Introduction
chain-of-thought prompting에서 사용되는 greedy decoding을 대체하기 위해 self-consistency(정답에 도달하는 추론 과정을 여러 개를 생각함)를 제안하여 추론 능력을 향상 시킴.
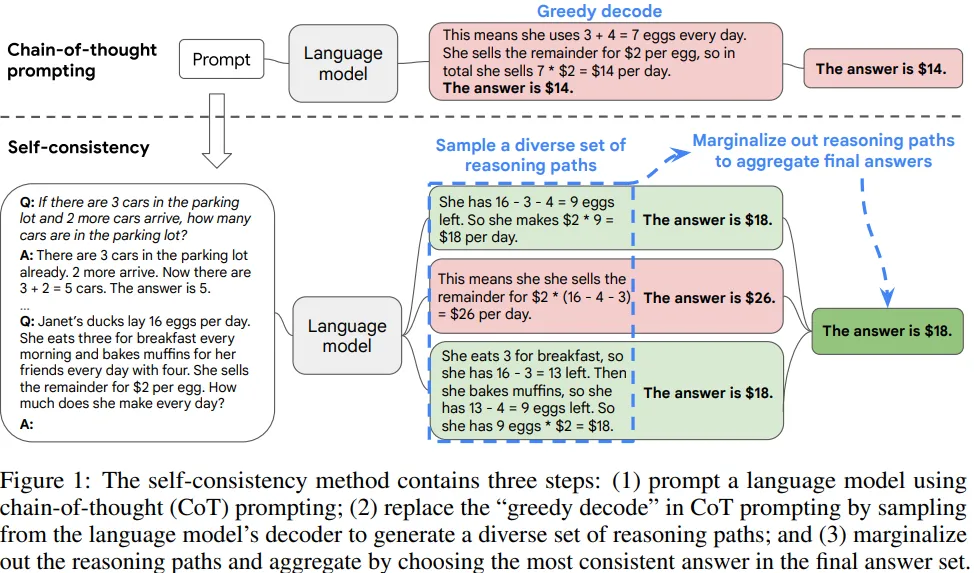
Greedy decode 대신 Sample-and-marginalize를 제안.
self-consistency는 비지도 학습 방식이며, pre-trained language model을 사용하고, 추가적인 labeling 작업이 필요 없어, 추가적인 학습, 보조 모델, fine-tuning이 필요 없음.
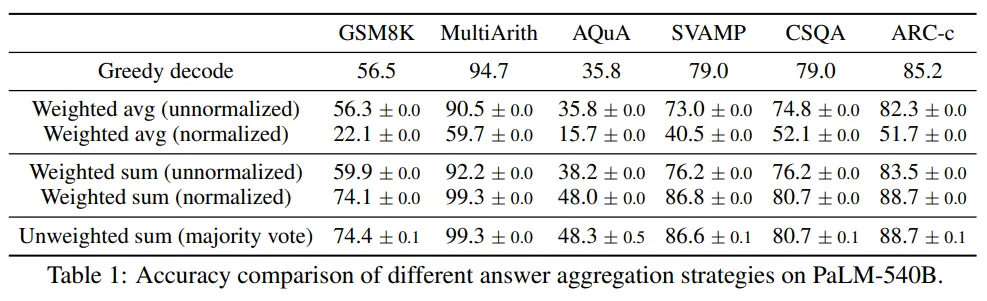
