ML_study
1.ML_intro

이제 머신러닝 데이터 분석을 시작해보자본격적인 머신러닝을 하기 이전에 어떤식으로 프로세스가 작동되는지 내가 먼저 스스로 머신이 됐다고 생각하고 러닝을 해보자, 일명 "Human learning'먼저 머신 러닝의 무조건적인 입문 자료 iris를 통해 시작했다.sklear
2.ML_iris
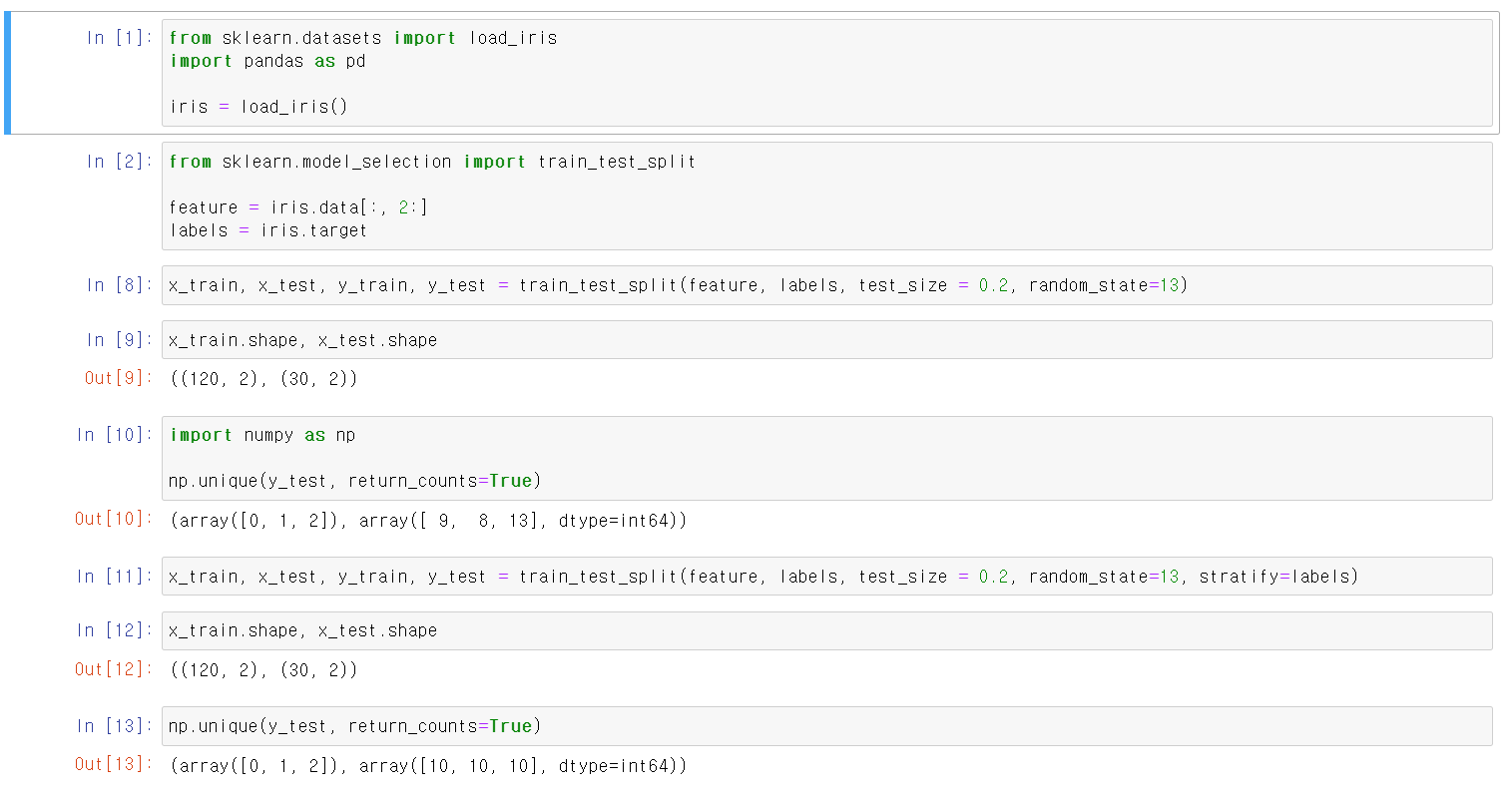
iris 데이터를 통해 다시 한 번 머신러닝의 과정을 이해해보자해당 과정에서 중요한 것은 데이터의 분리이다.현실적인 문제로 머신러닝 작업 시 분석 객체의 모든 데이터를 수집하는 것은 어렵다.그렇기에 수집한 데이터를 7:3 혹은 8:2로 분류 후 큰 데이터를 tranin
3.titanic
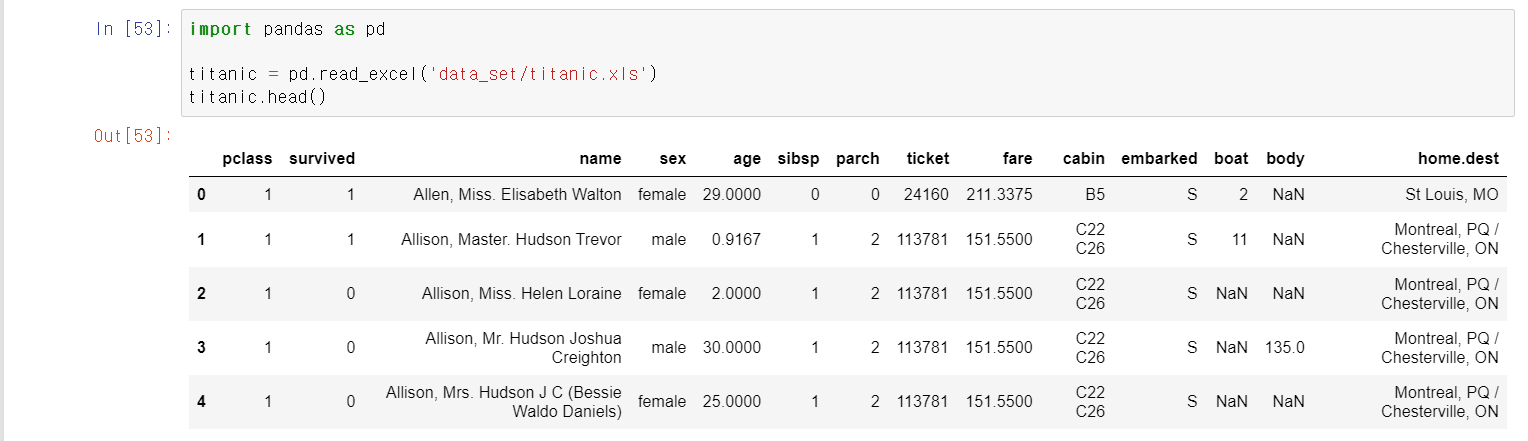
타이타닉 승객 정보를 통해 EDA분석 후 머신러닝을 통해 디카프리오와 윈슬렛의 생존 확률을 구해보자먼저 준비한 타이타닉 승객에 대한 정보를 DataFrame형식으로 저장matplotlib.pyplot과 seaborn으로 시각화를 통한 데이터 분석 시작앞에 그래프는 생존
4.preprocessing
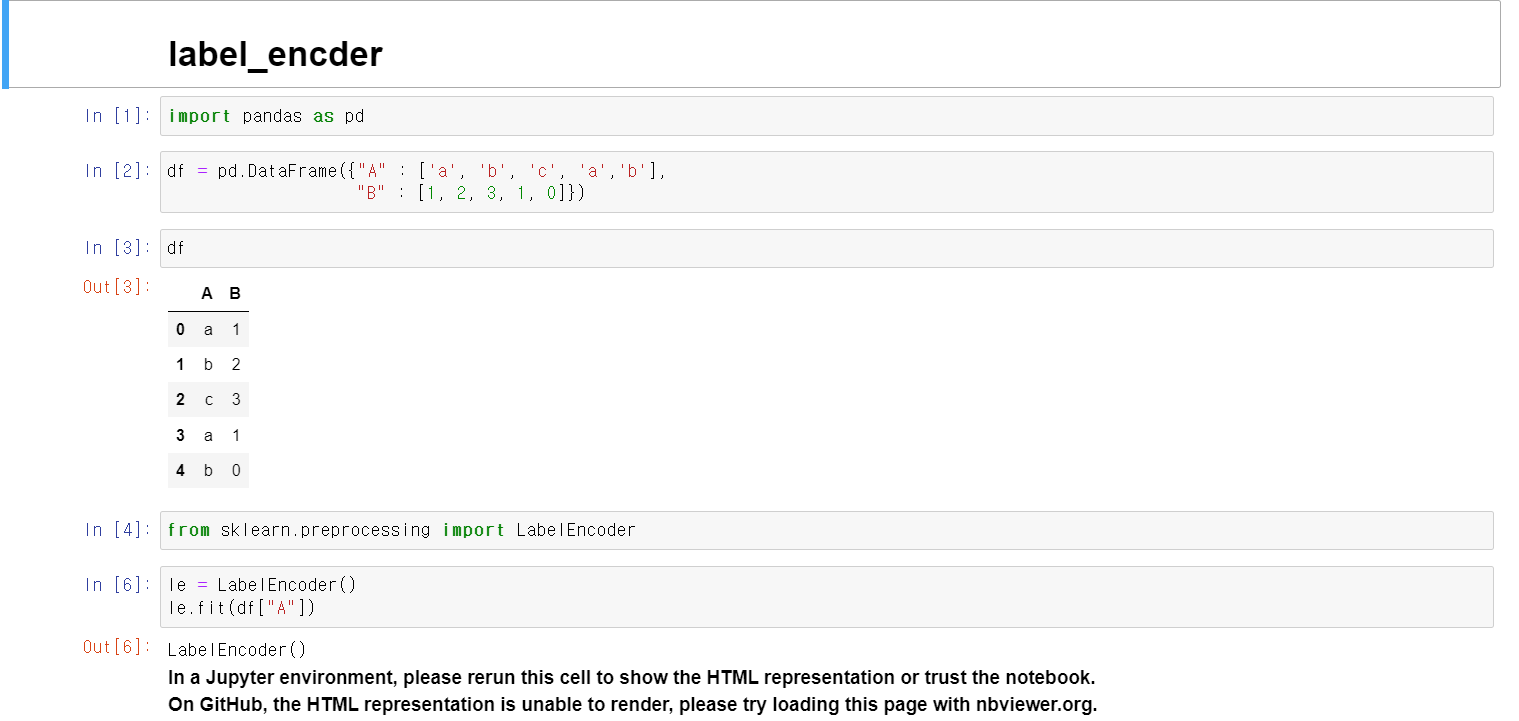
