0 설정
* KoNLPy 패키지 설치
1. JDK (Java SE Downloads)
- abit.ly/easypy_101(.msi)
- 자신의 os에 맞게 인스톨
2. KoNLPy 의존성 패키지 설치하기
- pip install jpype1
3. KoNLPy 설치
- pip install konlpy
3. 워드 클라우드
- pip install wordcloud
4. gensim 설치
- pip install gensim
-->안되면
pip install -U setuptools
pip install gensim
5 4. (C:\Users\A\Anaconda3) C:\Users\A\Anaconda3>python
>>> import nltk
>>> nltk.download()
--> stopwords & punkt duble click download1 TF-IDF
- TF-IDF(Term Frequency-Inverse Document Frequency): 정보 검색과 텍스트 마이닝에서 널리 사용되는 특성 추출 기법. 각 단어의 중요성을 수치적으로 평가해서 텍스트 특징 나타낸다.
- TF는 하나의 문서 내의 단어의 빈도 => 특정 단어가 문서 내에 자주 등장할수록 해당 단어의 TF가 커진다.
- IDF는 전체 문서에서 특정 단서의 빈도 => 특정 단어가 전체 문서 집합에서 많이 나타날 수록 IDF 작아진다.
- TF-IDF는 TF와 IDF의 곱이다. 즉, 해당 문서에는 그 단어가 자주 나오지만, 전체 문서에서는 덜 나오는 단어가 중요한 단어다.
- 일반적으로 TF-IDF는 TF를 로그 스케일로 변환한 후, IDF를 곱하여 사용.

import warnings
warnings.filterwarnings(action='ignore')
import pandas as pd
#영화 반응에 대한 파일
train_df = pd.read_csv('../Data/ratings_train.txt', sep='\t')
train_df.head(5)
#데이터 확인 => document에 5개 null 발견
print(train_df['label'].value_counts( ))
print(train_df.info())
import re
train_df = train_df.fillna(' ') #5건 공백 변경
train_df['document'] = train_df['document'].apply(
lambda x : re.sub(r"\d+", " ", x) ) #x는 document, 숫자를 공백으로 변경
#test 데이터도 똑같이
test_df = pd.read_csv('../Data/ratings_test.txt', sep='\t')
test_df = test_df.fillna(' ')
test_df['document'] = test_df['document'].apply(
lambda x : re.sub(r"\d+", " ", x) )
# id 칼럼 삭제 수행
test_df.drop('id', axis=1, inplace=True)
train_df.drop('id', axis=1, inplace=True)- 데이터를 확인 후 5개 null 발견하고 => 먼저 fillna(' ')로 null을 ' '으로 바꾸고 => regular expression으로 lambda x : re.sub(r"\d+", " ", x)를 통해 내부의 숫자를 모두 공백으로 바꾼다.
re.sub()은 문자열에서 특정 패턴을 찾아 다른 문자열로 대체하는 메서드.
r"\d+"는 숫자, " "는 숫자를 대체할 문자열, 'x' 대상 문자열로 데이터프레임의 각 행의 원소가 들어간다.
=> 이를 apply로 데이터프레임 각 행에 적용.- 이를 test 데이터에도 똑같이 적용한다.
- id 칼럼 수정
from konlpy.tag import Twitter
twitter = Twitter()
def tw_tokenizer(text):
#입력 들어온 text를 형태소 단어로 토큰화하여 list 객체로 반환
tokens_ko = twitter.morphs(text)
return tokens_ko
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
tfidf_vect = TfidfVectorizer(tokenizer=tw_tokenizer, ngram_range=(1, 2), min_df=3, max_df=0.9)
tfidf_vect.fit(train_df['document'])
tfidf_matrix_train = tfidf_vect.transform(train_df['document'])- 한국어 텍스트 형태소 단위로 토큰화하는 게 목표.
- konlpy 라이브러리의
Twitter클래스 생성. =>twitter.morphs(text): 한국어 텍스트를 형태소 단위로 분리해서 리스트로 반환하는 메서드.
예를 들면 tw_tokenizer('오늘은 기분이 좋습니다') => ['오늘', '은', '기분', '이', '좋습니다'] TfidfVectorizer: 문서 집합을 TF-IDF 특성 행렬로 변환하는 클래스.tokenizer: 단어를 토큰화하 데 사용하는 함수 지정.ngram_range: 텍스트를 토큰으로 나누는 방법을 제어. ngram은 연속된 단어나 문자의 그룹. The apple is yummy이면 (1, 1)이면 The, apple, is, yummy 로 나누고 (1, 2)면 The, apple, is, yummy, The apple, apple is, is yummy로 나눈다. 일반적으로(최소, 최대)의 형태로 지정한다. => 작은 ngram 범위는 더 많은 특성을 생성하지만, 훈련 데이터 부족할 떈 과적합 유발.min_df: 생성된 단어장(vocabulary)에 포함되기 위한 최소 문서 빈도 수 지정. 3개 이하의 단어는 무시.max_df: 마찬가지로 생성된 단어장에 포함되기 위한 문서지만, 여기선 최대 문서 빈도 수 지정. 0.9이므로 전체 문서의 90% 이상에서 나타나는 단어는 무시.
