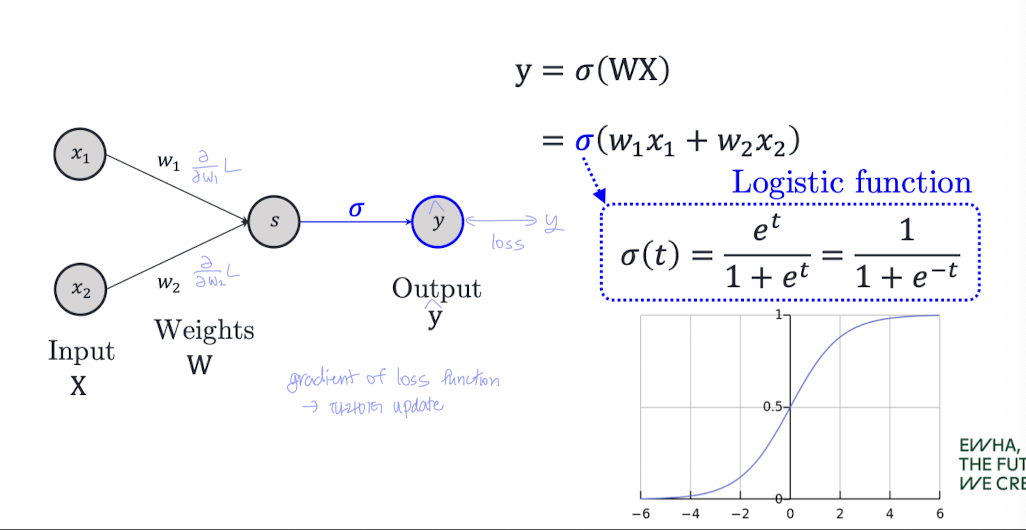
2. Logsitic Regression Model
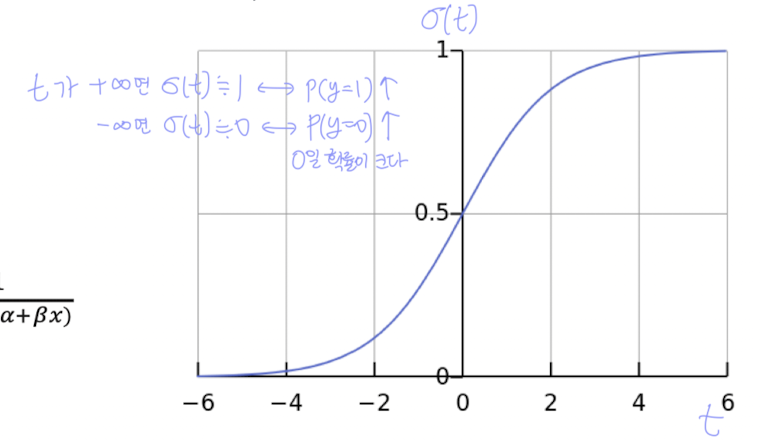
로지스틱 함수는 다음과 같은 형태를 갖는다:
- →
- →
→ 출력 범위는 항상 [0, 1]
이제 (linear regression)을 에 넣으면
📌 전체 모델 수식 :
- : 입력에 대한 선형 점수(score)
이진 분류에서는 score가 하나뿐이다
즉, 클래스 1 입장에서의 score만 계산해서 확률을 예측한다.
👉 그래서 는
입력값 x가 주어졌을 때, 그 결과가 클래스 1일 확률을 나타냄!
👉 회귀처럼 생겼지만 실제로는 분류 모델
→ “확률을 예측하는 회귀식”이라서 Logistic “Regression”이라고 부른다.