머신러닝에 사용하기 위해 자료값을 교육 후 변환시켜주는 기능이다.df자료에 A컬럼에 a,b,c 값이 존재하는데, 이를 sklean.preprocessing에 LabelEncoder로 교육시킴클래스는 기존의 값이 a,b,c이며, transform으로 변환 결과 0, 1,
5.Wine_Data
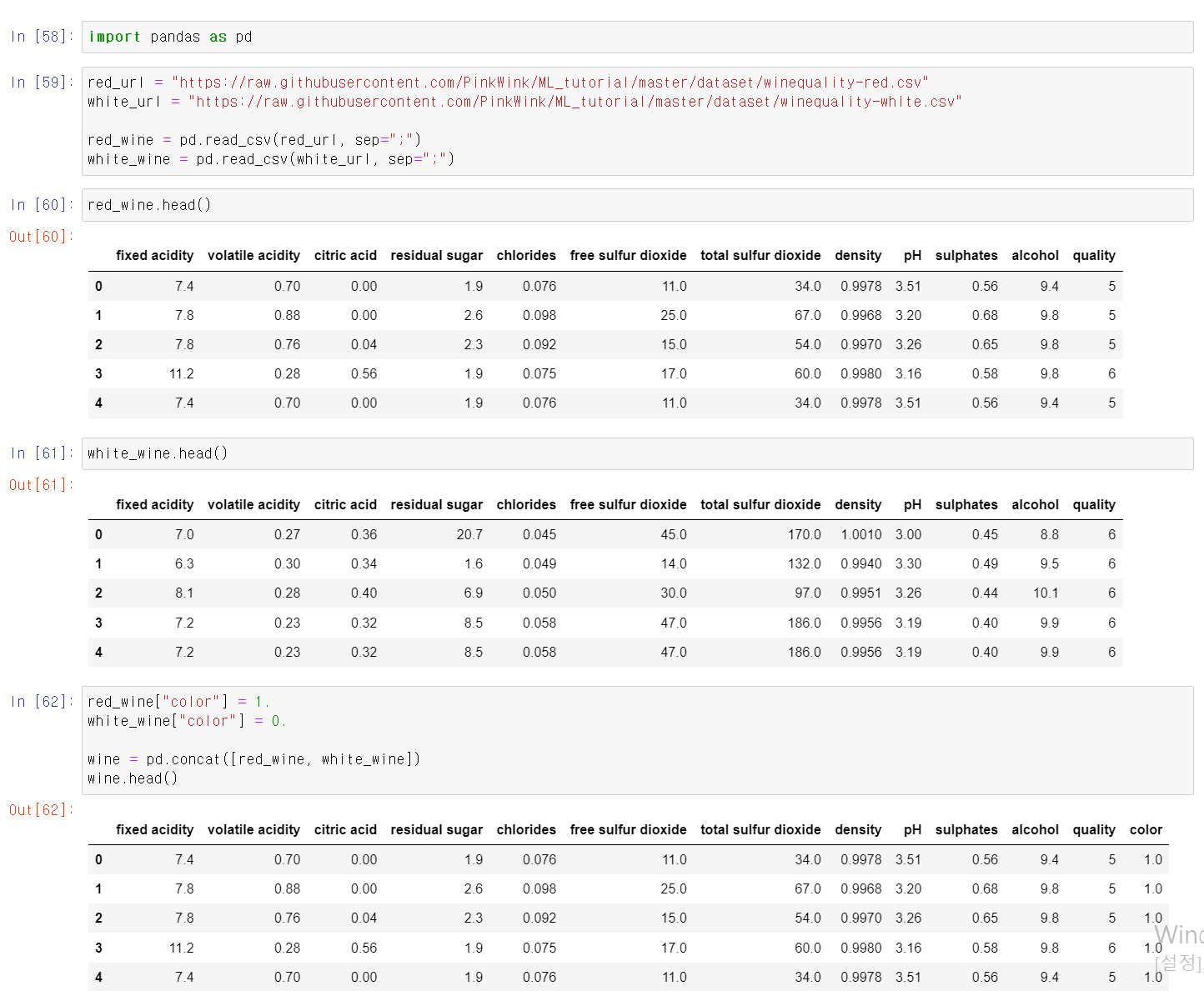
와인 성분 데이터를 통해 머신러닝을 조금 더 연습해보자준비한 자료를 변수에 저장 후 화이트 와인은 0, 레드 와인은 1로 컬럼을 추가 후, pd.concat으로 두 자료를 합친다.quality 변수를 각 값의 count를 분석 결과 3과 9가 가장 낮음레드 와인과 화이
6.Pipeline
이전에 머신러닝에서 DecisionTree, 자료 변환 등 여러 과정을 가지지만, 한 번에 해결하는 PipeLine이라는 기능이 존재함먼저 이전에 사용한 자료를 다시 변수에 저장 후리스트 안에 튜플 형태로 스케일과 교육 방법을 지정 후 해당 변수를 Pipeline에 저
7.cross validation
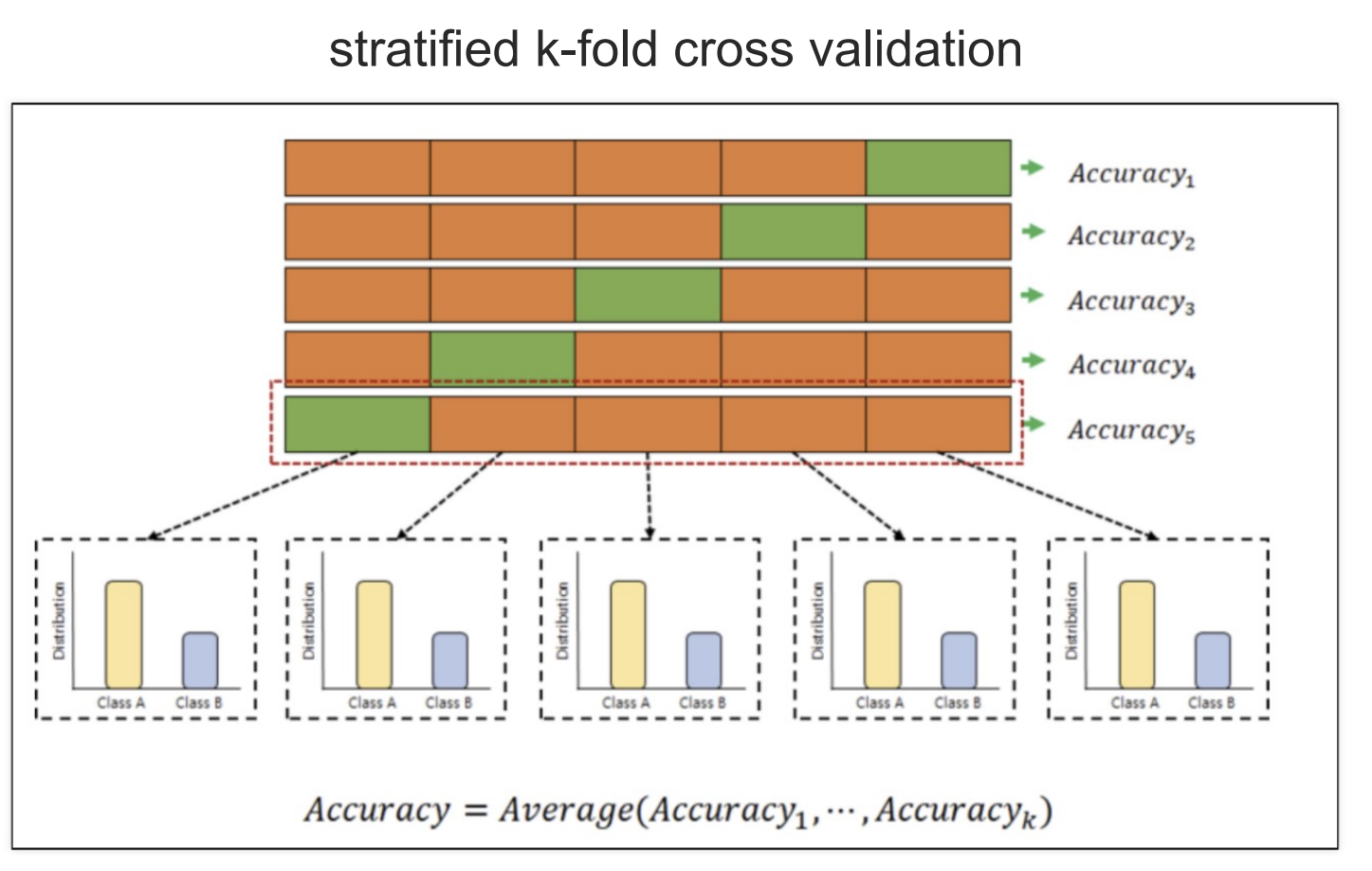
