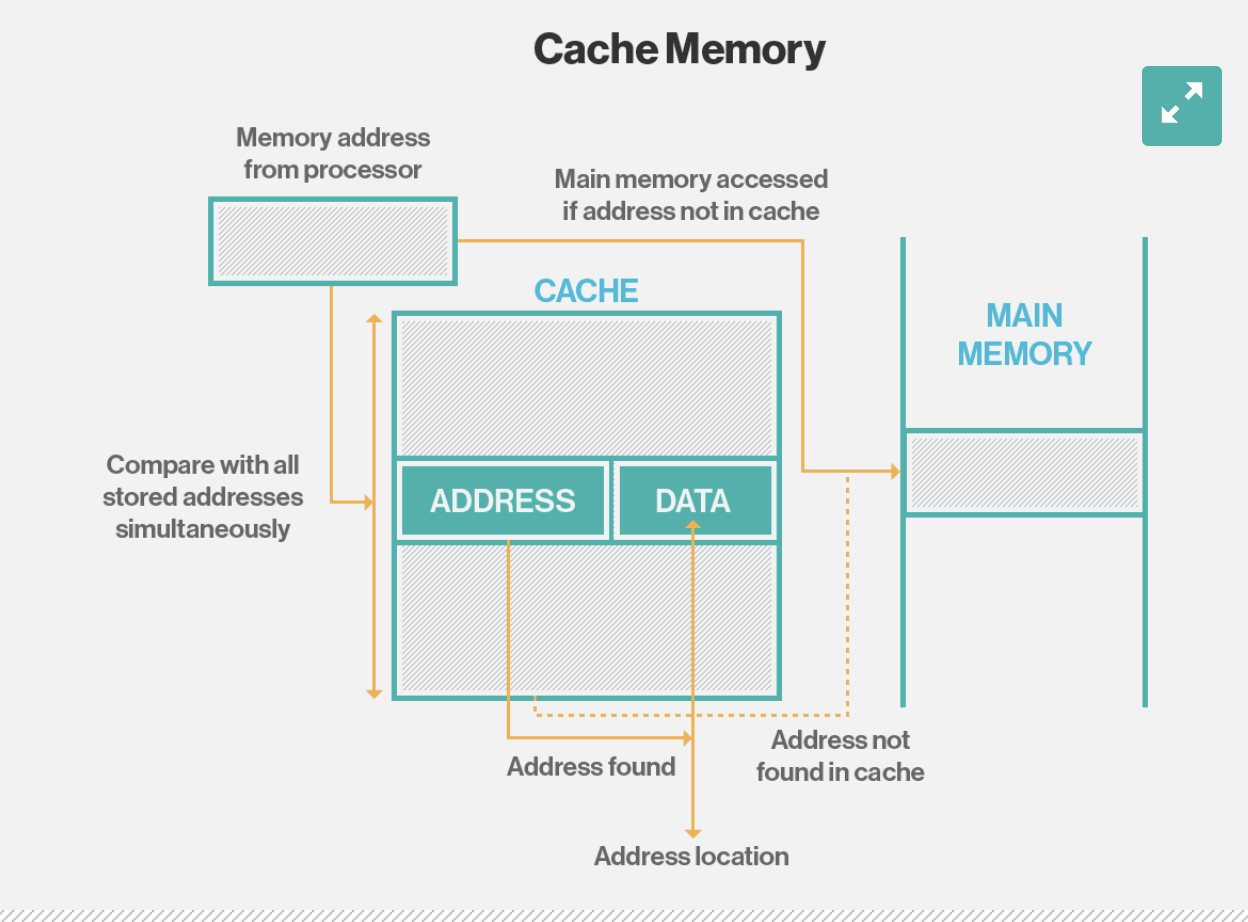
1.Cache란?
- 캐쉬란 데이터 요청 주체와 메모리 저장공간 사이에 위치하면서 메모리 저장공간에 대한 조회 요청을 앞에서 먼저 대신 처리해주는 저장장치이다.
- 데이터 요청자는 먼저 cache에서 원하는 데이터가 존재하는지 찾아보고 있는 경우 cache의 데이터를 가져가고 없는 경우 원본 데이터 저장공간에서 데이터를 가져오게 된다.