3. Classification Using Probability
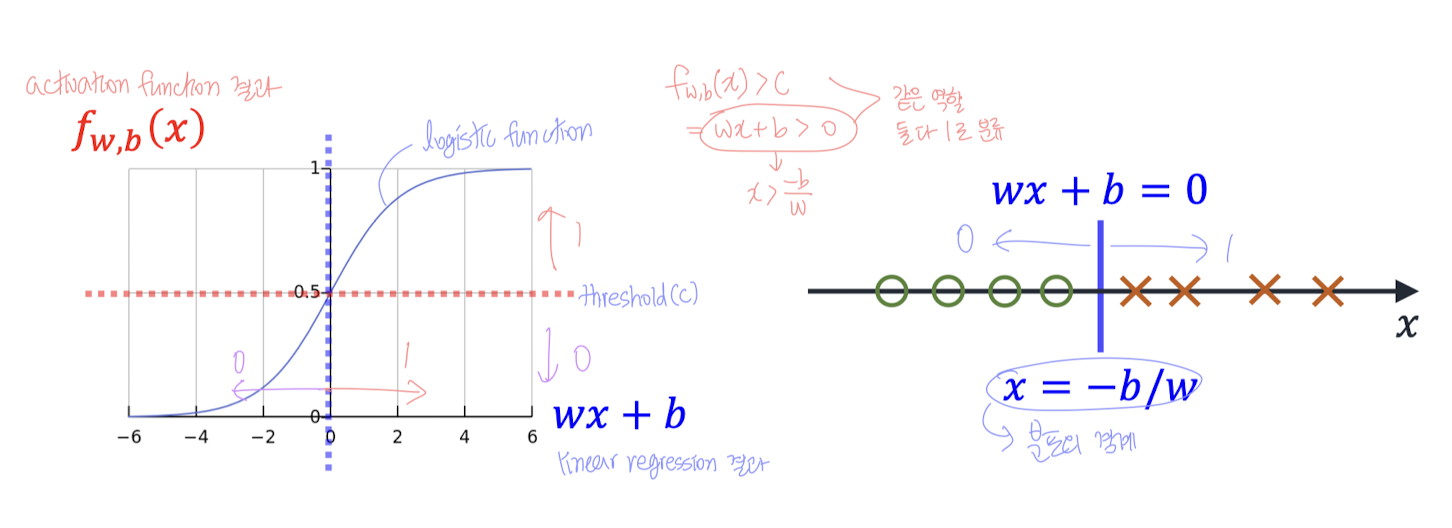
그럼 이 확률 을 이용해서 어떻게 클래스를 분류할까?
분류 기준: Threshold
👉 임계값(threshold)을 두고 그 기준으로 분류한다!
예를 들어 임계값을 0.5라고 한다면:
가
- 이면 → 클래스 1로 예측
- 이면 → 클래스 0으로 예측
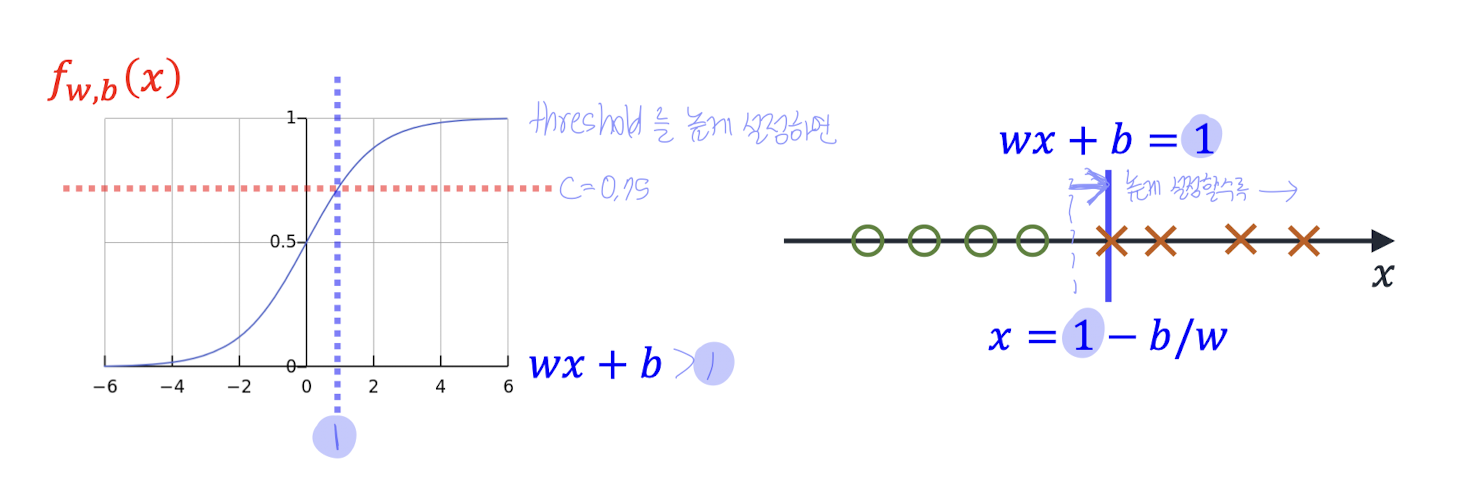
threshold는 원하는대로 조정할 수도 있다.
