1 PCA 분석
- PCA(Principal Component Analysis) 분석(주성분 분석)은 다차원 데이터를 저차원 공간으로 차원 축소하는 기법. 데이터 분산을 최대한 보존하면서 차원 축소해서 데이터 시각화, 압축, 노이즈 제거 등의 목적으로 활용. 주성분을 찾아내고 이를 이용해 데이터를 새로운 공간으로 반환.
- 데이터 분산이 가장 큰 방향을 찾아내서 이를 첫 번째 주성분으로 정의하고, 그 다음 주성분은 이전 주성분과 직교하면서 데이터 분산을 최대한 보존하는 방향으로 정의.
- 차원 축소는 데이터를 가장 잘 나타내는 일부 특성을 선택해 데이터 크기를 줄이는 것. 특성 많으면 선형 모델의 성능이 높아지고 과적합되기 때문에, 차원 줄여서, 데이터 크기 줄이고 지도 학습 모델 성능 향상.
- 주의할 점은 1차원 배열(벡터)에서의 차원은 원소의 갯수 but 2차원 이상 다차원 배열에서 차원은 배열 축의 개수를 말하는 것.
import numpy as np
fruits = np.load('fruits_300.npy')
fruits_2d = fruits.reshape(-1, 100*100)
from sklearn.decomposition import PCA
pca = PCA(n_components = 50)
pca.fit(fruits_2d)
fruits_pca = pca.transform(fruits_2d)- 먼저 fruits_300.npy라는 파일을 불러온다. Kmeans에서 사용한 사과, 파인애플, 바나나의 이미지 100개씩 픽셀값. 300, 100, 100. 그걸 => 300, 100000으로 2차원 배열로 바꾼다(하나당 이미지 하나)
PCA는 n_components는 유지할 주성분의 개수 지정. 50개만 유지.- 그리고 fit하고 transform한다. PCA 변환을 수행. (300, 50)으로 바뀌었다. 300개의 이미지가 각각 주성분 50개로 표현됨.
import matplotlib.pyplot as plt
def draw_fruits(arr, ratio=1):
n = len(arr) #n은 샘플 개수
rows = int(np.ceil(n/10)) # 한 줄에 10개씩 이미지
cols = n if rows <2 else 10 # 행이 1개면 열 개수는 샘플 개수, #그렇지 않으면 10개
fig, axs = plt.subplots(rows, cols, figsize=(cols*ratio, rows*ratio), squeeze=False)
for i in range(rows):
for j in range(cols):
if i * 10 + j < n: #n개까지만 그린다
axs[i, j].imshow(arr[i*10+j], cmap='gray_r')
axs[i, j].axis('off')
plt.show()
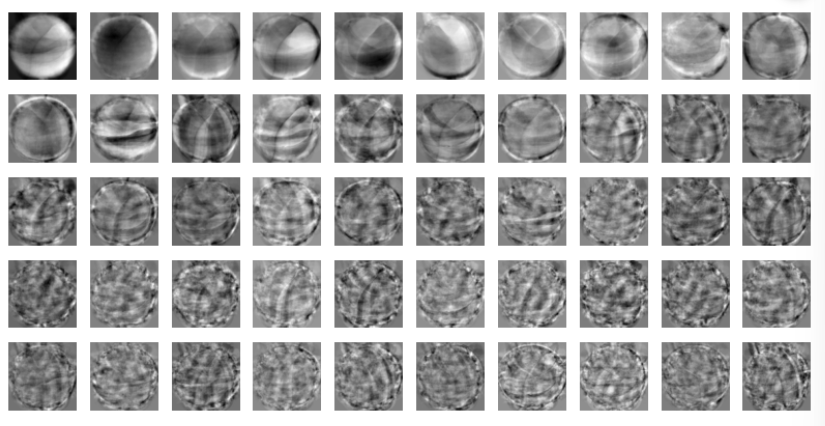
draw_fruits(pca.components_.reshape(-1, 100, 100))- 10개씩 그림 그리기.
pca.components_는 주성분에 대한 정보를 담고 있는 배열로, (50, 100000)이다. 위에 50개의 주성분을 추출했고, 10000은 원본 데이터 특성 수.
=> 각 행은 주성분을 나타낸다. 주성분의 목적은 데이터의 변동성(variability)를 설명하는 것. 이미지의 픽셀 10000개에 대해 픽셀이 높은 값을 나타내면, 해당 픽셀은 데이터 변동성을 크게 설명하는데 중요한 역할을 하는 것. => 값이(가중치가) 크면 클수록 해당 픽셀은 주성분이 데이터의 변동성을 설명하는 데 중요한 역할을 한다.
