0. Abstract
- 3가지 LLM 모델에 대해 실험한 결과 CoT Prompt 기술이 다양한 arithmetic, commonsense, symbolic reasoning과 같은 작업에서 성능을 향상 시킴.
- CoT를 사용한 PaLM 540B 모델은 math word problem에 대한 GSM8K 벤치마크에서 fine-tuning된 GPT-3보다 성능이 좋게 나옴.
- PaLM 540B : 구글에서 개발한 5400억 개의 파라미터를 가진 모델
- GSM8K : 8천 500개의 수준 높은 초등학교 수학 문제로 구성된 데이터 셋
1. Introduction
- language models은 Scaling up을 통해 성능이 향상되었지만, arithmetic, commonsense, symbolic reasoning과 같은 task에서 좋은 성능을 보여주기에 충분하지 못함.
- 2가지 아이디어에서 영감을 얻은 간단한 방법을 통해 LLM 모델의 추론 능력을 어떻게 향상 시킬지 탐구.
- arithmetic reasoning 기술은 최종 답안으로 이어지는 natural language rationales를 생성함으로써 이점을 얻을 수 있음.
- 기존의 자연어 중간 단계 생성 모델 개발을 위한 2가지 방법
- 처음부터 학습
- 사전 학습된 모델을 fine-tuning
- neuro-symbolic methods
- 자연어를 대신하여 formal language를 사용
- 기존의 자연어 중간 단계 생성 모델 개발을 위한 2가지 방법
- LLM 은 프롬프팅을 통해 in-context few shot learning을 진행하여 fine-tuning 대체할 수 있음.
- arithmetic reasoning 기술은 최종 답안으로 이어지는 natural language rationales를 생성함으로써 이점을 얻을 수 있음.
- 기존 접근 방식의 한계점
- rationale-augmented training 및 fine-tuning 방법
- 고품질의 rationales로 구성된 large set 생성은 비용이 많이 듬.
- 전통적으로 few-shot prompting 방법.
- 추론 능력이 필요한 작업에서 성능 저조.
- 언어 모델 규모가 커져도 성능이 크게 향상되지 않음(Rae et al.,2021)
- rationale-augmented training 및 fine-tuning 방법
- 논문의 제안
- 두 아이디어의 강점을 결합하여 한계를 극복
- 입력, 사고 과정, 출력의 세 가지 요소로 구성된 프롬프트 사용.
- CoT(chain-of-thought prompting)
- 중간 자연어 추론 단계를 포함하여 최종 출력으로 이어지는 과정.
- example Prompting
- Prompt 기반 접근법의 중요성
- large training dataset이 필요 없음
- single model checkpoint로도 loss of generality 없이 많은 task를 수행할 수 있음
- LLM이 task에 대한 자연어 데이터로 된 적은 예제를 통해 학습할 수 있음
2. Chain-of-Thought Prompting
- 문제 해결 사고 과정
- 복잡한 추론 작업을 중간 단계로 나누어 각각을 해결.
- 유사한 사고 과정을 언어 모델에 도입
- Chain-of-thought
- 문제의 최종 답으로 이어지는 일관된 중간 추론 단계
- 충분히 큰 언어 모델이 사고 과정 추론 예시를 통해 학습 가능
- CoT Prompting의 매력적인 속성
- 중간 단계 분해
- 여러 단계의 문제를 중간 단계로 분해할 수 있음
- 더 많은 추론 단계가 필요한 문제에 추가 계산을 할당 할 수 있음.
- 모델 행동의 해석 가능성
- 특정 답에 도달한 방법을 시사.
- 추론 경로의 디버깅 기회 제공.
- 다양한 작업에 적용 가능
- 수학 문제, 상식 추론, 기호 조작 등.
- 언어를 통한 모든 작업에 적용 가능.
- 상용 언어 모델에서의 용이한 유도
- 사고 과정 시퀀스를 포함시키기만 하면 됨.
