- 이번에는 문장간의 유사도를 통해 책을 추천하는 시스템을 작게 구현해보자
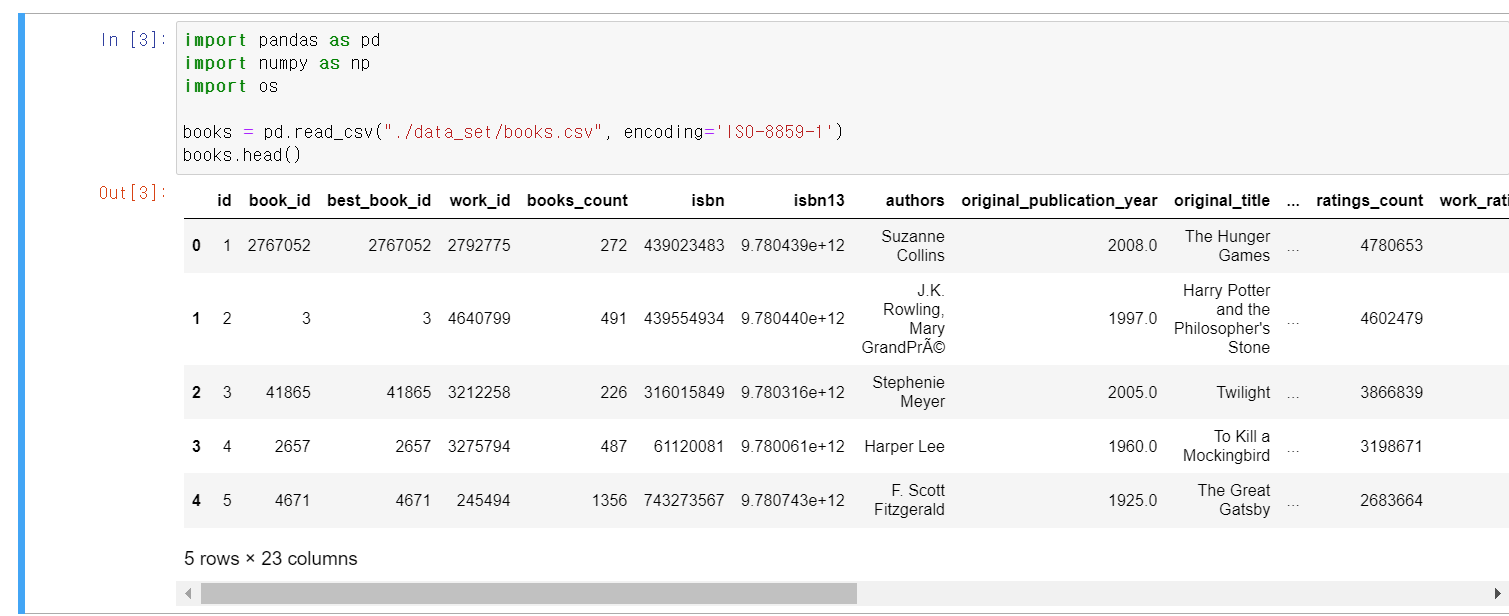
- 먼저 book 데이터를 업로드한다. 해당 데이터는 캐글에서 가져왔다.