여기서 변동성은 데이터 포인트들이 서로 다른 값을 갖는 정도(얼마나 다양한 값을 포함하는지, 평균으로 얼마나 펴져 있는지) => 분산이 크다 => 클러스터링에서 구분이 더 유효하다
=> 1행은 가장 중요한 특성. 2행이 그 다음.- 이렇게 뽑은 주성분 50개를 각각 이미지로 나타낸다. 해당 이미지(주성분)의 진한 픽셀이 더 큰 변동성을 갖는 부분.
1-1 차원을 줄인 후 원상복구가 가능한가?
fruits_inverse = pca.inverse_transform(fruits_pca)inverse_transform메서드는 PCA 변환된 데이터를 다시 원래 차원으로 복원. => 완전히 동일하지 않고 정보 손실 있을 수 있다.- 주성분 갯수가 많으면 당연히 정보가 덜 손실된다.
1-2 50개 특성은 분산을 얼마나 보존하고 있는가?
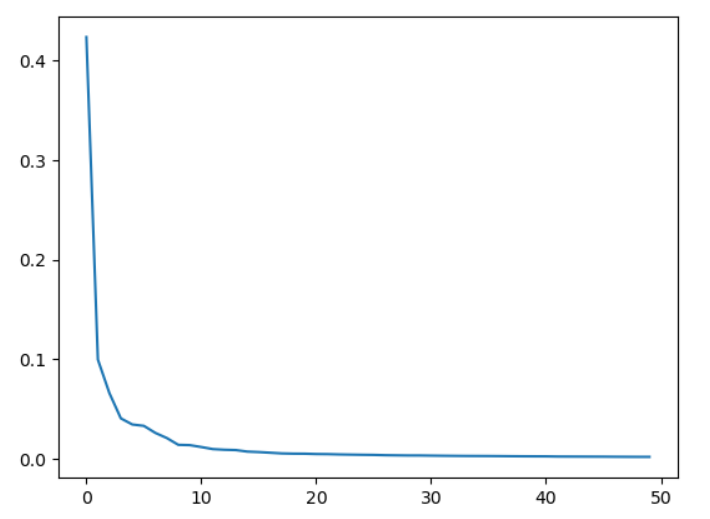
print(np.sum(pca.explained_variance_ratio_))
plt.plot(pca.explained_variance_ratio_)
plt.show()pca.explained_variance_ratio: 각 주성분이 전체 데이터의 분산을 설명하는 비율을 나타낸다. 지금 pca 모델은 50개이므로 (50, )의 1차원 배열로 각각의 주성분이 분산을 설명하는 비율이 배열로.- np.sum()으로 다 합친다. => 0.92가 결과. 92% 보여준다.
- plotting 해보면 몇 개가 적절한지 파악 가능. => 결과를 보면 최초 10개가 대부분의 분산을 설명.
2 다른 알고리즘과 함께 사용 => 원본 데이터와 비교
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
target = np.array([0]*100 + [1]*100 + [2]*100)
from sklearn.model_selection import cross_validate
scores = cross_validate(lr, fruits_2d, target)
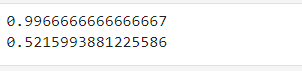
print(np.mean(scores['test_score']))
print(np.mean(scores['fit_time']))- 먼저 LogisticRegression을 위해 타겟 데이터로 사과 0, 파인애플 100, 바나나 2의 target 배열을 만든다.
cross_validate는 교차 검증을 수행해 모델 성능 평가. lr은 평가할 모델, fruits_2d는 데이터, target은 타겟.
=> fit_time, score_time, test_score에 각각 5개씩 들어가있는 딕셔너리 형태다. 각각 5번의 교차 검증에 대한 정보들.
fit_time: 모델 훈련에 걸린 시간, score_time: 예측 수행에 걸린 시간, test_score: 각 교차 검증에서 모델 성능 점수- 그것들에 대해 np.mean()으로 평균을 낸 결과들
pca = PCA(n_components = 0.5)
print(pca.n_components_)
pca.fit(fruits_2d)
fruits_pca = pca.transform(fruits_2d)
scores = cross_validate(lr, fruits_pca, target)
print(np.mean(scores['test_score']))
print(np.mean(scores['fit_time']))- 여기서 ncomponents가 0.5면 주성분 수가 아니라 누적 설명된 분산 비율이 0.5가 축소 된다. => ```pca.n_components```는 선택한 주성분의 수 출력. 확인해보면 2개가 나온다.
