0 군집 알고리즘
- 군집 알고리즘(Clustering Algorithm)은 비지도 학습(Unsupervised learning)의 한 종류로, 데이터를 서로 유사한 그룹 또는 클러스터로 그룹화하는 알고리즘.
데이터를 자동으로 그룹화해 패턴이나 특징을 발견하고 이해.
- K-means
- 계층적 클러스터링
- DBSCAN
- Mean Shift 클러스터링 - K-means 클러스터링은 주어진 데이터를 k개의 클러스터로 그룹화하는 가장 간단한 군집 알고리즘. => 각 클러스터는 중심(centroid)라고 불리는 특정 지점을 가져서, 각 데이터 포인트는 가장 가까운 중심에 할당.
1 데이터 준비 및 확인
import urllib.request
url = 'https://bit.ly/fruits_300_data'
file_name = 'fruits_300.npy'
urllib.request.urlretrieve(url, file_name)
import numpy as np
fruits = np.load('fruits_300.npy')
fruits_2d = fruits.reshape(-1, 100*100)- 이 파일은 300개의 과일 이미지가 포함되어 있다. 정확히는 사과, 파인애플, 바나나의 이미지가 100개씩.
- fruits는 (300, 100, 100)으로 된 배열. => reshape(-1, 100*100)으로 하니 (300, 10000) 모양으로 바뀐다.
plt.imshow(fruits[0], cmap='gray_r')
plt.show()
plt.imshow(fruits[200], cmap='gray')
plt.show()
- 데이터 시각화해서 내용물 확인.
apple = fruits[0:100].reshape(-1, 100*100)
pineapple = fruits[100:200].reshape(-1, 100*100)
banana = fruits[200:300].reshape(-1, 100*100)
print(apple.mean(axis=1))
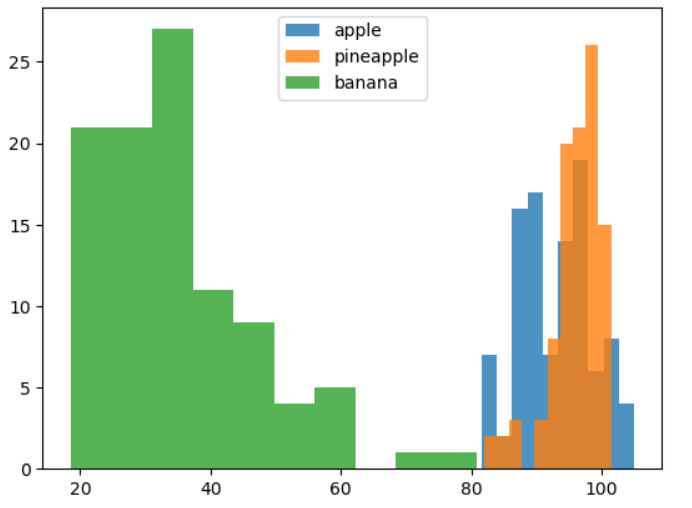
plt.hist(np.mean(apple, axis=1), alpha=0.8)
plt.hist(np.mean(pineapple, axis=1), alpha=0.8)
plt.hist(np.mean(banana, axis=1), alpha=0.8)
plt.legend(['apple', 'pineapple', 'banana'])
plt.show()- 픽셀값 분석.
- 먼저 100X100 크기의 이미지가 100장씩 있는 걸 => 10000개짜리 1차원 배열이 100행 있는 2차원 배열로 apple, pineapple, banana 각각 바꾼다.
- 각 행은 하나의 그림을 의미하고, 여기서
.mean(axis=1)이므로, 각 행들의 평균값을 계산. => 즉, 각 이미지의 평균 밝기 값. - 그걸 각자 그래프로 표시.