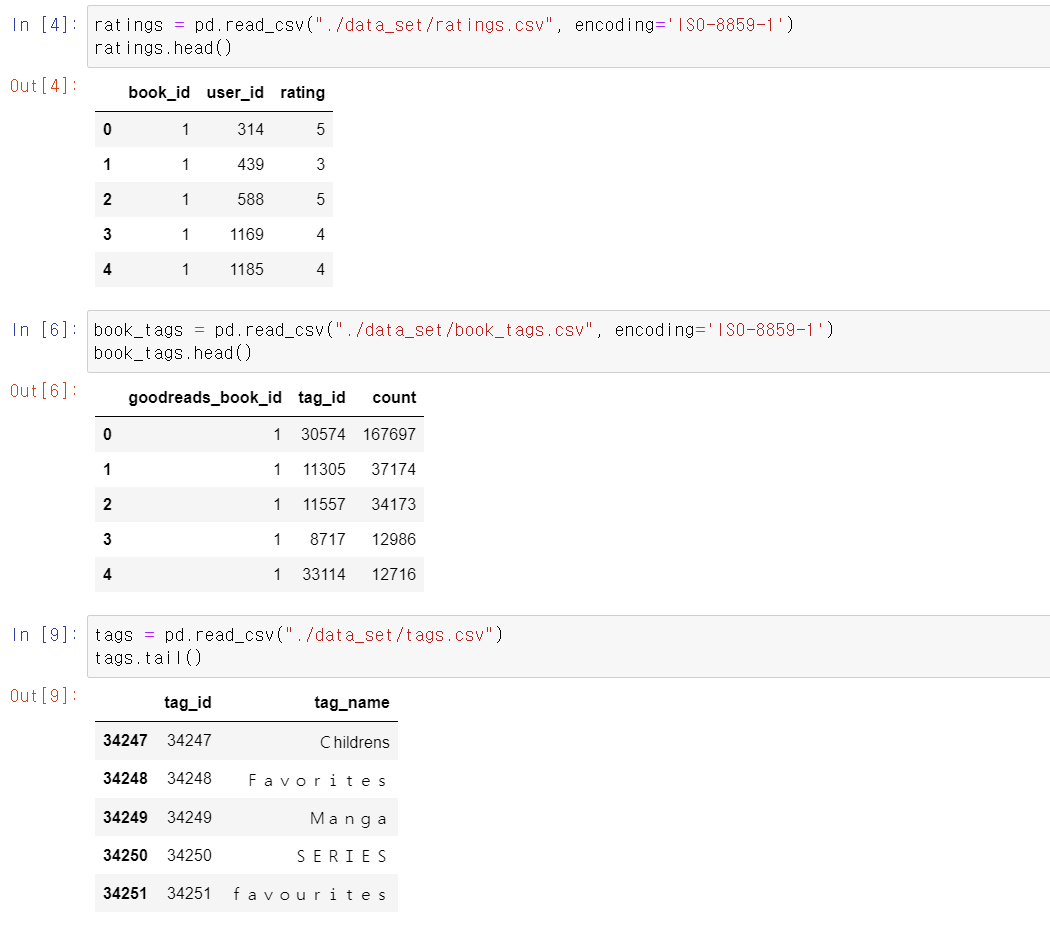
- 해당 여러 데이터로 구분되어 있는데 순위, tag, tag_name 등 여러 데이터를 불러왔다.
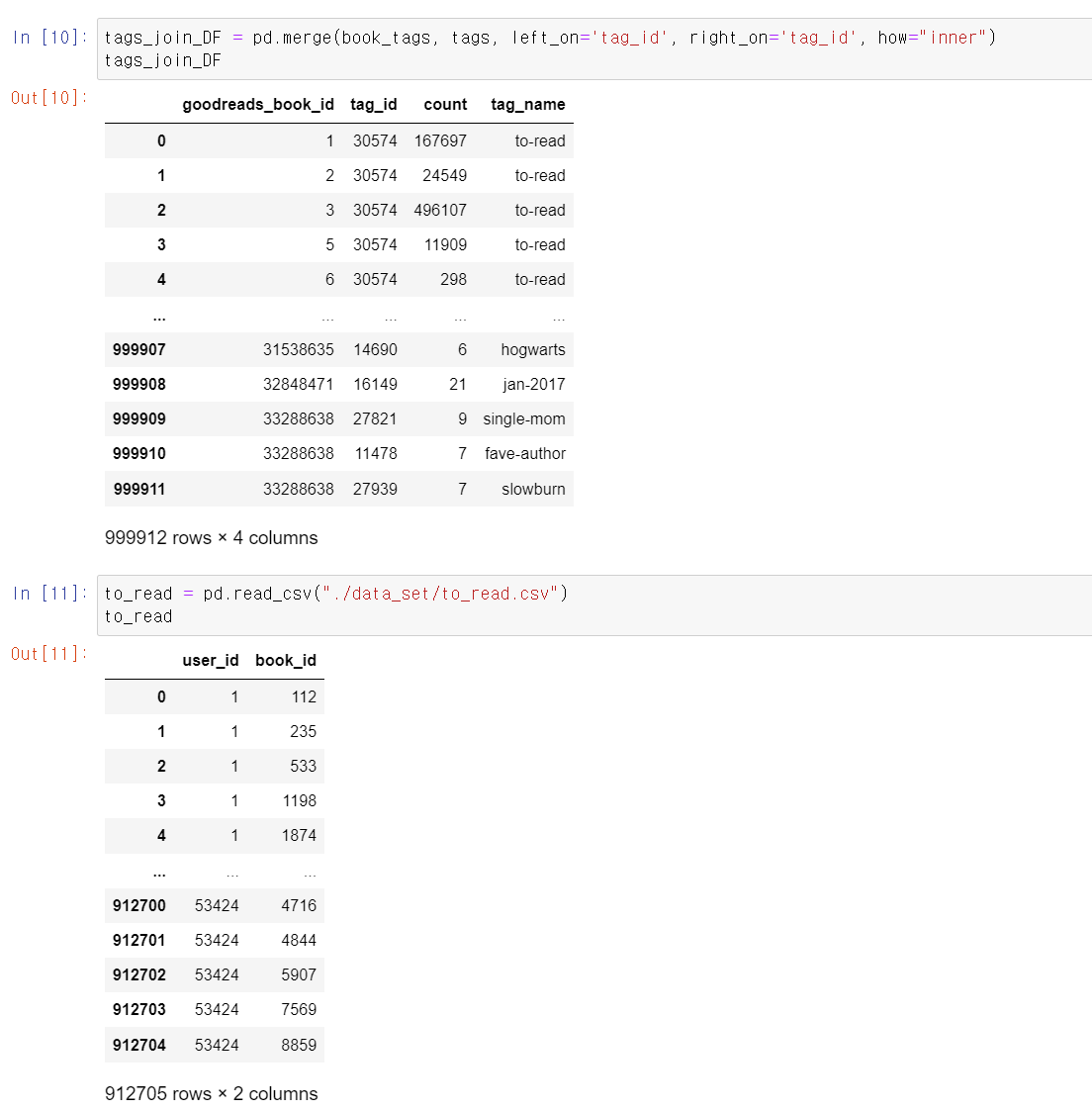
- 이제 분석하기 좋게 pandas의 merge를 사용해서 book_tag와 tag_name을 합치고, user_id가 있는 데이터를 불러왔다.
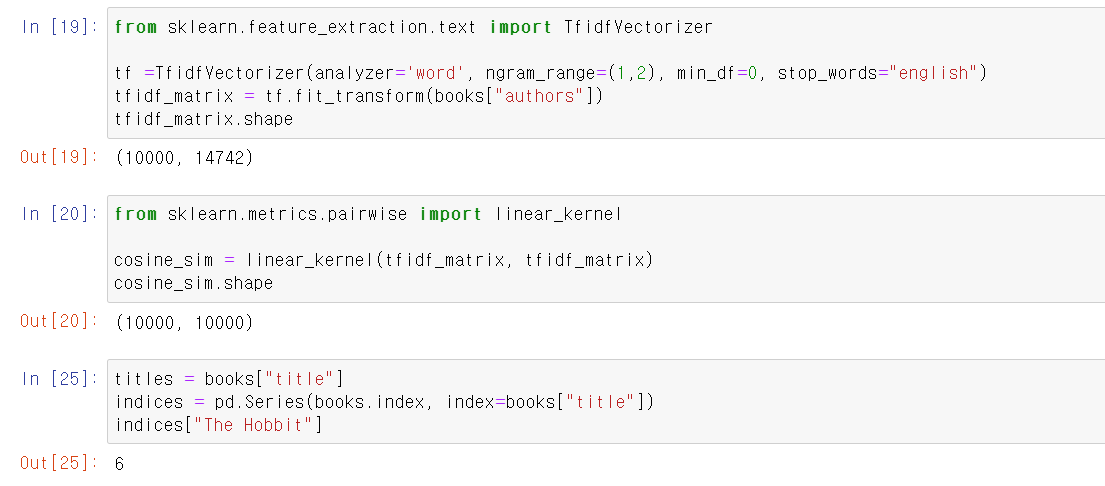
- 이제 Tfidvectorizer 모듈을 불러와서, books DF에서 작가 부분을 transform시켰다
- 그리고 해당 행렬을 linear_kernel모듈을 사용해서 cosine 유사도를 측정했다.
- 불연속적인 자료의 상관계수를 구할 때 코사인 유사도를 사용하는데 코사인 유사도의 값은 사이의 값을 가지며 공식은 이다.
user1 user2 user3 user4 user5
item1 1 0.9 0.8 0.7 0.3
item2 0.9 1 0.4
item3 1
item4 1
item5 1
- 빈칸이 너무 많으니 몇개는 생략하고, 위와 같은 형태로 두 변수간의 상관관계를 포현형식으로 행렬을 만들어준다.
- 이제 시리즈 형태로 title을 만들고 제목을 넣었을 때 해당 인덱스 번호를 나오게 만든다.