- 직접적으로 데이터 처리 로직을 실행 하지않고 이전에 조회된 데이터를 다시 가져오는 방식이기 효율성을 얻기 적이지만 일관성을 일부 양보하는 전략이라고 할 수 있다.
1.0. Long tail 법칙
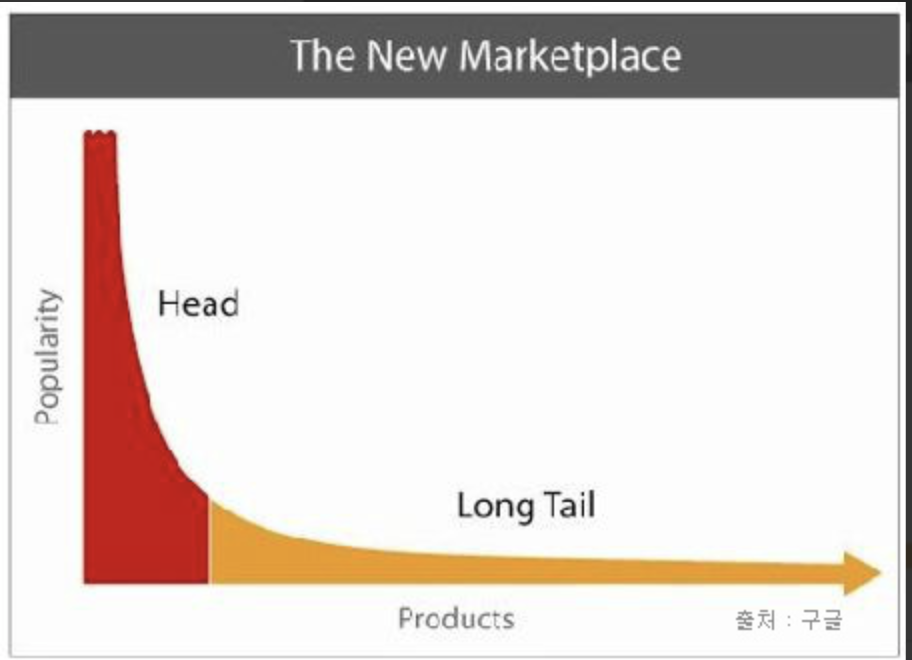
- 20%의 요구가 시스템 리소스의 대부분을 잡아먹는다는 법칙.
- 자주 사용되는 20%의 기능에 캐시를 이용하면 리소스 사용량을 대폭 줄일 수 있어, 시스템의 성능을 대폭 향상 시킬 수 있다.
1.1. Hit ratio
- 데이터를 cache에서 먼저 찾은 경우의 비율을 Hit ratio 라고 한다.
- 이 비율이 높으면 cache로 인한 성능 향상이 효율적으로 이루어지고 있는 것이다.
- 따라서 Hit ratio 를 높이는 방식으로 cache 에 데이터를 저장하는 것이 중요하며 이때 지역성의 원리가 적용된 알고리즘이 주로 사용된다.
