자료구조
1.자료구조 (1) 배열 -분할상환분석

자료구조의 처음 배열에 관한 정보 O(1), O(n)
2.삽입 연산의 시간복잡도 O(n)

삽입 연산에 대한 설명
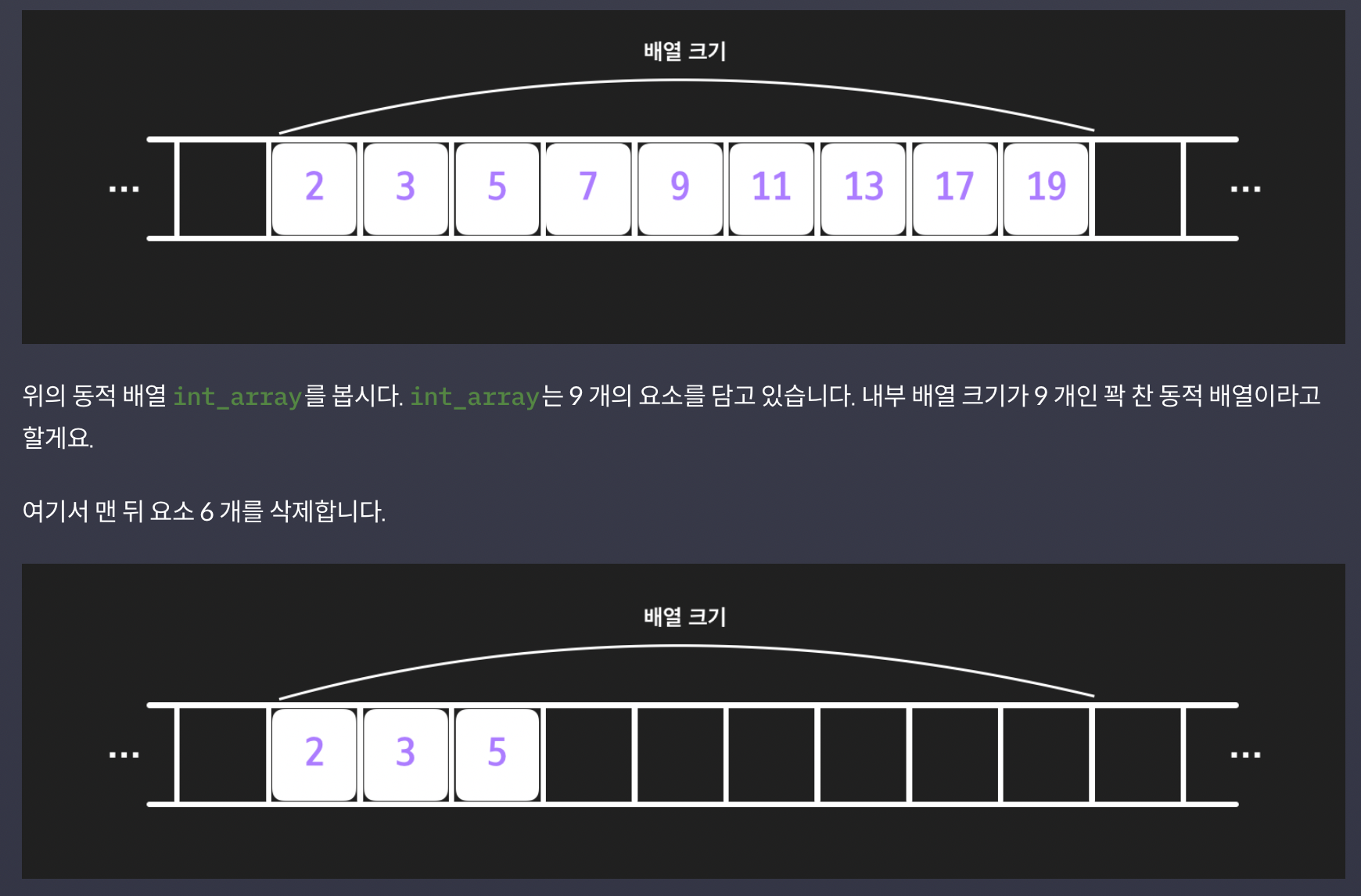
3.동적 배열의 크기 줄이기


실제 메모리는 여기저기 흩어져있지만 n_1.next = n_2 로 레퍼런스를 참조하는 개념이 linked list
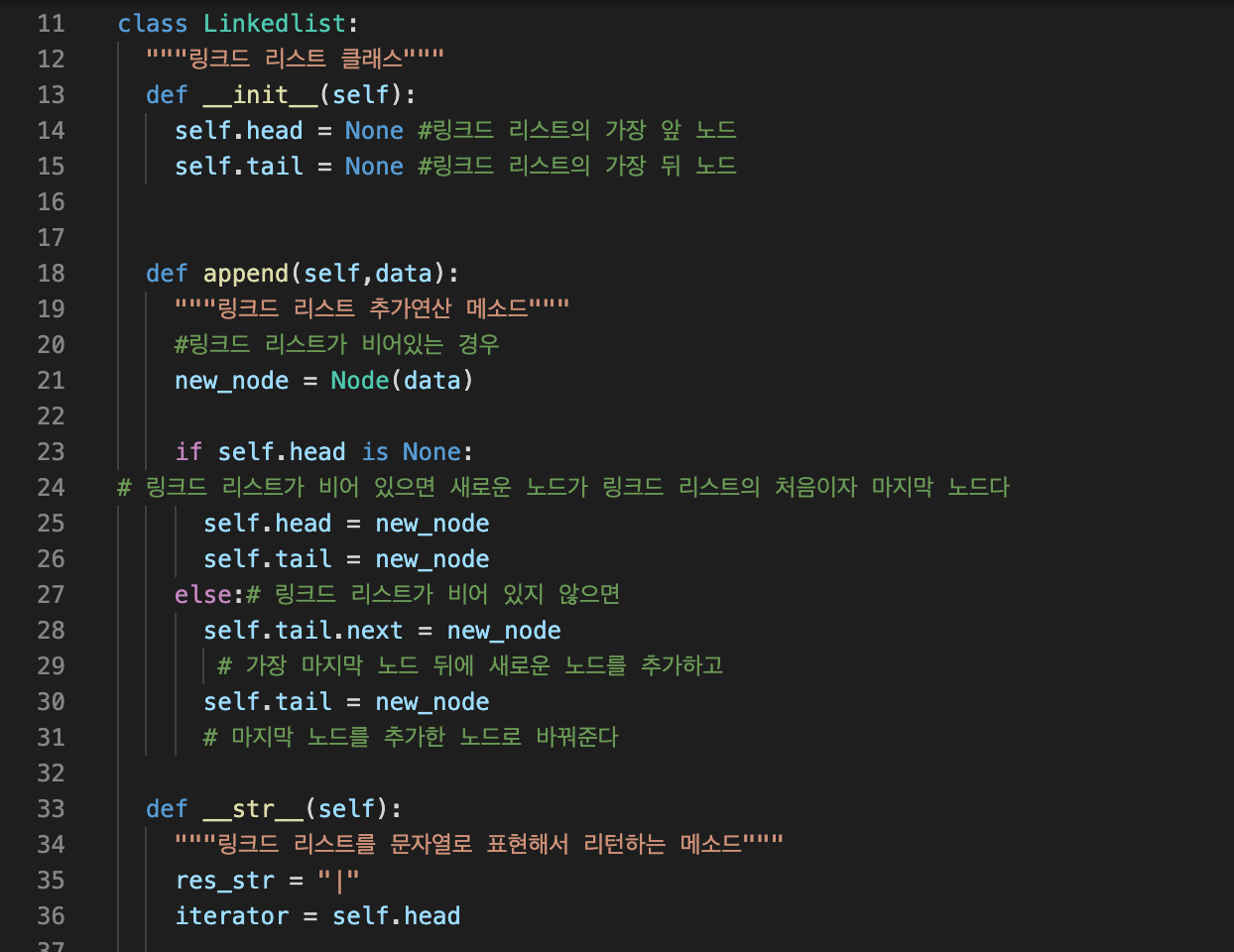
6.__str__링크드-리스트

시간복잡도에서 배열과 달리 링크드리스트는 효율적이지 않음 head Node에서 하나씩 다 찾아봐야되기때문에 O(n)
8.linked-list 실습과제