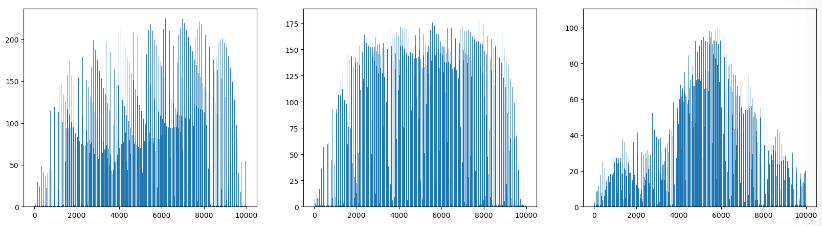
fig, axs = plt.subplots(1, 3, figsize=(20, 5))
axs[0].bar(range(10000), np.mean(apple, axis=0))
axs[1].bar(range(10000), np.mean(pineapple, axis=0))
axs[2].bar(range(10000), np.mean(banana, axis=0))
plt.show()- mean(axis=0)이므로, 이건 개별 이미지가 아니라, 100개 이미지의, 0~10000까지의 각 픽셀의 평균 밝기.
apple_mean = np.mean(apple, axis=0).reshape(100, 100)
pineapple_mean = np.mean(pineapple, axis=0).reshape(100, 100)
banana_mean = np.mean(banana, axis=0).reshape(100, 100)
fig, axs = plt.subplots(1, 3, figsize=(20, 5))
axs[0].imshow(apple_mean, cmap='gray_r')
axs[1].imshow(pineapple_mean, cmap='gray_r')
axs[2].imshow(banana_mean, cmap='gray_r')
plt.show()- 이건 각 픽셀별로의 평균 밝기를 각각 그림으로 나타낸 것.
- mean(axis=0)에서 reshape(100, 100)으로 돌려놨다(plot을 하기 위해)
- 여기까지 그래프들을 확인해보면 셋이 어느 정도 다른 패턴을 가지고 있고, 픽셀 값으로 클러스터링을 할 수 있을 것이라고 짐작할 수 있다.
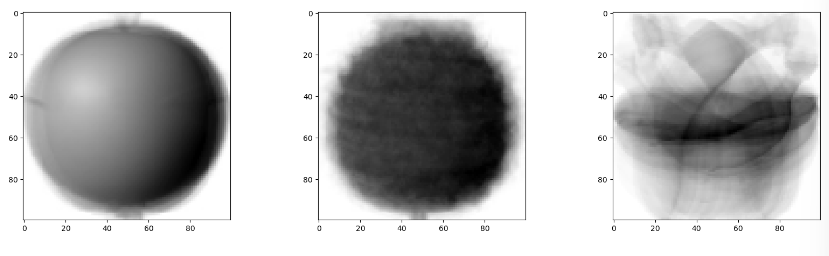
abs_diff = np.abs(fruits - apple_mean)
abs_mean = np.mean(abs_diff, axis=(1, 2))
print(abs_mean.shape)
apple_index = np.argsort(abs_mean)[:100]
fig, axs = plt.subplots(10, 10, figsize=(10, 10))
for i in range(10):
for j in range(10):
axs[i, j].imshow(fruits[apple_index[i*10 + j]], cmap='gray_r')
axs[i, j].axis('off')
plt.show()np.abs(fruits - apple_mean)으로 모든 과일 이미지와 사과 이미지의 평균과 각 픽셀별 절대값 차이를 계산. 여기서 fruits는 (300, 100, 100)의 3차원 배열이고 apple_mean은 (100, 100)짜리 2차원 배열. => 넘파이의 브로드캐스팅으로 배열간 연산 수행.np.mean(abs_diff, axis=(1, 2))으로 abs_diff의 평균을 계산하는데, axis=(1, 2)는 이미지의 세로와 가로 축에 대해 평균을 계산하도록 지정.
axis=0은 축0으로, 300장의 이미지.
axis=1은 축1로, 이미지의 각 행으로, 이미지의 세로.
axis=2는 축2로, 이미지의 열, 각 이미지의 가로.
=> 이렇게 모든 가로세로 픽셀의 평균 차이(사과 평균 - 각 이미지)를 계산한, (300, )짜리 1차원 배열이 생겼다.np.argsort(abs_mean)[:100]: argsort는 배열을 정렬할 때, 해당 요소의 원래 인덱스를 반환. 기본적으로 오름차순으로 정렬하고, 각 원소가 원래 배열에 어디에 위치 했는지를 나타낸다. => 즉, [3, 1, 5, 2]를 argsort하면 [1, 3, 0, 2]가 반환된다. 작은 순서대로 배열된 것의 인덱스가 반환되기 때문에.
