머신러닝에서 learning(학습)은 다음과 같이 나뉜다:
1. Supervised learning(지도 학습)
- Regression(회귀) : 연속적인 수치 예측 (예: 집값 예측)
- Classification(분류) : 범주(class) 예측 (예: 개/고양이 구분)
2. Unsupervised learning(비지도 학습)
- Clustering
- Anomaly detection
- Association
- Dimenstionality reduction (차원 축소)
이번 글에서는 이 중 Linear Regression(선형 회귀)에 대해 정리해보려 한다!
용어 정리
- : input variable = feature = explanatory variable
- : output variable = label = target
1. Simple Linear Regression
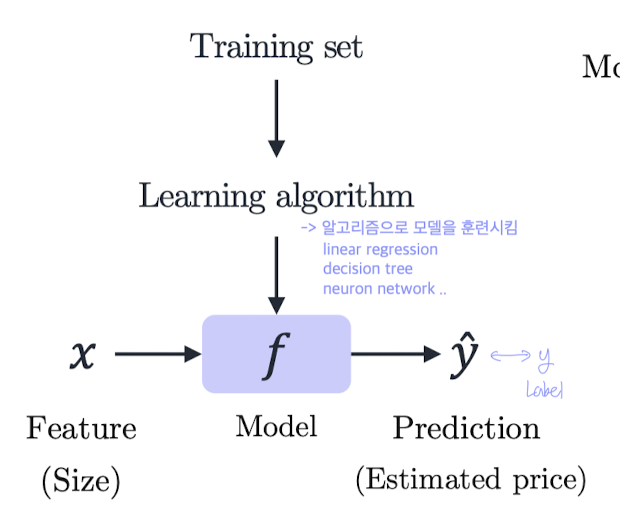
단순 선형 회귀 모델을 살펴보자.
(하나의 입력 변수 x로부터 출력 변수 y를 예측하는 linear regression)
- : weight (가중치)
- : bias (편향)
여기서 가중치와 편향을 파라미터라고 한다.
그렇다면 이 파라미터는 어떻게 결정할까?
2. 모델 파라미터 학습: Cost Function
📌 목적 : 비용 함수를 최소화하는 파라미터 찾기
💡 비용 함수 (Cost Function)란?
모델이 얼마나 잘 예측하는지를 판단하기 위한 함수
손실 함수 (Loss Function)
오차 제곱 (Squared Error) :
개별 샘플 에 대해
비용 함수 (Cost Function)
Sum of Squared Error (SSE) :
전체 샘플에 대한 손실의 합
3. 최적화(1): Least Squares Estimation (LSE)
앞서 선형 회귀 모델의 목적은
👉 예측값과 실제값의 차이인 cost function을 최소화하는 파라미터를 찾는 것이었다.
💡 Least Squares Estimation (
LSE)란?
