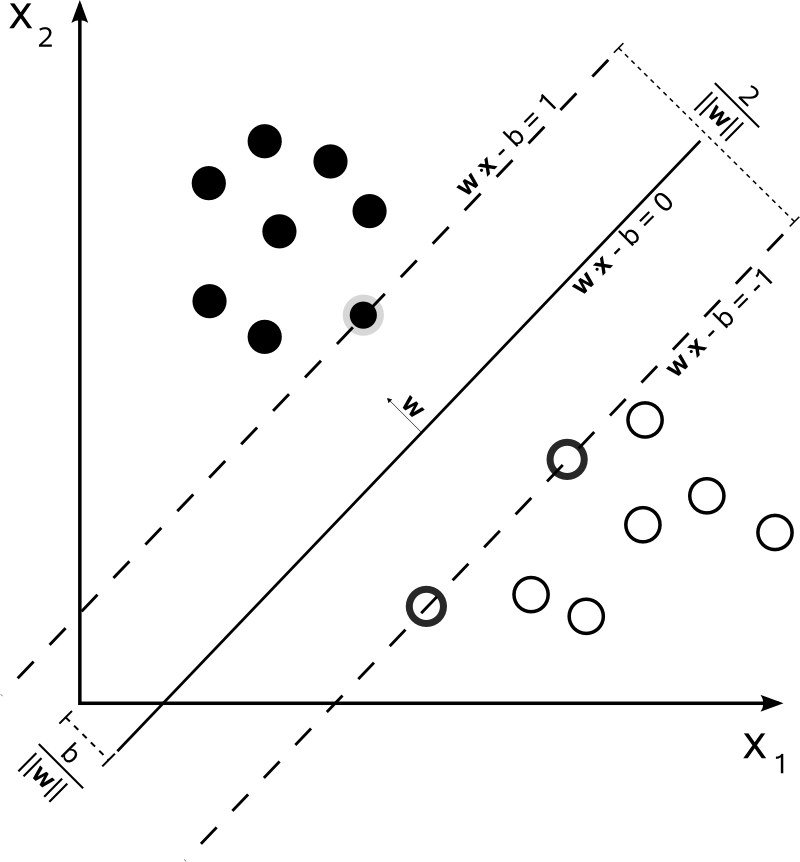
1 SVM(서포트 벡터 머신)
- 다른 방법들은 일반적으로 error를 최소화. 하지만 SVM은 마진(margin, 여백)을 최대화한다.
- 주어진 데이터를 이진 분류한다고 하면, 각 데이터를 고차원 공간에 매핑하고, 주어진 데이터가 어느 카테고리에 속하는지 판단하는 모델을 만들어 경계를 긋는다. => 이때 그 두 부류 사이의 여백이 가장 커지면(Maximum Margin) 잘 분류했다고 할 수 있다.
support vector는 두 카테고리의 데이터 세트에서 최외각에 있는 샘플들이고, 이를 토대로 margin을 구할 수 있다. margin은 support vector를 통해 구한 두 카테고리 사이의 거리.
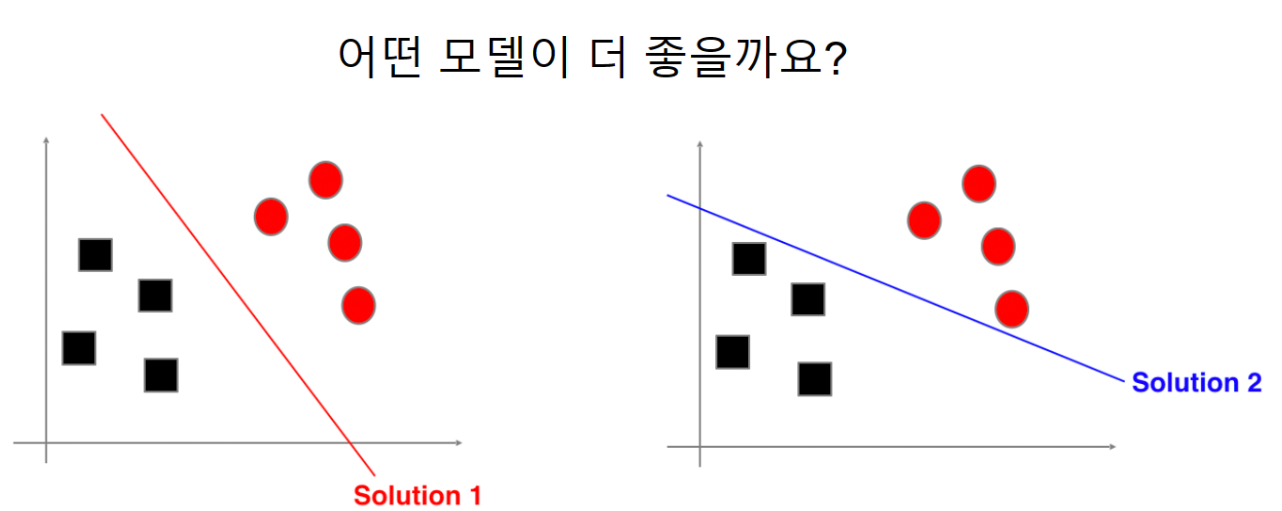
- 위와 같은 그림에서 왼쪽이 margin(여백)이 더 크므로 더 좋은 모델.
