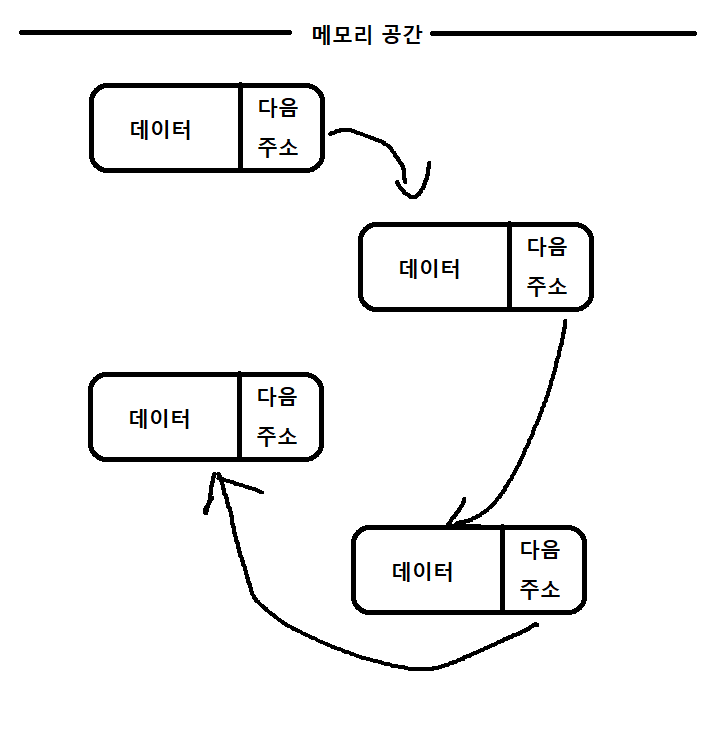
이번에 lsit 사용법에 대해서 알아보자
1.개요
연결형 리스트 경우에는 메모리 공간에 연속적으로 데이터가 존재 하는것이 아니다.
데이터 가 메모리 비어있는 공간에 각각 존재 하고 그 데이터를 다음공간 데이터 주소값을 같이 가지고 있어서 그값을 이용해 찾아간다.
그러면 새로 데이터가 리스트에 들어가 면 필요한 많큼 공간을 부여하고 데이터를 저장 한다.
그런 한 단위를 노드라고 부른다. 이 노드에 경우 데이터도 들어있고 추가로 다음 데이터 위치 주소값도 같이 가지고 있다.
이런 방향으로 코드를 보여주고 설명 들어가겠다.
2. 코드
Arr.h
// 노드
typedef struct _tagNode
{
int iData; // 저장될 데이터
struct _tagNode* pNextNode; // 다음 데이터 노드 포인터
}tNode;
// LinkedList
typedef struct _tabList
{
tNode* pHeadNode; // LinkedList에 시작 주소 값 확인
int iCount; // List 크기
}tLinkedList;
// 초기화
void InitList(tLinkedList* _pList);
// 데이터 추가
void PushBack(tLinkedList* _pList, int _iData);
void PushFront(tLinkedList* _pList, int _iData);
// 리스트 삭제
void ReleaseList(tLinkedList* _pList);_tabList 가 전체 관리하는부분이고
_tagNode 가 하나의 노드로서 동작한다.
위에 사진을 보면 이해가 더 쉽다.
Arr.cpp
#include "Arr.h"
#include <iostream>
void InitList(tLinkedList* _pList)
{
_pList->pHeadNode = nullptr;
_pList->iCount = 0;
}
void PushBack(tLinkedList* _pList, int _iData)
{
tNode* pNode = (tNode*)malloc(sizeof(tNode));
pNode->iData = _iData;
pNode->pNextNode = nullptr;
if (0 == _pList->iCount)
{
_pList->pHeadNode = pNode;
}
else {
tNode* pCurNode = _pList->pHeadNode;
while (true)
{
if (nullptr == pCurNode->pNextNode)
break;
pCurNode = pCurNode->pNextNode;
}
pCurNode->pNextNode = pNode;
}
++_pList->iCount;
}
void PushFront(tLinkedList* _pList, int _iData)
{
tNode* pNewNode = (tNode*)malloc(sizeof(tNode));
pNewNode->iData = _iData;
pNewNode->pNextNode = _pList->pHeadNode;
_pList->pHeadNode = pNewNode;
++_pList->iCount;
}
void ReleaseList(tLinkedList* _pList)
{
tNode* pDeletNode = _pList->pHeadNode;
while (pDeletNode)
{
tNode* pNext = pDeletNode->pNextNode;
free(pDeletNode);
pDeletNode = pNext;
}
_pList->iCount = 0;
}기본적으로 구현된 구조 이다.
void InitList(tLinkedList* _pList) 를 보면
List를 포인터로 받아서 헤드 노드롸 iCount를 초기화 하는 부분이다.
void PushBack(tLinkedList* _pList, int _iData)을 보면
먼저 새로 만들어줄 노드 를 만들고
다음으로 가는 pNextNode는 없으니 nullptr넣어준다.