: cost function 중 하나인 SSE를 최소화하는 파라미터 , 를 수학적으로 구하는 방법
파라미터가 1개일 경우:
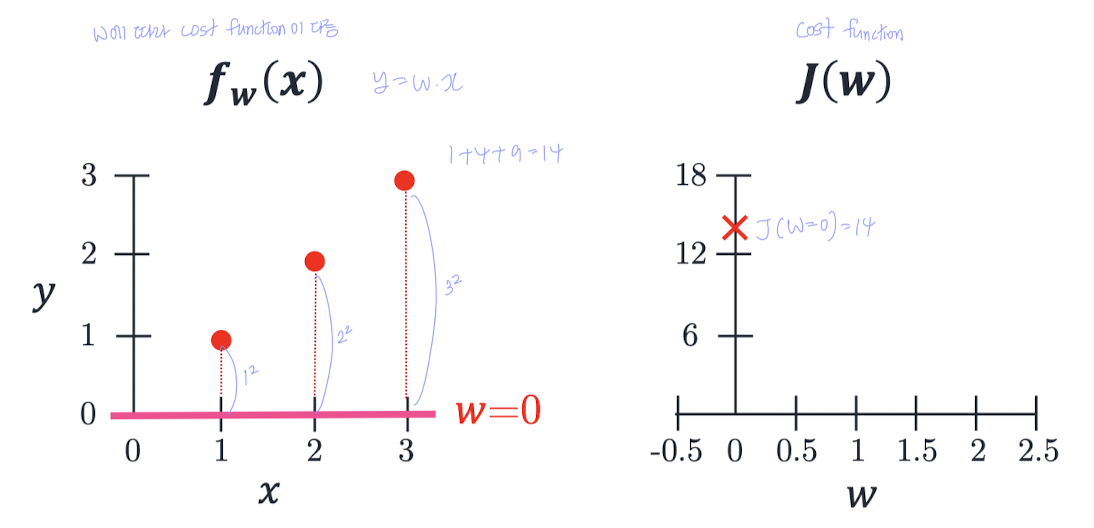
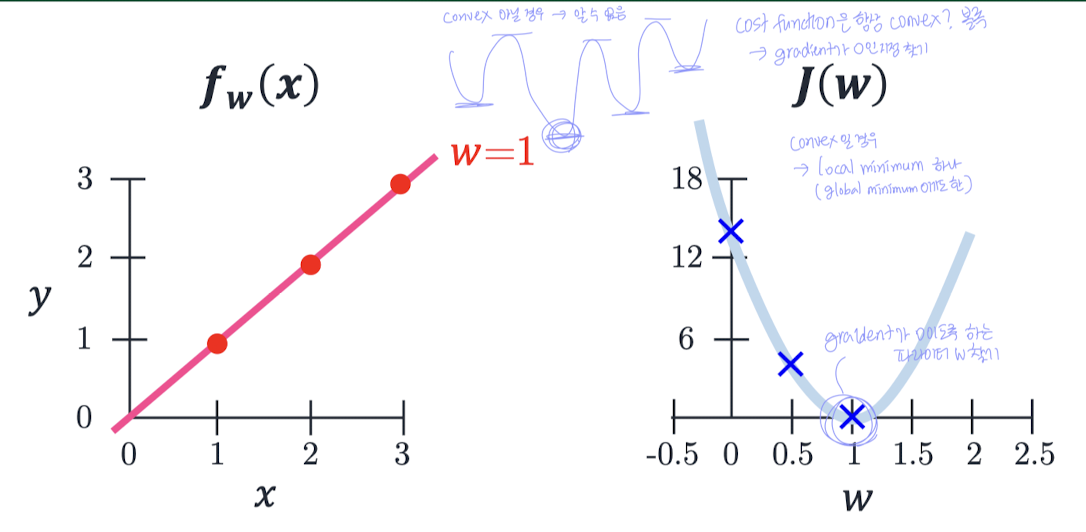
- 이때 SSE는 2차 함수 형태로 볼록(convex)하다.
- 따라서 이 되는 지점(기울기가 0이 되는 지점)을 만드는 w를 찾으면 된다.