이렇게 abs_mean이 가장 작은 순서부터 배열한 것의 인덱스를 100번까지 추출 => 사과 평균과 가장 픽셀의 절대값 차이가 적은 것을 100개 추출.- subplot 그리고 => 10개 X 10개로 그린다.
imshow는 이미지를 표시하는 함수. fruits라는 배열에서 apple_index에서 하나씩 지정해서 그려낸다.
axis는 off로 한다.

- 분류가 잘 된 것을 알 수 있다.
바나나, 파인애플도 똑같이 해보면 아래와 같은 결과가 나온다.
abs_diff = np.abs(fruits - banana_mean)
abs_mean = np.mean(abs_diff, axis=(1, 2))
banana_index = np.argsort(abs_mean)[:100]
fig, axs = plt.subplots(10, 10, figsize=(10, 10))
for i in range(10):
for j in range(10):
axs[i, j].imshow(fruits[banana_index[i*10 + j]], cmap='gray_r')
axs[i, j].axis('off')
plt.show()
abs_diff = np.abs(fruits - pineapple_mean)
abs_mean = np.mean(abs_diff, axis=(1, 2))
pineapple_index = np.argsort(abs_mean)[:100]
fig, axs = plt.subplots(10, 10, figsize=(10, 10))
for i in range(10):
for j in range(10):
axs[i, j].imshow(fruits[pineapple_index[i*10 + j]], cmap='gray_r')
axs[i, j].axis('off')
plt.show()

1 Kmean
from sklearn.cluster import KMeans
km = KMeans(n_clusters = 3 , random_state=42)
km.fit(fruits_2d)
print(km.labels_)
print(np.unique(km.labels_, return_counts=True))KMeans: K 평균 클러스터링을 실행하는 객체.
여기서n_clusters는 생성할 클러스터 수 지정.km.labels_: 각 데이터 포인트의 레이블을 담고 있는 속성. fitting을 통해 클러스터링을 수행한 후에 사용할 수 있다.np.unique(return_counts=True): 배열 내의 고유한 값들을 찾아주는 함수고, 여기서 return_counts는 각 고유값이 배열 내에 등장하는 횟수도 반환.
import matplotlib.pyplot as plt
def draw_fruits(arr, ratio=1):
n = len(arr) #n은 샘플 개수
rows = int(np.ceil(n/10)) # 한 줄에 10개씩 이미지
cols = n if rows <2 else 10 # 행이 1개면 열 개수는 샘플 개수, #그렇지 않으면 10개
fig, axs = plt.subplots(rows, cols, figsize=(cols*ratio, rows*ratio), squeeze=False)
for i in range(rows):
for j in range(cols):
if i * 10 + j < n: #n개까지만 그린다
axs[i, j].imshow(arr[i*10+j], cmap='gray_r')
axs[i, j].axis('off')
plt.show()- 이 함수는 이미지 배열을 넣으면, 그걸 모두 그려내는 함수.
- 먼저 n에 이미지의 개수를 저장.
np.ceil(): 주어진 숫자를 올림한 값으로 반환한다. => np.ceil(n/10)이므로 들어온 배열을 10개씩 하면 몇 줄이 나오는지가 나오고 => int로 정수로.- 행이 2보다 작으면(1이면), n 개수가 곧 행 개수. 안그러면 10
- fig, axs로 각자 rows, cols 개에 그 사이즈에 맞게 그리고,
squeeze=는 subplot 배열 시에 축을 압축하지 말고, 행과 열을 2차원으로 명확하게 만들도록. - for i, j로 하나씩 다 그리고 n개까지만. => axis('off')로 축 없앤다.

