- 이번에는 mnist데이터를 통해 PCA와 KNn기법을 모두 사용해보자
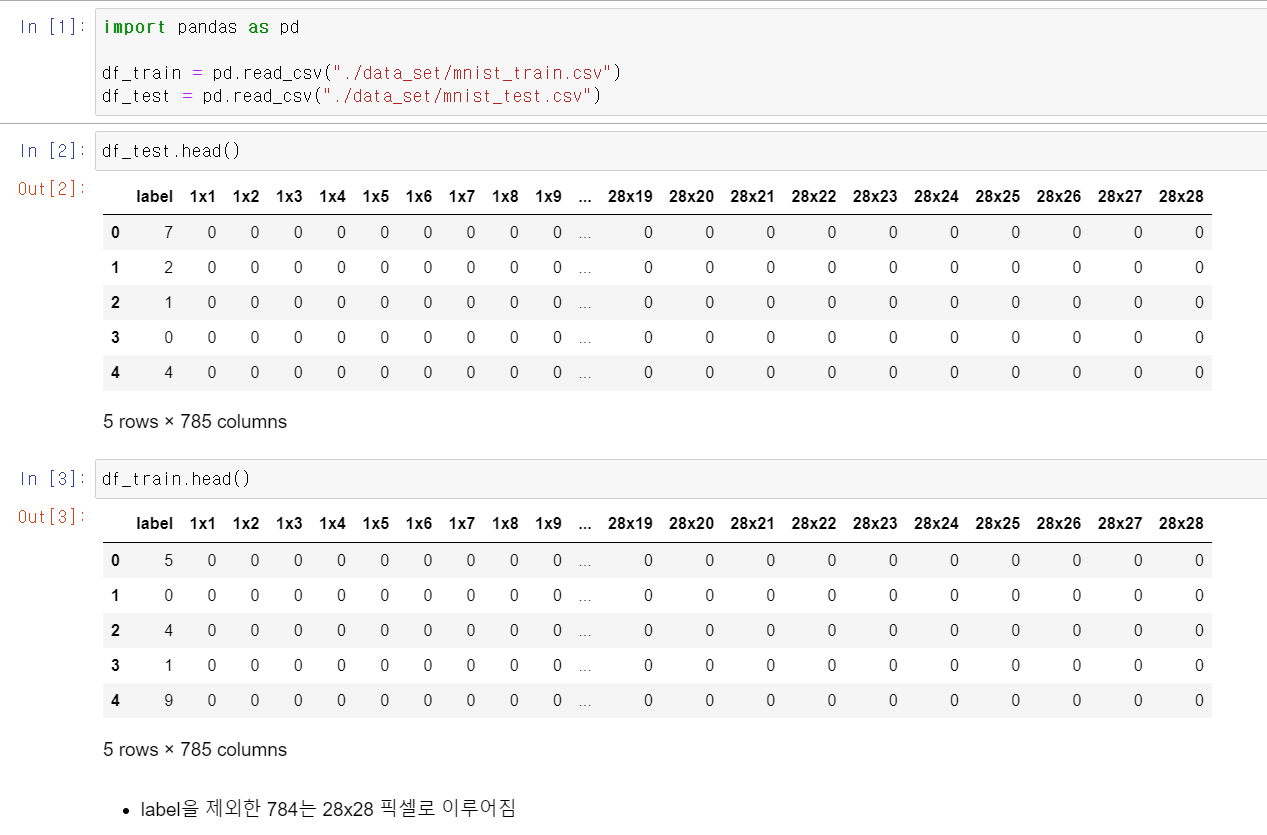
- 해당 데이터는 숫자 적을 때 모양을 데이터 셋으로 저장한 것인데, 첫번 째 컬럼은 라벨이며 나머지는 해당 라벨에 대한 데이터다.
- 785개 중 1개는 label이며 나머지 784개는 개의 픽셀로 이루어진 데이터다.
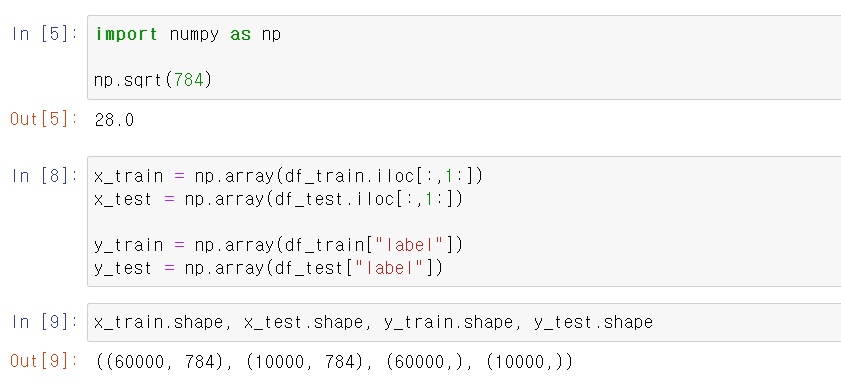
- x_train, x_test, y_train, y_test 총 4개로 구분하고, 데이터를 확인해보니 정상적으로 분리됐다.