fitTF-IDF 변환기에 주어진 문서 집합에 맞추는 메서드. => transform
#Logistic Regression 이용 감성 분석 Classification 수행
lg_clf = LogisticRegression(random_state=0)
#Parameter C 최적화 - GridSearchCV
params = {'C': [1, 3.5, 4.5, 5.5, 10]}
grid_cv = GridSearchCV(lg_clf, param_grid = params, cv=3, scoring='accuracy', verbose=1)
grid_cv.fit(tfidf_matrix_train, train_df['label'])
print(grid_cv.best_params_, round(grid_cv.best_score_, 4))Logistic Regression으로 감성 분석 분류 수행하기 위해 인스턴스 생성.
여기서C는 로지스틱 회귀 분석 모델의 정규화 매개변수. C값이 작을수록 모델 일반화 된다.GridSearchCV로 하이퍼파라미터 조합 교차 검증한다.- 처음 매개변수는, 최적화하려는 모델 객체.
param_grid는 탐색할 하이퍼파라미터를 딕셔너리로 지정.cv: 교차 검증을 수행할 때 데이터를 분할할 전략 지정. 정수면 kFold로.scoring: 모델 성능 평가에 사용되는 지표 지정. accuracy, precision, recall, f1 등.verbose: 실행 과정 중 출력되는 메시지 상세도 지정. 숫자 입력하면 출력 레벨 증가하고, 0이면 출력 없다.
- fit으로, tfidf_matrix_train은 위에서 TF-IDF로 변환시킨 값들. 그리고 train_df['label']는 긍정 부정에 대한 값들. 0이 부정, 1이 긍정적 평.
.best_params_는 최적의 하이퍼파라미터 조합..best_score_는 이 조합에 대한 교차 검증 평균 정확도(accuracy)
from sklearn.metrics import accuracy_score
#학습 데이터를 적용한 TfidVectorizer를 이용
#테스트 데이터를 TF-IDF 값으로 Feature 변환
tfidf_matrix_test = tfidf_vect.transform(test_df['document'])
#최적 파라미터로 학습된 classifier를 그대로 이용
best_estimator = grid_cv.best_estimator_
preds = best_estimator.predict(tfidf_matrix_test)
print('Logistic Regression 정확도: ', accuracy_score(test_df['label'], preds))- tfidf_matrix_test로 test data도 똑같이 transform.
- bestestimator는 로 위의 best_estimator를 저장
- best_estimator를 이용해서 predict, test를 사용.
accuracy_score()는 진짜 데이터, 예측 데이터로 => accuracy 점수를 낸다.- 즉, 여기까지 큰 그림을 보면 => 데이터 토큰화 => TF-IDF 모델로 train set 넣어서 fit, transform => 로지스틱 회귀 모델에 GridSearchCV로 최적의 파라미터 찾기(best_estimator라는 모델로) => grid_cv에 train 데이터를 TF-IDF 적용한 데이터를 넣어서 fit => test set을 TF-IDF로 바꾸고 => best_estimator에 test set 넣어서 predict해서 최종 모델.
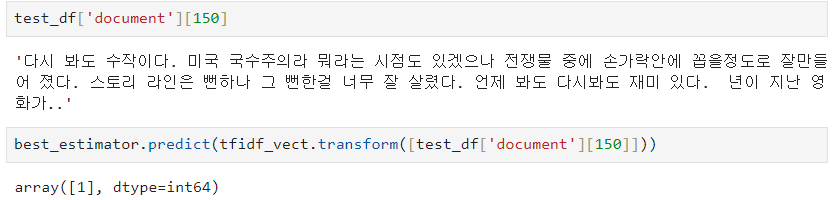
- 위의 내용을, 전환해보면 1. 즉, 긍정이 나온다.
if best_estimator.predict(tfidf_vect.transform([text])) == 0:
print(f'"{text}" -> 부정일 가능성이 {round(best_estimator.predict_proba(tfidf_vect.transform([text]))[0][0],2)}% 입니다.')
else:
print(f'"{text}" -> 긍정일 가능성이 {round(best_estimator.predict_proba(tfidf_vect.transform([text]))[0][1],2)}% 입니다.')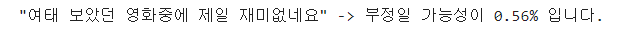
- 텍스트를 입력하면, %로 대답해주도록.
- 여기서 인덱싱이 [0][0]이 되어 있는 이유는 직접 확인해보면 됨.

일본에서 일하는 게임 기획자. 시시해서 죽어버리지 않게, 재밌고 의미 있는 컨텐츠에 관심 있습니다. 그 도구로 데이터, AI도 찝적댑니다.