1.2.지역성의 원리
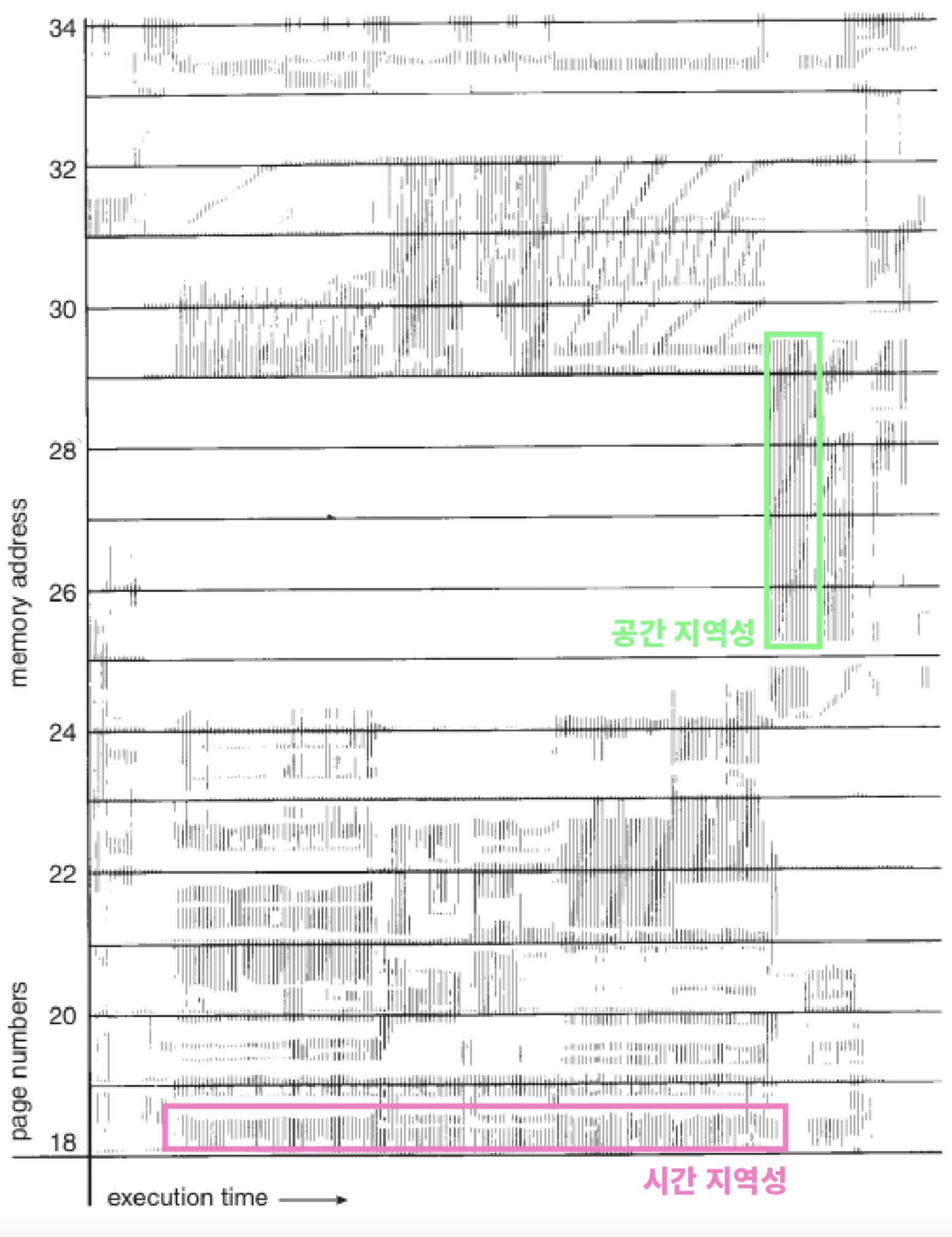
- 시간 지역성(Temporal locality)
- 최근에 요청된 데이터가 다시 요청될 확률이 높다.
- For, while 같은 반복문에 사용되는 조건 변수처럼 한번 참조된 데이터는 잠시후 참조될 가능성이 높다.
- 공간 지역성(Spatial locality)
- 요청된 데이터 주변 메모리 데이터가 요청될 확률이 높다.
- a[0], a[1]처럼 같은 데이터 배열에 연속적으로 접근할때 참조된 데이터 근처에 있는 데이터가 잠시 후 사용될 가능성이 높다.
1.3. Cache 데이터 대체 알고리즘
- 어떤 cache의 데이터를 먼저 지울지 정하는 알고리즘이다.
- Least Frequently Used
- 가장 적게 요청된 데이터부터 지운다.
- Least Recently Used
- 가장 요청된지 오래된 데이터를 지운다.
- Most Recently Used
- 가장 최근에 요청된 데이터를 지운다.
1.4. Cache 사용의 장점
-
응답시간이 감소한다.
-
DB부하를 줄일 수 있다.
-
자원을 효율적으로 사용한다.