- 중간 단계 분해
3. Arithmetic Reasoning
3.1 실험 설정
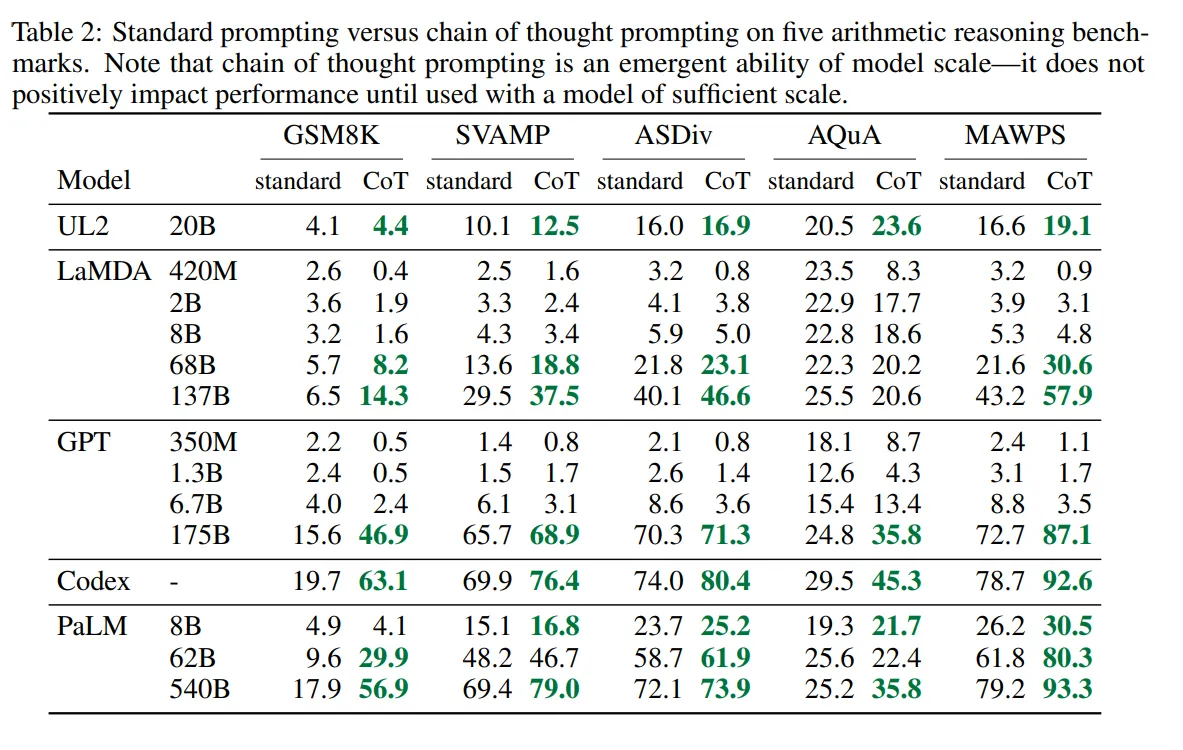
Benchmarks.
- GSM8K : math word problems
- SVAMP : math word problem with varying structures
- ASDiv : diverse math word problems
- AQuA : algebraic word problems
- MAWPS : online repository of Math Word Problems
Standard prompting
- few-shot prompting을 고려
- 언어 모델은 test-time example에 대한 예측을 출려하기 전에 in-context exemplars of input-output pairs를 제공 받음.
Chain-of-thought prompting
- few-shot prompt의 각 예시에 연관된 답에 대한 chain-of-thought을 추가하는 방식을 제안.
Language model
- 5가지 대형 언어 모델을 평가
- GPT-3
- text-ada-001(350M), text-babbage-001(1.3B), text-curie-001(6.7B), text-davinci-002(175B)를 사용했으며, 이는 InstructGPT모델에 해당된다고 가정
- LaMDA
- 422M, 2B, 8B, 68B, 137B 파라미터 모델이 존재.
- 각 시드마다 다른 무작위로 섞인 순서의 예시를 가진 5개의 무작위 시드에 대한 평균 결과를 보고.
- 실험에서는 시드 간 큰 분산이 나타나지 않았기 때문에 계산 자원을 절약하기 위해 다른 모든 모델에 대해서는 단일 예시 순서에 대한 결과만 보고.