머신러닝에서 내가 분석할 때 자료를 검증하기 위해서 주어진 자료를 나눈 후 검증하는 교차검증이 있다.사용방법을 간단히 보기 위해 두 개의 변수를 가진 데이터프레임을 생성교차검증을 하는 모듈은 sklearn.model_selection에서 KFold이다.for문을 통해
8.Model Evaluation
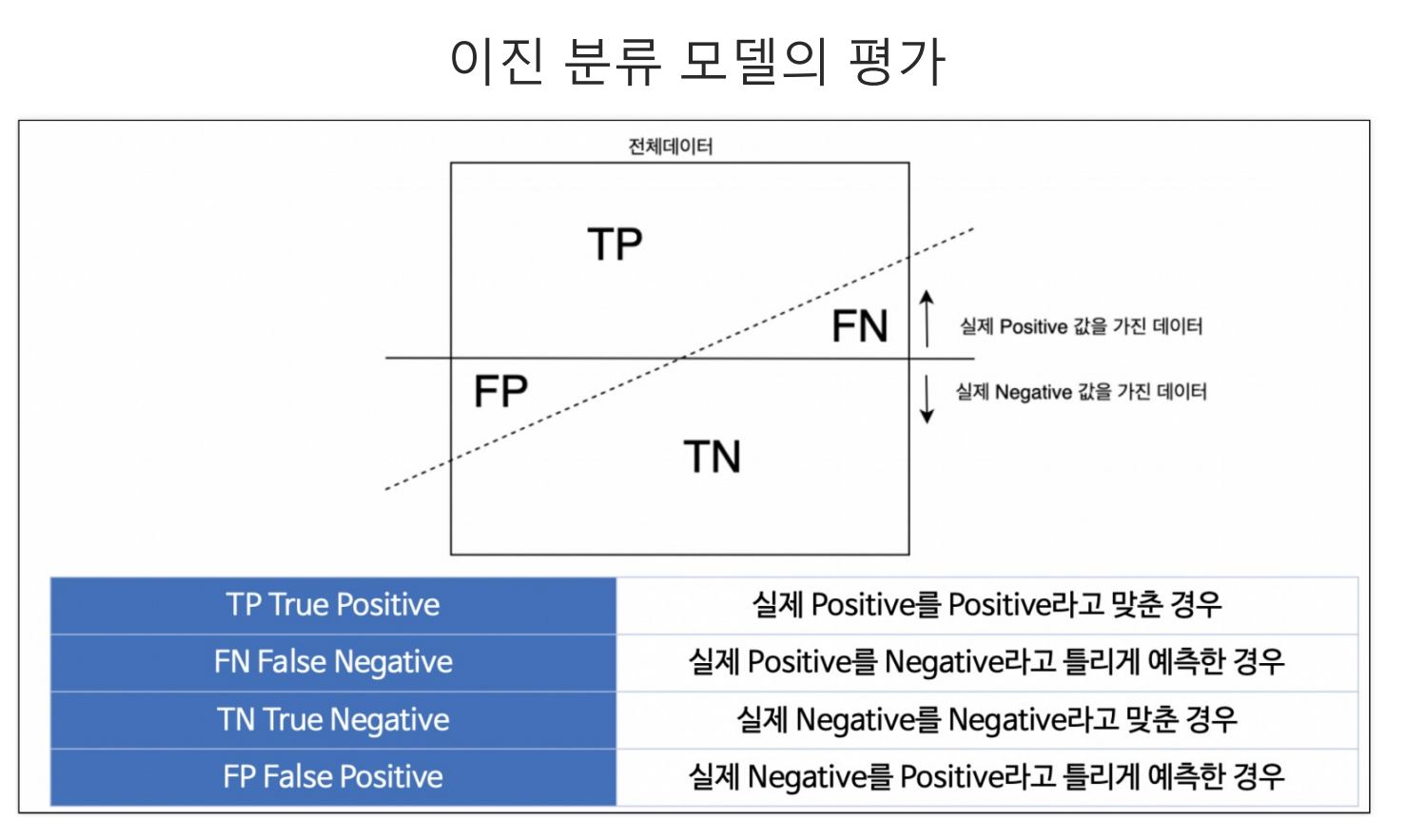
머신러닝에 새로운 input Data를 넣고 기존의 데이터로 만든 모델링을 통해 새로운 데이터를 예측하는 과정에서 4가지 영역으로 구분된다.TP(True Positive) : 실제 참값을 맞힌 경우FP(False Positive) : 실제 거짓 값을 참이라고 틀린 경우
9.math function
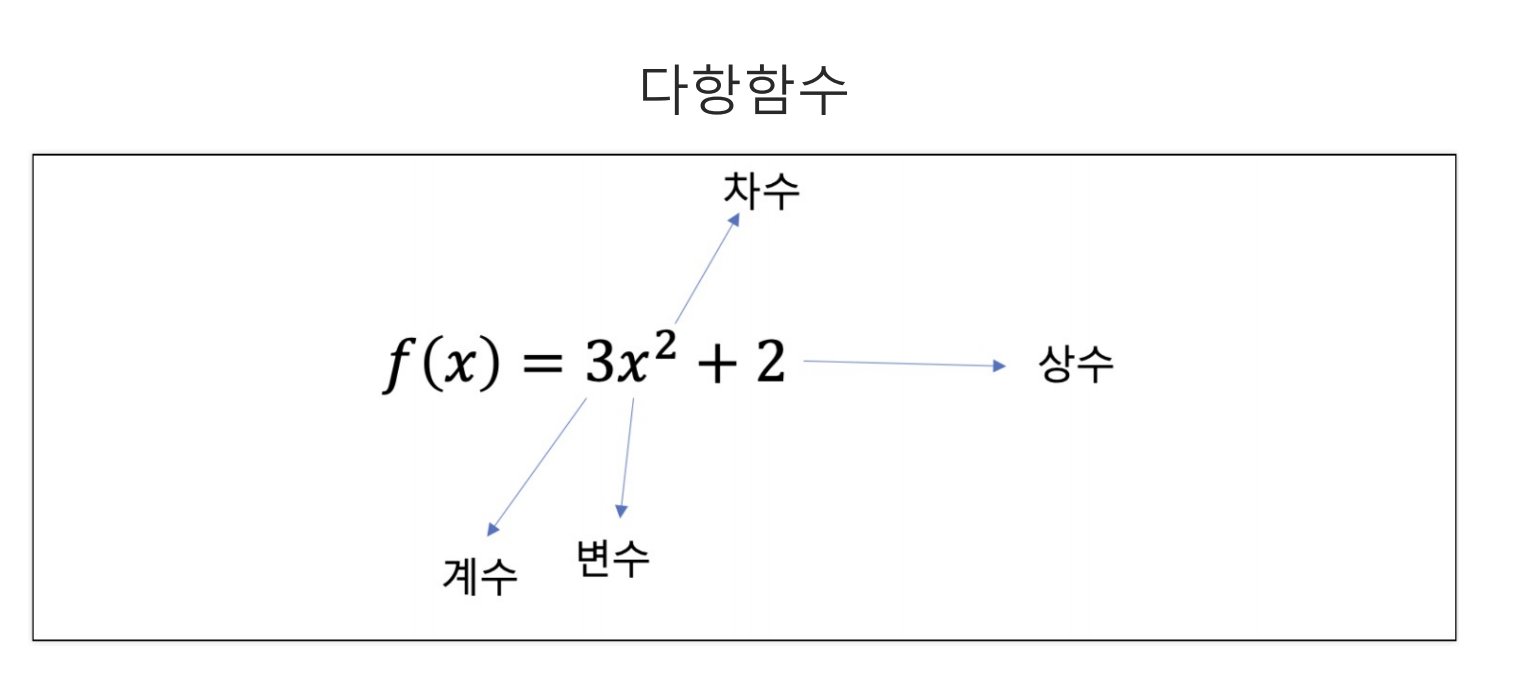
일반적인 다항함수는 $f(x) = nx^2 + 2$의 모양을 가진다$n$ : 계수이며, 이는 $x$값이 변함을 결정짓는 기울기이기도 하다.$x^2$ : 변수 위에 제곱에 따라 차수가 결정된다.해당 함수를 시각화하기 위해 numpy에 임의의 숫자를 $x$에 저장하고, $
10.box_plot
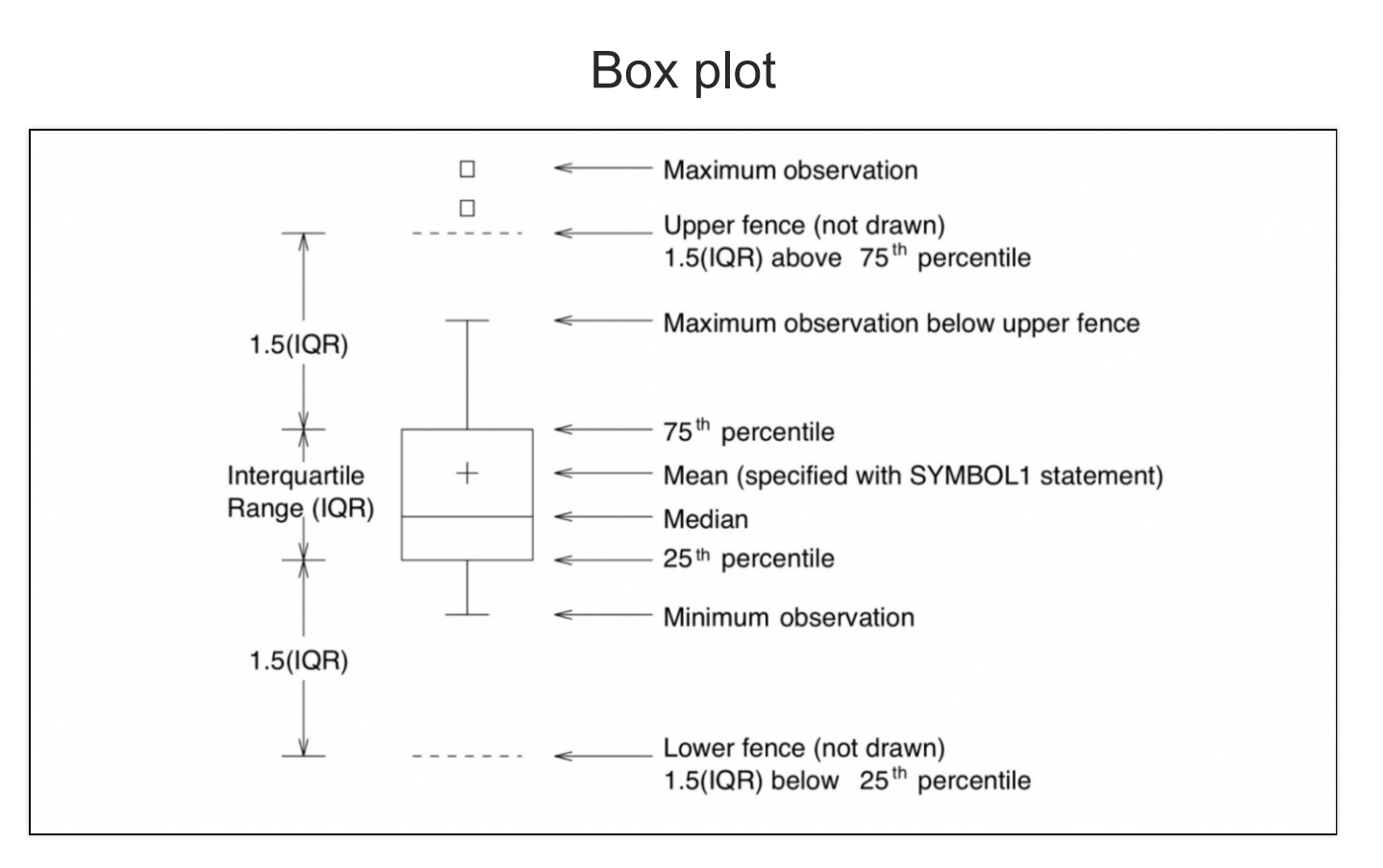
