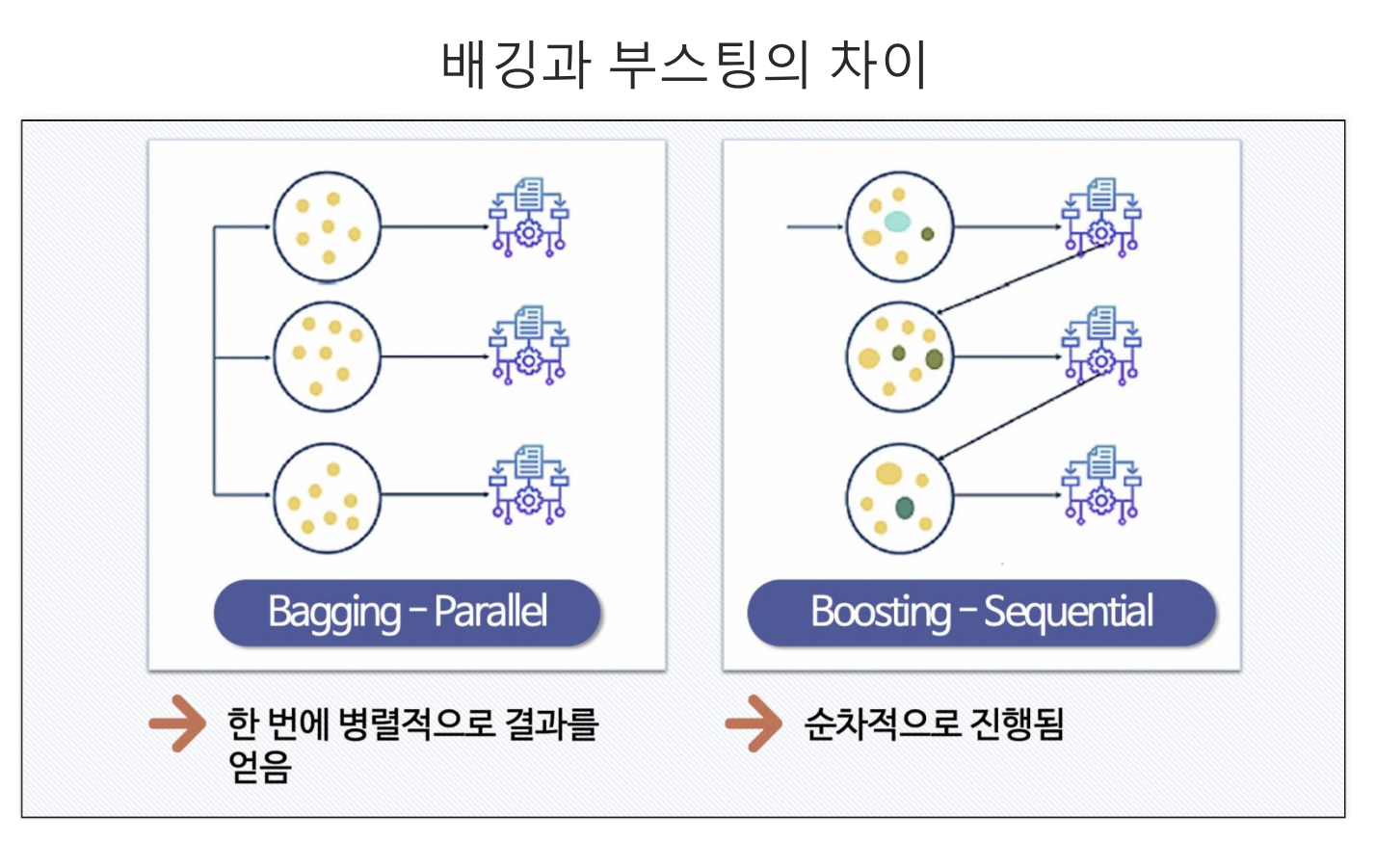
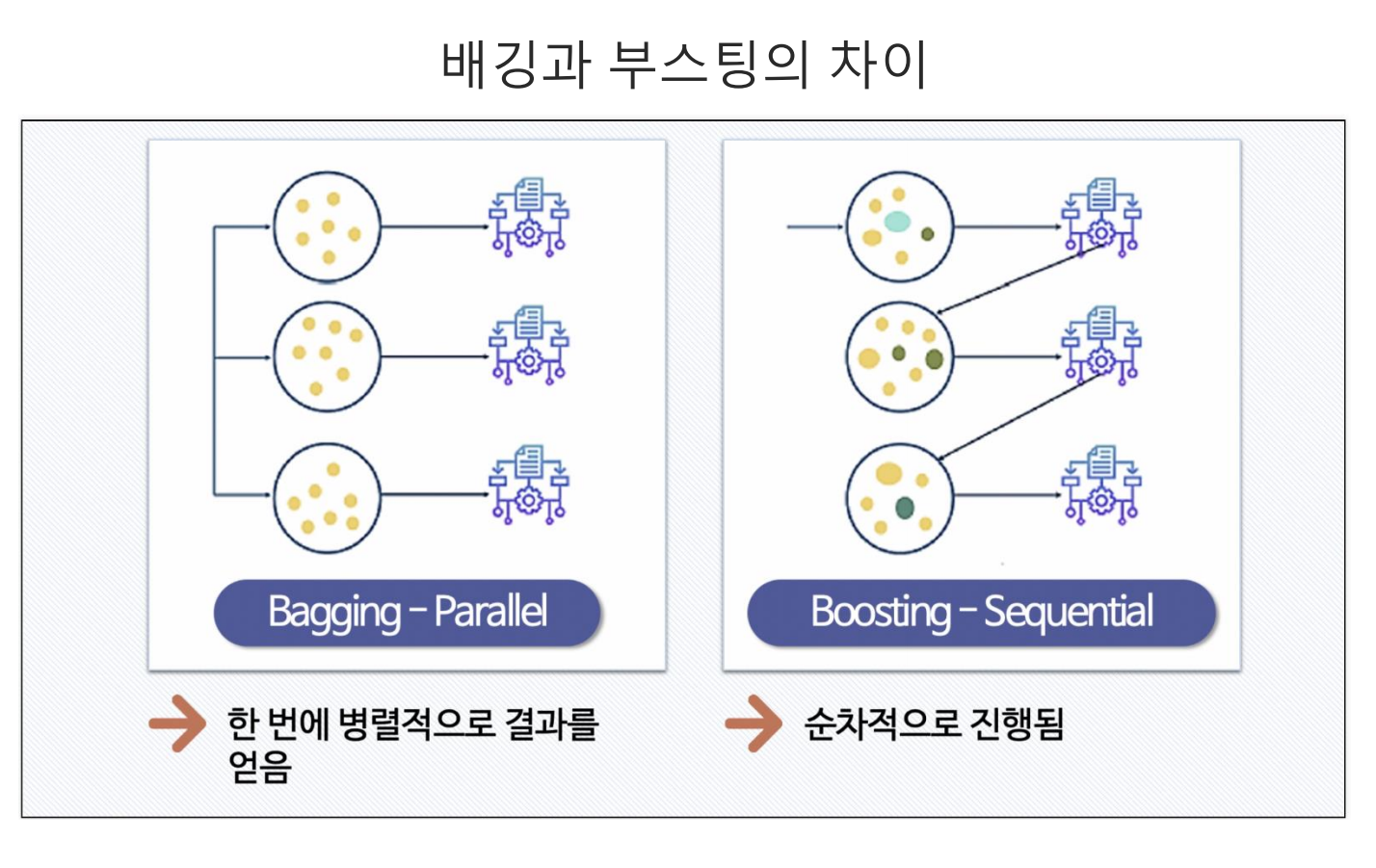
- 부스팅은 앙상블의 한 기법으로 배깅과의 차이는 배깅은 병렬적으로 데이터를 구분 후 교육을 하지만, 부스팅은 순차적(꼬리를 물듯이) 교육을 진행한다.
