1 Decision Tree 결정트리
- 분류와 회귀 문제에 사용되는 머신러닝 알고리즘.
- 데이터를 분석해 데이터 사이 패턴을 학습, 데이터를 가장 잘 구분할 수 있는 특정 기준(질문)에 따라 데이터를 구분하는 걸 반복하는 모델. 한 번의 분기 때마다 변수 영역을 2개로 분리.
분할 기준은 정보 이득(Information Gain), 지니 불순도(Gini Impurity), 엔트로피(Entropy) 등이 사용. 목표 가능한 한 순수한 subset을 생성하는 것으로, 최종적으로 모든 데이터 포인트가 정화한 분류에 도달할 때까지 반복.
결정 트리의 질문이나 정답을 담은 네모 상자를 노드라고 한다. 처음의 분류 기준을 ROot Node, 마지막 노드를 Terminal Node 혹은 Leaf Node, 그 사이의 노드를 Internal Node라고 한다. 노드 사이의 연결선을 Branch라고 한다. - 장점: 사람이 이해하기 쉽고, 정규화나 스케일링 등 전처리 필요 없고, 수치형 및 범주형 데이터 모두 처리 가능
- 단점: 트레이닝 데이터에 과적합되기 쉽다(pruning(가지치기) 필요), 작은 데이터 변화에도 트리 구조 크게 변할 수 있어 불안정.
1-1 데이터 준비
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine_csv_data')
wine.info()
wine.describe()
wine.info()
data = wine[['alcohol','sugar','pH']].to_numpy()
target = wine['class'].to_numpy()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data,target,test_size = 0.2, random_state = 42)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
train_scaled = sc.fit_transform(X_train)
test_scaled = sc.transform(X_test)- 데이터 불러와서 => 확인 => split => SS로 표준화
1-2 모델 학습하고 시각화
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state = 42)
dt.fit(train_scaled,y_train)
print(dt.score(train_scaled,y_train))
print(dt.score(test_scaled,y_test))
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize =(10,7))
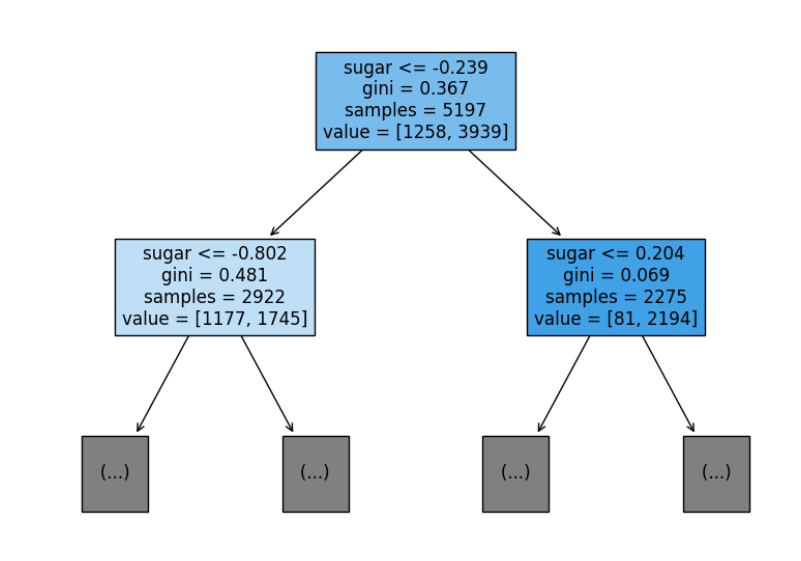
plot_tree(dt, max_depth=1, filled=True,feature_names=['alcohol','sugar','pH'])
plt.show()DecisionTreeClassifier(): 결정 트리 분류 모델 생성. => fit => train set과 test set 을 각각 score로 정확도 출력.plot_tree: 결정 트리 시각화.
- dt라는 인스턴스를 시각화.
- max_depth는 최대 깊이 제한.
- filled=True는 노드 분류에 따라 색을 다르게 해서 시각적으로 구분.