- PaLM
- 8B, 62B, 540B 파라미터 모델이 존재
- UL2 20B
- codex
- GPT-3
- greedy decoding을 통해 모델을 샘플링
- though follow-up work shows chain-of-thought prompting can be improved by taking the majority final answer over many sampled generations
3.2 Result
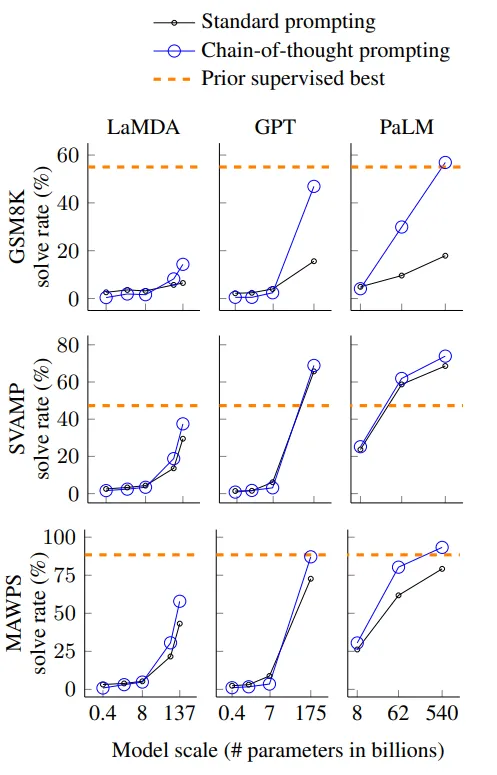

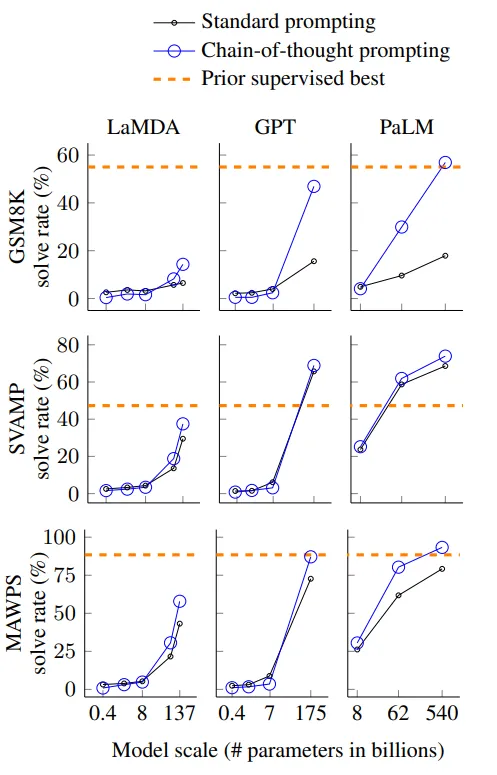
- 모델 규모와 CoT의 관계
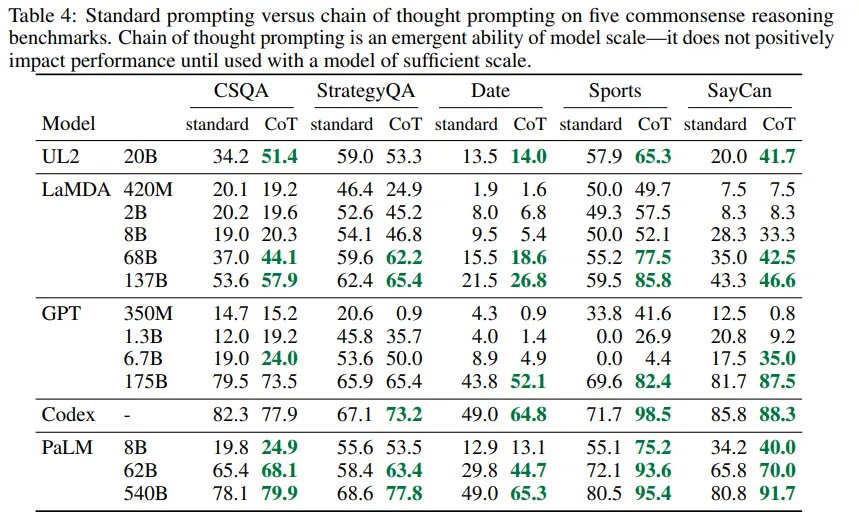
- 작은 모델에서는 큰 성능 차이를 보이지 않지만 100B 파라미터 이상 모델에서는 큰 차이를 볼 수 있음.