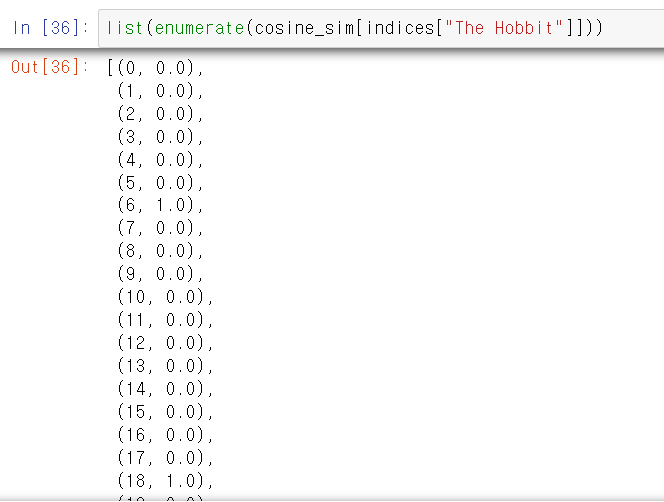
- 이제 인덱스 번호와 상관계수를 list형태로 만들어주고
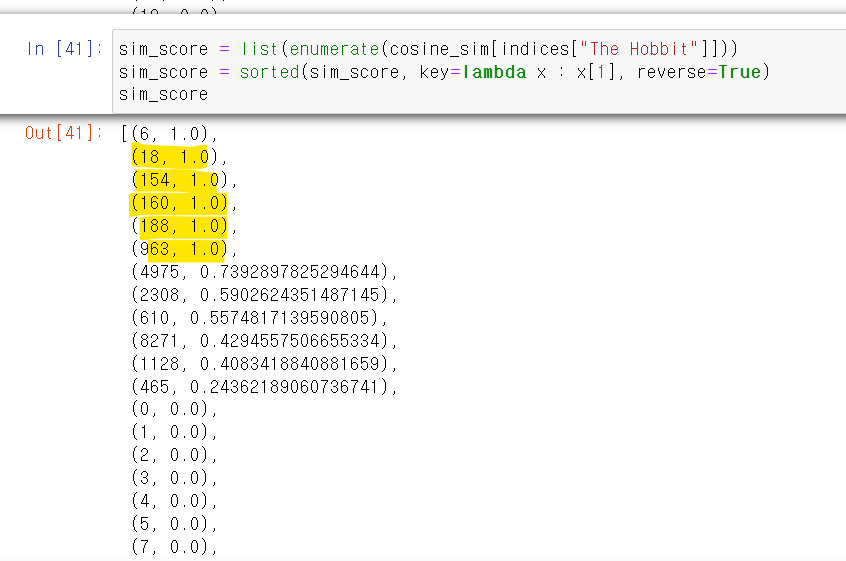
- 상관계수를 기준으로 내림차순으로 만들어주며, 해당 title과 유사도가 있는 영화의 인덱스와 상관계수를 내림차순으로 볼 수 있다.
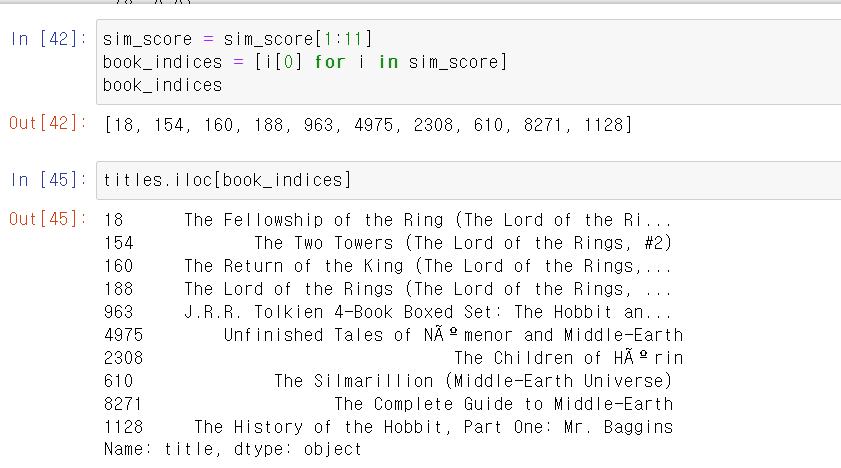
- 첫번째 인덱스는 검색한 타이틀의 제목이니까 1부터 11까지(10순위)만 지정하고, 리스트 안에 상관계수는 뺴고 인덱스 번호만 추출한 뒤 추출한 인덱스 번호를 아까 만든 titles시리즈에 넣으면 유사한 영화가 검색된다.
