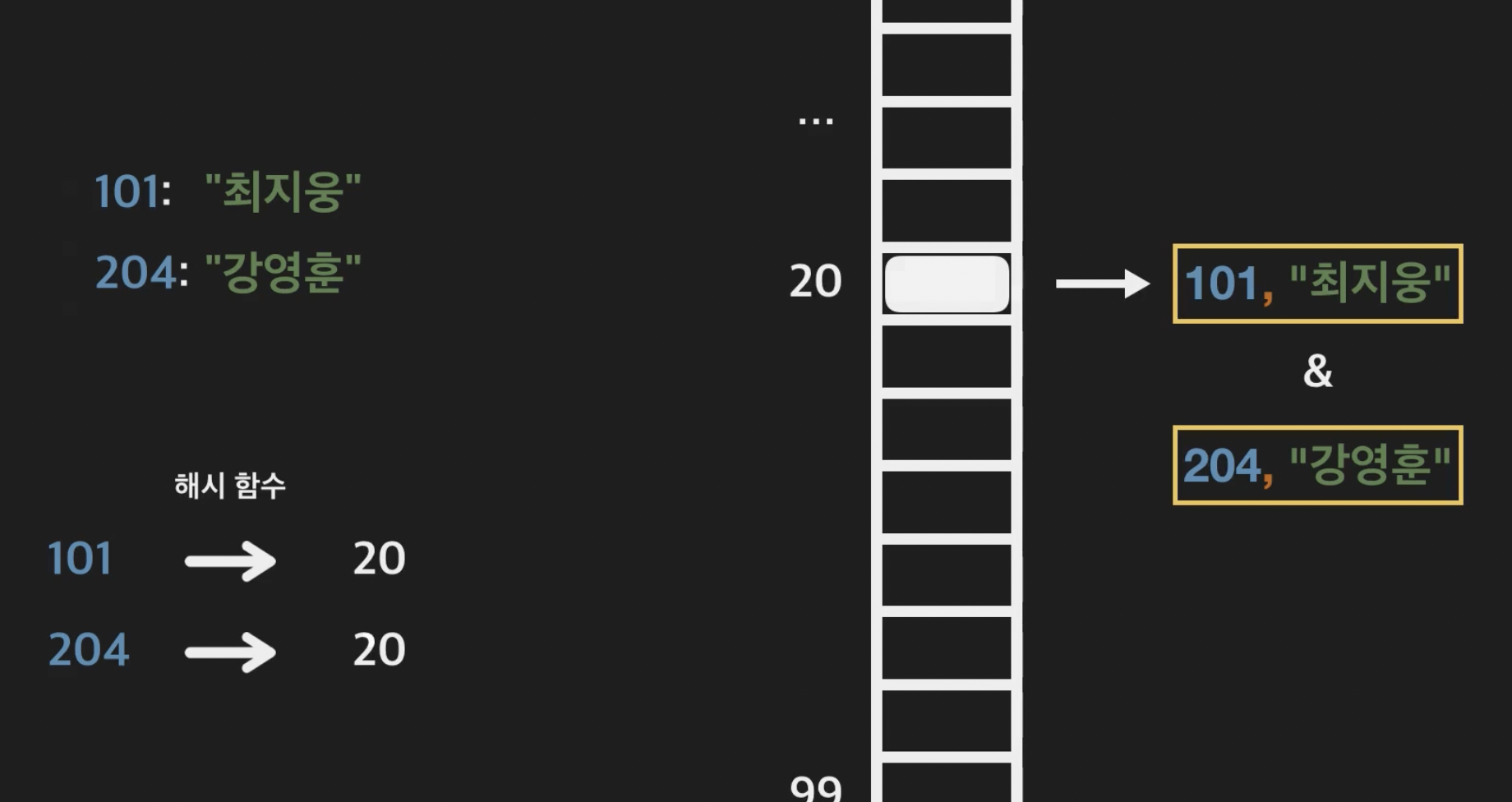
해시함수를 사용하더라도 같은 값이 나오게 된다면 같은 인덱스에 두 키 쌍을 저장해야되는데 그럴때 충돌(collision)이 발생된다. 이럴땐 chainning 으로 연결시켜주는데 앞에서 배웠던 인덱스 배열에 linked-list 개념을 활용한다.