from sklearn.svm import SVC
svc = SVC()
svc.fit(X_train, y_train)
y_pred = svc.predict(X_test)
print(y_pred)
print(accuracy_score(y_test, y_pred)*100)SVC(): Support Vector Classifier 인스턴스 생성.accuracy_score()는 실제 레이블(y_test)와 예측 레이블(y_pred)를 비교해 정확도 평가. 정확도는 올바르게 예측된 데이터의 비율. 여기선 *100해서 퍼센트로.
2 SVM 다양하게 써보기
import warnings
warnings.filterwarnings(action='ignore')
# 한글 깨짐
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False
f_path = "C:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=f_path).get_name()
rc('font', family=font_name)
import pandas as pd
import numpy as np
df = pd.read_csv('../data/two_classes.csv')
df.tail()- 파일 들고온다.
df_positive = df[df['y'] > 0] #y가 1인 데이터만 추출
df_negative = df[df['y']==0] #y가 0인 데이터만 추출
import matplotlib.pyplot as plt
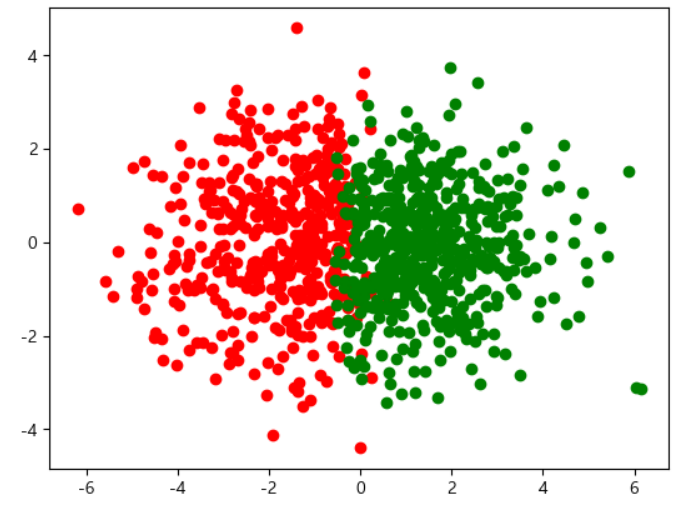
plt.scatter(df_positive['x1'], df_positive['x2'], color='r')
plt.scatter(df_negative['x1'], df_negative['x2'], color='g') - df에서 y가 1인 것과 0인 것을 구분해서 => 각각 r, g로 시각화. x1을 x축으로, x2를 y축으로.
from sklearn.svm import LinearSVC
X = df[['x1', 'x2']].to_numpy() #x1, x2를 입력 벡터로 한다
y = df['y']
svm_simple = LinearSVC(C=1, loss='hinge')
svm_simple.fit(X,y)
svm_simple.predict([[0.12, 0.56], [-4, 40], [0, 40], [5,20]])- X에서 x1, x2를 입력벡터로 해서 저장해서 numpy 배열로. y를 또.
LinearSVC: 선형 SVM 분류기를 구현한 클래스. SVM은 주어진 데이터를 선형으로 분리하는 hyperplane을 찾는 알고리즘.- C: 오차범위를 결정. 작으면 오차를 많이 허용, 크면 적게 허용. 기본값 1.
- loss: 손실함수 지정. 주로 hinge 손실 사용. squared_hinge가 기본 값.
- 그리고 fit.
- 그리고 predict로 값을 넣으면 1인지 0인지 예측값 배열이 반환된다.