통계를 이해하는데 중요한 개념 중 하나는 4분위수다.25%, 50%(중앙값), 75%를 기준으로 구분해서 1, 2, 3, 4분위수로 나눈 것이다.여기서 중요한 개념은 $Q3 -Q1$의 값은 IQR이라고 보고 $Q1, Q3$를 기준으로 IQR를 1.5배한 값에서 더 멀어
11.Regression_Basic
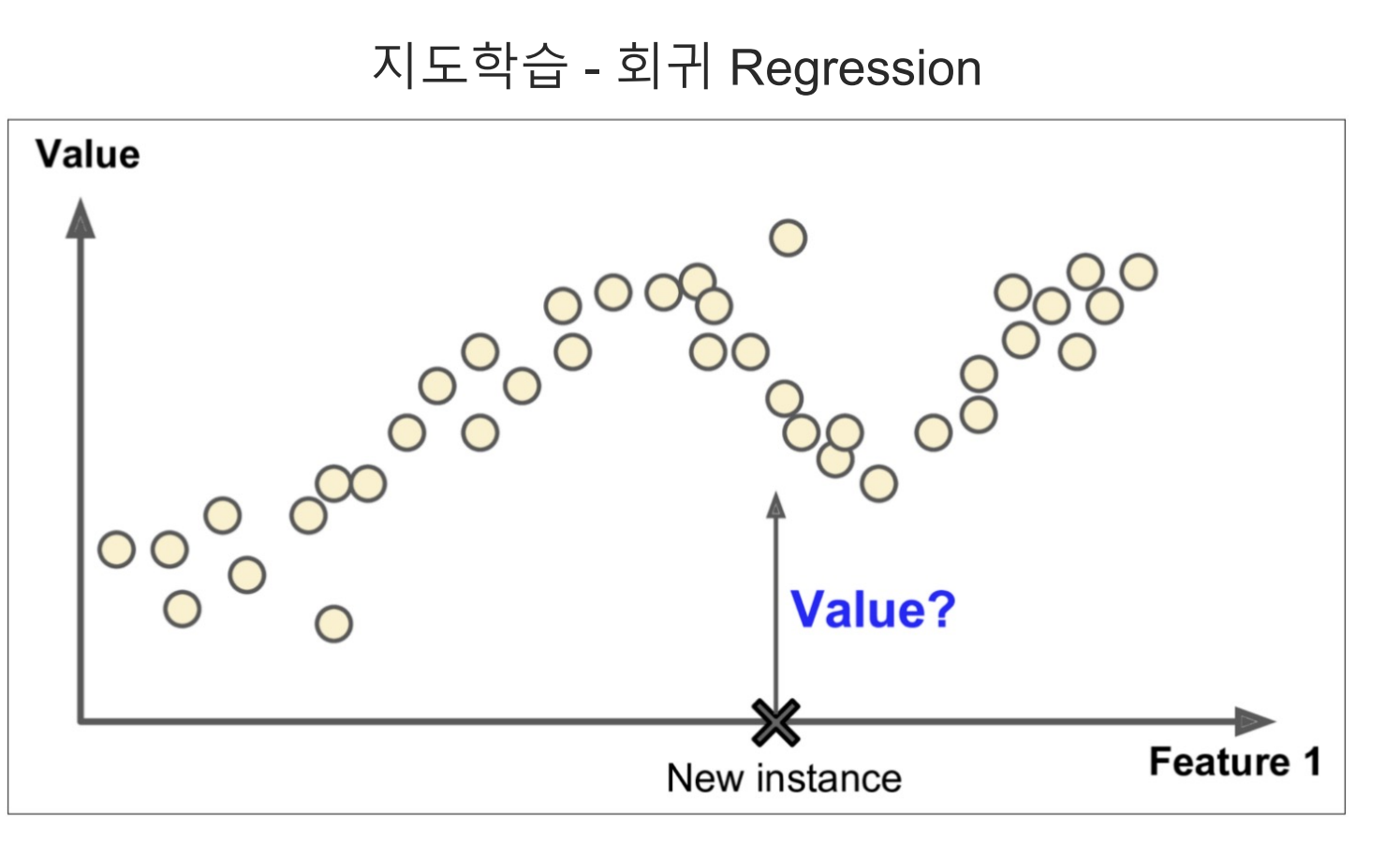
회귀에서 지도학습은 기존의 데이터를 통해 모델링을 한 후 새로운 Data를 넣었을 때 이를 예측하는 것이다. 함수와 비슷하다$f(x) = ax+b$일 때 $x$에 넣는 값에 따라 출력이 달라지듯이선형회귀의 경우 결국 1차식 함수의 방정식을 추론하는 것과 같다.$y$축이
12.12. cost_function
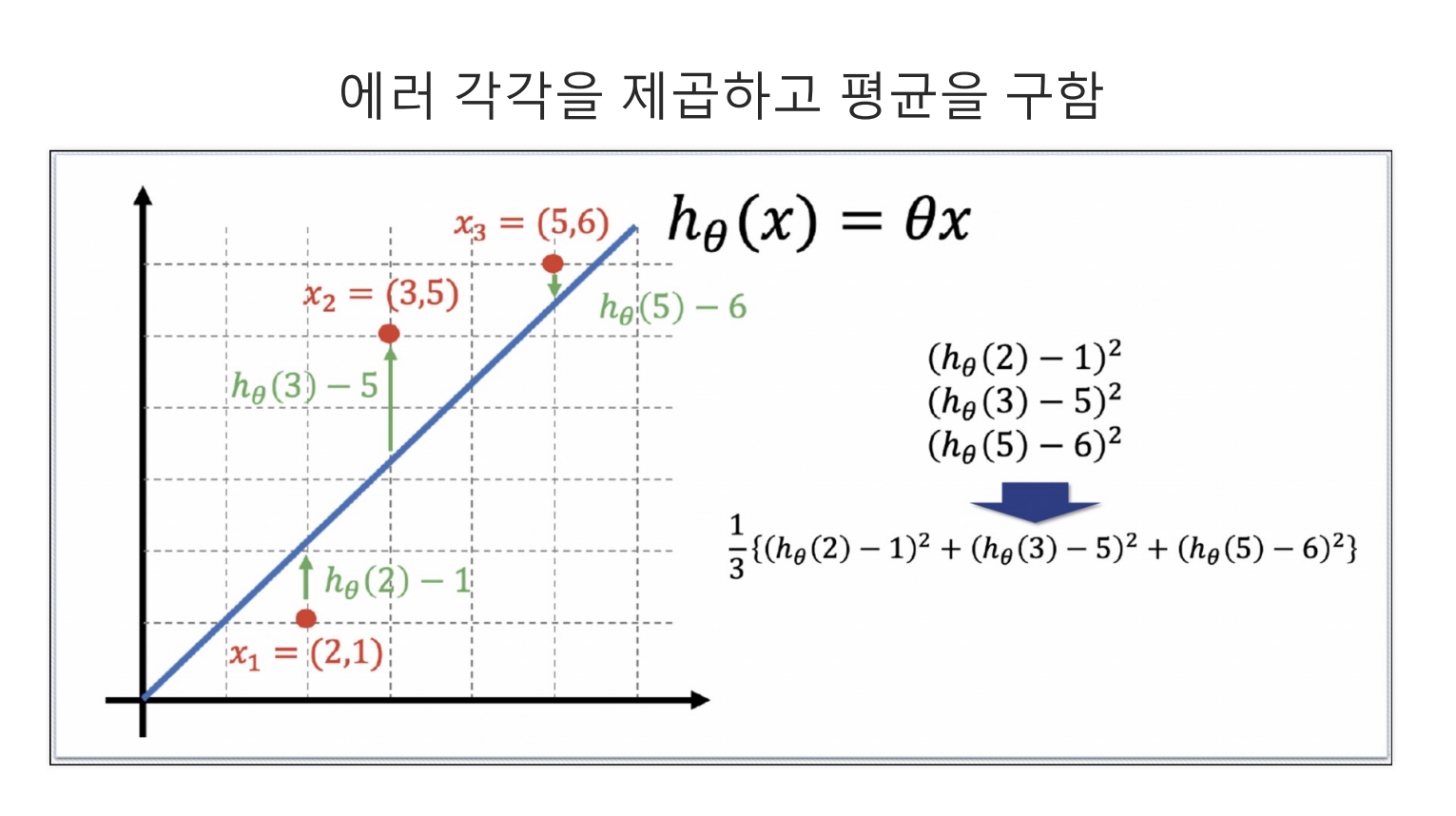
cost Function은 예측값을 실제값을 빼고 제곱한 값의 평균이다.해당 값은 얼마나 예측값이 실제값을 잘 예측했는지 보여주는 지표로서, 낮을수록 모델의 성능이 좋다는 것을 보여준다.중요한 점은 해당 Cost Function을 최소화하는 직선을 찾는 것이다.이를 n
13.Logistic_Regression
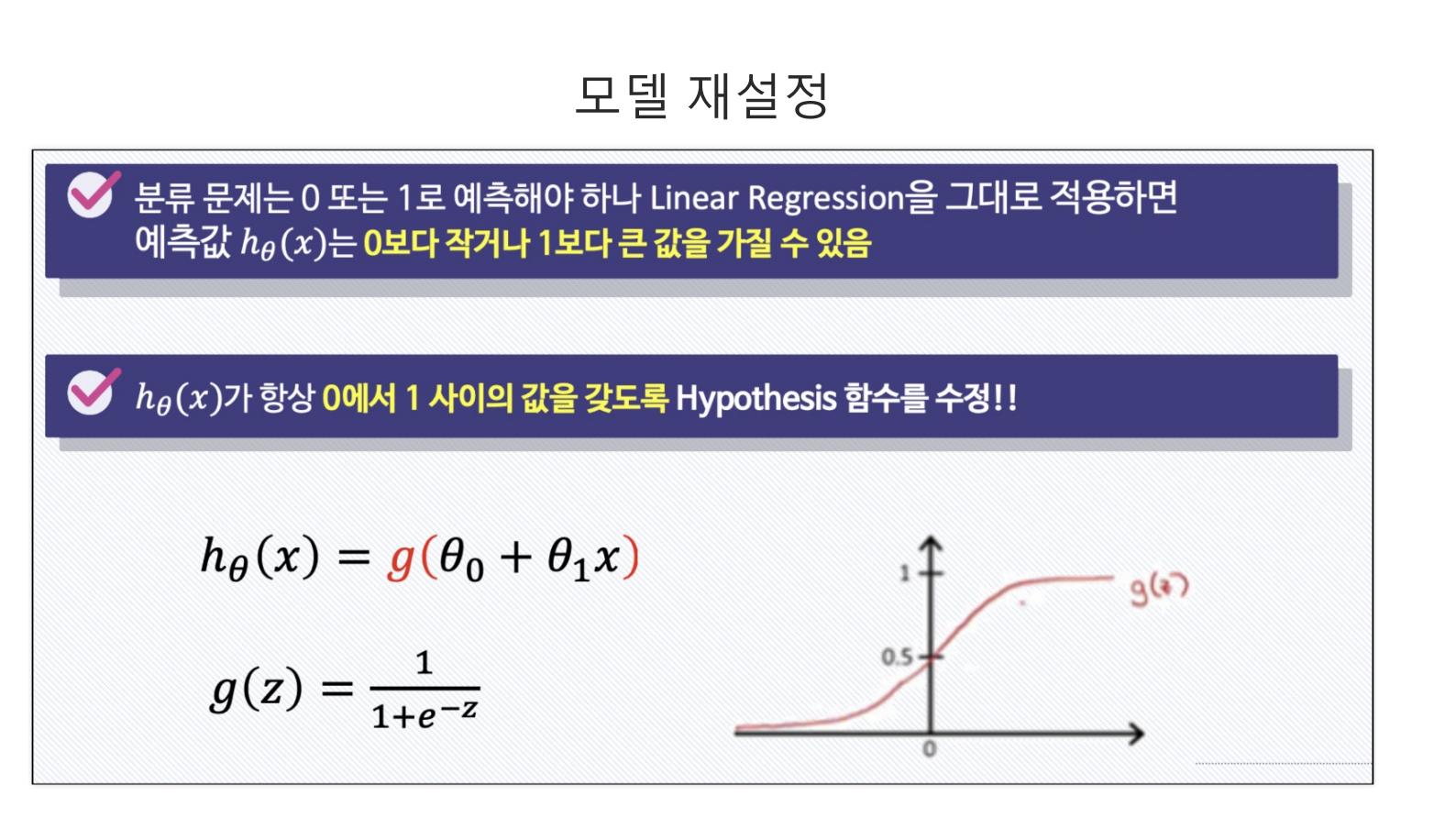