파라미터가 2개일 경우:
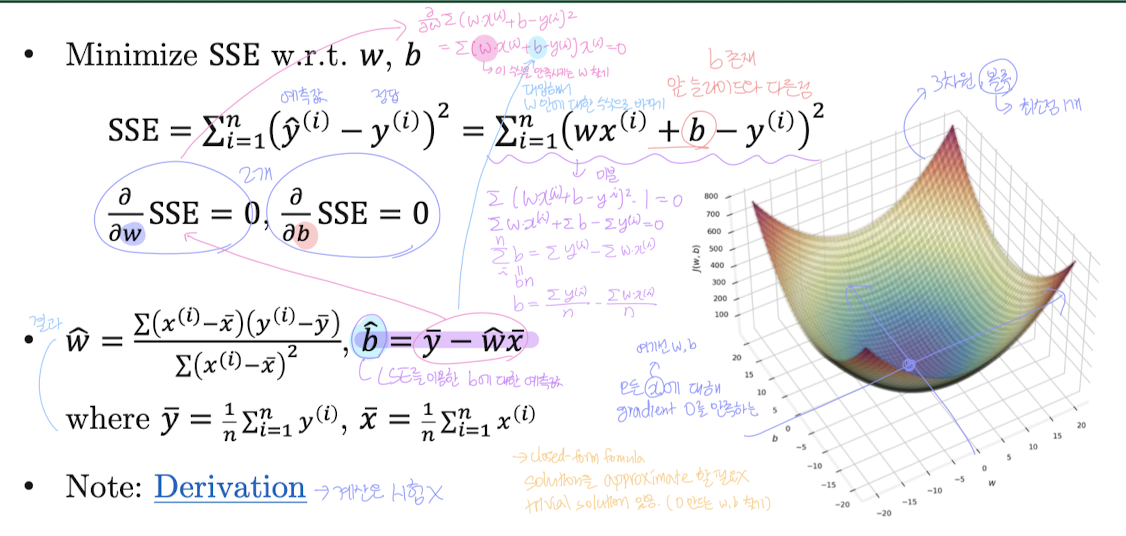
- SSE는 , 두 축에 대한 3차원 볼록 함수가 된다.
- 가로축: weight
- 세로축: bias
- 높이축:
- 가운데 파란 점은 모든 파라미터(, )에 대해 기울기 = 0인 지점, 즉 SSE가 최소가 되는 해
👉 이 점이 바로 우리가 찾는 최적의 파라미터
📌 공식 (Closed-form Solution)
- , : 각각 x와 y의 평균
- 이 공식은 모든 데이터에 대해 미분값이 0이 되는 지점을 수학적으로 풀어낸 결과
- 계산된 해는 반복 없이 바로 구할 수 있는 닫힌 해이며, 수학적으로 유도 가능하다.
- 근사해가 아니라 정확한 수학적 해
4. 최적화(2): Maximum Likelihood Estimation (MLE)
💡 MLE란?
주어진 데이터가 현재 모델(파라미터) 하에서 발생할 가능성(우도, Likelihood)이 가장 높도록 하는 파라미터를 찾는 방법이다.
선형 회귀 모델을 이렇게 표현해보자:
- : 에러 항 (노이즈), 평균 0, 분산 인 정규분포를 따른다고 가정
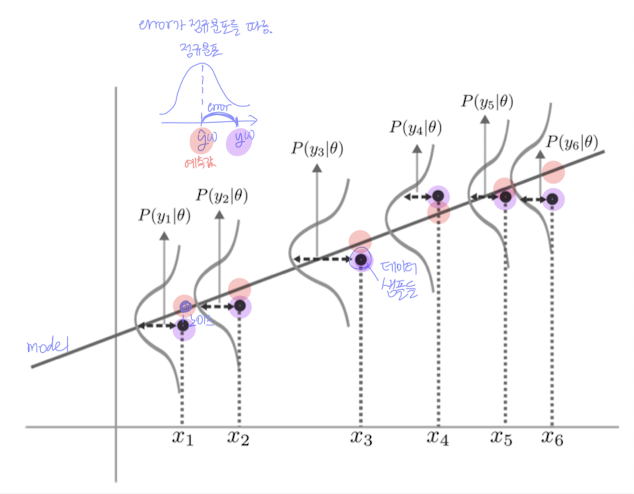
즉,
👉 모델이 완벽히 데이터를 설명하지 못하고 오차가 있을 수 있음을 고려해 확률적 관점에서 모델을 본다.
📌 가정
MLE를 적용하려면 다음 조건이 성립해야 한다:
- Linearity: y는 x에 대해 선형으로 표현됨
- Normality: 오차는 정규분포를 따름
- Homoscedasticity: 오차의 분산은 일정함 (등분산성)
이러한 조건 하에서 likelihood를 계산할 수 있다.