Chaining을 이용하면 해시 테이블에서 충돌이 일어나도 key - value 쌍들을 모두 저장할 수 있습니다.
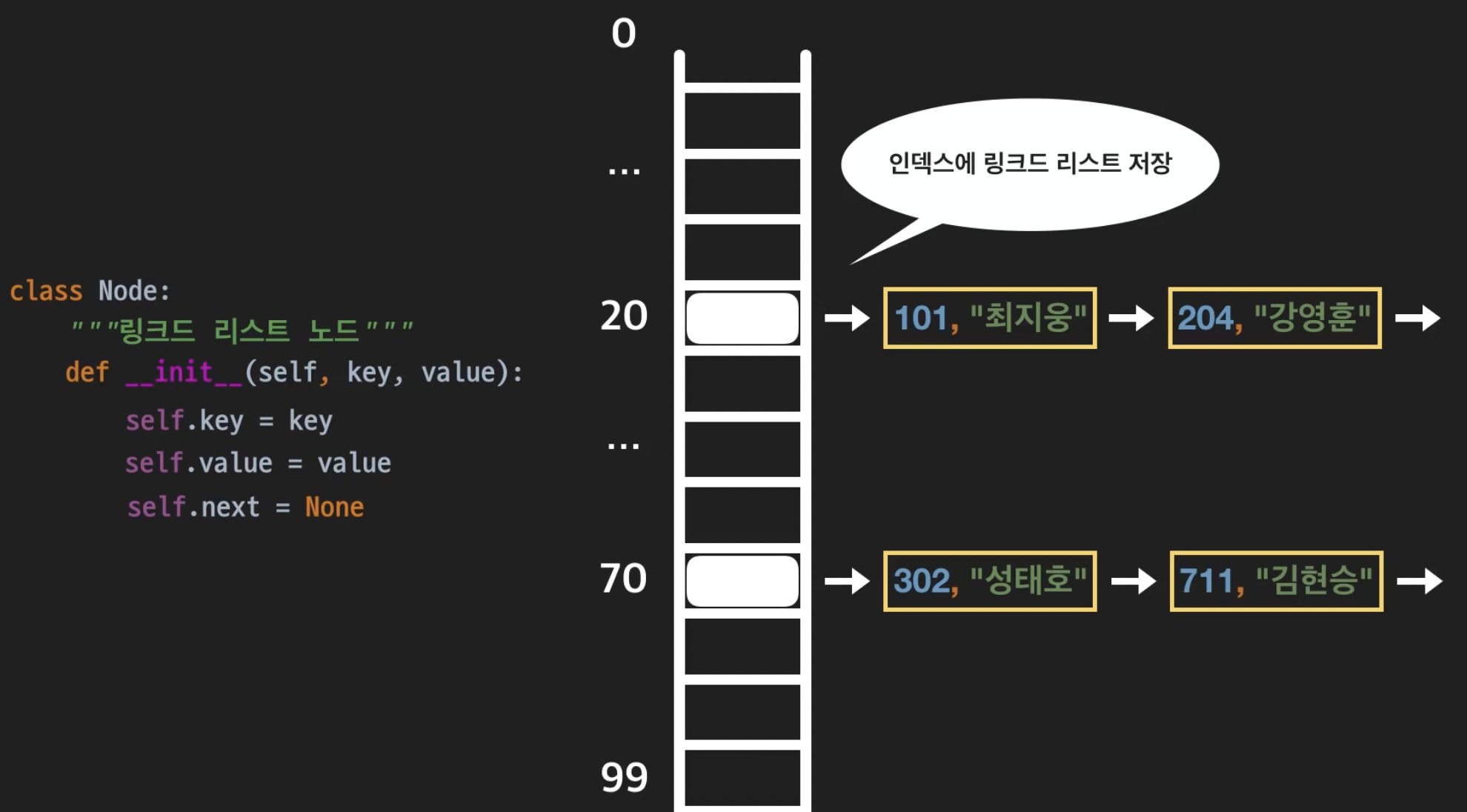
링크드 리스트에서는 self.data = data 로 데이터를 지정해줬는데 , channing 에서는 키와 값을 Node에 저장해준다
class Node:
"""링크드 리스트 노드 """
def __init__(self,key,value):
self.key = key
self.value = value
self.next = None # 다음 노드에 대한 레퍼런스
self.prev = None # 전 노드에 대한 레퍼런스
class linkedList:
"""링크드 리스트 클래스"""
self.head = None # 링크드 리스트의 가장 앞 노드
self.tail = None # 링크드 리스트의 가장 뒤 노드
def find_node_with_key(self, key):
"""링크드 리스트에서 주어진 데이터를 갖고있는 노드를 리턴한다. 단, 해당 노드가 없으면 None을 리턴한다"""
iterator = self.head #노드를 돌기 위한 변수
while iterator is not None:
if iterator.key == key:
return iterator
iterator = iterator.next
retrun None
def append(self, key, value):
"""링크드 리스트 추가 연산 메소드"""
new_node = Node(key,value)
if self.head is None:
self.head = new_node
self.tail = new_node
else:
self.tail.next = new_node # tail의 다음 노드로 추가
new_node.prev = self.tail #새 노드의 전은 원래의 끝 노드
self.tail = new_node # 끝 노드로 지정
def delete(self, node_to_delete):
"""더블리 링크드 리스트 삭제 연산 메소드"""
# 링크드 리스트에서 마지막 남은 데이터를 삭제할 때
if node_to_delete is self.head and node_to delete is self.tail:
self.head = None
self.tail = None
# 링크드 리스트 가장 앞 데이터 삭제할 때
elif node_to_delete is self.head:
self.head = self.head.next #시작노드를 뒤로 한칸 미뤄줌으로 지정