Logistic Regression모델은 결과값이 0과 1사이에서만 나와야 할 경우 사용하는 모델링 방법이다.이를 위해 사용하는 것이 시그모이드다. 시그모이드는 어떠한 입력값을 받아도 결국 0과 1사이에서 값을 출력하기 때문이다.임의의 숫자를 $z$변수에 저장하고 $\
14.angsangbeul
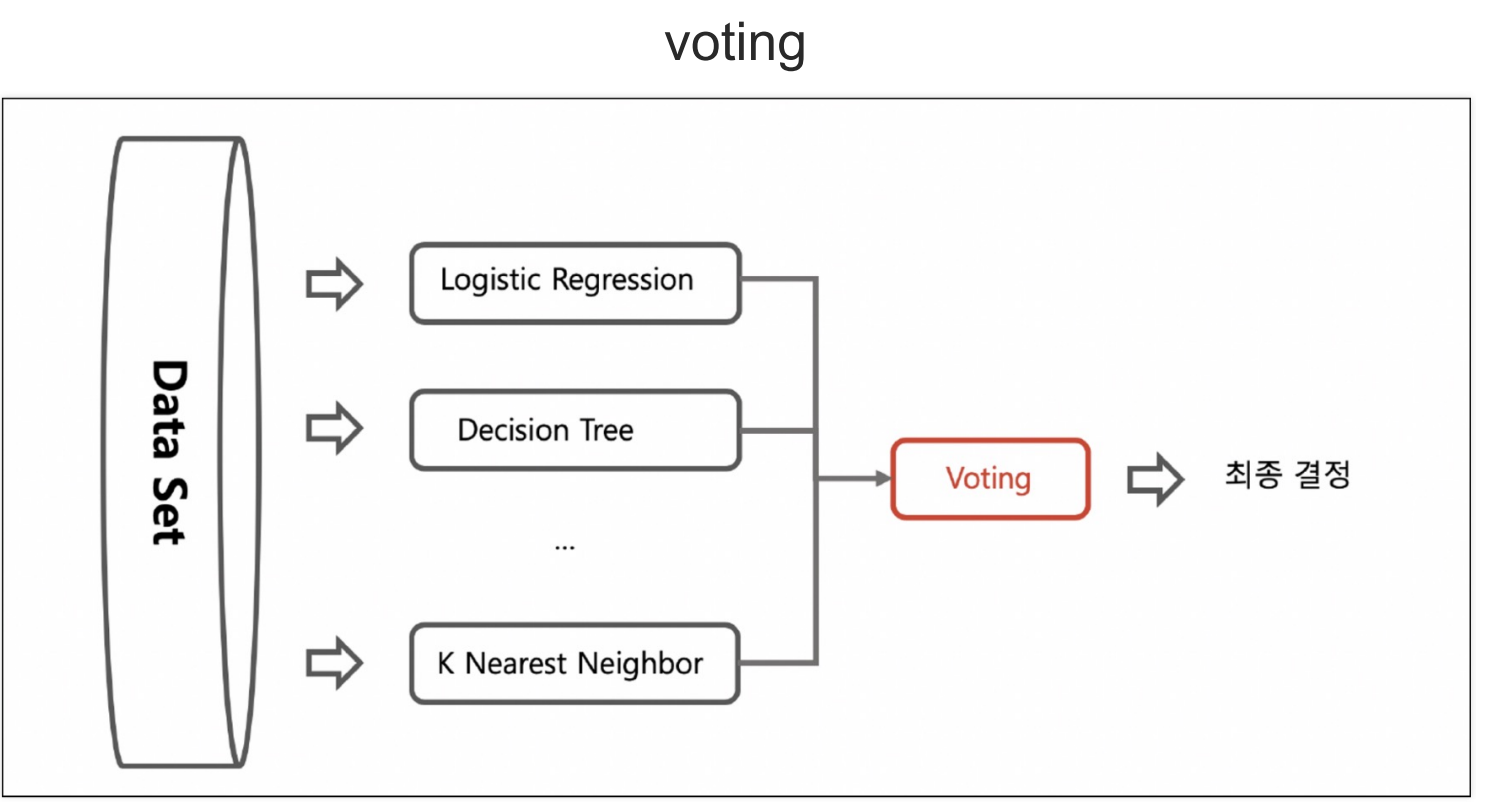
앙상블은 머신러닝을 모델링하는 과정에서 단일 알고리즘을 사용하는 것이 아니라, 여러 방법을 통해 성능을 올리는 것을 의미한다.먼저 voting방식은 여러 모델링 기법을 구분해서 성능을 테스트 후 제일 좋은 성능의 기법을 사용하는 방법이다.bagging은 하나의 데이터셋
15.Boosting
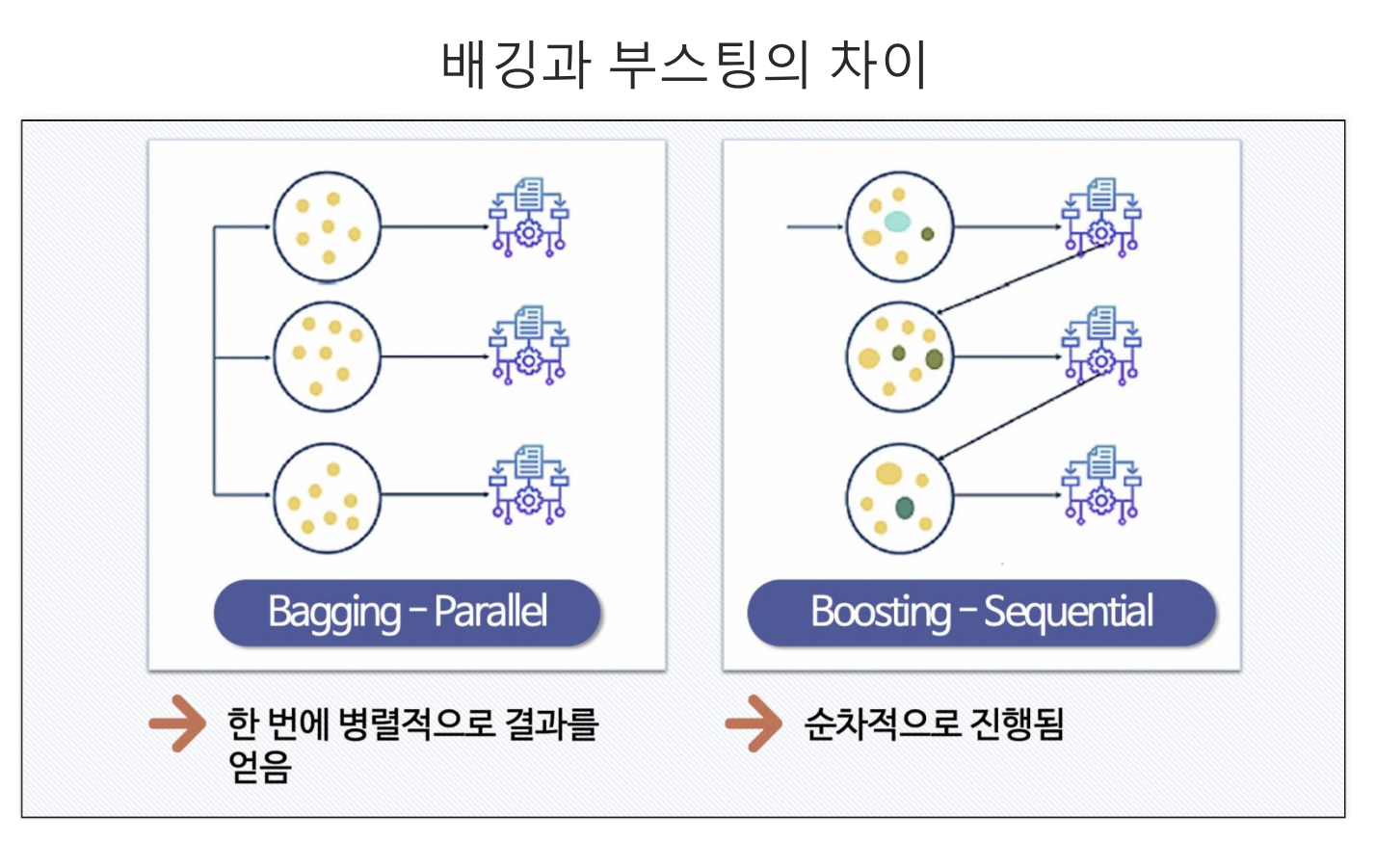
부스팅은 앙상블의 한 기법으로 배깅과의 차이는 배깅은 병렬적으로 데이터를 구분 후 교육을 하지만, 부스팅은 순차적(꼬리를 물듯이) 교육을 진행한다. 부스팅 중 adaboost의 경우 위 그림과 같이 모델 결과 중 예측이 틀린 데이터를 기준으로 순차적 교육을 진행한다
16.Knn
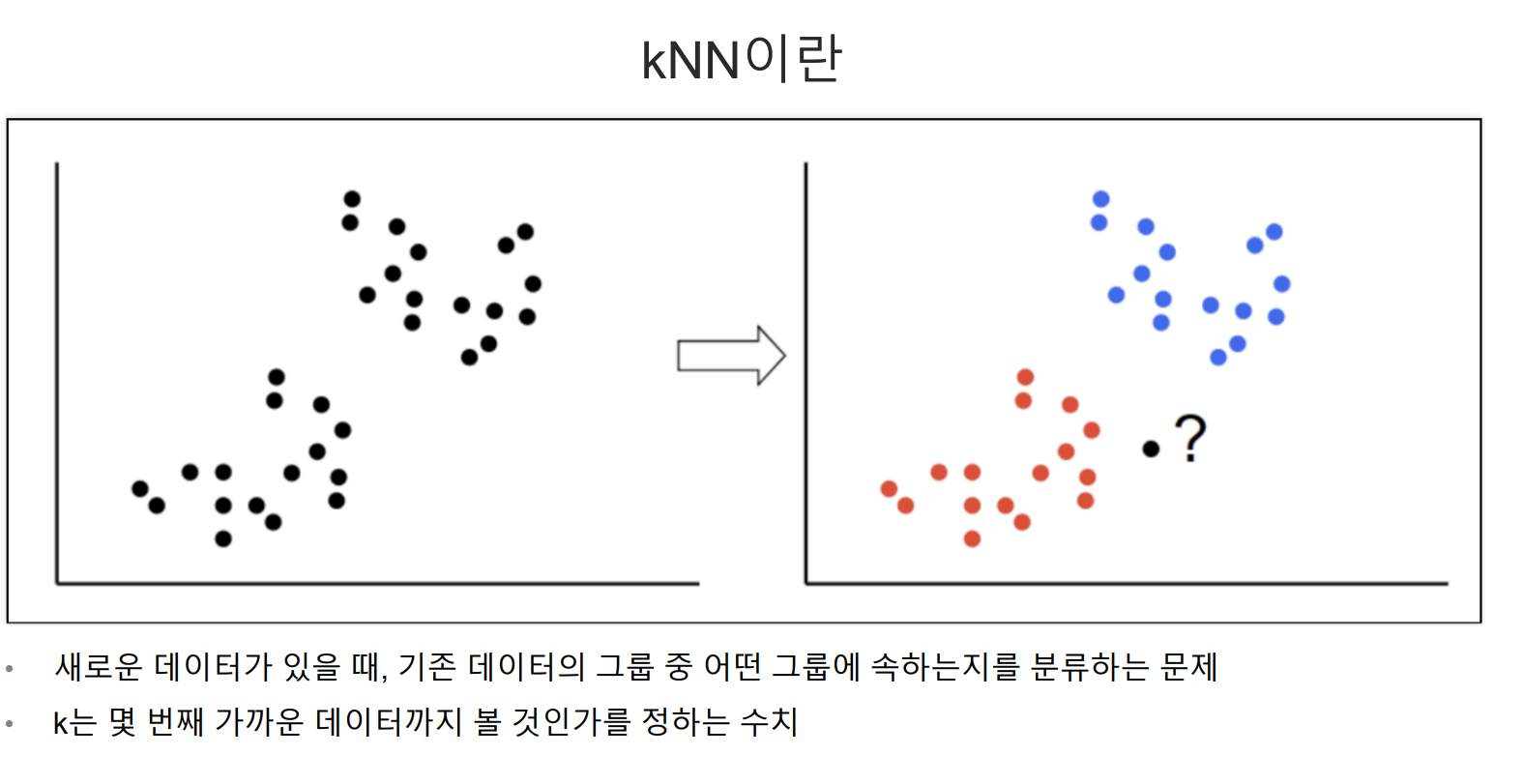