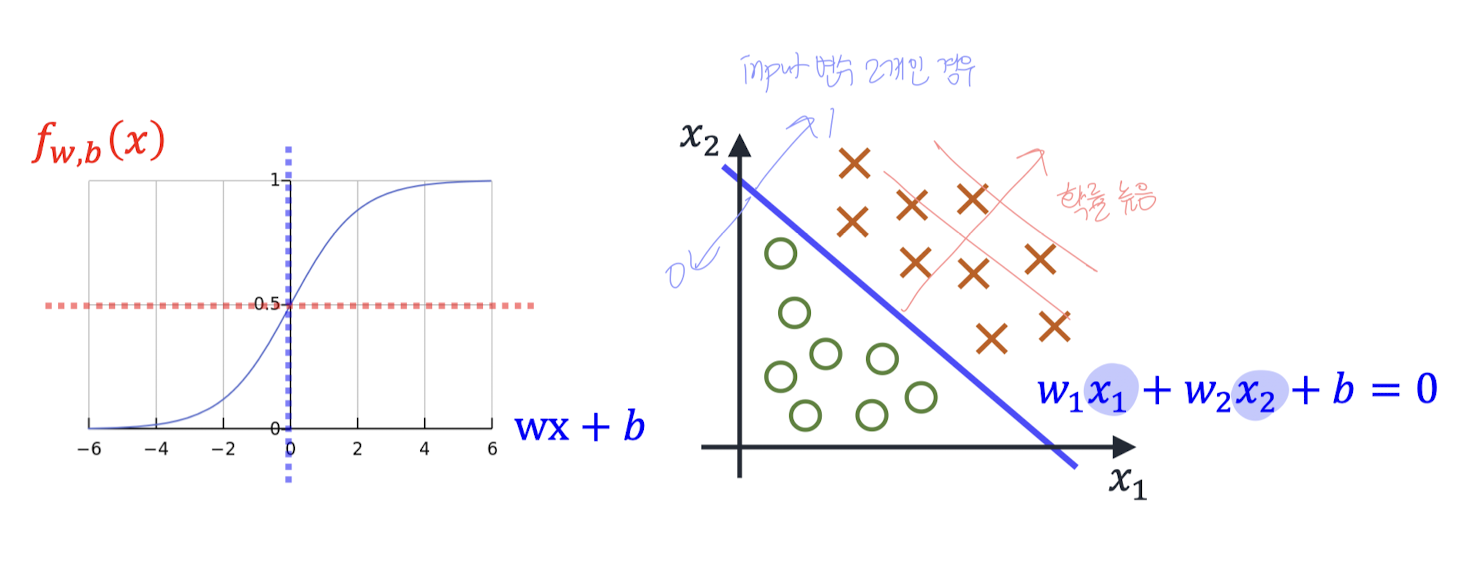
input이 여러 개일 수도 있다.
예) 2개인 경우 :
어떻게 가장 좋은 Threshold(c)를 정할 수 있을까?
1. 기본값: 0.5 사용
가장 흔하게 사용하는 기본값은 0.5이다.
이 경우, 결정 경계(decision boundary) :
‼️ 이 방식은 양 클래스의 비율이 비슷하거나 비용(cost)이 비슷할 때는 괜찮지만, 그렇지 않을 경우에는 문제가 생긴다.
👉 가능하면 Prior Knowledge나 Loss function 고려하기!
2. Prior Knowledge (사전 지식 반영)
데이터가 현실의 분포를 완벽히 반영하지 못하는 경우가 많다. 예를 들어,
- 데이터상으로는 클래스 1의 비율이 45%이지만,
- 실제로는 3.5%만 클래스 1일 수 있다 (ex. 국가 통계)
👉 이런 경우, threshold를 그에 맞게 낮춰줘야 더 정확한 판단이 가능하다.
예시:
실제 분포에 따라 threshold 조정
→ 예: 희귀 질병 예측, 연체 확률 판단 등
3. Loss Function 기반 조정
경우에 따라, 오류의 종류마다 발생하는 비용(cost)이 다를 수 있다.