- feature_names는 각 특성의 이름을 리스트로 전달. => 실제로 alcoho, sugar, pH는 칼럼 명이다. 그리고 시각화한 결과를 보면 sugar를 기준으로 나눠져있다. 여기서 depth가 늘어나면 다른 것
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(max_depth=7,random_state = 42)
dt.fit(train_scaled,y_train)
print(dt.score(train_scaled,y_train))
print(dt.score(test_scaled,y_test))
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize =(20,10))
plot_tree(dt, filled=True,feature_names=['alcohol','sugar','pH'])
plt.show()- 위와 같은데 깊이만 7층으로.
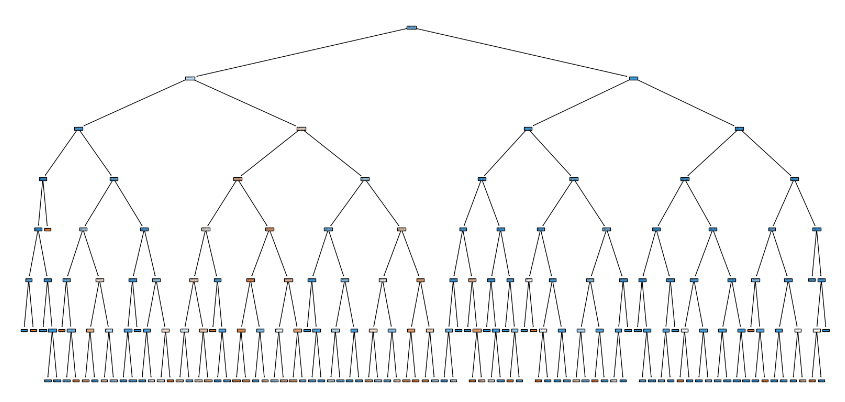
- 일반적으로 max_depth가 얕으면 과소적합된다. 여기서는 max_depth가 1일 때, 모델이 너무 단순해서 훈련 데이터에 있는 패턴을 대부분 놓친 과소적합. => 훈련 세트만 높게 나온다.
반면 max_depth = 7일 때는, train set은 줄어들었지만, test set은 아주 조금 올라갔다.
dt.feature_importances_: 결정 트리에서 각 특성이 목표 변수를 예측하는데 얼마나 중요한지를 나타내는 값을 제공. 0~1이고 모든 특성의 합은 1. => 결정 트리에서 특성 중요도 계산할 때는, 특성을 사용해 데이터를 분할했을 때 얻는 순도(purity) 증가, 또는 불확실성(uncertainty) 감소의 총량을 측정해서, 더 많은 정보 이득을 제공하거나 더 큰 지니 감소를 가져오면 그 특성은 더 중요.
2 교차 검증으로 최적의 하이퍼 파라미터 찾기
2-1 GridSearchCV로 교차검증해서 Decision Tree의 최적의 max_depth 찾기
from sklearn.model_selection import GridSearchCV
param_grid = {'max_depth': range(1, 10)}
# GridSearchCV 객체 생성
grid_search = GridSearchCV(dt, param_grid, cv=5)
# 그리드 서치 수행
grid_search.fit(X_train, y_train)
# 결과 출력
print(f"최적의 파라미터: {grid_search.best_params_}")
print(f"최고 교차 검증 점수: {grid_search.best_score_}")- param_grid는 탐색할 max_depth값의 범위를 지정하는 딕셔너리.
