0. Abstract
- 배경 및 목적
- 기존에는 CoT prompting 기법이 few-shot 학습에서 우수한 성능을 보였는데, 이 현상이 few-shot 학습에 의해서 향상 했는지에 대한 조사
- 주요 발견
- ‘step-by-step’이라는 간단한 프롬프트를 추가하여 zero-shot에서도 우수한 성능을 보일 수 있음을 입증.
- 성능 개선 :
- Zero-shot CoT 방법이 다양한 벤치마크 reasoning task 성능을 크게 개선
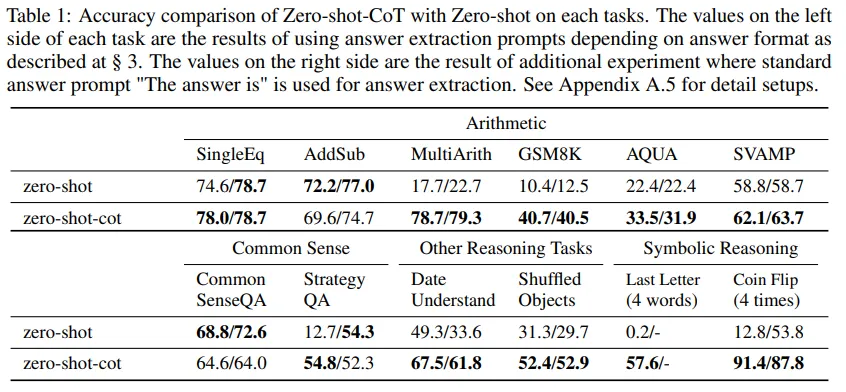
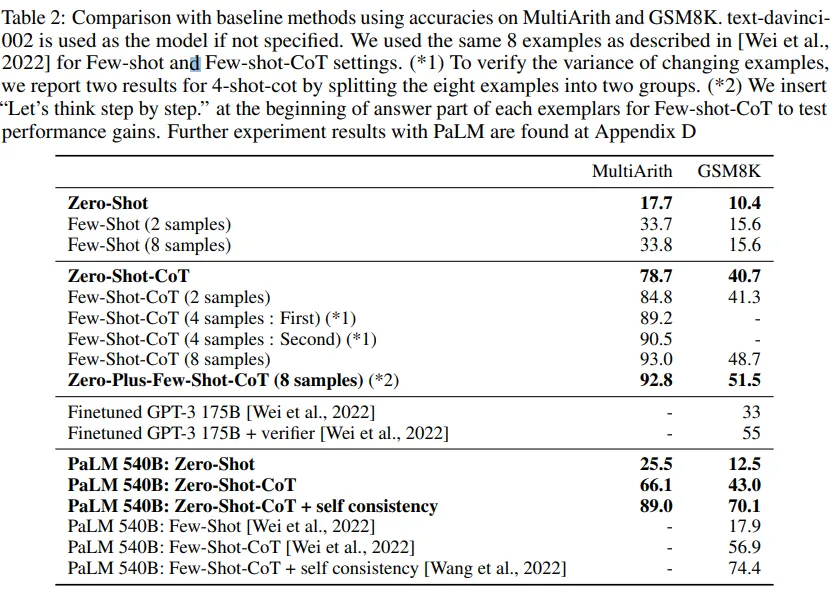
- MultiArith에서는 17.7% 에서 78.7%로 상승, GSM8K에서 10.4%에서 40.7%로 상승
- 모델 성능 :
- InstructGPT 모델(text-davinci002)과 540B 매게변수를 가진 PaLM 모델 모두에서 유사한 수준의 성능 향상이 관찰됨.
- 프롬프트의 범용성 :
- 단일 프롬프트가 다양한 reasoning task에서 효과적으로 작용
- LLM의 잠재적 zero-shot capabilities를 시사하며, 고차원적이고 다중 작업을 수행할 수 있는 인지 능력을 지닌 것으로 보임.
1. Introduction

- 기존 CoT 연구에서는 few-shot하는 방법이 제안됨에 따라, 비용이 발생할 수 있음.
- 따라서 ‘Let’s think step by step’이라는 prompt를 제안해 zero-shot 방식으로 질문에 답하기 전 step-by-step thinking을 가능하게 함.
- Few-shot-CoT가 human engineering을 요구하며, 프롬프트 예시 질문 유형과 작업 질문 유형이 일치하지 않으면 성능이 저하됨.
- Zero-shot-CoT의 다재다능성은 LLM의 Zero-shot 능력이 숨겨져 있을 가능성을 제시.
2. Background
2가지의 core preliminary concepts를 리뷰.
- Large Language Model and prompting
- LM은 텍스트에 대한 확률분포를 추정
- text 나 prompt를 사용하여 생성 과정에서 원하는 작업에 대한 답변을 강력하게 유도. (few-shot과 같은 방식)
- Chain of thought prompting
- few-shot프롬프트의 일환으로, 예시의 답변을 step-by-step 답변으로 수정하는 간단한 해결책을 제안.
- 이번 연구에서는 zero-shot 방식을 적용할 예정
3. Zero-shot Chain of Thought
Zero-shot CoT는 ‘Let’s think step by step’을 활용하여 단계별 추론을 추출하는 것이 목표.
3.1 Two-stage prompting

zero-shot CoT 의 경우 개념적으로는 간단하지만, 추론과 답변을 모두 추출하기 위해 두 번의 프롬프트를 사용.
- Reasoning Extraction
- 1단계에서는 trigger sentence를 통해 답변을 추론
- Answer Extraction
- 추론된 답변으로부터 최종 답변을 추출.
4. Experiment
Tasks and datasets : 12개의 데이터셋을 4가지 reasoning task categories에서 평가.
- 산술 추론
- 상식 추론
- 기호 추론
- 기타 논리적 추론 작업
Models : 17개 모델을 실험
- InstructGPT3 (text-ada/babbage/curie/davinci-001 및 text-davinci-002)
- GPT-3 (ada, babbage, curie, davinci)
- PaLM (8B, 62B, 540B)
- GPT-2
- GPT-NEO
- GPT-J
- T0
- OPT
Baselines
- Zero-shot-CoT를 기존 zero-shot prompt와 비교하여 CoT Reasoning의 효과성을 검증
- Zero-shot-CoT와 유사한 답변 Prompt를 default값으로 사용.
- 더 좋은 평가를 위해 Few-shot, Few-shot-CoT와 비교.
- greedy decoding을 사용
Greedy decoding?
기본적인 Seq2Seq 모델에서의 디코딩 과정은 보통 Greedy Decoding 방식을 따름.
Greedy Decoding이란 해당 시점에서 가장 확률이 높은 후보를 선택하는 것.
- few-shot 접근법의 경우, in-context 예제의 순서가 결과에 영향을 미치기 때문에 모든 방법과 데이터셋에 고정된 시드를 사용하여 각 실험을 한 번만 실행하여 공정한 비교를 진행
Answer cleansing
- 답변 포맷에 맞는 부분만 추출.

- Few-shot or Few-shot-CoT 방법에서는 [Wang et al., 2022]를 따르며, 모델 출력에서 “The answer is” 이후의 답변 텍스트를 추출하고 동일한 Answer cleansing을 적용.
- 모델 출력에서 “The answer is”가 발견되지 않으면, 뒤에서부터 형식에 맞는 첫번째 text를 예측으로 설정
4-1. Results