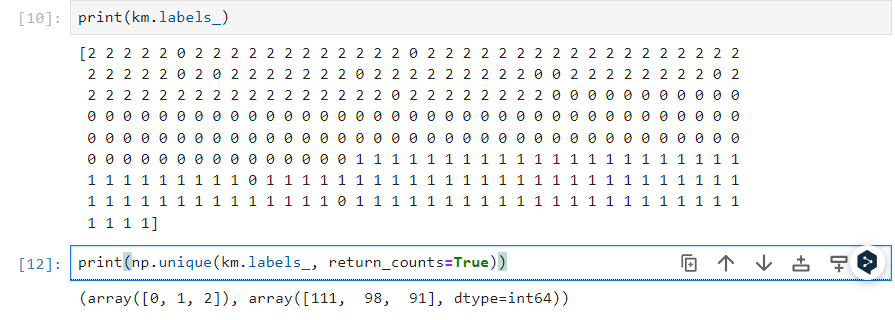
draw_fruits(km.cluster_centers_.reshape(-1, 100, 100), ratio=3)
print(km.transform(fruits_2d[100:101]))km.cluster_centers_: 클러스터링 수행한 후 얻은 클러스터 중심점을 나타내는 배열. 클러스터 중심점은 클러스터링 알고리즘에서 각 클러스터의 대표점.- 이를 (-1, 100, 100)으로 각각 2차원 배열로 reshape한다. 위의 함수가 이런 입력방식을 요구하기 때문에.
- 그리고 그걸 위에서 만든 함수로 그리되, ratio=3으로 크게(3배로) 그린다.
km.transform(): 주어진 데이터 포인트(여기선 101번째)와 각 클러스터 중심점 간의 거리를 계산. => 이를 통해 각 데이터 포인트가 각 클러스터에 얼마나 가깝게 속하는지 측정. => 제일 가까운 것으로 분류.
inertia = []
for k in range(2, 7):
km = KMeans(n_clusters=k, n_init='auto', random_state=42)
km.fit(fruits_2d)
inertia.append(km.inertia_)
plt.plot(range(2, 7), inertia)
plt.xlabel('k')
plt.ylabel('inertia')
plt.show()- 최적의 k값을 찾기. 여기서
n_init='auto'는 클러스터링 알고리즘이 초기 클러스터 중심점을 설정 방법을 지정하는 매개변수. 기본은 k-means++, random 2가진데, auto는 클러스터 수가 작으면 k-means++, 크면 random을 사용하도록 적용. km.inertia_는 클러스터링 결과의 응집성(inertia)를 나타내는 지표. 각 데이터 포인트와 해당 클러스터의 중심점 간의 거리를 제곱한 값들. 작을수록 더 잘 수행된 것.
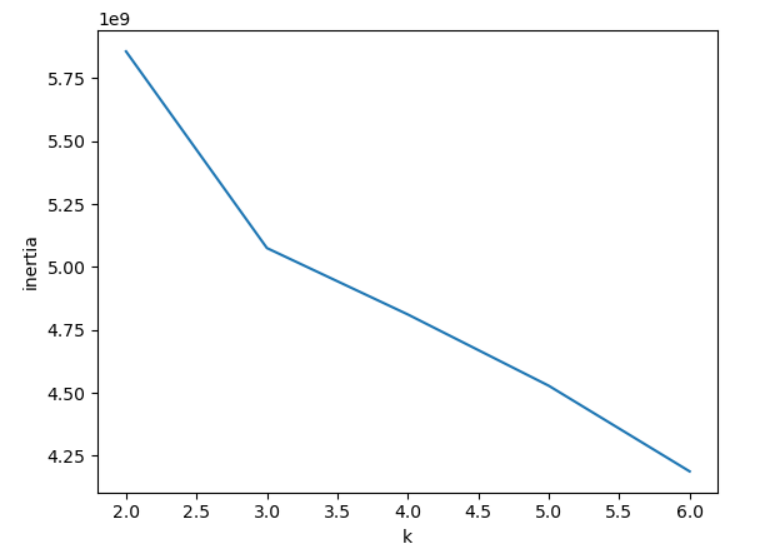
- 3이 제일 잘 된 걸 확인 가능.