- 결과를 확인해보면 score는 크게 다르지 않지만, 시간은 엄청 줄었다.
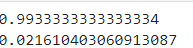
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3, random_state=42)
#fruits_pca => 50% 비율
km.fit(fruits_pca)- 이건 KMeans로 실행한 거.
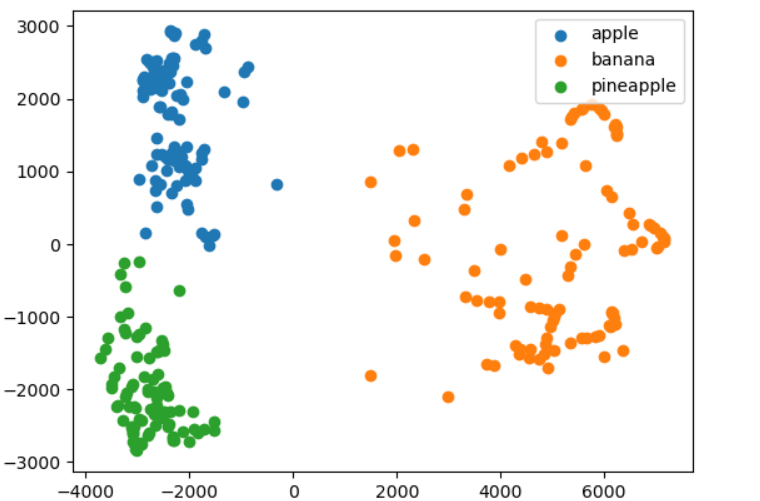
for label in range(0, 3):
draw_fruits(fruits[km.labels_ == label])
print('\n')
for label in range(0, 3):
data = fruits_pca[km.labels_ == label]
plt.scatter(data[:, 0], data[:, 1])
plt.legend(['apple', 'banana', 'pineapple'])
plt.show()- 위는 각각 예측 라벨별로 이미지.
- 아래는 fruits_pca는 300, 2로 되어 있는 배열. 즉, 각각 300개의 이미지에서 주성분 2개.
- 각각의 예측 라벨을의 pca성분을 data라는 변수에 저장해서, 모든 행에 주성분 0, 1을 각각 x와 y에 넣어서 scatter로 시각화.
3 문제
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import sklearn
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
iris = load_iris()
from matplotlib import font_manager, rc
plt.rcParams["axes.unicode_minus"] = False #-표시 깨짐 방지
#f_path = "/Library/Fonts/AppleGothic.ttf" # Mac 전용
f_path = "C:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname = f_path).get_name()
rc("font", family = font_name)
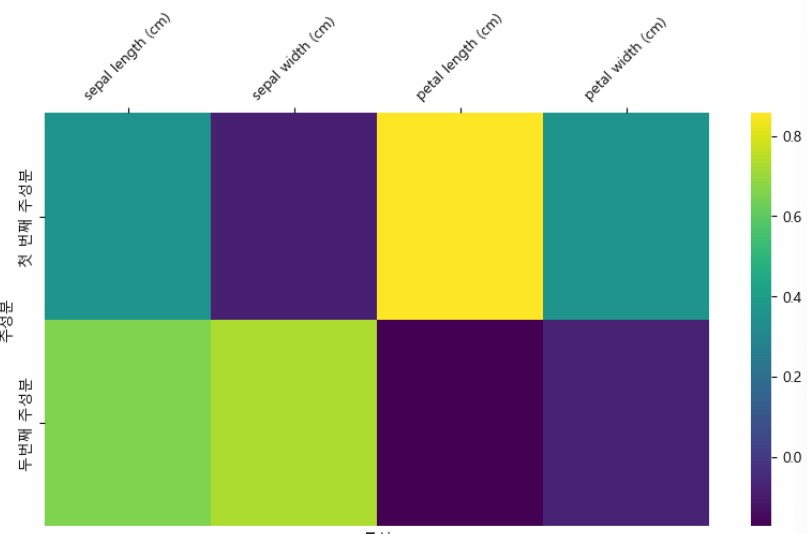
# 주성분 2개 줘보기
pca = PCA(n_components=2)
pca.fit(iris.data)
compo_uc = pd.DataFrame(pca.components_, columns=iris.feature_names, index = ["첫 번째 주성분", "두번째 주성분"])