기존 tail 노드와 new_node를 연결시킴 그후 tail 노드를 new_node로 설정해줌previous_node.next 가 new_node가 들어설 자리previous_node의 레퍼런스로 new_node를 설정함
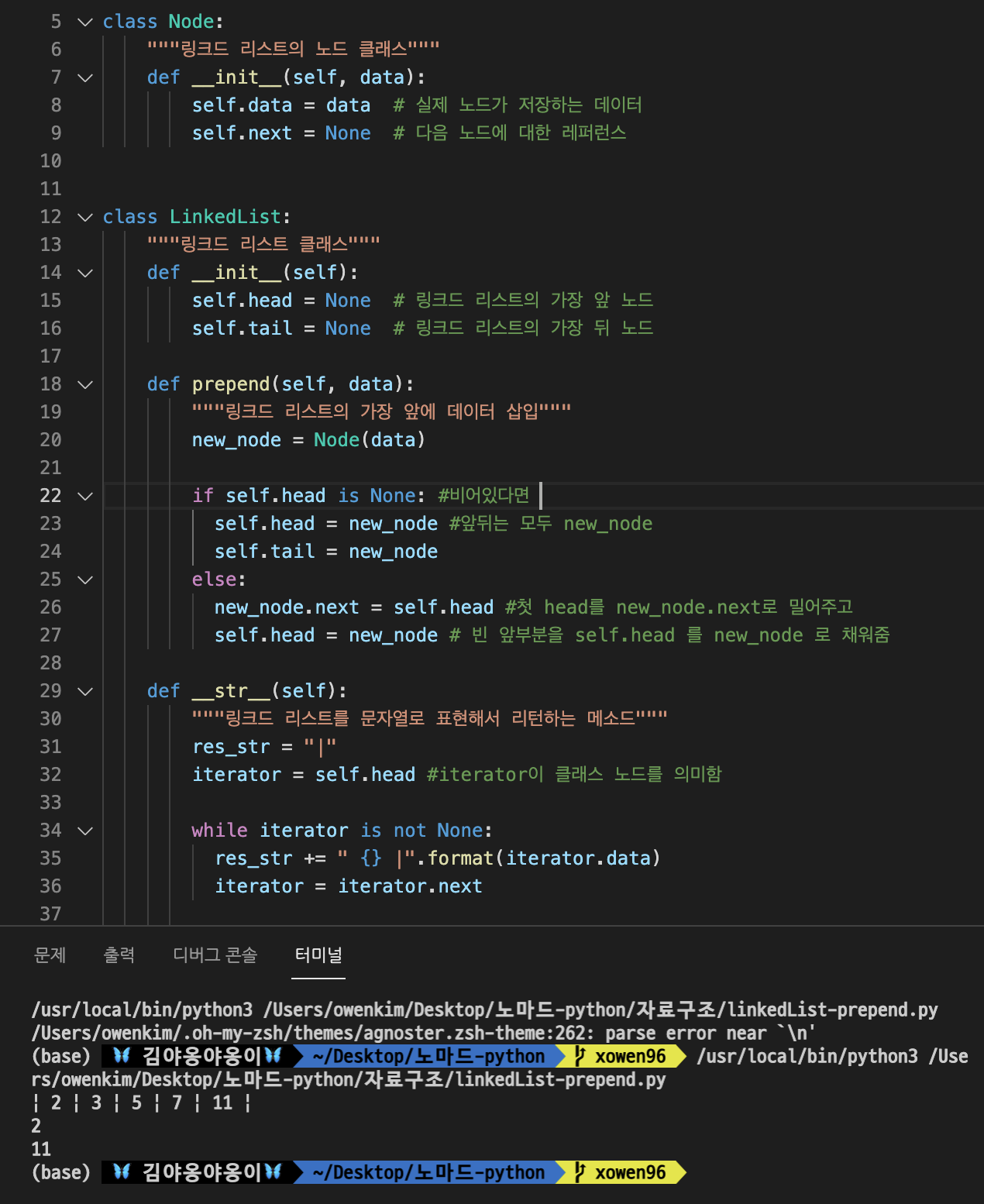
10.실습 과제 prepend: 링크드 리스트 가장 앞 삽입

node_2 = 인덱스 2 뒤 데이터 삭제 2 3 13 -> 11 (7삭제)second_to_last_node = tail 노드 삭제 2 3 13 (11삭제 뒤에 none)
12.linked-list popleft: 링크드 리스트 가장 앞 삭제