예: 파산 예측 문제
- 잘못된 분류 1) 건강한 회사 → 파산으로 분류 → 약간 손해
- 잘못된 분류 2) 파산할 회사 → 건강한 회사로 분류 → 큰 손실 발생 (전액 투자 손실)
👉 이럴 때는 더 위험한 오류를 줄이기 위해 threshold를 조정해야 한다.
Cut-off 공식:
- : 클래스 0을 1로 잘못 분류했을 때 손실
- : 클래스 1을 0으로 잘못 분류했을 때 손실
👉 더 위험한 오류에 가중치를 두고 cut-off 조정 → 맞춤형 threshold 설계
4. 기타 고려사항
- 전문가 의견 (Expert opinion)
- 모델의 민감도(Sensitivity) / 특이도(Specificity)
- 규제기관 가이드라인 등
4. Parameter Estimation: MLE 기반 로지스틱 회귀 학습
이제 파라미터(w, b)를 학습해야 하는데,
선형 회귀처럼 SSE(오차 제곱합)를 최소화하는 방식을 사용할 수는 없다.
(로지스틱 회귀 모델에서는 출력값이 확률이기 때문에)
👉 대신, 우도(likelihood)를 최대화한다! (MLE)
💡 MLE( Maximum Likelihood Estimation )란?
현재 모델 파라미터 가 주어진 데이터가 관측될 가능성(우도, likelihood)을 최대화하는 것
Cross Entropy
💡 Cross Entropy (= Negative Log Likelihood)란?
우도(likelihood)에 log를 취하고 음수 부호를 붙인 것이다.
👉 최소화할 loss function으로 사용 가능
유도 과정은 다음과 같다 :

📌 최종 수식
👉 이 식이 바로 로지스틱 회귀의 비용 함수(cost function)
‼️ 로지스틱 회귀에서는 선형 회귀처럼 닫힌 해(Closed-form solution)이 존재하지 않는다.
최적화: 경사 하강법 (Gradient Desent)
👉 그래서 Gradient Descent(경사하강법)를 사용해 파라미터를 점진적으로 업데이트한다.
💡 경사하강법이란?
현재 위치에서 기울기(gradient)를 계산하고
기울기 반대 방향으로 조금씩 이동하면서 손실 함수를 줄여가는 방식이다.
📌 업데이트 공식:
- : 학습률 (learning rate) → 한 번에 이동할 거리
- : 비용 함수의 기울기
아래 그래프는 Gradient Descent의 동작을 보여준다:
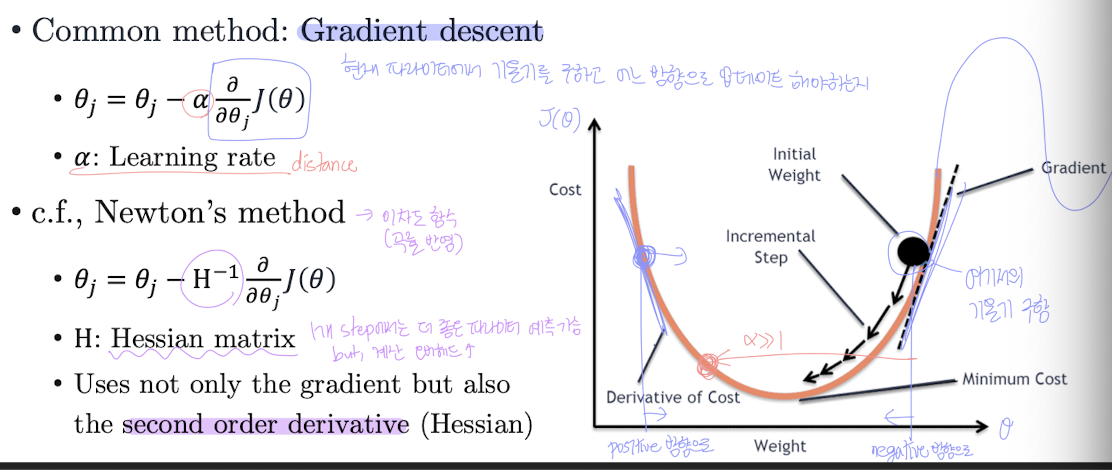
현재 위치에서 손실 함수의 기울기를 따라 만큼 이동
👉 반복적으로 이동하다 보면 최솟값(Minimum Cost)에 수렴하게 됨
cf) Newton’s method (뉴턴 방법)
더 정확하게 이동하고 싶다면?