- 먼저 기존 데이터를 28*28로 형태로 변환한 뒤 시각화를 해봤다.

- 위에 title은 y_train 즉 라벨값(실제값)이며, 밑에 그려진 그림은 x_trina데이터를 array(28, 28)형태로 변환한 뒤 그린 그림이다.
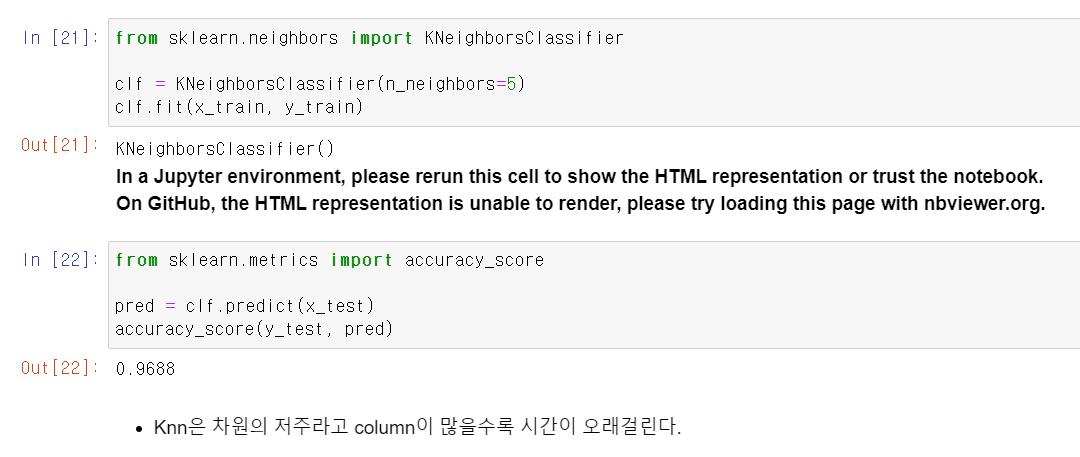
- 이제 Knn모듈을 다운받고, x_train을 y_train 정답으로 교육시키고 성능을 확인해보나 97%성능을 보여준다.

- 이제 더 정확한 테스를 위해 Pipeline, PCA, GridSearchCV, StraifiledkFold 모듈을 다운받고,
- 5개 단계로 교차검증을 설정 후 PCA로 데이터 변환 후 KNN으로 교육시킨다.

- 교차검증에서 가장 높은 성능은 93%이며, KNn 10에서, pca는 10개 차원에서 가장 높은 성능을 보인다.
- 해당 설정으로 x_test로 예측하고, y데이터에 검증 결과 93%성능을 보여준다.
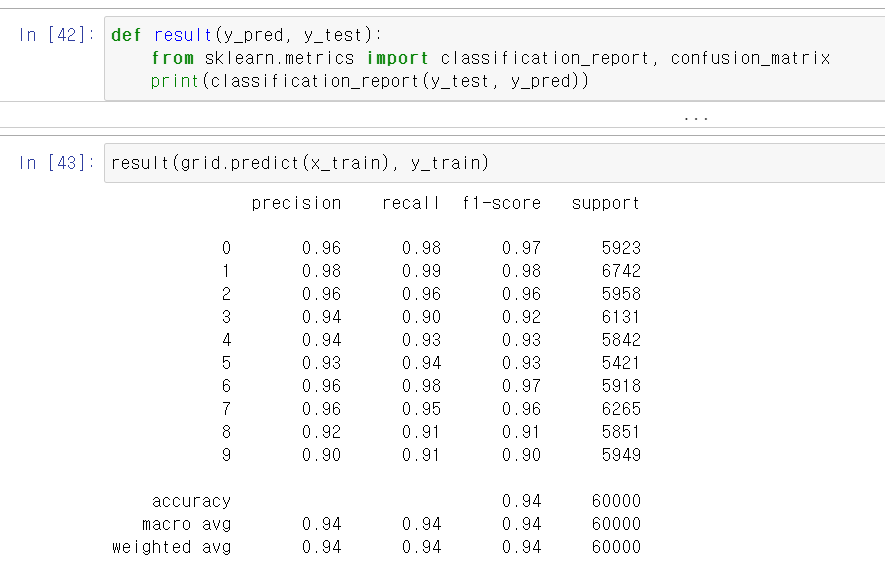
- 이제 confusion_martix로 확인해보니 각 단계의 결과를 보여준다.
- 이제 실제 검증을 해보니 실제값과 예측값이 정상적으로 일치한다.

상황을 바꿀 수 없다면, 나를 바꾸자