GridSearchCV(dt, param_grid, cv=5): 하이퍼파라미터 튜닝하는 메서드.- dt, 위에 만든 결정 트리 분류기
param_grid는 탐색할 하이퍼파라미터를 딕셔너리로 지정.cv: 교차 검증을 수행할 때 데이터를 분할할 전략 지정. 정수면 kFold로. 교차 검증은 모델의 일반화 능력을 평가하는 방법으로, 5겹이면 훈련 데이터 세트를 무작위로 5개의 동일한 크기의 subset(겹, 또는 fold)로 분할, 1개를 test set으로 나머지 4개를 train set으로 검증함.scoring: 모델 성능 평가에 사용되는 지표 지정. accuracy, precision, recall, f1 등.verbose: 실행 과정 중 출력되는 메시지 상세도 지정. 숫자 입력하면 출력 레벨 증가하고, 0이면 출력 없다.
grid_search.fit(): 훈련 데이터에 대해 그리드 서치 수행. => param_grid에 지정된 모든 매개변수 조합에 대해 모델을 훈련, 지정된 교차 검증 전략에 따라 모델의 성능 평가.grid_search.best_params_,grid_search.best_score_: 각각 최적의 파라미터와 최고 교차 검증 점수 출력.

2-2 validation_curve로 최적의 max_depth 범위 찾기
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import validation_curve
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
# 데이터 불러오기
data, target = load_digits(return_X_y=True)
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(data, target, random_state=42)
# 하이퍼파라미터 범위 설정 (1에서 10까지의 트리 깊이)
param_range = np.arange(1, 11)
# 검증 곡선 계산
train_scores, test_scores = validation_curve(
DecisionTreeClassifier(), X_train, y_train,
param_name="max_depth", param_range=param_range,
cv=5, scoring="accuracy", n_jobs=1)
# 평균과 표준 편차 계산
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)load_digits: 손으로 쓴 숫자 0~9의 이미지 데이터를 불러온다.return_X_y=True는 함수가 데이터(X)와 레이블(y)를 분리해서 반환하도록 지시. 각각의 데이터는 8X8 픽셀 크기의 이미지로 구성.
여기서 data의 하나하나는 (64, )의 1차원 배열로 각각은 float, 그게 총 1797개 있다. target은 그 각각이 실제로 어떤 숫자인지 1797개.- 그 데이터를 split하고, param_range에 1~10까지 트리 깊이 설정.
validation_curve(): 주어진 하이퍼파라미터의 범위에 따라 모델의 성능 변화를 평가하기 위해 사용.- DecisionTreeClassifier(): 사용할 분류 모델. 결정 트리 모델에 다양한 max_depth 값에 대해 평가.
- X_train, y_train은 모델 훈련하는데 사용되는 데이터와 레이블.
- param_name= 으로 하이퍼 파라미터 이름을 문자열로 입력.모델에 따라 다르고, DecisionTreeClassifier에 대해 사용할 수 있는 하이퍼파라미터는 'max_depth', 'min_samples_split', 'min_samples_leaf', 'min_weight_fraction_leaf', 'max_features', 'max_leaf_nodes', 'min_impurity_decrease'.
- param_range는, 위에서 정의한 param_range로 1~10
- cv=5는 교차 검증 횟수
- scoring="accuracy": 모델 성능 평가 기준 지정.
- 여기서 'precision', 'recall', 'f1', 'roc_auc' 등이 분류 문제에 사용된다.
회귀 문제에서는 'neg_mean_squared_error', 'neg_mean_absolute_error', 'r2' 등이 사용.
- 여기서 'precision', 'recall', 'f1', 'roc_auc' 등이 분류 문제에 사용된다.
- n_job=1은, 동시에 실행할 작업의 수. n_jobs=1은 한 번에 하나의 CPU 코어만 사용. -1로 설정하면 모든 프로세서 사용해 병렬 처리 수행.
- 위의 validation_curve로 나온 결과값들은 아래와 같다.
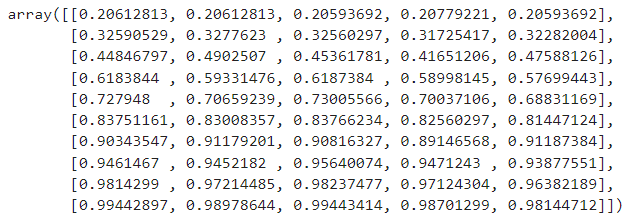
- 여기서 1개의 행에 들어있는 건 5-fold 한 각각의 결과. => np.mean과 np.std에서 axis=1로 하면, 각 행의 평균을 계산. axis=0이면 각 열별로.