→ 기울기(1차 미분)뿐만 아니라 곡률(2차 미분)까지 고려!
뉴턴 방법 공식:
- : Hessian 행렬 = 2차 미분을 모은 행렬
- 곡률 정보까지 활용해서 → 현재 위치에서 더 정확한 이동 방향을 예측
5. Interpretation of Logistic Model
로지스틱 회귀(Logistic Regression)의 출력은 확률이다.
즉, 모델은 가 주어졌을 때, 클래스 1일 확률을 예측한다.
📌 모델 수식 다시 보기
계수(Weight, )의 해석
- 이면 → 입력 가 커질수록 이 증가
- 이면 → 입력 가 커질수록 이 감소
즉, 로지스틱 회귀에서의 계수 는 입력이 결과에 얼마나 긍정적/부정적으로 영향을 미치는지를 나타냄.
확률 표현 방식: Odds & Odds Ratio
1. Odds
💡 Odds란?
확률을 표현하는 또 다른 방법으로,
“일어날 확률 / 안 일어날 확률”의 비율을 의미한다.
예: 확률이 0.75라면 (p = 0.75)
→ odds = = 3
→ 사건이 일어날 확률이 안 일어날 확률보다 3배 높다는 의미!
2. Odds Ratio (OR)
💡 Odds Ration란?
입력 가 한 단위 증가할 때 odds가 몇 배 변하는지
예: 이면
→ 입력이 1 증가할 때
→ odds는 배 증가!
6. Softmax Regression
앞서 로지스틱 회귀는 이진 분류(binary classification)에 적합한 모델이었다.
‼️ 하지만 현실 세계에서는 클래스가 3개 이상인 다중 분류(multi-class classification) 문제가 자주 발생한다.
👉 이럴 때 사용하는 것이 바로 Softmax Regression다.
(= 다중 로지스틱 회귀, Multinomial Logistic Regression)
모델 구조
cf) 이진 분류에서는 오직 하나의 score(클래스 1일 확률)만 계산하면 됐기 때문에,
파라미터도 1세트만 필요했다:

하지만 Softmax 회귀에서는 클래스마다 각각 score를 계산해야 하므로,
K개의 클래스가 있다면 각 클래스마다 별도의 파라미터 벡터()를 사용한다.
즉, 총 K개의 weight 벡터를 학습하게 된다.
📌 모델 수식 :
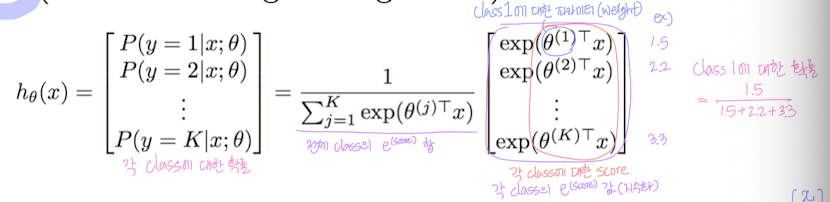
- : 클래스 에 해당하는 파라미터 벡터 (가중치)
- : 입력 벡터 (예: 나이, 키, 소득 등 feature)
- : **클래스 에 대한 score (점수)
- 클래스별로 입력이 얼마나 잘 맞는지 나타냄 (→ 가중치 × 입력의 내적값)
Softmax 함수
Softmax는 각 클래스의 score를 확률처럼 바꿔주는 함수다
→ 전체 클래스의 score를 지수화한 후 정규화
→ 출력은 각 클래스에 속할 확률의 벡터로, 총합이 항상 1이 된다.