다음 노드에 대한 레퍼런스만 갖는경우 = 싱글리 링크드 리스트다음 노드의 정보나 전 노드의 정보까지 모두 포함하는 = 더블리 링크드 리스트next 와 prev 를 동시에 가짐 self.data, self.next, self.prev싱글리 링크드 리스트의 노드와 같다
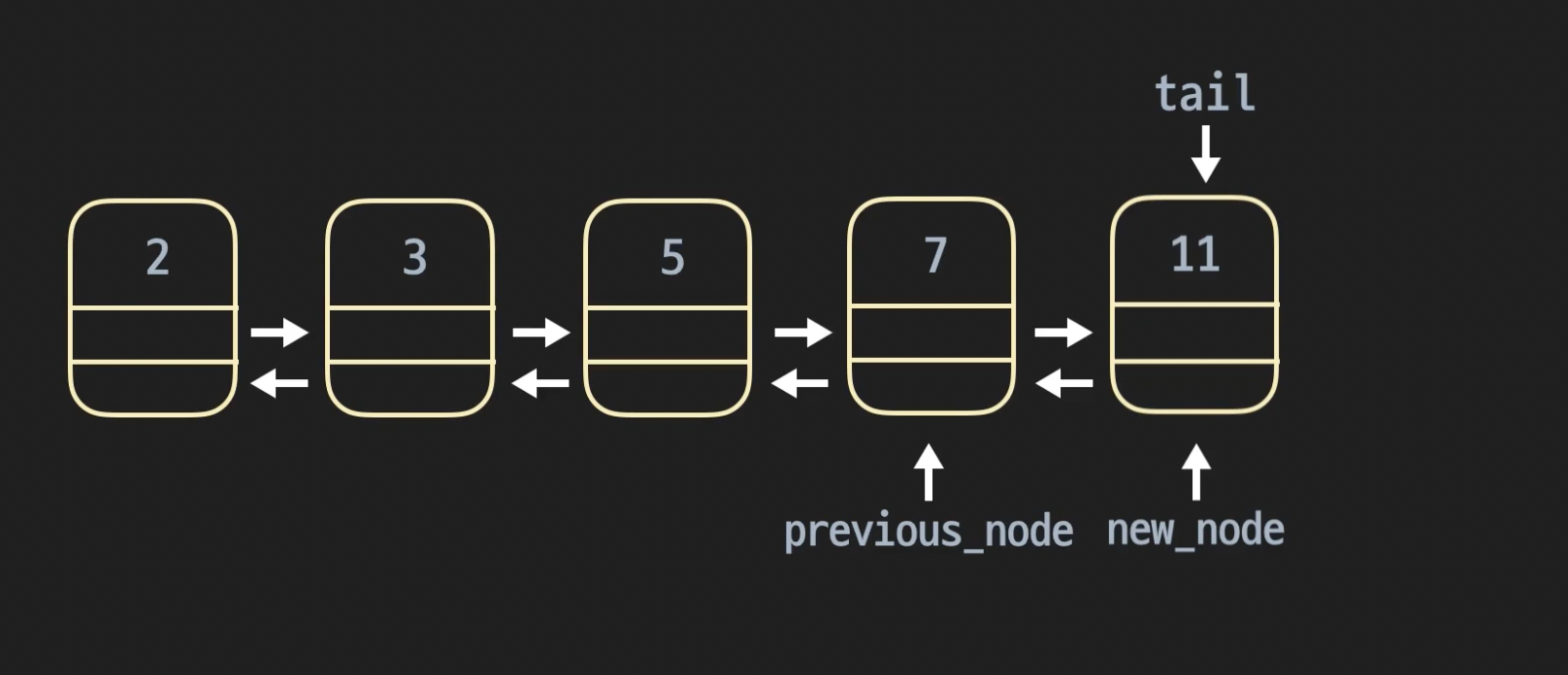
15.과제- 더블리 링크드 리스트 삽입


지우려는 노드 자체를 파라미터로 넘겨줌 1. 지우려는 노드가 마지막 노드일 경우 

더블 링크드 리스트는 다음 노드.next 와 전 노드 .prev의 레퍼런스를 가진다싱글 링크드 리스트는 다음 노드.next 만 레퍼런스를 가진다둘다 추가적 공간 측면에서는 O(n)이지만 현실적으로 더블 링크드 리스트가 싱글 링크드 리스트 보다 2배정도 더 차지 하기