- 문제 복잡성과 성능 향상
- CoT는 복잡한 문제에서 더 큰 성능 향상을 보임.
- GSM8K (기본 성능이 가장 낮은 데이터셋)의 경우, 가장 큰 GPT 및 PaLM 모델에서 성능이 두 배 이상 향상.
- singleOp(단일 단계만을 요구하는 MAWPS의 가장 쉬운 하위 집합)에서는 성능 향상이 없거나 매우 미미했음.
- CoT는 복잡한 문제에서 더 큰 성능 향상을 보임.
- 최신 기술과 비교
- GPT-3 175B와 PaLM 540B를 통한 CoT Prompting은 일반적으로 레이블이 붙은 훈련 데이터 셋에서 과제별 모델을 fine-tuning하는 이전의 최신 기술과 비교해 유리한 성과를 보임
- Figure 4를 보면 PaLM 540B가 CoT Prompting를 사용하여 GSM8K, SVAMP, MAWPS에서 최고 성과를 달성.
- AQuA와 ASDiv에서는 CoT프롬프트를 사용한 PaLM과 다른 GPT, LaMDA의 차이가 2% 이내.
- LaMDA 173B 모델의 CoT 검토 결과
- GSM8K용 LaMDA이 생성한 CoT를 수동으로 검토
- 올바른 답을 낸 50개 중 48개(2개는 우연히 답을 냄)의 CoT는 수학적, 논리적으로 정확함.
- 잘못된 답을낸 50 개중 46%는 사소한 실수로 인한 오답이며, 54%는 major한 error가 남.
- GSM8K용 LaMDA이 생성한 CoT를 수동으로 검토
- PaLM 모델의 확장에 따른 오류 수정 효과 분석
- PaLM 62B에서 오류가 난 문제를 540B에서는 해결이 됐는지를 확인.
- one-step missing과 semantic understanding error 큰 부분이 해결됨을 볼 수 있음.
- PaLM 62B에서 오류가 난 문제를 540B에서는 해결이 됐는지를 확인.
3.3 다른 Prompt 유형의 성능 개선 가능성 탐구
- Equation only
- CoT 프롬프트가 도움 되는 이유 중 하나는 평가할 수학적 방정식을 생성하기 때문임.
- 모델이 정답을 제공하기 전에 수학적 방정식만 출력하도록 프롬프트하는 변형을 테스트.
- 결과 : Figure 5. 에서 볼 수 있듯 방정식만 출력하는 프롬프트는 GSM8K에서 크게 도움이 되지 않음. 이는 GSM8K의 질문 의미가 자연어 추론 단계 없이 직접적으로 방정식으로 번역하기에는 너무 어려움을 시사
- one-step, two-step 문제의 경우 방정식만 사용하는 방식이 도움이 되기는 함.
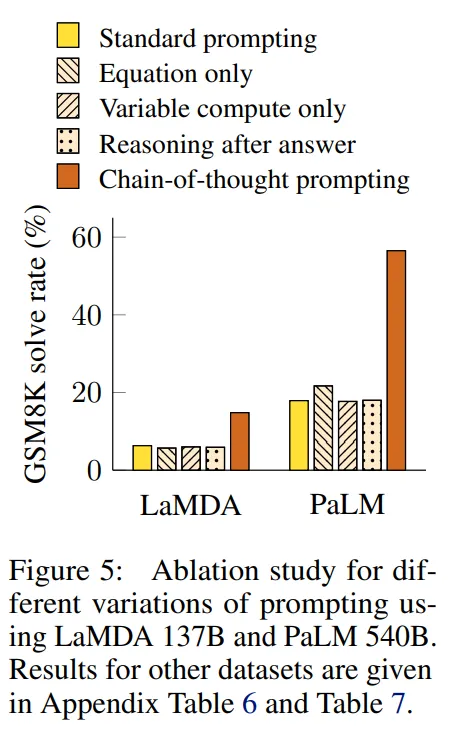
- variable compute only
- CoT가 더 어려운 문제에 대해 더 많은 계산(intermediate tokens)수가 늘어나 연산량이 증가한 것이 더 좋은 성능의 원인이 아닐까라는 생각함.