plt.figure(figsize=(10,5))
ax = sns.heatmap(compo_uc, cmap="viridis")
ax.set_xticklabels(ax.get_xticklabels(), rotation=45)
ax.xaxis.set_ticks_position('top')
plt.xlabel("특성")
plt.ylabel("주성분")
plt.show()
#1
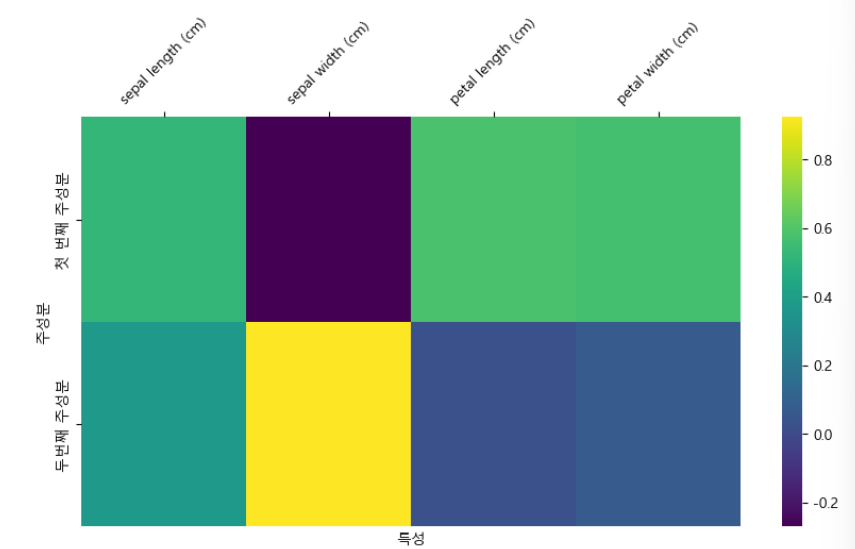
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
iris_sc = ss.fit_transform(iris.data)
# 주성분 2개 줘보기
pca = PCA(n_components=2)
pca.fit(iris_sc)
compo = pd.DataFrame(pca.components_, columns=iris.feature_names, index = ["첫 번째 주성분", "두번째 주성분"])
plt.figure(figsize=(10,5))
ax = sns.heatmap(compo, cmap="viridis")
ax.set_xticklabels(ax.get_xticklabels(), rotation=45)
ax.xaxis.set_ticks_position('top')
plt.xlabel("특성")
plt.ylabel("주성분")
plt.show()
iris_pca = pca.transform(iris_sc)
print(iris_pca.shape)
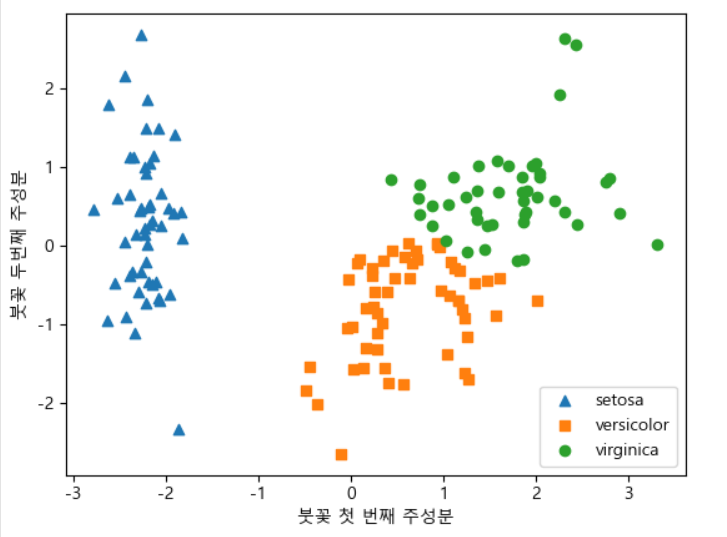
km = KMeans(n_clusters=3, random_state=1)
km.fit(iris_pca)
markers = ["^","s", None]
for label in range(0,3):
d = iris_pca[km.labels_ == label]
plt.scatter(d[:,0], d[:,1],marker=markers[label])
plt.legend(iris.target_names)
plt.xlabel("붓꽃 첫 번째 주성분")
plt.ylabel("붓꽃 두번째 주성분")
plt.show()- iris 데이터 로드하고 => 주성분 분석 실시 => 그 주성분으로 데이터프레임 만들어서 => 히트맵으로 시각화(각각의 주성분이 얼마나 잘 설명하는지)
- 다른 데이터로 한 번 더.
- 마지막은 주성분 1, 2 별로 시각화.

일본에서 일하는 게임 기획자. 시시해서 죽어버리지 않게, 재밌고 의미 있는 컨텐츠에 관심 있습니다. 그 도구로 데이터, AI도 찝적댑니다.