20.Direct-Access Table

0 부터 943 의 배열 크기를 만들고 거기에 Key - Value 쌍 값으로 값을 지정해준다. 이러한 인덱스를 직관적이게 찾아갈 수 있는 것을 direct access table 이라고 하는데 이는 자칫 잘못하면 배열의 크기를 너무 크기 잡아버려 공간 낭비를 할 수
21.Hash-Table
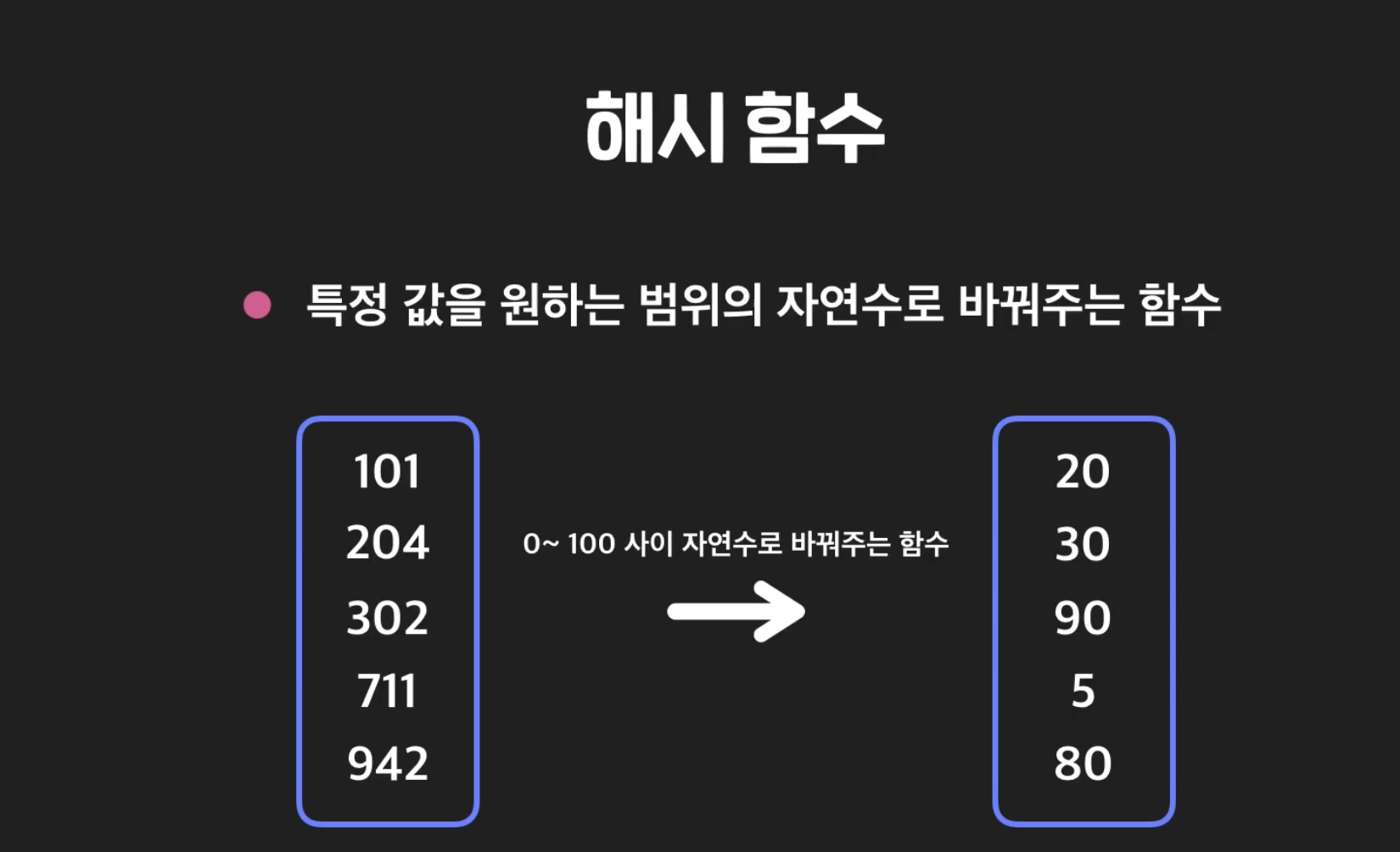
앞에서 Direct Acess Table 은 자칫 잘못하면 메모리 공간을 낭비 한다고 했는데, 이러한 시간과 메모리 둘다 효율적으로 사용하는 Hash Table = (해쉬 함수와 배열을 같이 사용) 한 인덱스에 키와 벨류를 모두 저장함.해쉬함수의 조건해쉬 함수 나누기