- Standard prompting에 ‘…’을 넣어 CoT때와 토큰 수를 똑같이 맞춤.
- 결과 : 이 방법은 기본값과 비슷한 성능을 보임. 토큰의 수 자체가 CoT 프롬프트 성공의 이유가 아니며, 자연어로 중간 단계를 표현하는 데 유용함을 시사.
- CoT after answer
- CoT 프롬프트의 또 다른 잠재적 이점은 이러한 프롬프트가 모델이 사전 학습 동안 획득한 관련 지식에 더 잘 접근할 수 있게 한다는 것일 수 있음.
- CoT 프롬프트가 실제로 최종 답을 제공하기 위해 필요하지 않은지 여부를 분리하기 위해 정답 후에만 CoT 프롬프트를 제공하는 대체 구성을 테스트.
- 결과 : 이 방법도 기본값과 비슷한 성능을 보임. 이는 CoT에 포함된 순차적 추론이 단순히 지식을 활성화하는 것 이상의 이유로 유용함을 시사
3.4 Robustness of CoT
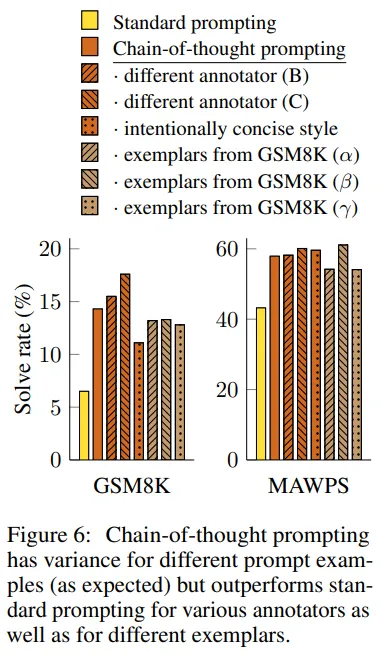
- 예시에 따라 결과의 성능이 바뀌지 않을까? 하는 생각에서 시작.
- 세명의 다른 사람이 CoT prompt를 제작해 성능 비교를 해본 결과 약간의 차이는 있지만 전체적으로 Standard Prompting 성능보다는 개선됨.
- 따라서, CoT prompt 방식은 비교적 Robust한 방식이란 걸 알 수 있음.
4. Commonsense Reasoning
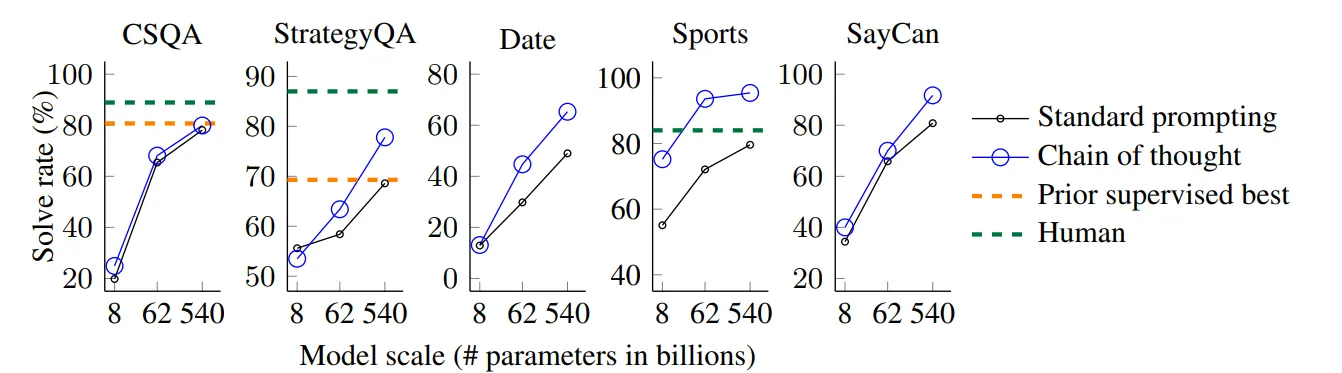
CoT는 수학 문제에 적합하지만, 언어 기반 특성으로 인해 배경 지식을 전제로 하는 광범위한 상식 추론 문제에도 적용 가능

- Benchmarks
- CSQA : 세계에 대한 상식 질문.