- 응답 시간 외에도 빠른 캐시로Select쿼리를 수행하는 것보다 단순히 캐쉬에 가서 데이터를 가져오는 전체 리소스 사용측면에서 효율적일 것이다.
1-5. Cache 사용시 생길 수 있는 문제점
- 데이터 일관성 문제: 실제 데이터와 다를 수 있다.
- 캐쉬 오염 문제: Procees의 Context Switching시 캐시 내용이 대부분 무의미 해진다.
1-6. Cache Read Policies
Cache-aside(lazy-loading)
- 가장 일반적인 cache전략이다.
- 먼저 Cache를 보고 원하는 데이터가 있으면 가져온다.
- 없으면 원본 DB에서 데이터를 가져온다.
- 원본 DB에서 가져온 데이터를 바로 Cache에 쓴다.
Read Through 패턴
- 캐시에서만 데이터를 읽어오는 전략 (inline cache)
- Look Aside 와 비슷하지만 데이터 동기화를 라이브러리 또는 캐시 제공자에게 위임하는 방식이라는 차이가 있음.
- 따라서 데이터를 조회하는데 있어 전체적으로 속도가 느림.
- 또한 데이터 조회를 전적으로 캐시에만 의지하므로, redis가 다운될 경우 서비스 이용에 차질이 생길수 있음.
- 대신에 캐시와 DB간의 데이터 동기화가 항상 이루어져 데이터 정합성 문제에서 벗어날수 있음
- 역시 읽기가 많은 워크로드에 적합
1-7. Cache Write Policies
Write-through cache: 캐시 DB 모두에 동시에씀
- write 할때에 cache에도 쓰고 메모리에도 동기적으로 쓰는 경우이다
- 장점은 cache데이터에 최근에 write 한 데이터 변화가 반영되기 때문에 데이터 정합성이 비교적 잘 맞는다.
- 단점으로는 한번의 write 가 cache, memory에 모두 이루어 지기 전까지 종료 되지 않기 때문에 write latency가 높아진다.Write-around cache: DB에만 우선적으로 씀
- write 할때에 cache에는 쓰지않고 메모리에만 쓰는 경우이다
- 장점은 수정할 때마다 cache를 수정하지 않아도 된다.
- 단점으로는 read하지 않으면 cache에 데이터가 반영되지 않는다. 캐시 데이터의 정합성이 더 떨어질 확률이 높다.
- 따라서 write operation이 대용량으로 발생하고 read operation이 적게 발생하는 경우에 적합하다.
- 캐시정보는 주로 읽는 api호출 시 활용될 것이고 이 경우 데이터 정합성이 완벽히 맞을 필요가 없을 수 있다. 하지만, write시 데이터 정합성이 정확하게 맞아야하는 정보가 있다면(상품의 재고) DB에만 쓰고 TTL등을 부여하여 추후에 재 조회시 캐시에 update가 되도록 한다. Write-back cache: Cache에만 우선적으로 씀
- write를 cache에만 하는 경우이다. cache 에 데이터가 저장되면 write가 종료되고, 이 데이터가 cache에서 탈락될 때 메모리에 복사된다.
- 장점은 write와 read 모두 latency가 적다. 유저 서비스 중에 사용하기 보다는 배치 작업등의 성능 목적의 작업에 적합하다.
- 단점으로는 오히려 db에 데이터 반영이 늦게 된다. 따라서 db 데이터가 현재 상태를 반영한다고 볼 수 없다.
- 또한, DB반영전 cache에 문제가 발생하면 데이터가 유실될 수 있다.storage에 일관성을 관리하기 위한 방법이 필요하다는 부분이다.
- 주로 배치 작업등에서 유리할 수 있을 것 같다. 데이터 정합성이 중요한 경우라면 사용하기 매우 힘들것 같다.2. Backend Cache
2.1.브라우저와 Server 사이의 Cache
- ETag : 캐시 정책을 백엔드 개발자가 정함. web server와 browser사이에 있는 캐쉬들에 적용.