22.해시 테이블 충돌과 Chaining 개념
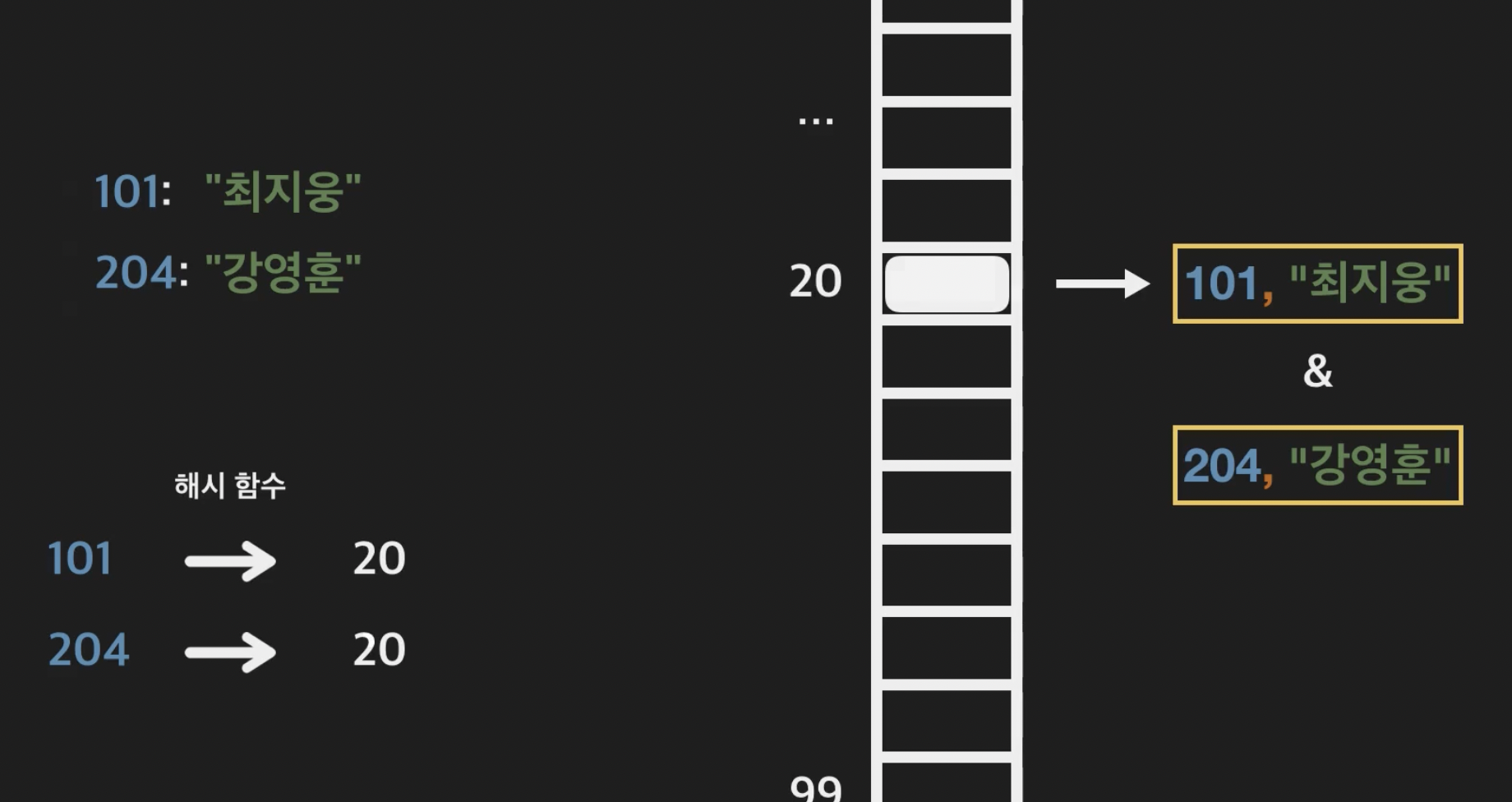
해시함수를 사용하더라도 같은 값이 나오게 된다면 같은 인덱스에 두 키 쌍을 저장해야되는데 그럴때 충돌(collision)이 발생된다. 이럴땐 chainning 으로 연결시켜주는데 앞에서 배웠던 인덱스 배열에 linked-list 개념을 활용한다. Chaining을 이용
23.Chaining을 쓰는 해시 테이블 시간복잡도 -탐색,삽입,삭제,
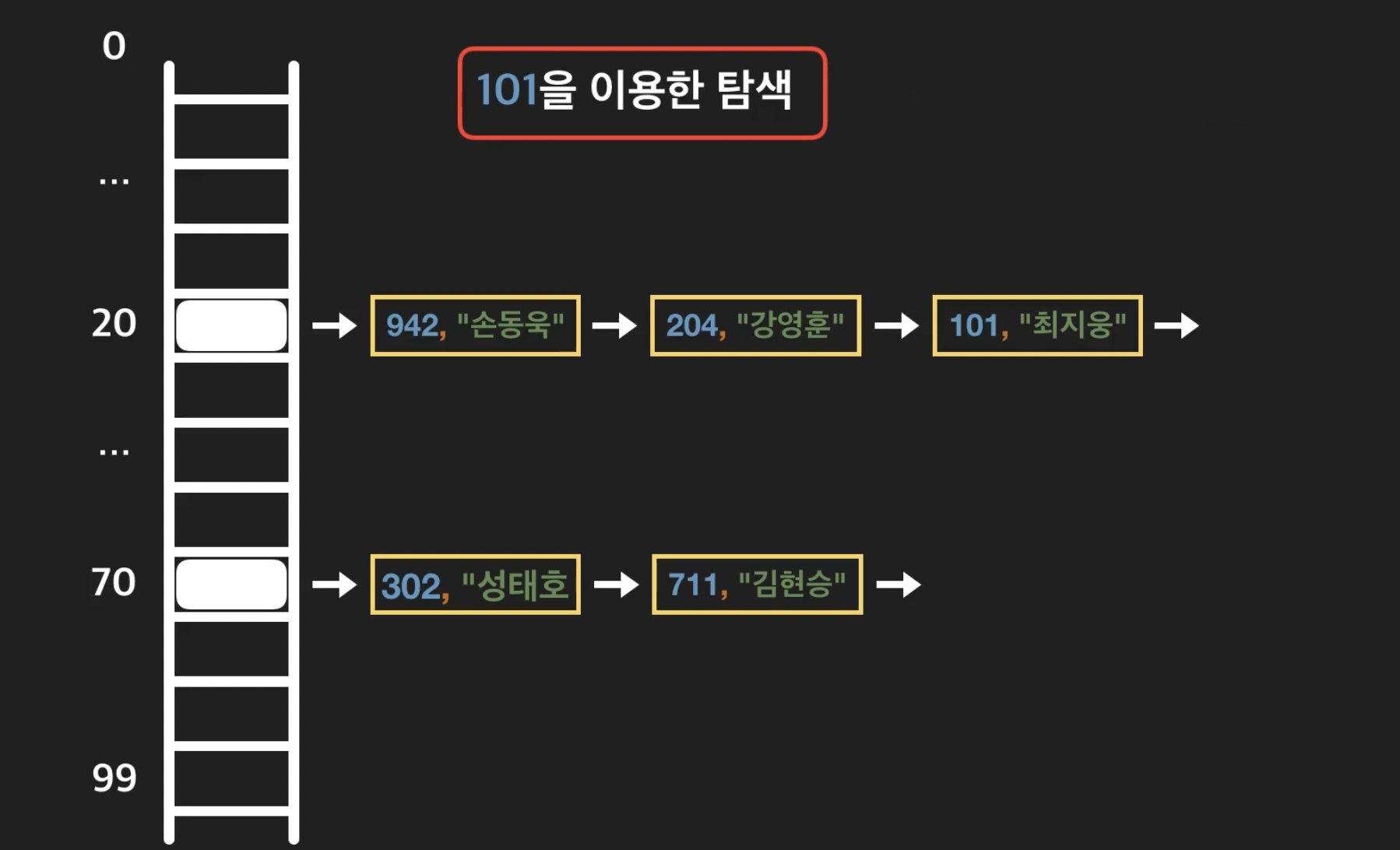
원하는 key 를 가지고 있는 노드가 있는지 선형 탐색을 함 원하는 데이터를 찾으면 value를 리턴 n개의 key-value가 