- StrategyQA : 질문에 답하기 위해 다중 단계 전략을 추론해야 하는 문제
- Date : 주어진 문맥에서 날짜를 추론
- Sports : 스포츠와 관련된 문장이 타당한지 여부를 판단.
- SayCan : 자연어 지시를 불연속적인 로봇 행동 시퀀스로 매핑.
- Prompts
- 이전 섹션과 동일한 실험 설정을 따름.
- CSQA, StrategyQA의 경우, train set에서 무작위로 예시를 선택하고 수동으로 CoT를 작성하여 few-shot 예시 사용.
- Date, Sports는 train set이 없으므로 evaluation set의 처음 10개 예시를 few-shot 예시로 선택하고 나머지 evaluation set에 대해 성능을 보고.
- Say Can의 경우, Ahn et al. (2022)에서 사용된 훈련 세트에서 6개의 예시를 사용하고 수동으로 CoT를 작성.
- Results
PaLM 결과
5. Symbolic Reasoning
- Task
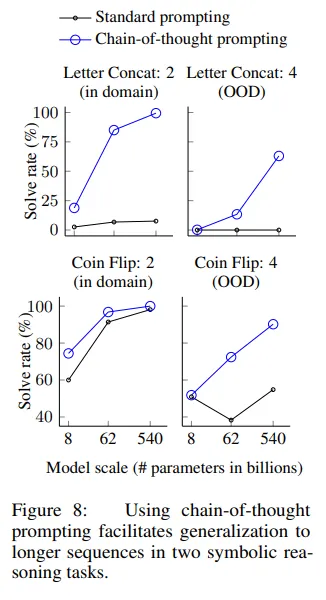
- Last Letter Concatenation
- Figure 3에서 보이듯이 뒤에 스펠링을 concatenate하는 task
- Coin Flip
- 코인의 뒤집혀짐 여부를 찾아가는 task
- Last Letter Concatenation
- 평가 방법
- 각 작업에 대해 training/few-shot exemplars와 동일한 step의 수의 예시를 가진 in-domain test set과 예시보다 더 많은 step을 가진 out-of-domain (OOD) test set을 고려
- Letter Concat의 task 경우 앞서 보여준 두 단어 예시만 참고하여, 3, 4개의 단어 이름에 마지막 글자를 연결하는 task 실행
- Coin flip task도 비슷하게 진행
- Result
- 위 Task 들과 마찬가지로 동일한 결론을 도출.
- CoT Prompting을 사용하면 성능이 크게 향상되며 모델의 사이즈가 커질수록 성능은 더 좋아짐.
- 위 Task 들과 마찬가지로 동일한 결론을 도출.
6. Discussion
- 연구 결과 요약
- arithmetic reasoning, commonsense reasoning, symbolic reasoning에 대해 좋은 성능을 보여줌
- 모델의 크기가 커짐에 따라 성능이 급격하게 좋아짐.
- 향후 연구 방향
- 모델 규모에 따른 추론 능력의 향상
- 모델의 크기를 추가로 늘릴 경우 추론 능력이 얼마나 더 향상될 수 있을지에 대한 질문
- 다른 프롬프트 방법의 탐색
- 언어 모델이 해결할 수 있는 작업 범위를 확장할 수 있는 다른 프롬프트 방법 탐색
- 모델 규모에 따른 추론 능력의 향상
- 한계점
- 신경망의 실제 ‘추론’ 여부
- CoT가 인간의 사고 과정을 모방하더라도 신경망이 실제로 ‘추론’하고 있는지는 열려 있는 질문
- the cost of manually augmenting exemplars
- few-shot setting 에서 CoT 예시를 수동으로 추가하는 비용은 미미하지만, fine tuning 에서는 비용이 제한적일 수 있음. 이는 synthetic data generation 또는 zero-shot
generalization로 해결할 수 있을 가능성 있음.
- few-shot setting 에서 CoT 예시를 수동으로 추가하는 비용은 미미하지만, fine tuning 에서는 비용이 제한적일 수 있음. 이는 synthetic data generation 또는 zero-shot
- 신경망의 실제 ‘추론’ 여부