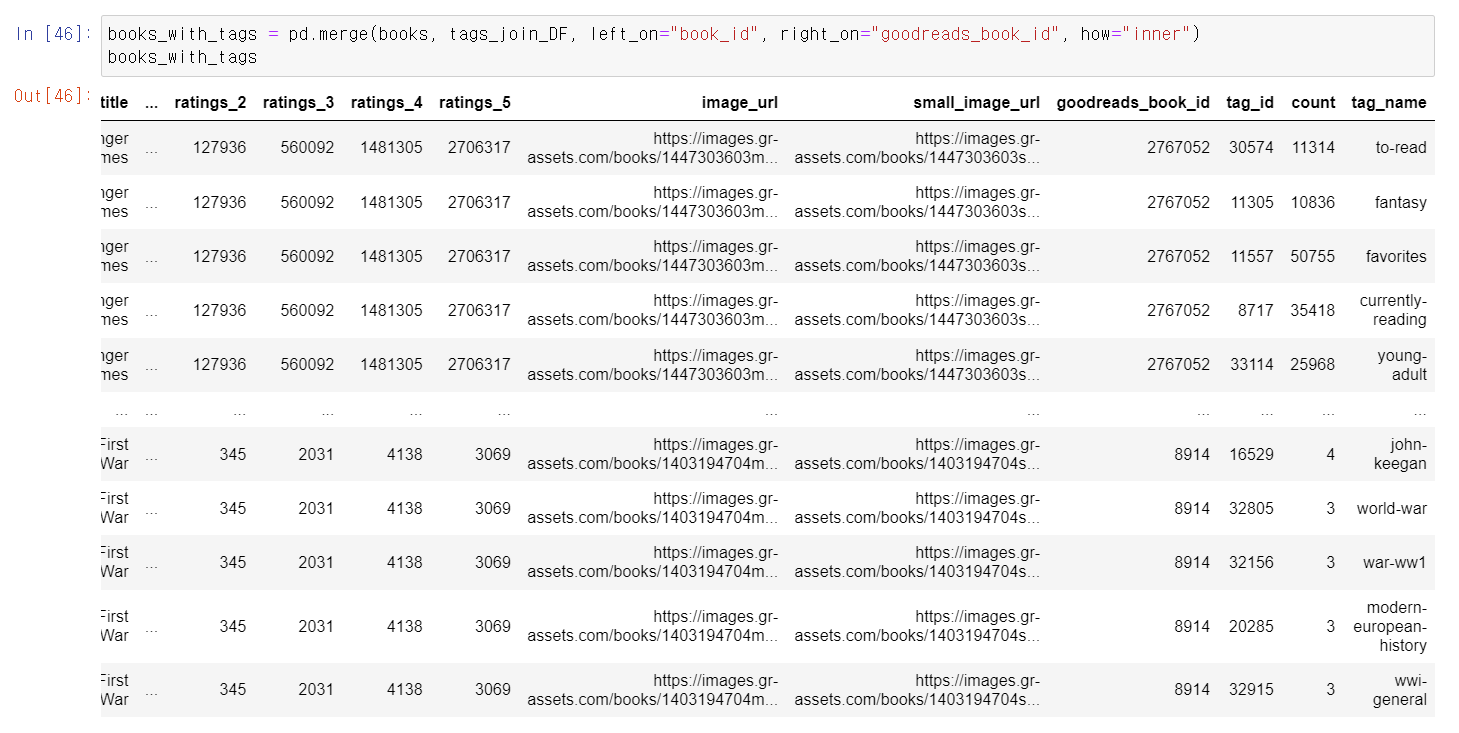
- 이제 더 정확한 추천 알고리즘을 만들기 위해 데이터를 가공해보자
- 먼저 books DF에 tag_name을 붙인다.