2 전체 흐름 정리
- 2차원 이미지 데이터가 300개 있으면 => 300개를 각각 1차원 배열로 바꾼다
- KM객체에서 그 데이터로 fit 시킨다
- 여기서 for문을 돌려서 최적의 k값을 찾을 수 있다(inertia 확인)
- 이미지로 하나씩 그리는 함수 만들어서, 결과를 그림으로 확인
- 클러스터 줏임을 그리고, 그를 통해 확인할 수 있다
3 TF-IDF 실습
import pandas as pd
import glob, os
path = r'C:\Users\~~~\topics'
all_files = glob.glob(os.path.join(path, '*.data'))
filename_list = []
opinion_text = []
for file_ in all_files:
#개별 파일을 읽어서 DataFrame으로 생성
df = pd.read_table(file_, index_col=None, header=0, encoding='latin1')
filename_ = file_.split('\\')[-1]
filename = filename_.split('.')[0]
filename_list.append(filename)
opinion_text.append(df.to_string())
document_df = pd.DataFrame({'filename':filename_list, 'opinion_text':opinion_text})
document_df.head()- topics에 있는 .data 파일을 다 긁어온다. 여기서
r'디렉'으로 하면, 디렉토리 복붙할 때 \ 문제가 해결된다. - 먼저 파일을 하나씩 불러와서 df로 만든다
- 그리고 file의 디렉토리를 \ 기준으로 잘라서, 마지막에 있는 파일 이름을 filename에 저장. => split으로 .으로 나누고 확장자까지 제거 => 파일 이름 리스트에 더한다.
- opinion_text에는 데이터프레임 자료를 모두 text로 바꿔서 저장.
- 데이터프레임으로 만든다
import nltk
nltk.download('all')- NLTK 라이브러리의 모든 데이터셋과 자원을 다운하라는 명령.
from nltk.stem import WordNetLemmatizer
import nltk
import string
# nltk는 it is ok. ==> 여기서 .제거
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
lemmar = WordNetLemmatizer()
def LemTokens(tokens):
return [lemmar.lemmatize(token) for token in tokens]
def LemNormalize(text):
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))- NLTK 라이브러리에서 텍스트 정규화하는 게 목적.
ord(): 주어진 문자의 유니코드 포인트를 반환. A는 65.string.punctuation: string(파이썬 문자열 모듈)에 정의된 상수. 모든 문장 부호 문자를 포함하는 문자열. !, ., ?, ! 등.- 즉, string.punctuation으로 각각의 문장 부호를 ord로 바꾼 유니코드 포인트를 key로, value는 각각 None으로 한 dict저장.
WordNetLemmatizer: 단어 원형 복원(Lemmatization)으로 단어의 기본 형태인 원형을 찾는 과정 => 단어를 문맥에 맞게 변환해 분석하는데 도움이 된다.
Wordnet은 영어 어휘 데이터 베이스로, 단어들 간의 상위 하위 개념 관계를 정의. => WordNetLemmatizer는 이런 wordnet 정보 활용해 단어 원형 찾는다.LemTokens: 토큰 리스트에 대해 단어 복원을 실행해서 그 리스트를 반환하는 함수. 토큰은 일반적으로 문장이나 문서를 단어 단위로 쪼갠 것.LemNormalizetext.lower(): 입력된 텍스트를 모두 소문자로 변환..translate(remove_punct_dict): 문자열 내에서 각 문자를 지정된 다른 문자로 변환하는 메서드. 위에서 remove_punct_dict는 문장 부호:None으로 정의된 딕셔너리.nltk.word_tokenize(): 주어진 텍스트를 단어 단위로 토큰화해서 반환.- 위에 만든 LemTokens로, 토큰들을 원형으로 반환.