Likelihood (우도)
각 데이터 샘플이 특정 파라미터 에서 발생할 확률:
→ 전체 데이터에 대한 joint likelihood는 각 데이터의 likelihood를 모두 곱한 것
‼️ but, 곱은 미분이나 최적화에 불편
Log-likelihood
log를 취해서 더하기로 바꾼다
cf) 이때, log 함수는 단조 증가 함수이므로, log를 취해도 최댓값의 위치는 변하지 않음
앞서 오차항 라고 했으므로,
각 는 다음과 같은 정규분포를 따른다:
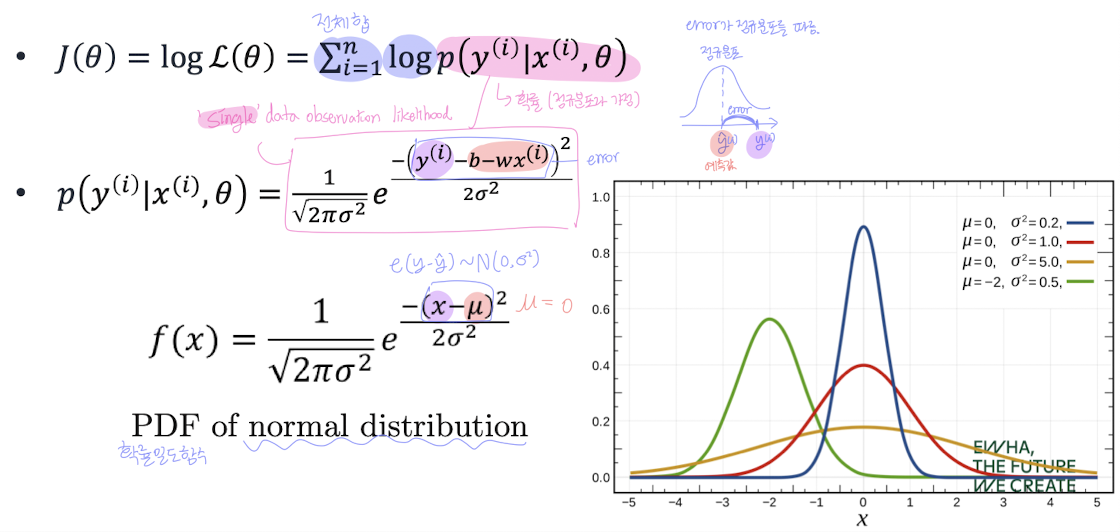
📌 최종 식:
앞부분은 상수항이므로 실제로 최적화할 대상은 아래 항(제곱합) 부분이다.
→ 결국 SSE를 최소화하는 것과 동일!
즉,
👉 MLE로 구한 파라미터 = LSE(최소제곱법)로 구한 파라미터
5. 다중 선형 회귀 (Multiple Linear Regression)
앞서 단순 선형 회귀(Simple Linear Regression)에서는 하나의 입력 변수 x만을 사용해 y를 예측했다.
하지만 현실의 대부분 문제는 여러 변수들을 함께 고려해야 정확한 예측이 가능하다.
👉 이때 사용하는 것이 바로 다중 선형 회귀(Multiple Linear Regression)다.
📌 모델 수식
- , , , : 입력 변수 (features)
- : 파라미터 (총 k+1개)
(→ loss function k+1 차원)
여전히 목표는 SSE를 최소화하는 파라미터를 찾는 것

📌 최적화 방법 : 정규방정식(Normal Equation)
SSE를 모든 파라미터 에 대해 미분하고, 미분값이 0이 되는 지점을 풀면
닫힌 해(Closed-form solution)을 얻을 수 있다:
- : 입력 행렬 (맨 앞 열은 bias를 위한 1로 채움)
- : 출력 벡터
- : 학습해야 할 파라미터 벡터
👉 이 문제는 고차원 공간에서 정의되지만, 여전히 convex 구조
→ 따라서 최적해는 항상 존재하며 유일
6. 다항 회귀 (Polynomial Regression)
앞서 선형 회귀는 데이터와의 관계가 직선(일차 함수)으로 표현될 수 있을 때 효과적이었다.
하지만 현실에서는 아래와 같이 선형으로 표현되지 않는 비선형 데이터인 경우가 많다.