Unweighted sum(majority vote)와 Weighted sum(normalized)의 정확도가 비슷함.
unnormalized보다 normalized를 한 경우 더 좋은 성능을 보여줌.
기존에는 고정된 답변이 있어 greedy 방식을 채택했다면, 이 논문에서는 고정된 답변이 있어도 다양한 추론 과정을 도입하여 성능을 향상 시킬 수 있다는 결론을 내림.
Main result
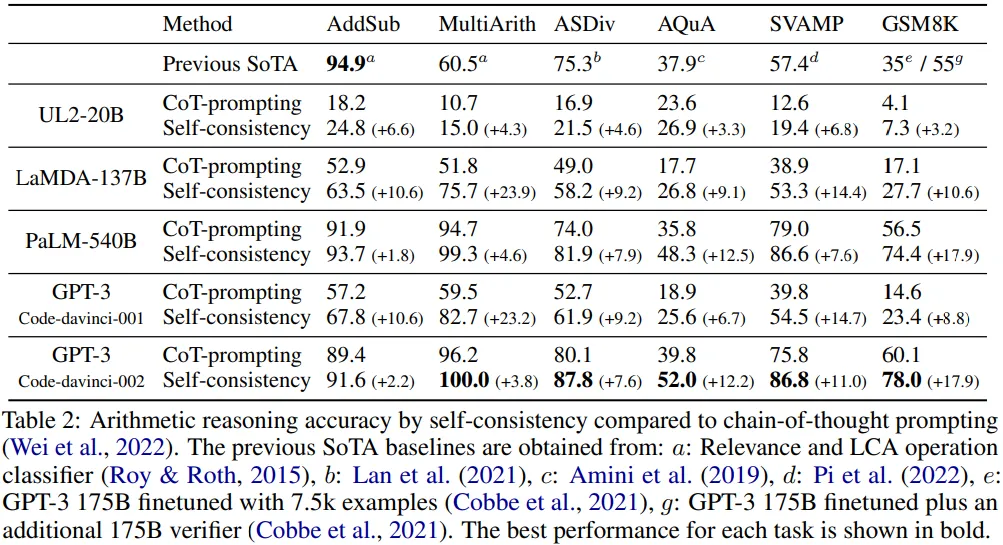
CoT-prompting 기법과 비교
Arithmetic Reasoning
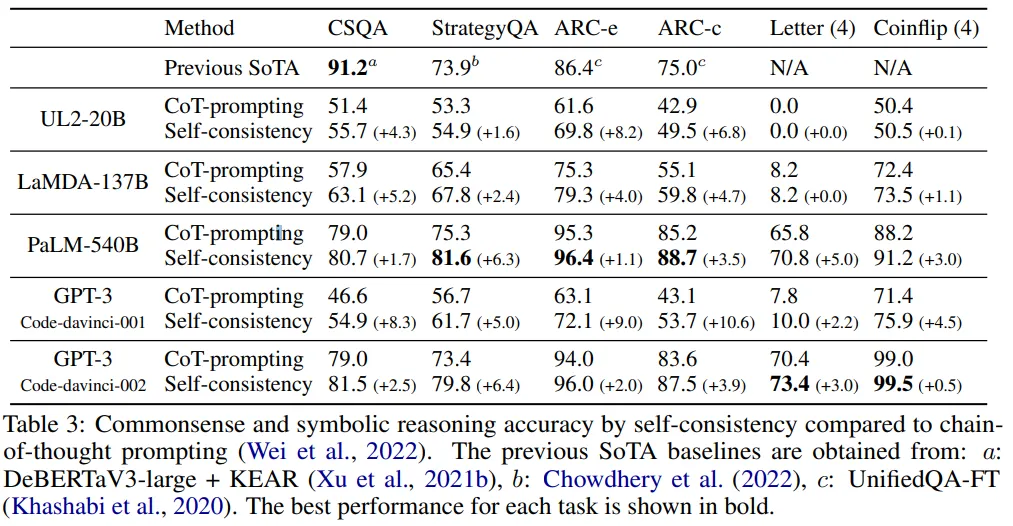
Commonsense and Symbolic Reasoning
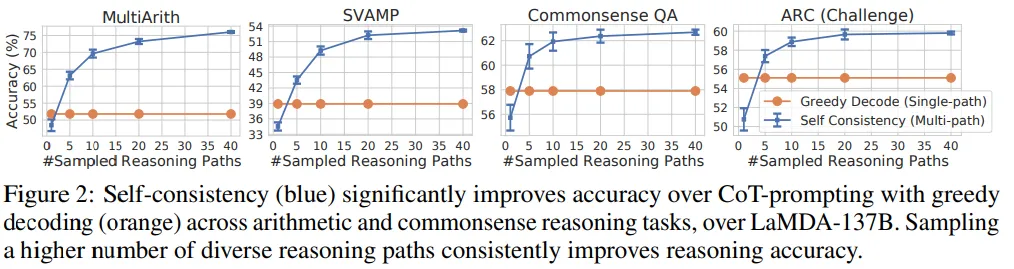