- 즉, 입력된 단어들을 소문자로 바꾸고, 부호들 없애고, 토큰화해서, 각 단어를 원형으로 반환
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vect = TfidfVectorizer(tokenizer=LemNormalize, stop_words='english',
ngram_range=(1, 2), min_df=0.05, max_df=0.85)
#opinion_text 컬럼값으로 feature vectorization 수행
feature_vect = tfidf_vect.fit_transform(document_df['opinion_text'])TfidVectorizer: 텍스트 데이터를 TF-IDF로 벡터화한다. TF-IDF는 위에 다른 문서에 설명 해놓았고, 요약하면 각 단어의 중요성을 나타내는 수치값.
tokenizer는 토큰화하고 전처리하는 함수이고, stop_word는 불용어 처리 방법 지정으로 여기서는 'english'로 영어 불용어 제거, ngram_range는 토큰화된 단어들 조합하는 방법 설정, min_df는 단어가 등장하는 문서의 최소 빈도수, max_df는 단어가 등장하는 문서의 최대 빈도수.- fit_transform으로 주어진 텍스트 데이터를 기반으로 TF-IDF 학습하고, TF-IDF 형식의 벡터로 변환. document_df['opinion_text']는 위에 만든 데이터.
from sklearn.cluster import KMeans
#5개 집합으로 군집화 수행
km_cluster = KMeans(n_clusters=5, max_iter=10000, random_state=0)
km_cluster.fit(feature_vect)
cluster_label = km_cluster.labels_
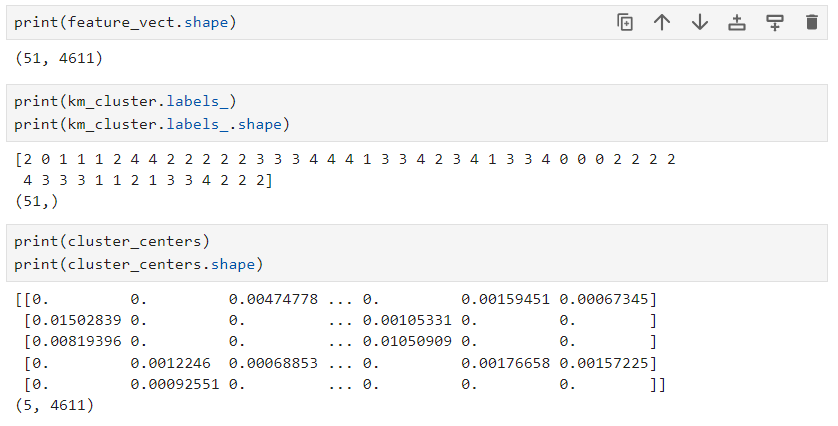
cluster_centers = km_cluster.cluster_centers_KMeans로 5개로 나누고, max_iter로 10000번까지 알고리즘 최대 반복 횟수 제한.km_cluster.labels_: 각 데이터 포인트에 할당된 클러스터 레이블을 나타내는 배열. 즉, 각 데이터 포인트가 어떤 클러스터에 속하는지.km_cluster.cluster_centers_: 클러스터 중심 좌표 나타내는 배열. 각 행은 하나의 클러스터, 열은 각 차원의 좌표 => 각 클러스터별로 중심 위치를 특징화하는 좌표.- 아래를 보면, featurevect는 51개의 문서를 토큰화해서, 각각 원형으로 바꾼 배열을, TF-IDF 모델로 벡터로 바꾼 것으로, (51, 4611)의 2차원 배열.
labels는 51개의 데이터 포인트가 어디에 해당되는지 배열.
clusercenters는 (5, 4611)의 2차원 배열인데, 각 행은 하나의 클러스터를 나타내고(총 5개의 클러스터로 나눴으므로) 열은 각 차원의 좌표(개별 피처들의 클러스터 중심과의 상대 위치를 정규화된 숫자값으로 표시)를 나타낸다(4611차원 벡터). => 그렇게 각 클러스터의 중심 포인트를. => 여기서 각 피처의 값이 클수록 중요한 피처가 된다. - 이렇게 나온 cluster.labels_를 새로운 열로 저장해서 결과 확인 가능.