- hash 된 etag 값을 비교하여 origin server와 값이 다르면 새로 값을 주고, 같은 경우 304 발생
- 브라우저 캐시 : Client local 저장공간에 위치하는 캐시
- 프록시 서버 캐시 : Client 와 Origin Server사이에 위치하는 Proxy server 에 저장 되는 캐시
- CDN(Content Delivery Network)- 프론트 엔드를 S3와Cloudfront에 배포하는데 그때 Cloudfront가 CDN의 역할을 수행한다.
2.2. DB와 WAS 사이의 Cache
2.2.1 Local Cache And Global Cache
- Local Cache
- 특징
- WAS 인스턴스 각각의 메모리에 Hashmap 자료구조나 EHcache등을 사용하여 임시적으로 데이터를 저장한다.
- 장점
- 프로세스가 실행되는 곳의 메인 메모리에서 데이터를 가져올 수 있기 때문에 네트워크 통신, io 에서 사용되는 시간이 분산 캐시와 비교하여 비교할 수 없을 정도로 매우 빠르다.
- 단점
- 각각의 WAS의 캐시 간의 데이터가 중복되고 불일치 할 수 있으므로 서로 동기화 시키는 비용이 든다.
- 데이터 일관성이 중요한 경우 사용하기 힘들다.
- WAS heap 메모리를 차지한다. GC도 더 자주 일어날 수 있으며 OOM가능성이 높아진다.
- 특징
- Global Cache
- 특징
- WAS나 DB와 따로 위치하며 여러 서버에서 공동으로 접근하여 사용하는 캐시이다.
- 주로 속도 보다는 DB 부하 분산과 Scale out을 위해 사용한다.
- Redis, Memcached 등의 in-memory DB가 있다.
- 장점
- 별도의 Cache Server를 이용하기 때문에 서버 간 데이터 공유가 쉽다.
- local cache에 비해
- 데이터를 분산하여 저장 할 수 있다.
- Replication - 데이터를 복제
- Sharding - 데이터를 분산하여 저장
- 단점
- Local Cache와 달리 네트워크 전송으로 인한 Latency가 추가된다.
- 특징
2.2.2 Redis vs Memcached
https://www.imaginarycloud.com/blog/redis-vs-memcached/
- Redis vs Memcached
- Redis
- 특징
- Single thread
- in-memory data structure
- key-value NOSQL
- sharding 등 Scale out에 유리
- 장점
- set, hash, sorted set, string 등의 자료구조가 있어 데이터 처리가 매우 편리하다.
- 설정(RDB, AOF적절히 설정)에 따라 100% 까지는 아니지만 거의 근접한 정도의 데이터 백업을 할 수 있다.
- 단점
- Memcached보다 메모리 단편화 문제로 메모리를 비효율적으로 사용한다.
- RDB를 위한 Fork시 순간적인 메모리 추가 할당으로 장애가 생길 수 있는 등 오히려 백업기능 때문에 문제가 생길 수 있다.
- 특징
- Memcached
- 특징
- Multi thread
- in-memory
- vertical Scalability에 유리하다
- 장점
- 메모리 관리면에서 Redis보다 뛰어나고 비교적 메모리 단편화 문제를 잘 해결한다.
- 단점
- Redis 에서 처럼 자료구조를 제공하지 않기 때문에 데이터들을 다루기 불편하다.
- 백업기능이 따로 제공 되지 않는다.
- Scale out 을 위해서 Application logic을 작성해야한다.
- 특징
- Redis
3. Cache Eviction, Expiration
3-1. Eviction
Eviction전략은 메모리의 용량이 얼마 없다면 먼저 제거되야할 우선순위를 정하는 전략이라고 보면된다. 즉, 메모리 관리 전략이다.
Least Recently Used (LRU): 가장 쓰인지 오래된것
Least Frequently Used (LFU): 가장 쓰이지 않은 것
First In First Out (FIFO): write 먼저 된 순서대로 evect
3-2. Expiration
- 생성후 지정한 시간이 지나면 캐시가 사라진다.
- Expiration 시간 설정은 캐시에서 잘 조회되지 않는 데이터를 삭제하여 메모리를 관리하는 의미도 있지만, 캐시 전략에 따라 데이터 정합성을 얼마나 중요하게 생각할지에 대한 여부도 있다.

Fail Fast