# 결과 시각화
plt.title("Validation Curve with Decision Tree")
plt.xlabel("Depth of tree")
plt.ylabel("Score")
plt.ylim(0.0, 1.1)
lw = 2
plt.plot(param_range, train_scores_mean, label="Training score",
color="darkorange", lw=lw)
plt.fill_between(param_range, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.2,
color="darkorange", lw=lw)
plt.plot(param_range, test_scores_mean, label="Cross-validation score",
color="navy", lw=lw)
plt.fill_between(param_range, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.2,
color="navy", lw=lw)
plt.legend(loc="best")
plt.show()- 처음에 제목과 축 이름 설정.
plt.ylim(0.0, 1.1)로 축으 ㅣ범위를 0.0에서 1.1까지 설정. 정확도 점수가 0~1이므로. lw = 2: 선의 두께를 2로 변수 설정.plt.plot(param_range, train_scores_mean, label="Training score", color="darkorange", lw=lw): x축은 param_range 1~10으로, train_scores_mean은 validation_curve로 max_depth를 10개로 바꿔가며 나온 5-fold cross validation의 score의 평균값. 레이블 지정하고, 색 지정하고, 굵기 지정하고.plt.fill_between(param_range, train_scores_mean - train_scores_std,train_scores_mean + train_scores_std, alpha=0.2,color="darkorange", lw=lw): 두 개의 선 사이의 영역을 색칠. 주로 데이터의 변동성이나 불확실성을 시각적으로 표현할 때 사용. x축은 para_range, y축의 범위를 mean-std, mean+std로 표기. alpha=0.2로 투명도 지정, color로 색깔, lw=lw로 선 굵기.
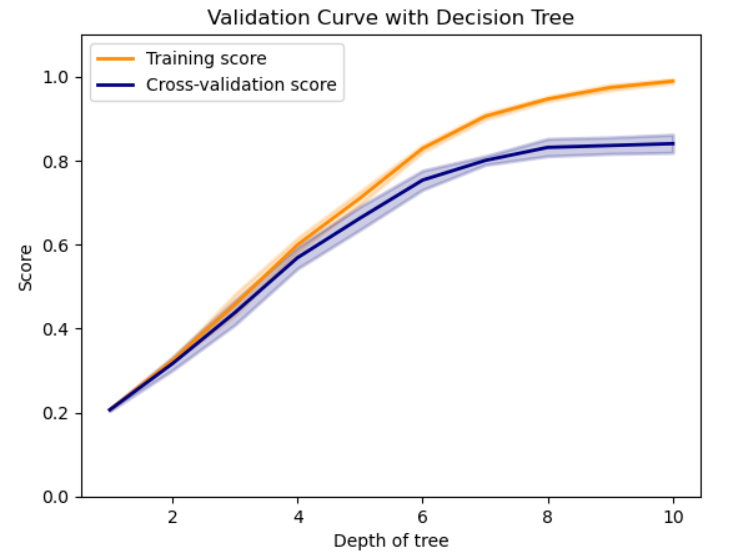
- GridSearchCV, validation_curve: 둘 다 머신러닝 성능 평가하고 최적의 하이퍼파라미터 찾기 위해 사용.
- GridSearchCV: 사용자가 지정한 여러 하이퍼파라미터의 조합에 대해 교차 검증 수행, 가장 좋은 성능 내는 하이퍼파라미터 조합 찾는다. => 비용이 매우 크다.
- validation_curve: 단일 하이퍼파라미터에 다양한 값 시도해보면서 모델 성능 변화 평가.