# 군집별 top n 핵심단어, 그 단어의 중심 위치 상대값, 대상 파일명들을 반환함.
def get_cluster_details(cluster_model, cluster_data, feature_names, clusters_num, top_n_features=10):
cluster_details = {}
# cluster_centers array 의 값이 큰 순으로 정렬된 index 값을 반환
centroid_feature_ordered_ind = cluster_model.cluster_centers_.argsort()[:,::-1]
#개별 군집별로 iteration하면서 핵심단어, 그 단어의 중심 위치 상대값, 대상 파일명 입력
for cluster_num in range(clusters_num):
# 개별 군집별 정보를 담을 데이터 초기화.
cluster_details[cluster_num] = {}
cluster_details[cluster_num]['cluster'] = cluster_num
# cluster_centers_.argsort()[:,::-1] 로 구한 index 를 이용하여 top n 피처 단어를 구함.
top_feature_indexes = centroid_feature_ordered_ind[cluster_num, :top_n_features]
top_features = [ feature_names[ind] for ind in top_feature_indexes ]
# top_feature_indexes를 이용해 해당 피처 단어의 중심 위치 상댓값 구함
top_feature_values = cluster_model.cluster_centers_[cluster_num, top_feature_indexes].tolist()
# cluster_details 딕셔너리 객체에 개별 군집별 핵심 단어와 중심위치 상대값, 그리고 해당 파일명 입력
cluster_details[cluster_num]['top_features'] = top_features
cluster_details[cluster_num]['top_features_value'] = top_feature_values
filenames = cluster_data[cluster_data['cluster_label'] == cluster_num]['filename']
filenames = filenames.values.tolist()
cluster_details[cluster_num]['filenames'] = filenames
return cluster_detailscluster_model.cluster_centers_.argsort()[:,::-1]: cluster_centers는 각 클러스터의 중심점. => 이걸 argsort로 작은 순부터 인덱스를 반환. [3, 1, 2]면 [1, 2, 0]으로. => 그걸 -1로 해서 큰 순으로 반환.
즉, (5, 4611)이라고 하면, 각 행별로(각 클러스터별로) 중요한 피처 순으로(숫자가 큰 순으로) 반환. => 5, 4611이 반환.- cluster_details[cluster_num] = {}라는 딕셔너리를 만들고, ['cluster'] = cluster_num라는 클러스터 번호를 담는다.
- top_feature_indexes = centroid_feature_ordered_ind[cluster_num, :top_n_features] => 위에서 인덱스 뽑은 것에서 클러스터 번호, 그리고 입력값으로 몇 개의 중요한 피처를 들고올지 => 인덱스 저장.
top_features = [ feature_names[ind] for ind in top_feature_indexes ] => 그 인덱스들로 feature에서 하나씩 들고온다. feature names도 처음 입력값. - topfeature_values = cluster_model.cluster_centers[cluster_num, top_feature_indexes].tolist()
tolist()는 리스트로 바꾸는 메서드. 앞에서 cluster_model은 최초의 입력값이고, cluster_centers에서 [cluster_num, :]은 하나의 클러스터를 골라서 그 중심 벡터를 모두 가져온다. 거기서 top feature index로 값들만 들고 와서 리스트로 바꾼 것. - 즉, top_features는 상위 피처들의 이름을 저장, top_feature_values는 그 값들을 저장.
- 앞서 만든 cluster_details에 각각 저장.
- filenames = cluster_data[cluster_data['cluster_label'] == cluster_num]['filename']
여기서 cluster_data[cluster_label]==cluster_num은, 입력값인 cluster_data에서, 각 데이터 포인트가 어떤 클러스터에 속하는지 레이블의 열과, 지금 지정한 클러스터 넘버가 일치하는 것들만 가져온다. => 그리고 filename열만 선택. 이는 해당 클러스터에 속하는 각 데이터 포인트의 파일명이 포함된 시리즈. - filenames = filenames.values.tolist()
이걸 .values.tolist로 넘파이 배열로 변환 후, 리스트로 변환.
즉, filenames에는 해당 클러스터에 속하는 모든 데이터 포인트의 파일명이 리스트 형태로 저장. - 그리고 그걸 cluster_details에 넣는다.

일본에서 일하는 게임 기획자. 시시해서 죽어버리지 않게, 재밌고 의미 있는 컨텐츠에 관심 있습니다. 그 도구로 데이터, AI도 찝적댑니다.