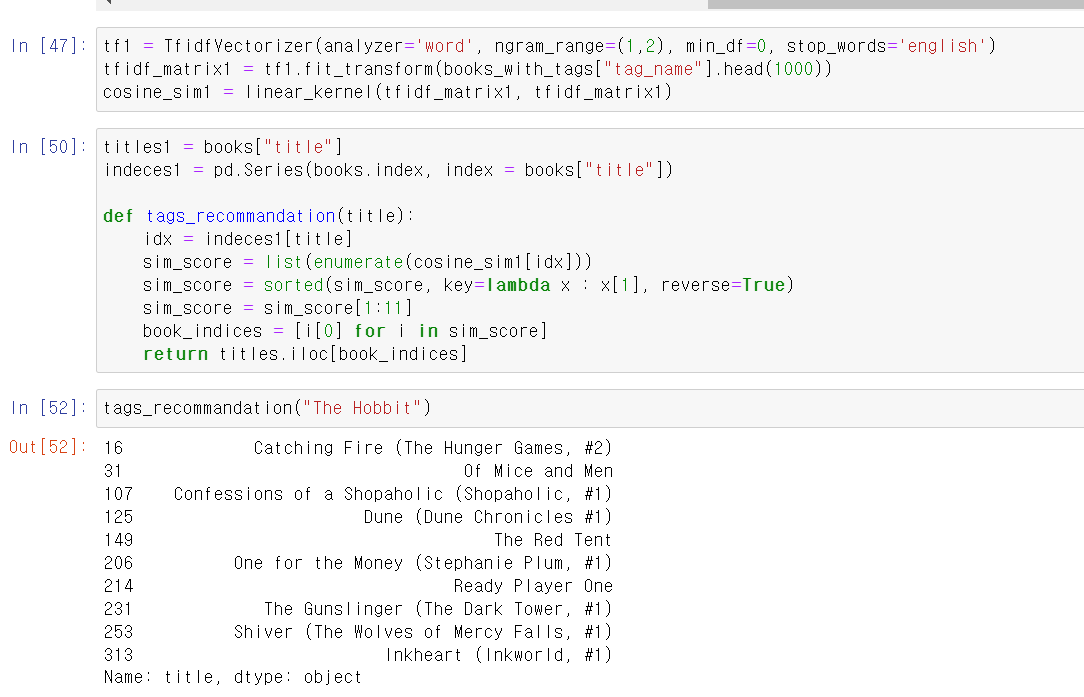
- 이제 해당 데이터를 아까와 같은 방법으로 데이터를 변환 후 매트릭스 형태로 상관계수를 나타나게 만든다.
- 이제 title을 넣어보니 아까와는 다른 결과가 나왔다.
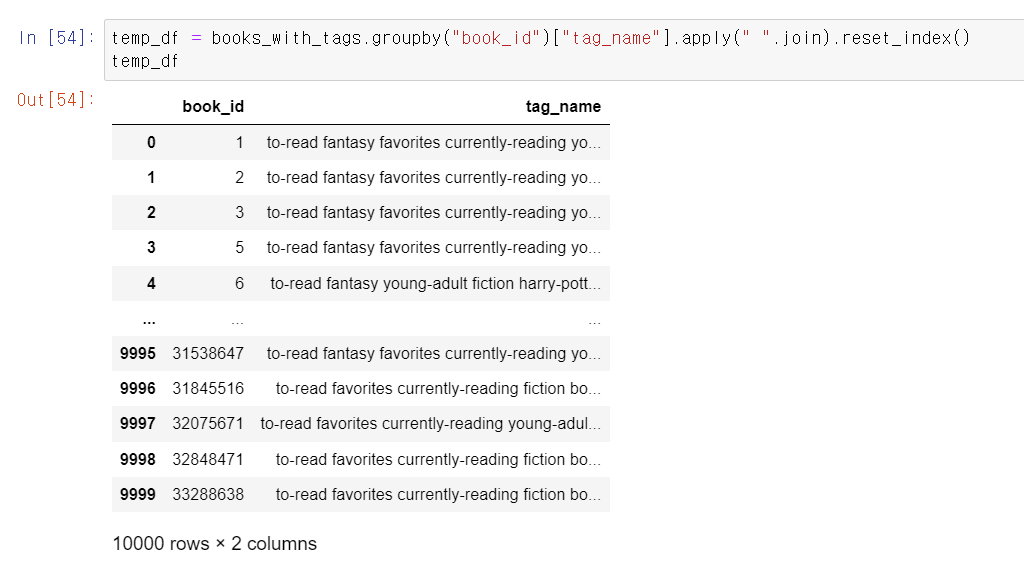