동일한 인덱스에 저장될 경우 탐색하면 최악의 경우로 시간복잡도는 O(n)해쉬함수의 결과값을 이용해 배열의 인덱스에 접근 저장된 링크드리스트에
24.과제 -Chaining을 쓰는 해시 테이블 구현 I
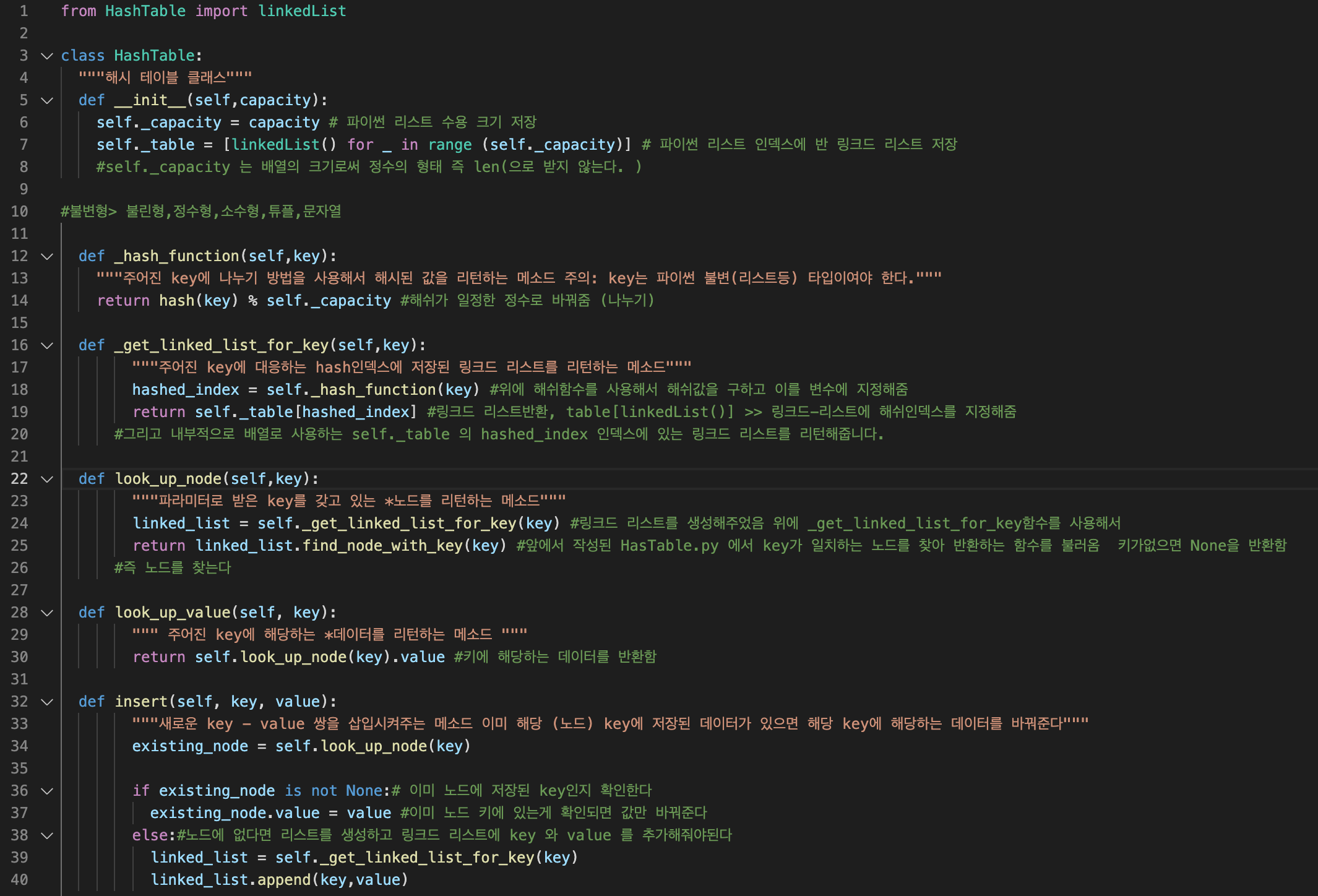
실습과제from Hastable.py import linkedList from Hastable.py import linkedlist 을 통해 Hastable.py 파일에서 linkedlist이라는 클래스나 함수만을 가져오는 것을 의미합니다.파라미터 key에 대한 데이터
25.Chaining을 쓰는 해시 테이블 구현 -delete

python 에는 이미 delete 메소드가 내장되어있으니 이를 활용하면 된다.