그후 넣을려는 리스트에 노드 개수 확인해서 없으면 헤드에 넣어주고
아니라면 헤드 노드 부터 타고 올라가면서 pNextNode 가 nullptr 인곳에 이어서 넣어주고 카운트 하나 추가 한다.
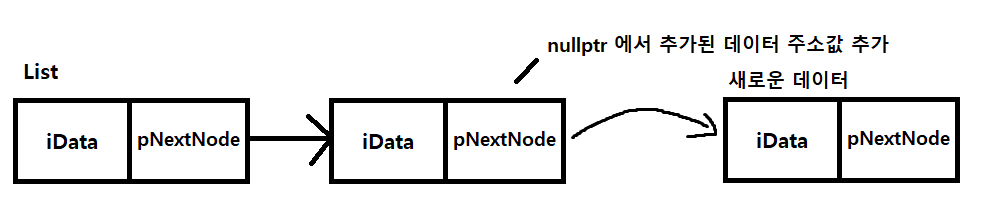
이런 방향으로 만들어지는것이다.
역시 void PushFront(tLinkedList* _plist, int iData)
부분을 보면 여기에선 먼저 List에 HeadNode 있는지 확인해서 있으면 헤드교체 를 해주고 NextNode에 추가해주는 부분이고
없다고 하면 헤드를 등록 해주는 부분이다.
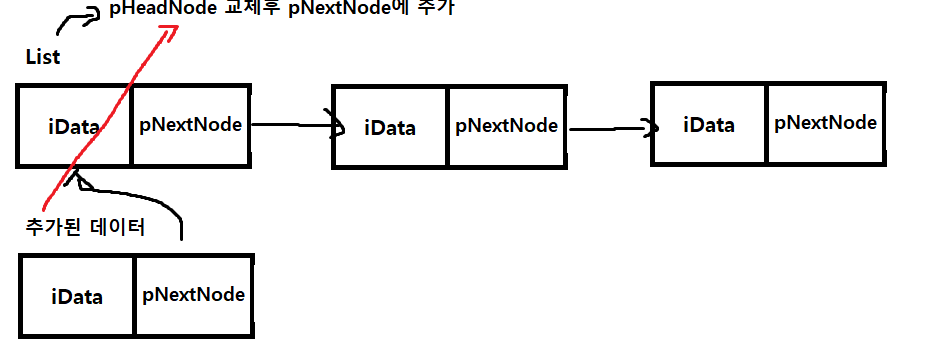
헤드 노드가 필요한 이유는 List에 시작 지점을 알아야하기 때문에 가지고 있다.
또한 시작 노드만 알면 모든 List를 확인할수도있다.
void ReleaseList(tLinkedList* _pList)
코드를 보면 헤드 노드를 찾아서 while문을 돌면서 메모리에 할당된 노드를 해제하는 부분이다.
활용 하는 법은
main.cpp
#include <iostream>
#include "Arr.h";
int main() {
tLinkedList list;
InitList(&list);
PushBack(&list, 10);
PushBack(&list, 100);
PushBack(&list, 1000);
PushBack(&list, 10000);
PushBack(&list, 100000);
PushFront(&list, 2);
tNode* pNode = list.pHeadNode;
for (int i = 0; i < list.iCount; ++i)
{
printf("%d \n", pNode->iData);
pNode = pNode->pNextNode;
}
ReleaseList(&list);
return 0;
}
으로 활용하고 브레이크 포인트 찍어서 보면 자세히 볼수있다
실행해보면
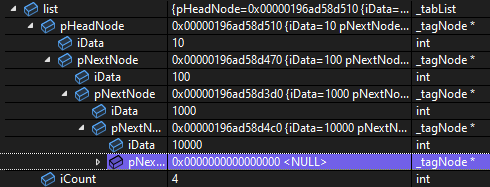
데이터 쌓여가는 과정과
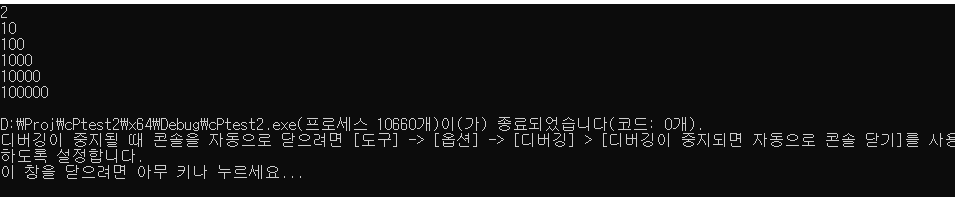
로그도 잘 나오는걸 확인 가능하다.