- 이번에는 다른 형태로 데이터를 가공해서 추천 알고리즘을 돌려보자
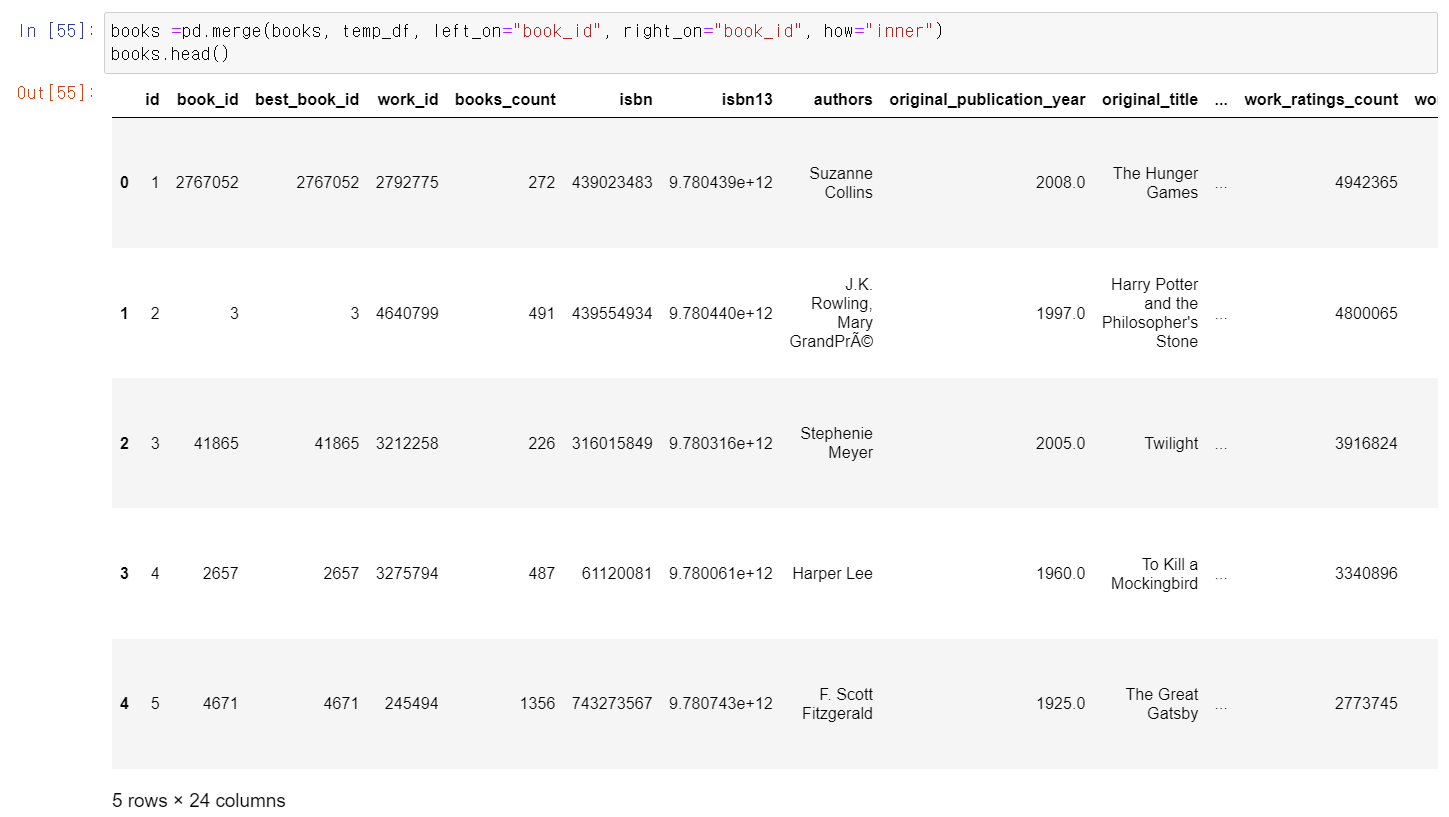
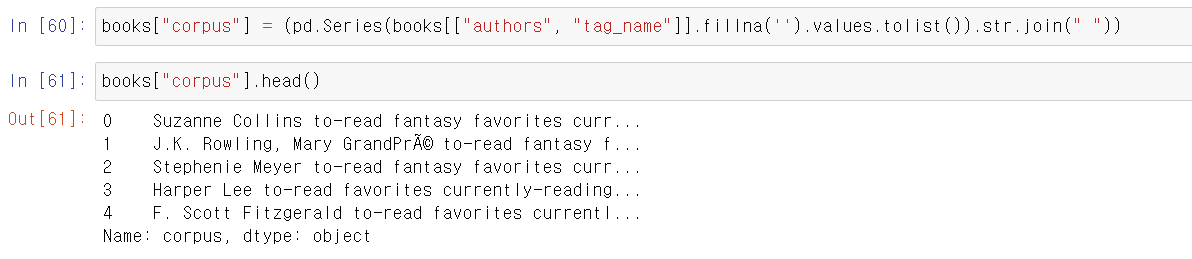
- 작가와 책 태그를 하나로 합친 corpus라는 컬럼을 만들고,