2-3 검증 세트(Validation Set)
- 훈련 세트에서 분리시켜, 모델이 학습 과정에 본 적이 없는 새로운 데이터에 대한 성능을 검증
- 즉 기존에 trian => test에서
train => validation으로 하이퍼 파라미터 튜닝을 한다. => 그리고 test set으로 검증.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = \
train_test_split(data, target, test_size = 0.2, random_state=42)
#위의 8로 나눈 train_input을 다시 한 번
sub_input, val_input, sub_target, val_target = train_test_split(
train_input, train_target, test_size = 0.2, random_state=42)
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state = 42)
dt.fit(sub_input, sub_target)- 이렇게 2차례 나눈다. => 그리고 sub로 만든 모델의 적절한 하이퍼파라미터를 val로 찾고 => 그걸로 test에 성능 확인
2-4 K-fold 교차 검증(Cross validation)
- 모델의 일반화 성능을 더 정확하고 신뢰성 있게 평가한다. 데이터셋이 작을 때 유효. => 데이터셋을 여러 부분으로 나누고, 이들 중 일부를 학습에 나머지를 테스트에 사용하는 것으로 여러 번 반복.
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)
print(np.mean(scores['test_score']))cross_validate: 주어진 추정기 dt(여기선 DecisionTreeClassifier 인스턴스), 그리고 주어진 데이터, 타겟 레이블을 넣으면, 교차 검증 성능을 평가. => 딕셔너리로 여러 평가 지표를 반환.
- default로 5fold 교차 검증 수행. cv로 조정 가능. 아래의 값들을 5개씩 반환한다.
- fit_time: 각 폴드에 대한 학습 시간.
- score_time: 모델을 평가하는데 걸린 시간.
- test_score: 각 폴드에서의 테스트 스코어.

- np.mean으로 테스트 스코어의 평균을 반환.
from sklearn.model_selection import StratifiedKFold
scores = cross_validate(dt, train_input, train_target, cv=StratifiedKFold())
print(np.mean(scores['test_score']))
splitter = StratifiedKFold(n_splits = 10, shuffle=True, random_state=42)
scores = cross_validate(dt, train_input, train_target, cv=splitter)
print(np.mean(scores['test_score']))StartifiedKFold(): 교차 검증에서 각 폴드가 원본 데이터셋의 클래스 비율을 대표하도록 유지하는 방법. => 클래스의 샘플 수가 균등하지 않을 때 사용. 위에서 cv에 이것만 지정한 게 차이고, 나머지는 똑같다.n_splits=: 데이터를 몇 개의 폴드로 넣을지 지정. default는 5. 10으로 넣으면 10fold.shuffle=True: 교차 검증 전에 데이터를 무작위로 섞는다. 데이터셋의 순서에 따른 편향 방지.
2-5 하이퍼파라미터 튜닝
- 하이퍼파라미터 튜닝(Hyperparameter tunning): 하이퍼 파라미터들의 최적 값을 찾는 과정.
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease': [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
dt = gs.best_estimator_
print(dt.score(train_input, train_target))
print(gs.best_params_)- params는 탐색할 하이퍼파라미터와 그 값들을 지정한 딕셔너리로,
GridSearchCV인스턴스를 생성할 때 집어넣는다. - 여기서는
min_impurity_decrease는 결정 트리 모델에서 노드 분할하는 데 사용되는 불순도 감소의 최소값. 여기서 지정한 값보다 작은 불순도 감소를 가진 노드는 분할되지 않고 리프 노드가 된다. 기본값은 0, 즉 불순도 감소 고려하지 않고 모든 노드 분할 허용. => min_impurity_decrease 높이면 더 간단한 모델이 되고 과적합 위험 줄인다. - 이제 GridSearchCV로 DecisionTreeClassifier에 params로 입력한 값들을 넣고, 여기서 n_jobs=-1로 병렬 처리를 한다.
gs.fit하면 모델이 나온다.gs.best_estimator_를 하면 가장 좋은 측정기가 된다. =>dt.score()로 그 점수를.gs.best_params_를 하면 가장 좋은 점수가 나온다. 이 경우 0.0001
#0.0001일 때 가장 좋은 점수(인덱스0)
# params 5개 * 5겹이므로 모델 25개 만들어진다
print(gs.cv_results_['mean_test_score'])
best_index = np.argmax(gs.cv_results_['mean_test_score'])
print(best_index)
print(gs.cv_results_['params'][best_index])gs.cv_results_: 교차 검증 과정에서 각 하이퍼파라미터 조합에 대한 다양한 정보를 포함. 여기서는 params가 5개, 5-fold이기 때문에 그 조합으로 25개가 나온다. 아래와 같은 모양으로, mean_fit_time, std_fit_time, mean_score_time, std_score_time, param_min_samples_split, param_min_impurity_decrease, 등이 key값으로 있다.