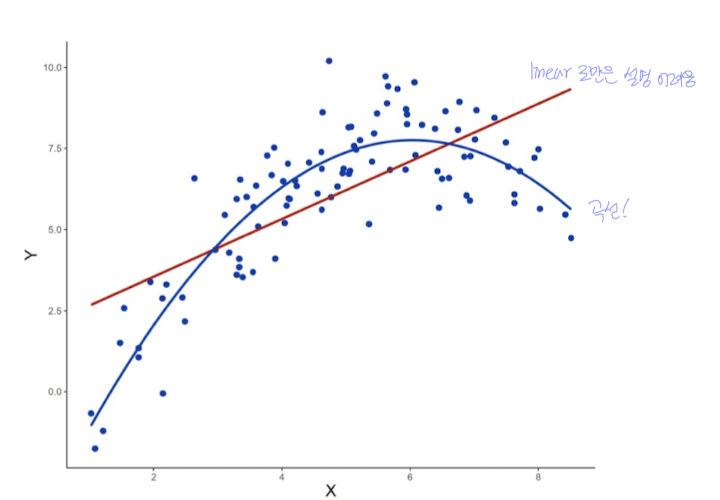
👉 이럴 때 사용하는 것이 바로 다항 회귀(Polynomial Regression)다!
📌 모델 수식
입력 표현 일반화 :
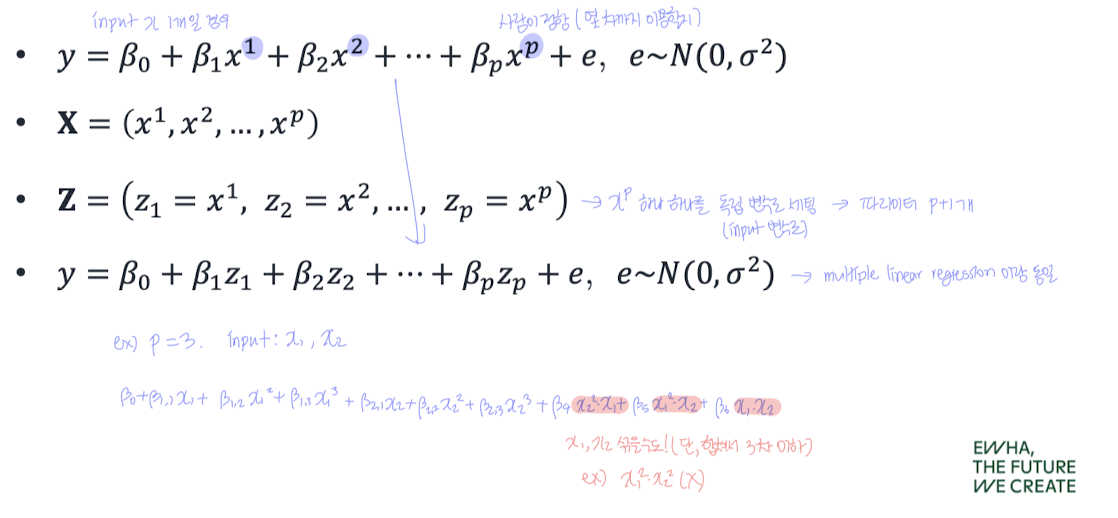
→ 즉, 원래 하나의 입력 변수 x를
→ 로 바꿔서
→ 마치 다중 선형 회귀처럼 학습을 진행하는 것과 동일
👉 다항 회귀는 결국 다중 선형 회귀로 변환해서 푼다 (선형 모델의 범주에 포함됨!)
7. 범주형 입력 변수 처리 (Handling Categorical Input Variables)
머신러닝에서 다루는 입력 변수 중에는 숫자가 아닌 범주형(categorical) 변수들도 많다.
예를 들어:
- 주차 공간 여부 → {Available, Not available}
- 주택 유형 → {Town house, Studio, Apartment}
- 요일 → {Mon, Tue, …, Sun}
‼️ 하지만 회귀 모델은 숫자 입력만 다룰 수 있기 때문에,
👉 범주형 변수는 반드시 수치형으로 변환해주어야 한다.