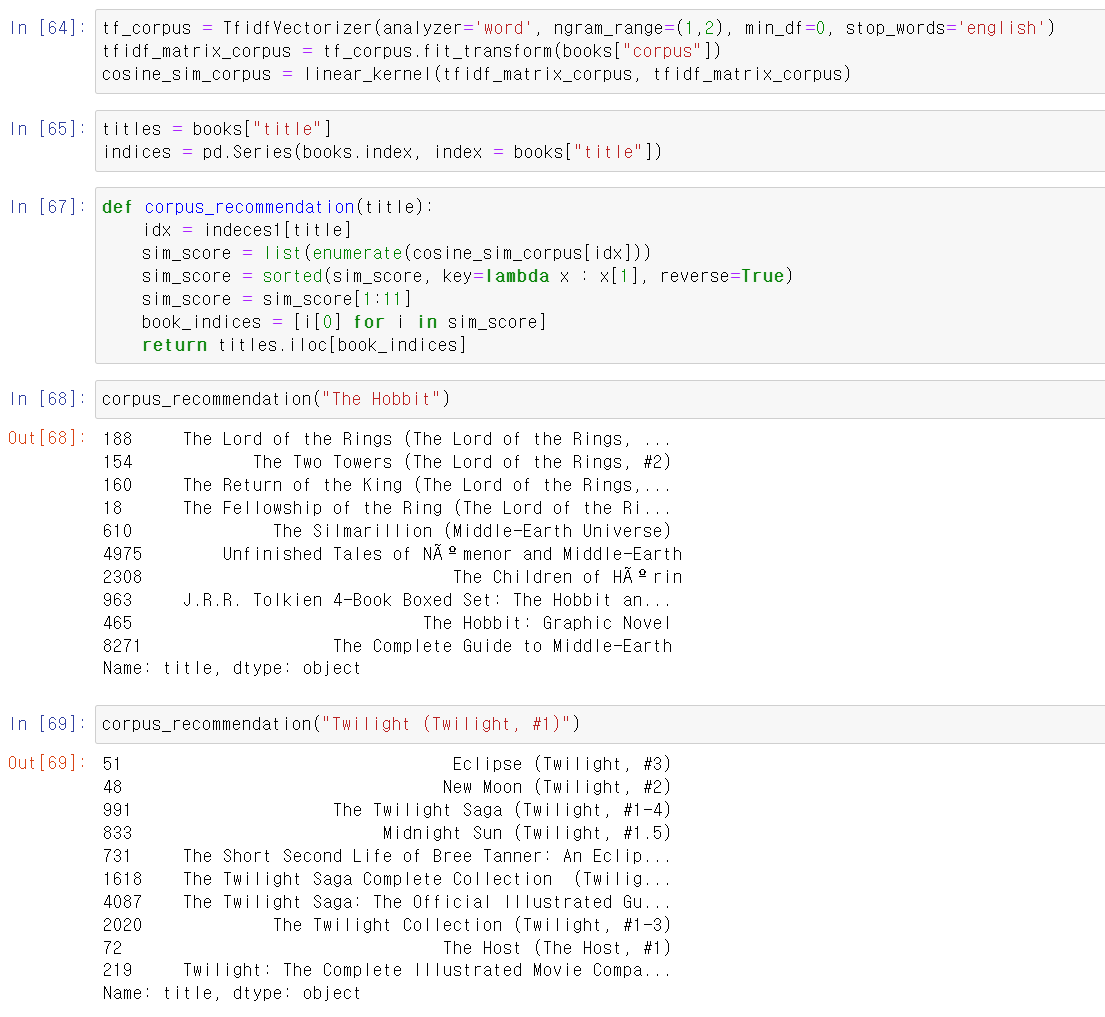
- 해당 컬럼을 Tfidvectorizer로 데이터를 변환 후 매트릭스 상관계수 형태로 만든다.
- 또한, 추천 영화를 출력하는 함수를 만든 뒤 호빗과 트와일라잇을 넣어보니 생각보다 괜찮은 추천 영화들이 나온다.

상황을 바꿀 수 없다면, 나를 바꾸자