- 여기서 ['mean_test_score']로 하면 각각의 params값에 대한 'mean_test_score'가 나오고 그 중에 인덱스 0이 0.0001일 때 점수. 확인해보면 가장 좋다.

np.argmax(gs.cv_results_['mean_test_score']): gs.cvresults['mean_test_score']에서 가장 큰 값을 가지는 원소의 인덱스 찾는다. => best index라는 변수에 넣는다.
그걸 이용해서 cvresults['params']에 인덱싱 해서, 가장 좋은 parameter가 뭔지 찾는다.
params = {'min_impurity_decrease': np.arange(0.0001, 0.001, 0.0001), #9개
'max_depth': range(5, 20, 1), #15개
'min_samples_split': range(2, 100, 10) #10개
}
#9 * 15 * 10 * 5폴드 = 6750
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
print(gs.best_params_)
print(np.max(gs.cv_results_['mean_test_score']))- params로 9개, 15개, 10개를 넣고 => 그 각각을 곱한 경우의 수에 *5로 6750개의 경우의 수가 나온다.
- 똑같이 gs로 해서 가장 좋은 parameter 조합과, 그로 인한 값을 np.max로 들고 온다.
2-6 랜덤 서치
- 하이퍼파라미터 튜닝을 위한 탐색법 중 하나. 주어진 하이퍼파라미터 공간에서 무작위로 하이퍼파라미터 선택해 여러 번 평가해서 찾는다. => 하이퍼파라미터 공간이 매우 크거나, 계산 비용이 높을 때 유용.
from scipy.stasts import uniform, randint
rgen = randint(0, 10)
rgen.rvs(10)
np.unique(rge.rvs(1000), return_counts = True)
ugen = uniform(0, 1)
ugen.rvs(10)randint(0, 10): 0부터 9까지의 정수 중에서 랜덤하게 하나의 숫자를 선택.rvs(10): 이런 랜덤한 숫자를 10번 생성해 배열로.uniform(0, 1): 0부터 1사이의 실수 중에 랜덤하게 하나의 숫자를 선택.
params = {'min_impurity_decrease': uniform(0.0001, 0.001),
'max_depth': randint(20,50),
'min_samples_split': randint(2, 25),
'min_samples_leaf' : randint(1, 25),
}
from sklearn.model_selection import RandomizedSearchCV
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42),
params, n_iter = 100, n_jobs = -1, random_state=42)
gs.fit(train_input, train_target)
print(gs.best_params_)
print(np.max(gs.cv_results_['mean_test_score']))
dt = gs.best_estimator_
print(dt.score(test_input, test_target))- params에 탐색할 하이퍼파라미터와 그들의 탐색 범위를 각각 지정.
RandomizedSearchCV: 랜덤 서치를 수행하기 위한 인스턴스. 첫 인자로 기본 모델(DecisionTreeClassifier)을 전달, 두 번째 인자로 params, n_iter로 랜덤 탐색을 반복할 횟수 지정.- np.max와 gs.bestestimat-r.score()의 결과가 다르다. 이유는, 전자는 교차 검증으로 찾은 최고의 검증 세트. 후자는 최적의 파라미터로 구성된 모델을 테스트 세트에 대해 평가한 값. 즉, 전자는 train_set에 대한 값이고, 후자는 test set에 대한 값.

일본에서 일하는 게임 기획자. 시시해서 죽어버리지 않게, 재밌고 의미 있는 컨텐츠에 관심 있습니다. 그 도구로 데이터, AI도 찝적댑니다.