Knn은 되게 간단한 방법으로 하나의 데이터를 기준으로 근처에서 가까운 데이터에 분류하는 방법이다.만약 k값을 5로 준다면 5번째로 가까운 데이터 분류에 넣고 분석하는 기법인데, 간단하고 빠르지만 변수, 특징이 많은 데이터셋에서 사용하기 어렵다는 단점이 있다.iris데
17.Credit_Card_Fraud_Detection
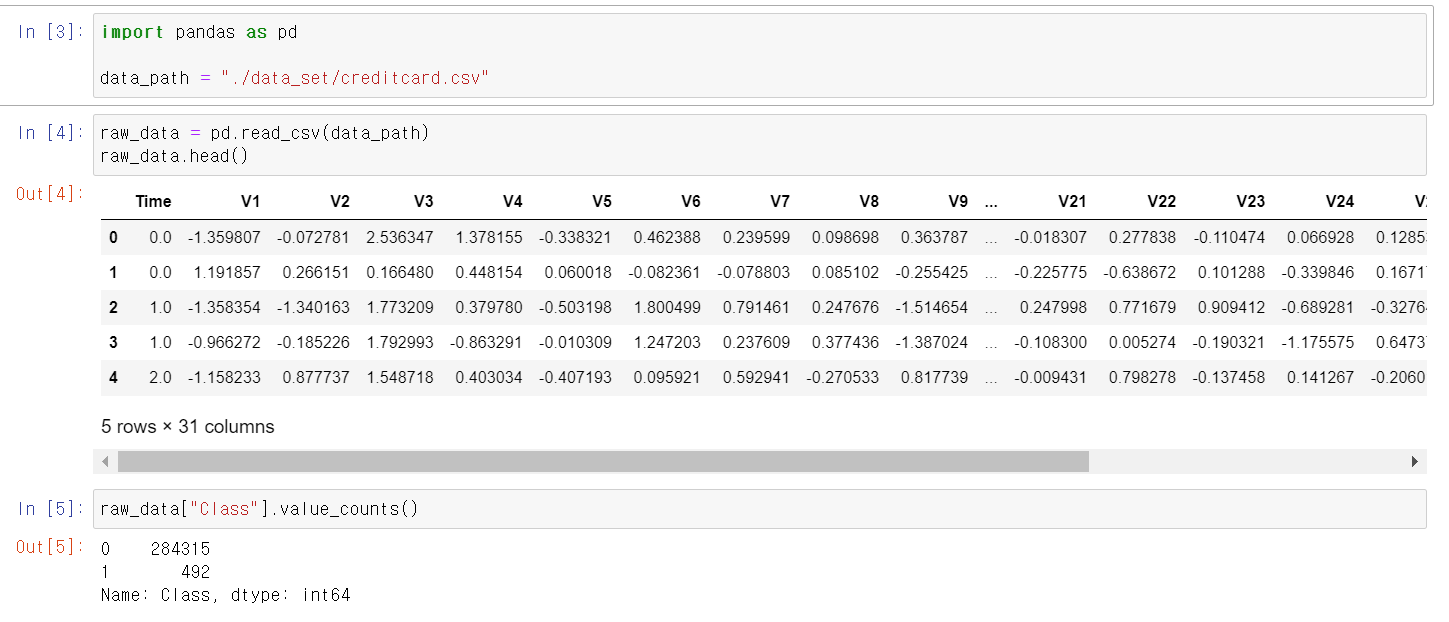
이번에는 금융권 데이터를 가지고 데이터 분석과 머신러닝 알고리즘을 활용해보자금융권 데이터는 개인정보가 많기 때문에 컬럼의 이름이 Vn으로 저장되어 있다.Class의 unique값은 0, 1이 있는데 0은 정상적인 신용카드 사용자, 1은 불법 신용카드 사용자다.Class
18.nltk
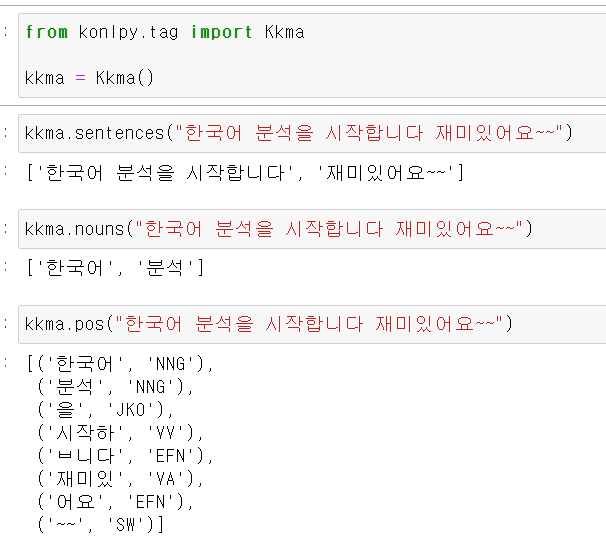
이제 정형화된 데이터가 아니라 자연어를 통해 머신러닝을 작동해보자먼저 우리나라에서 만든 모듈인 konlpy의 kkma(꼬꼬마)를 사용해서 각 단위에 따라 단어를 구분할 수 있다.다음은 한나눔 모듈로도 단어, 형태소를 구분할 수 있다.제일 많이 사용하는 모듈로는 Okt가
19.WordCloud