Self-Consistency helps when chain-of-thought hurts performance

CoT는 때때로 성능을 저하 시키는 경우(Natural Language Inference, Closed-Book Question Answering)가 존재하지만, Self-consistency를 사용함으로 써 성능을 향상시킴.
Compare to other existing approaches
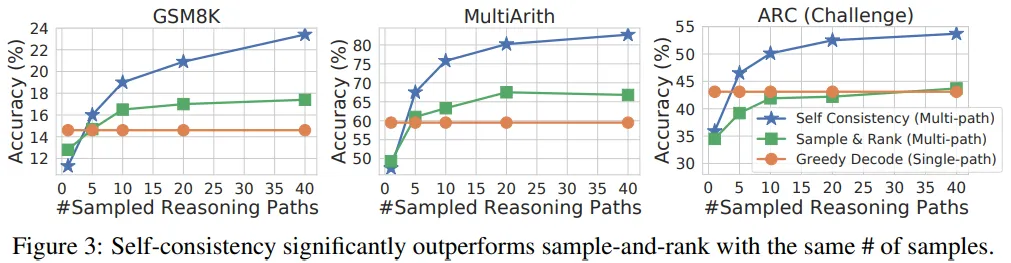
Comparison to Sample-and-Rank
Comparison to Beam Search

Comparison to Ensemble-based Approaches

Additional studies
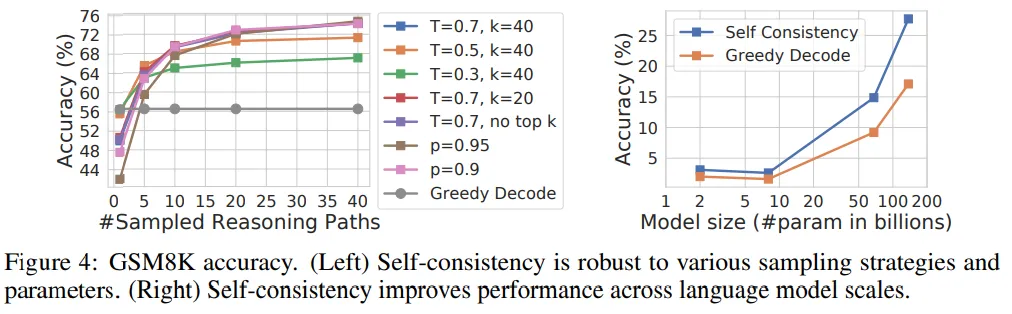
Relation to consistency and Accuracy
수동으로 작성된 프롬프트에서 Human annotators는 사소한 실수가 발생할 수 있음. 이를 Self-consistency를 통해 향상 시킬 수 있음을 발견.

Conclusion and Discussion
- 정확도 향상: 자기 일관성은 다양한 언어 모델에서 성능을 개선하며, 특히 산수 및 상식 추론 작업에서 두드러짐.
- 추론 합리성 수집: 자기 일관성은 단순한 성능 향상 외에도, 추론 작업에서 모델이 합리적 경로(rationale)를 제시할 수 있도록 도움.
- 불확실성 추정 및 출력 보정: 이 방법을 사용하면 모델의 추론 경로에서 불확실성을 추정하고, 출력의 보정(calibration)도 개선.
한계점
- 비용 발생 : 여러 추론 경로를 샘플링해야 하기 때문에 많은 resource가 필요. CoT에 비해 샘플링하는 대답에 갯수에 비례하여 Cost가 발생.