2-1 시각화
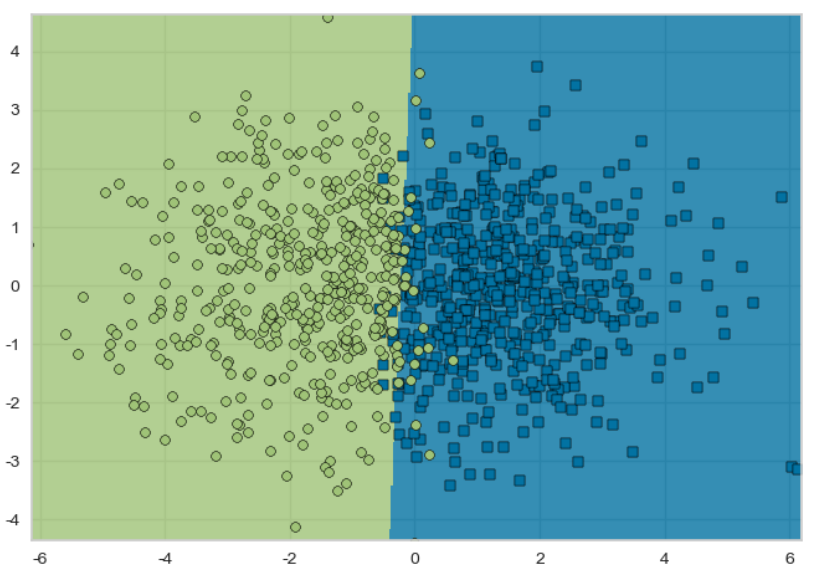
from yellowbrick.contrib.classifier import DecisionViz
viz = DecisionViz(svm_simple, title='linear SVM')
viz.fit(X, y)
viz.draw(X, y)DecisionViz: 분류기의 결정 경계를 시각화 하는 도구로, SVM 모델의 결정 경계 시각화 가능.
svm_simple은 분류기. title은 시각화에 사용될 제목.- fit은 분류기를 훈련, draw는 시각화해서 그린다.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
svm_std = Pipeline([ #파이프 라인으로 svm 생성
('std', StandardScaler()), #데이터 표준화 단계 포함
('lsvm', LinearSVC(C=1, loss='hinge')), #선형 SVM 분류기 포함
])
svm_std.fit(X, y)2-2 파이프라인 이용한 데이터 정제
Pipeline: 여러 단계를 순차적으로 처리할 수 있는 유틸리티. 각 단계는 튜플 형태로 주어지고, 첫 번째 요소는 단계의 이름, 두 번째는 변환기나 추정기 등 모델.- 즉 svm_std.fit을 하면 위의 std를 하고 lsvm을 순서대로 하는 모델이 된다.
- 즉, 똑같은 LinearSVC지만, 여기선 표준화를 해서 결과가 또 다르게 나온다.
2-3 다항 특정 변환을 통한 비선형 SVM 구현
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
svm_poly = Pipeline([ #파이프 라인으로 svm 생성
('std', StandardScaler()), #데이터 표준화 단계 포함
('poly_inputs', PolynomialFeatures(degree = 5)), #선형 SVM 분류기 포함
('lsmv', LinearSVC(C=0.01, loss='hinge'))
])
svm_poly.fit(X, y)
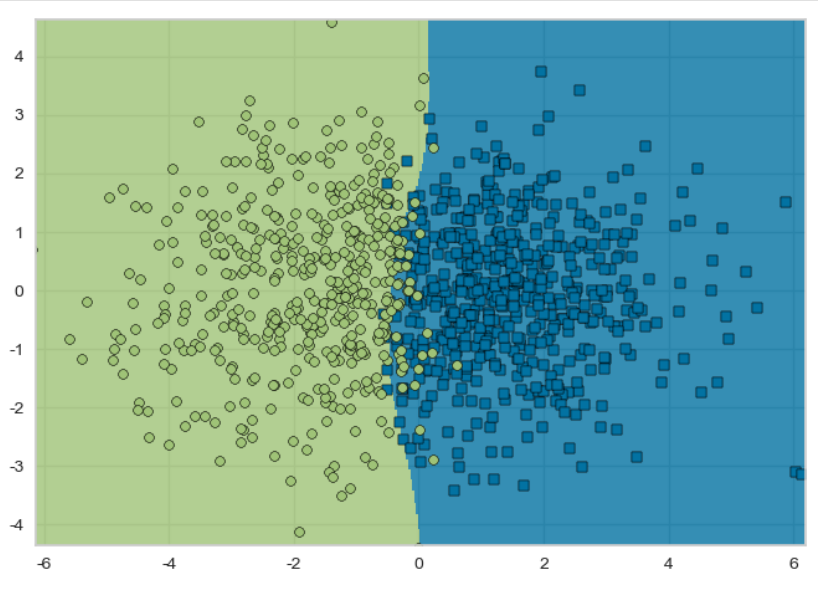
viz = DecisionViz(svm_poly, title='Standardization - SVM')
viz.fit(X, y)
viz.draw(X, y)PolynomialFeatures(degree = 5): PolynomialFeatures는 사이킷런의 변환기 중 하나로, 입력 특성을 다항식 특성으로 변환하는 역할.