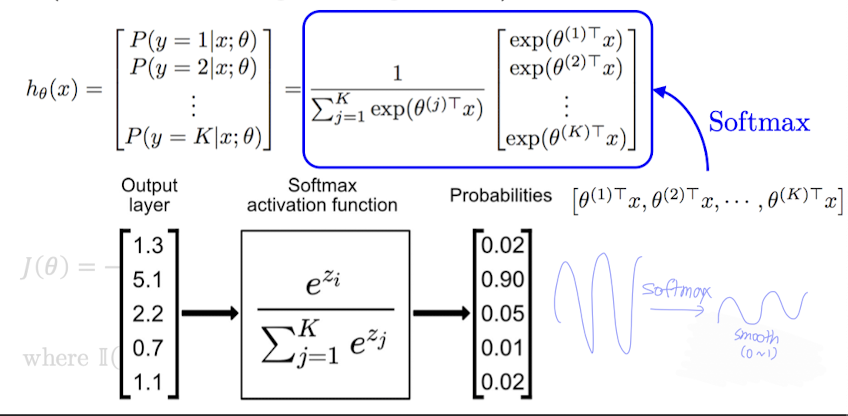
정리
✅ Softmax 회귀는 입력 x에 대해
→ 각 클래스별 점수(score)를 계산하고,
→ 지수 함수()로 변환한 뒤,
→ 모든 클래스에 대해 정규화(softmax)하여
→ 확률 분포를 출력한다.
👉 즉, Logistic 회귀가 시그모이드 함수를 이용한 확률화였다면,
👉 Softmax 회귀는 Softmax 함수를 통해 다중 확률을 예측한다.
비용 함수: Cross Entropy
이진 분류와 마찬가지로,
Softmax Regression에서도 비용 함수로는 Cross Entropy를 사용한다.
이 함수는 모델이 정답 클래스의 예측 확률을 최대화하도록 학습을 유도한다.
📌 수식 :
- : 전체 샘플 수
- : 클래스 개수
- : 샘플 의 정답 클래스가 이면 1, 아니면 0인 indicator 함수
- : softmax로 계산된 클래스 에 대한 예측 확률
📌 작동 방식 :
이중 합으로 보이지만, 실제로는 각 샘플마다 정답 클래스 하나만 활성화된다.
는 정답인 클래스에만 1이고, 나머지는 0이기 때문
즉, 전체 식은 이렇게 축약된다:
👉 각 샘플에 대해 정답 클래스의 예측 확률만 로그 취해서 누적하는 구조
📌 해석 :
- 정답일수록 모델의 예측 확률 가 커짐
- 확률이 커질수록 로그 값이 덜 작아짐 (log 값이 0에 가까워짐)
- 따라서 전체 loss가 줄어들고, 모델이 학습을 잘했다는 의미가 된다.
7. 회귀 구조 비교
선형 회귀 : Linear Regression
- 입력 (feature)와 가중치 의 선형 결합 결과를 그대로 출력
- 출력값 는 연속적인 실수값
- 예: 집값 예측, 키 예측 등
👉 선형 회귀는 출력이 범위를 가짐
로지스틱 회귀 : Logistic Regression
- 결과를 시그모이드 함수(σ)에 통과시켜 확률로 해석
- 출력값은 [0, 1] 사이의 값 → 확률로 이용
- 예: 이진 분류
👉 시그모이드는 score를 확률로 변환해주는 역할
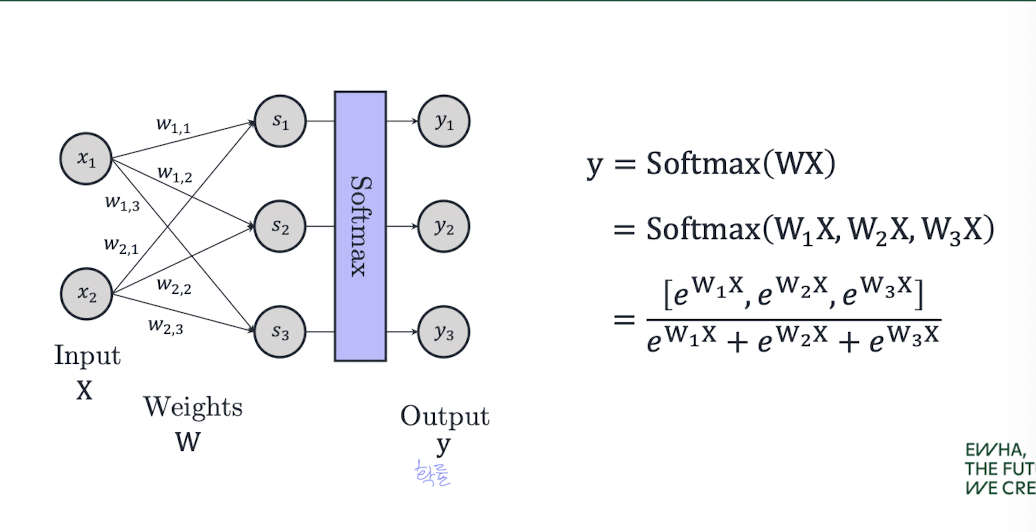
소프트맥스 회귀 : Softmax Regression (다중 클래스 분류)
- 클래스가 K개일 때, 각 클래스마다 별도의 가중치 를 학습
- 각 클래스에 대한 score (선형 결합)를 계산하고,
이를 softmax 함수에 통과시켜 확률로 변환
👉 출력은 K개의 클래스에 대한 확률 분포 (총합 1이 되도록 정규화됨)
8. Softmax Decision Boundary (결정 경계)
📌 Softmax 회귀의 핵심은 각 클래스마다 독립된 결정 경계를 학습한다는 점이다.