self.head.prev = None #전의 시작노드를 삭제
# 링크드 리스트 가장 뒤 데이터 삭제할 떄
elif node_to_delete is self.tail:
self.tail = self.tail.prev
self.tail.next = None
# 두 노드 사이에 있는 데이터 삭제할 때
else:
node_to_delete.prev.next = node_to_delete.next
node_to_delete.next.prev = node_to_delete.prev
def __str__(self):
"""링크드 리스트를 문자열로 표현해서 리턴하는 메소드"""
res_str = ""
iterator = self.head #노드를 돌 변수
while iterator is not None:
# 각 노드의 데이터를 리턴하는 문자열에 더해준다
res_str += "{}: {}\n |".format(iterator.key,iterator.value)
iterator = iterator.next
return res_str
- 탐색 메소드는 이제 특정 데이터를 갖은 노드를 찾는 게 아니라 특정 key를 갖는 노드를 찾습니다. 이에 맞게 링크드 리스트를 처음부터 끝까지 돌면서 원하는 key를 갖는 노드를 리턴해주도록 수정해줍니다. 코드에서는 기존에 data 변수를 다 key로 바꿔주면 되죠.
- 추가 메소드 append는 이제 파라미터로 data 변수 대신 key와 value를 받습니다. 링크드 리스트에 데이터를 더해줄 때는 항상 새로운 노드를 만들어줘야 되는데요. 파라미터로 받은 정보를 key와 value를 갖는 새로운 노드를 만들어줍니다. 새 노드를 링크드 리스트에 연결해주는 부분 코드는 똑같습니다.
- 원래 링크드 리스트 삭제 메소드에서는 노드를 삭제할 때 삭제하는 노드의 데이터를 리턴했는데요. 이 부분을 빼줄게요.
나머지 부분은 바꿔줄 필요 없습니다. 더블리 링크드 리스트 삭제 메소드는 어차피 노드가 주어졌을 때 그 노드를 링크드 리스트에서 삭제해주죠? 기존 data 변수나 key, value 변수와 전혀 관계가 없는 메소드기 때문에 나머지 코드를 바꿀 필요가 없는 거죠.
4.이제는 key - value 쌍을 저장하니까 출력 형식도 바꿔주는 거죠.
링크드 리스트에 101: “최지웅”, 204: “강영훈”, 305: “성태호”이 들어 있다고 할게요. 그러면 아래와 같이 이 링크드 리스트를 출력했을 때 한 줄에 한 key, value 쌍 하나씩 나오도록 바꿔준 거죠.

전문 금융인을 목표로하는 김야옹야옹이