📌 예시: 주택 가격 예측 문제
- : 집값 예측 결과
- : 주차 공간 (Available, Not available) → 범주형(이진)
- : 주택 유형 (Town, Studio, Apt) → 범주형(3개)
- : 방 개수 (1,2,3,...) → 수치형
이진 범주형 변수 처리 (Binary Category)
두 가지 class만 있을 경우
예: Parking space () ∈ {Available, Not available}
- Available → = 1
- Not available → = 0
→ 문제 없음 !
- 은 “주차 공간이 있을 때 집값이 얼마나 더 상승하는지”를 의미
- 예: 주차 공간이 있을 때 가격이 5천만 원 상승
다중 범주형 변수 처리 (More than Two Categories)
2가지 이상 class가 있을 경우
예: House type () ∈ {Town house, Studio, Apartment}
이걸 단순히
- Town house → = 0
- Studio → = 1
- Apartment → = 2
처럼 숫자로 넣으면
‼️ dependency가 있는 것처럼 잘못 해석된다.
예:
- studio가 town house보다 1천만원 비싸면 ()
- apartment는 town house보다 무조건 2천만원 비싸야함
→ 해결 방법 필요!
해결 방법 1: One-hot encoding (모든 범주를 나눠서 표현)
📌 각 범주를 개별 변수로 분리
→ 모델 수식은 이렇게 바뀐다:
- 각 계수 는 해당 타입의 절대적인 가격 수준을 나타낸다.
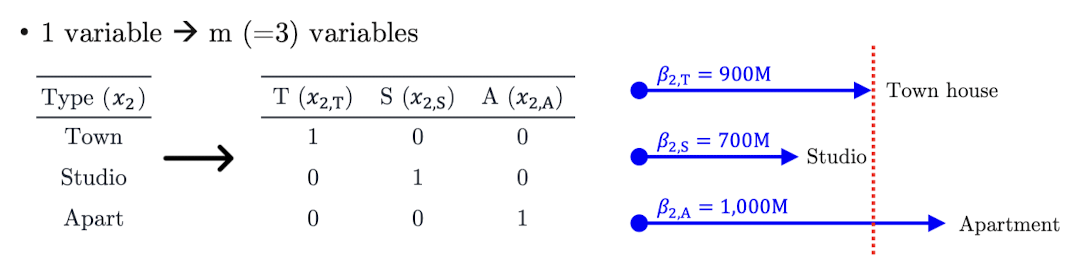
‼️ 해석은 쉬우나
- 변수가 너무 많아지는 문제가 생기고,
- 모든 범주를 포함하면 선형 종속(linear dependence) 문제가 발생해 회귀 모델이 학습 불가능해질 수 있다. (역행렬이 없어 정규방정식을 사용 못하는 문제)
해결 방법 2: Dummy variable encoding (기준 그룹 대비)
그래서 일반적으로는 기준 그룹(base category) 하나를 제거하고 나머지만 사용한다.
→ 여기서 Town house는 기준 그룹 (baseline)
- : Studio가 Town에 비해 얼마나 더 비싼지
- : Apartment가 Town에 비해 얼마나 더 비싼지

결론
정리
- Linear Regression : 연속형 값을 예측하는 선형 모델
- Cost Function : 예측값과 실제값의 차이를 제곱해서 합한 것 (SSE)
- LSE : SSE를 최소화하는 파라미터를 구하는 방법
- MLE : 확률적 관점에서 가장 우도 높은 파라미터 추정법 (SSE 최소화와 같아짐)
- 다중 회귀 : 여러 개의 입력 변수를 사용하는 선형 회귀
- 다항 회귀 : 입력을 비선형으로 확장해 선형 회귀로 푸는 방식
다음 글에서는?
로지스틱 회귀(Logistic Regression)의 수식과 해석
Classification 문제에서 확률 예측과 결정 경계에 대해 다룰 예정!