예를 들어, 입력 feature가 x1, x2일 때 degree=2이면 1, x1, x2, x1^2, x2^2, x1*x2로 feature를 늘린다.- 파이프라인으로 표준화 => feature 늘리기 => linear svc로 해서 fit하고 시각화.
2-4 비선형 SVM 이용한 분류
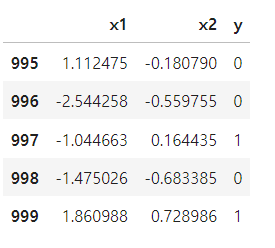
df = pd.read_csv('../data/twisted_data.csv')
df.tail()- 새 파일 들고 온다. 위와 비슷한 구조.
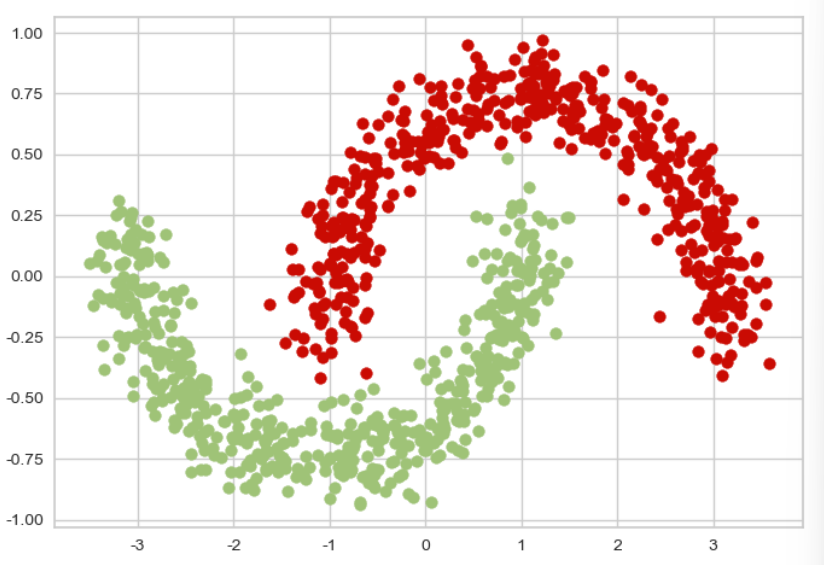
df_positive = df[df['y'] > 0] #y가 1인 데이터만 추출
df_negative = df[df['y']==0] #y가 0인 데이터만 추출
import matplotlib.pyplot as plt
plt.scatter(df_positive['x1'], df_positive['x2'], color='r')
plt.scatter(df_negative['x1'], df_negative['x2'], color='g') - 1과 0인 데이터를 각각 분리. => 그리고 시각화를 해보면 아래와 같이 나온다. 즉, 선형으로 plane으로는 분리가 안된다.
X = df[['x1', 'x2']].to_numpy() #x1, x2를 입력 벡터로 한다
y = df['y']
polynomial_svm_clf = Pipeline([ #파이프 라인으로 svm 생성
('scalar', StandardScaler()), #데이터 표준화 단계 포함
('poly_features', PolynomialFeatures(degree = 5)), #선형 SVM 분류기 포함
('svm_clf', LinearSVC(C=1, loss='hinge'))
])
polynomial_svm_clf.fit(X, y)
viz = DecisionViz(polynomial_svm_clf, title='polynomial feature SVM')
viz.fit(X, y)
viz.draw(X, y)- 위와 같다. 위는 선형으로도 구분되는 걸 좀 더 섬세하게 구분하기 위해 쓴 경우고, 이 경우는 아예 비선형에 적용.

일본에서 일하는 게임 기획자. 시시해서 죽어버리지 않게, 재밌고 의미 있는 컨텐츠에 관심 있습니다. 그 도구로 데이터, AI도 찝적댑니다.