26.Open Addressing (선형탐사, 제곱탐사)
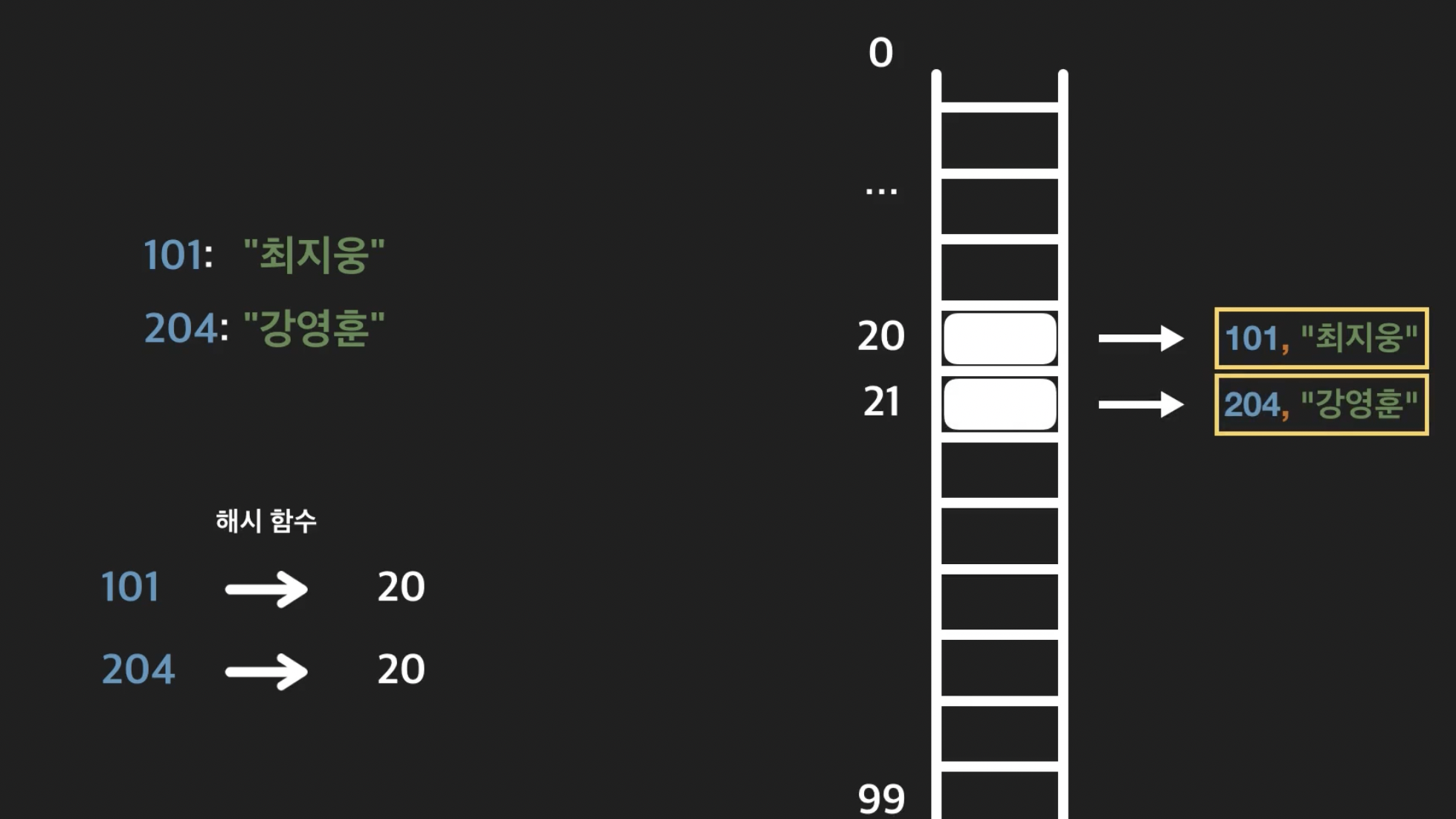
앞선 Channing 에서는 한 인덱스에 같은 hash 값이 있는 key-value 쌍이 저장 됬을 경우 병렬형태로 데이터를 저장해서 충돌을 막아줬었다.open addressing은 channing 과 달리 비어있는 인덱스를 찾아서 그곳에 데이터를 저장함으로써 데이터
27.Open Addressing 탐색/삭제 연산
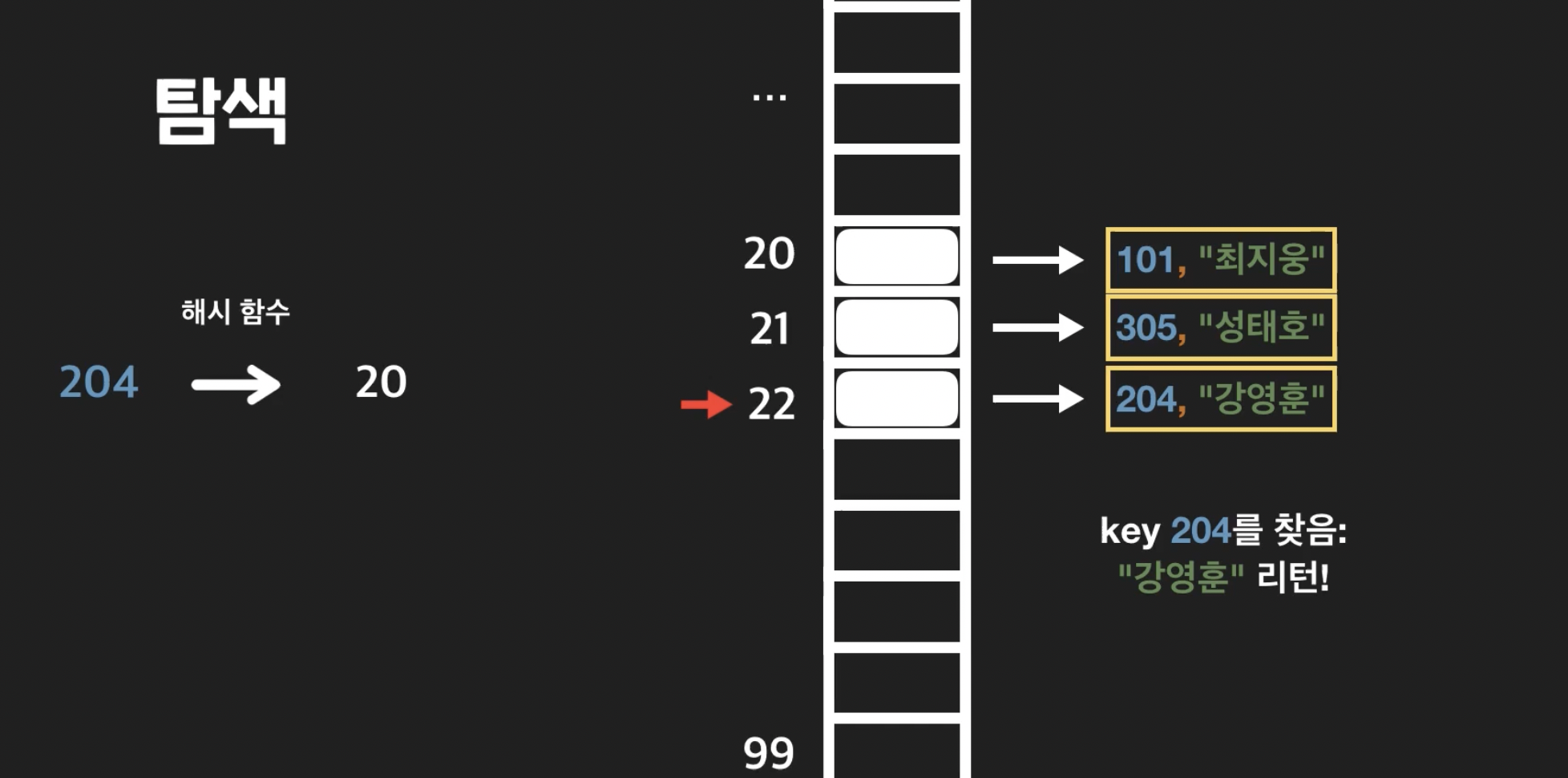
순서대로 선형 탐색을 하여 key를 찾고 그에 맞는 값을 리턴해줌 하지만 선형 탐사를 하다가 비어있는 부분을 찾게 된다면 애초에 204 라는 key 가 저장되지 않았음을 뜻한다 . 왜냐면 선형탐사는 순차적으로 비어있는 인덱스를 찾아서 값을 저장해주기 때문임.hash
28.Open Addressing을 쓰는 해시 테이블 시간 복잡도

Open Addressing 의 삽입 연산은 탐사를 통해서 빈 인덱스를 찾고, 탐색과 *삭제 연산은 원하는 key를 갖는 데이터 쌍을 찾는다.
29.추상화 (추상 자료형vs자료구조)

구현을 몰라도 기능만 알면 사용할 수 있게 해주는 것, 코드를 재활용하고 협업할때 중요!추상자료형을 생각하면 코드의 흐름에 집중 할 수 있다.기능을 나열해놓음각 연산을 어떻게 할지에 대하여 묶어논 개념, 구체적으로 구현까지 포함한 내용자료구조 (동적배열 과 링크드리스트