이번에는 자연어 머신러닝을 통해 그림에 자연어를 넣는 wordCloud작업을 해보자먼저 사용할 text파일을 불러온다.그리고 많이 사용되지만 큰 의미가 없는 단어를 stopword로 지정하고,사용할 그림 파일을 불러온다.해당 그림은 이상한 나라의 엘리스 그림이다.mat
20.Naver_API
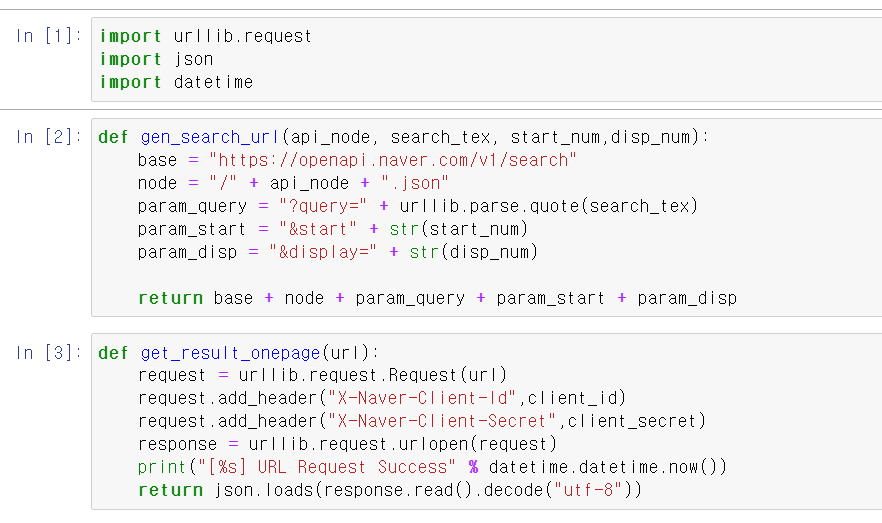
이제 네이버에서 Train데이터를 크롤링해서 불러온 후 자연어 모데링을 해보자크롤링 과정을 예전 EDA할 때 사용한 함수를 불러와서 사용했다.파이썬이 들어가는 검색을 한 후 100개의 문장을 추출하고,해당 문장에서 html기호를 빼고 리스트의 인덱스마다 하나의 문장씩
21.Principal_iris_wine
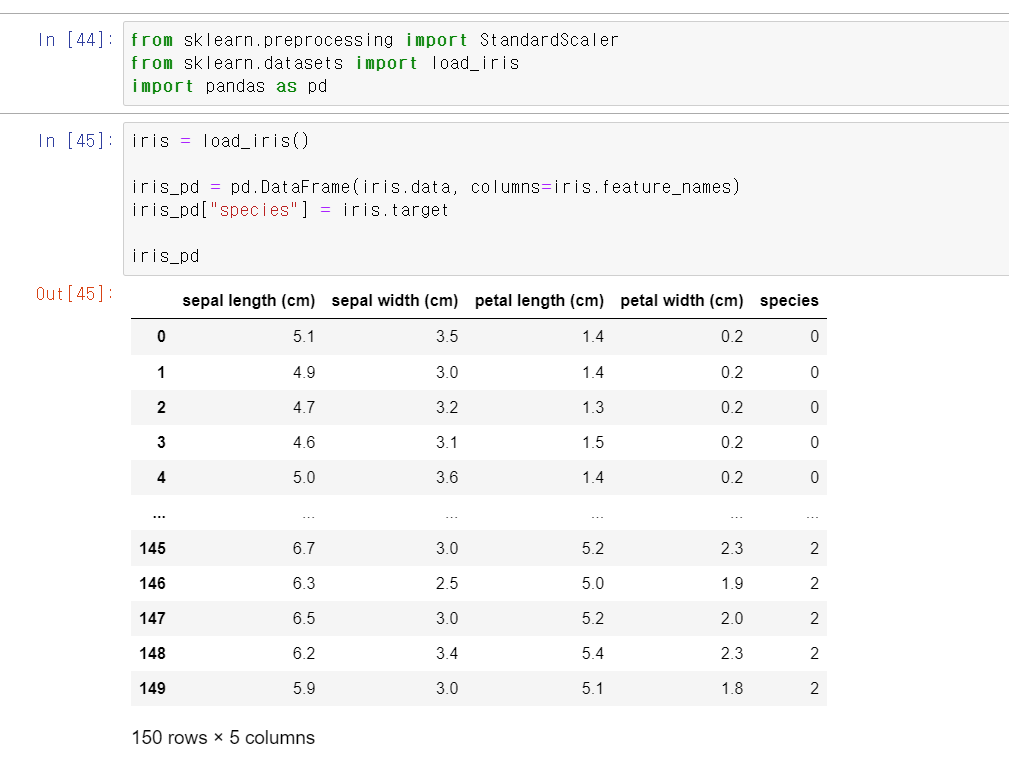
이번에는 기존의 데이터를 차원축소해서 분석하는 Principal_component를 사용해서 iris데이터와 wine데이터를 분석해보자먼저 정말 친숙한 iris 데이터를 불러온다.그리고 iris데이터를 StandardScaler로 변환 후 4개의 차원(column)을
22.principal_engineface
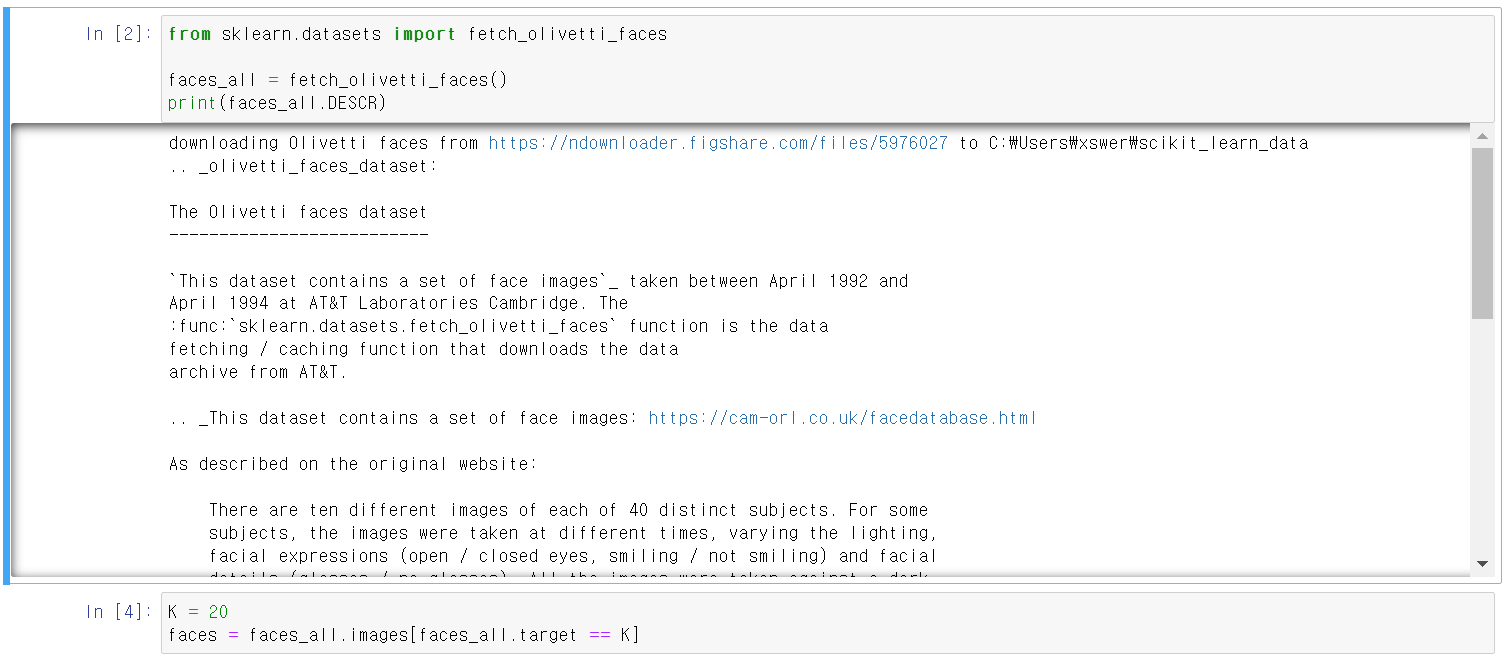
