삼진 탐색은 이진 탐색과 같은 분할정복 알고리즘입니다.
다만, 탐색 대상을 세 부분으로 나누어 탐색한다는 점에서 차이가 있고
이진 탐색처럼 정렬된 데이터에서만 사용할 수 있습니다.
삼진 탐색에서는 중간값을 두 개(mid1, mid2)로 나누어 탐색 범위를 좁혀 나갑니다.
삼진 탐색 과정
- 초기화 :
배열의left와right인덱스를 설정한 후, 두 중간값mid1과mid2를 계산합니다.
mid1 = left + (right - left) / 3
mid2 = right - (right - left) / 3
이렇게 세 부분으로 배열을 나눕니다 :
[left, mid1], [mid1 + 1, mid2 - 1], [mid2, right].
- 값 비교 :
-
target이mid1또는mid2와 같으면 해당 인덱스를 반환합니다. -
target < mid1이면 배열의 왼쪽 부분에서 탐색을 재귀적으로 수행합니다. -
target > mid2이면 배열의 오른쪽 부분에서 탐색합니다. -
target이mid1과mid2사이에 있으면 중간 부분에서 탐색합니다.
- 반복 :
탐색 공간이 더 이상 없거나 목표값을 찾을 때까지 과정을 반복합니다. 끝까지 찾지 못하면-1을 반환합니다.
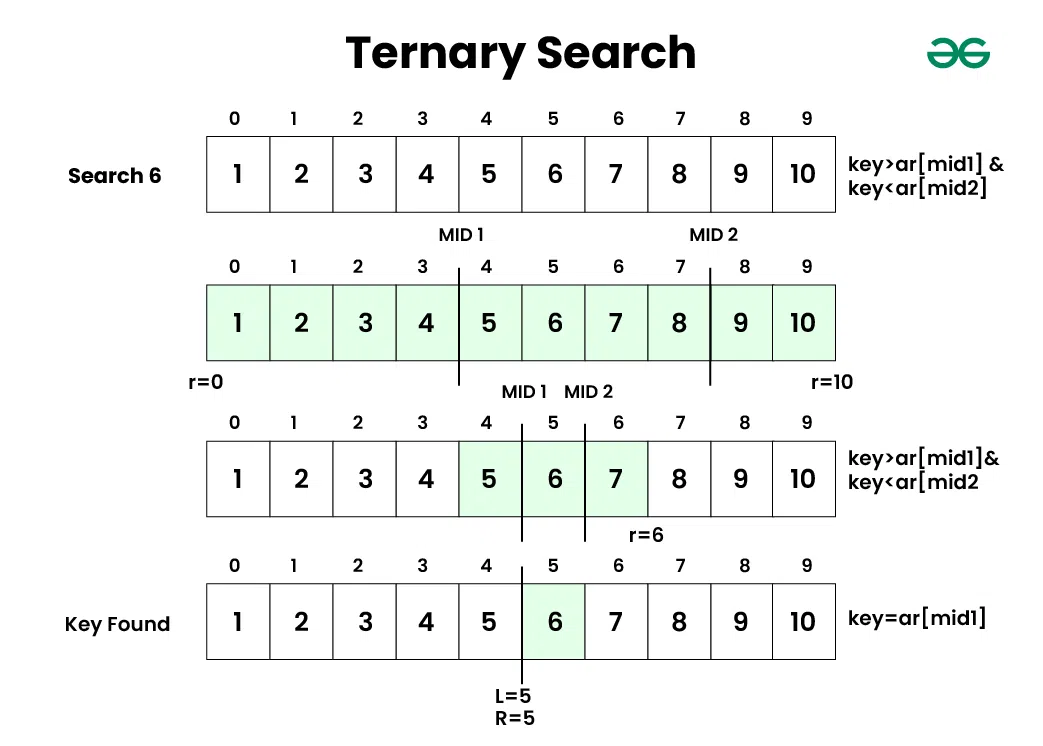
출처: GeeksforGeeks
구현
#include <stdio.h>
// 삼진 탐색 함수
int ternarySearch(int l, int r, int key, int ar[]) {
while (r >= l) {
int mid1 = l + (r - l) / 3;
int mid2 = r - (r - l) / 3;
// key가 mid1 또는 mid2에 있는 경우
if (ar[mid1] == key) return mid1;
if (ar[mid2] == key) return mid2;
// 왼쪽 부분 탐색
if (key < ar[mid1]) {
r = mid1 - 1;
}
// 오른쪽 부분 탐색
else if (key > ar[mid2]) {
l = mid2 + 1;
}
// 중간 부분 탐색
else {
l = mid1 + 1;
r = mid2 - 1;
}
}
return -1; // key를 찾지 못한 경우
}
int main() {
int ar[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int l = 0, r = 9, key = 5;
int p = ternarySearch(l, r, key, ar);
printf("Index of %d is %d\n", key, p);
key = 50;
p = ternarySearch(l, r, key, ar);
printf("Index of %d is %d\n", key, p);
return 0;
}성능평가
-
시간 복잡도 :
삼진 탐색은 배열을 세 부분으로 나누기 때문에 이진 탐색보다 조금 더 많은 비교가 필요하지만, 큰 차이는 없습니다. -
공간 복잡도 :
반복문을 사용하는 경우 추가 메모리 사용이 거의 없습니다.
장점
-
단봉 함수 최적화 문제에 적합합니다. 이진 탐색으로 찾기 어려운 최대값, 최소값을 찾는 데 유리합니다.
-
선형 탐색보다 빠르고, 이진 탐색과 유사한 시간 복잡도를 가집니다.
단점
-
정렬된 배열에서만 사용할 수 있습니다.
-
단조 함수에서는 이진 탐색보다 시간이 더 소요될 수 있습니다.
-
분할이 한 번 더 발생하므로 특정 상황에서는 오히려 비효율적일 수 있습니다.
정리
삼진 탐색은 배열을 세 부분으로 나누어 목표값을 찾는 분할정복 알고리즘입니다.
이진 탐색보다 약간 복잡하지만, 최적화 문제에 적합하며 선형 탐색보다 훨씬 빠릅니다.
그러나 정렬된 배열에서만 사용할 수 있으며, 단조 함수에서는 오히려 이진 탐색보다 효율이 떨어질 수 있습니다.