예: 클래스가 3개일 때
- 각 클래스에 대해 하나의 선형식:
- 입력 가 주어졌을 때 세 개의 score를 계산하고,
- 이 중 가장 높은 score를 가진 클래스를 예측값으로 선택
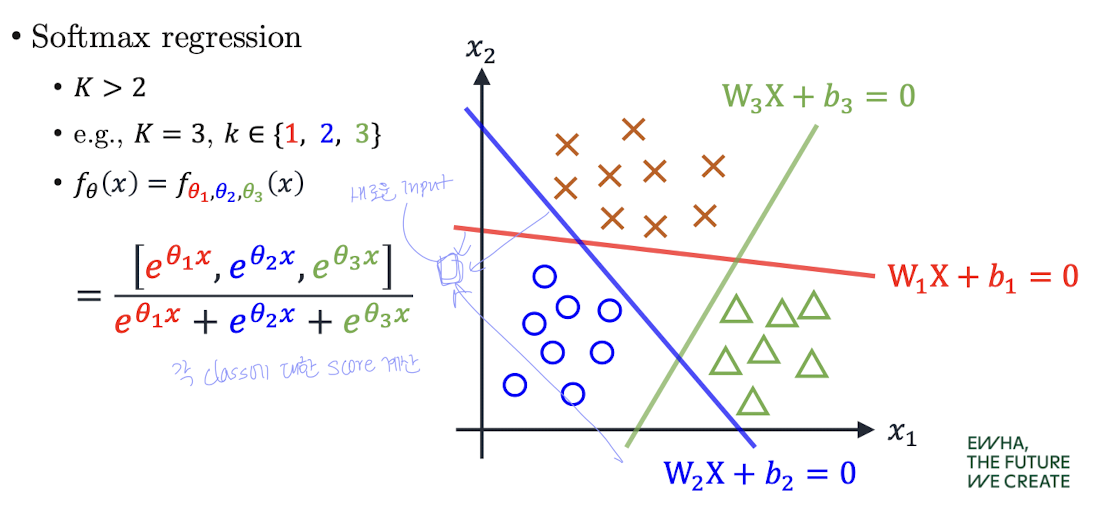
👉 각 클래스마다 자기만의 직선(결정 경계)를 만들며,
softmax는 이 score들을 비교하여 확률화된 예측을 수행함.
결론
정리
| 모델 | 주요 용도 | 출력값 | 활성화 함수 | 예측 방식 |
|---|---|---|---|---|
| 선형 회귀 | 연속값 예측 | 실수 | 없음 | |
| 로지스틱 회귀 | 이진 분류 | 확률 | 시그모이드 함수 | 클래스 1일 확률 예측 |
| 소프트맥스 회귀 | 다중 분류 | 확률 벡터 (총합 1) | 소프트맥스 함수 | 클래스 중 가장 높은 확률 선택 |
- 로지스틱 회귀는 score 하나만 사용하여 이진 분류 확률을 계산하고,
- 소프트맥스 회귀는 클래스마다 score를 따로 계산한 후 확률로 정규화하여 다중 분류를 수행함.
- 두 경우 모두 cross-entropy를 비용 함수로 사용하고,
경사 하강법 등의 최적화 방법으로 학습한다.
다음 글에서는?
- Overfitting이 왜 생기는지
- 이를 방지하기 위한 Regularization(정규화) 기법들
- 로지스틱 회귀에서의 정규화 적용 방법