이번에는 Principal기법을 사용해서 사람의 사진도 차원을 축소할 수 있는지 확인해보자먼저 sklearn에서 사람 사진에 대한 자료를 업로드를 한다.그리고 K=20은 해당 자료에서 20번째 사람의 사진을 불러오는 것이다.한 사람의 여러 표정을 matplotlib.p
23.HAR_Principal
이번에는 HAR(human activity recognition)에 차원을 축소해서 데이터를 분석해보자먼저 train, test 데이터를 가져오고, 정상적인 형태로 불러온 것을 확인했다.이제 기존의 x_train 데이터의 561개 차원을 PCA를 통해 2개로 축소하고,
24.PCA_KNn
이번에는 mnist데이터를 통해 PCA와 KNn기법을 모두 사용해보자해당 데이터는 숫자 적을 때 모양을 데이터 셋으로 저장한 것인데, 첫번 째 컬럼은 라벨이며 나머지는 해당 라벨에 대한 데이터다.785개 중 1개는 label이며 나머지 784개는 $28\\times28
25.Book_Recommendation
이번에는 문장간의 유사도를 통해 책을 추천하는 시스템을 작게 구현해보자먼저 book 데이터를 업로드한다. 해당 데이터는 캐글에서 가져왔다.해당 여러 데이터로 구분되어 있는데 순위, tag, tag_name 등 여러 데이터를 불러왔다.이제 분석하기 좋게 pandas의 m