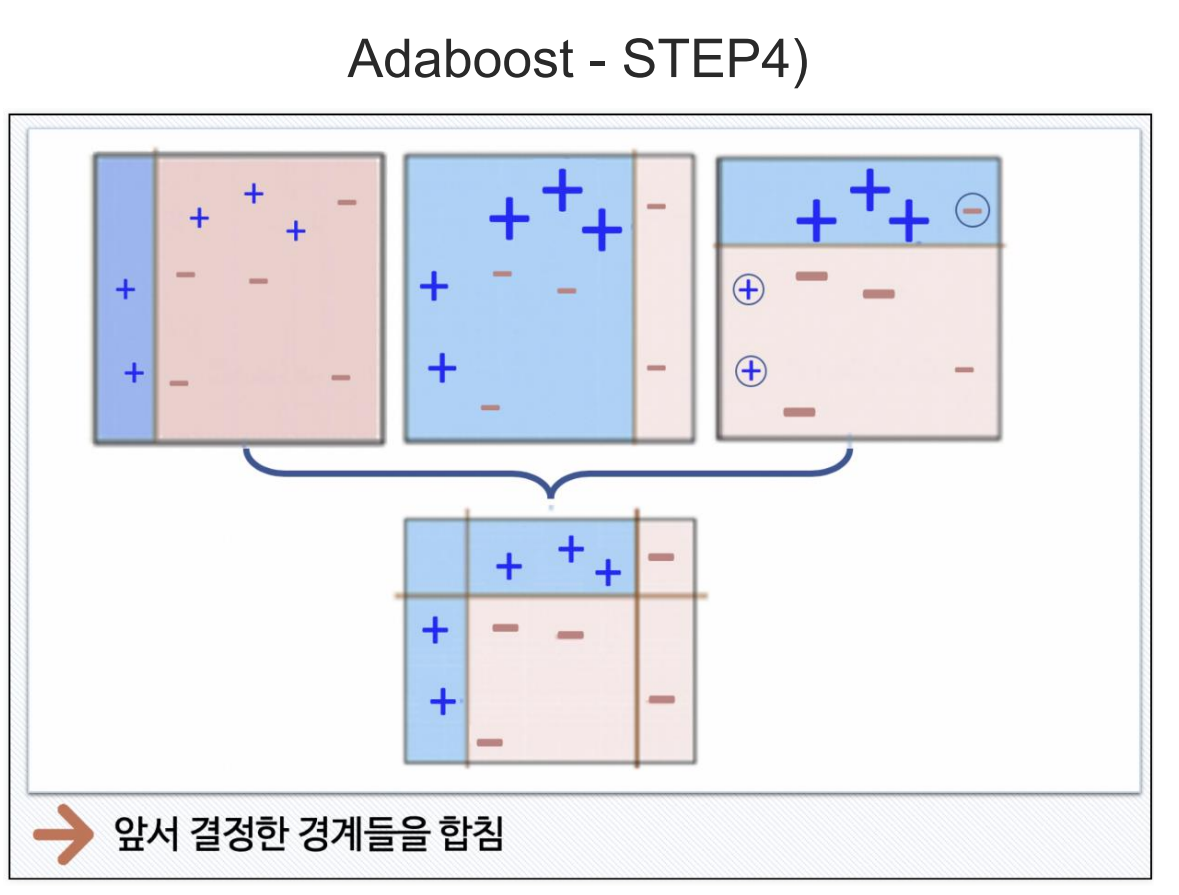
- 부스팅 중 adaboost의 경우 위 그림과 같이 모델 결과 중 예측이 틀린 데이터를 기준으로 순차적 교육을 진행한다.

- 부스팅의 기법은 위 3가지를 자주 사용하며, 상황에 따라 다양하게 사용한다.
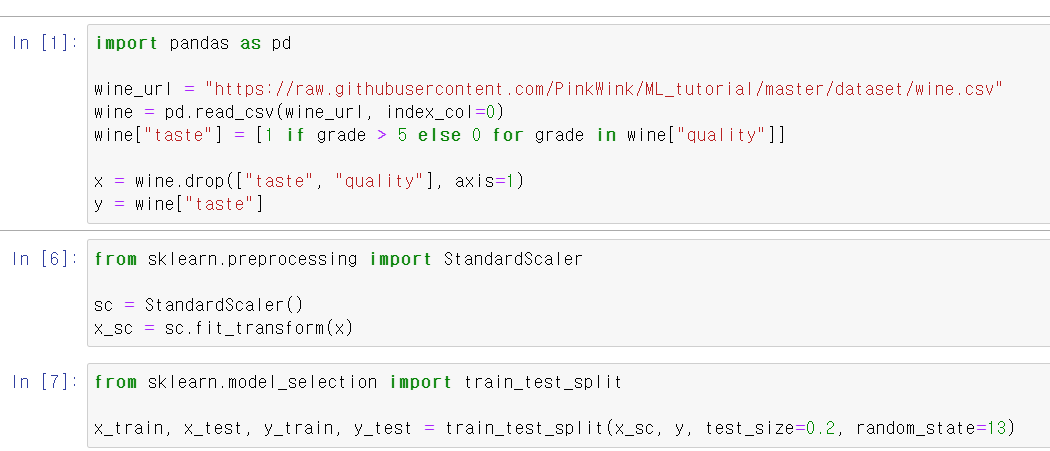
- 이제 자주 사용한 wine데이터를 통해 boosting을 해보자
- 위 데이터 형태와 정보를 앞서 많이 했으니...생략
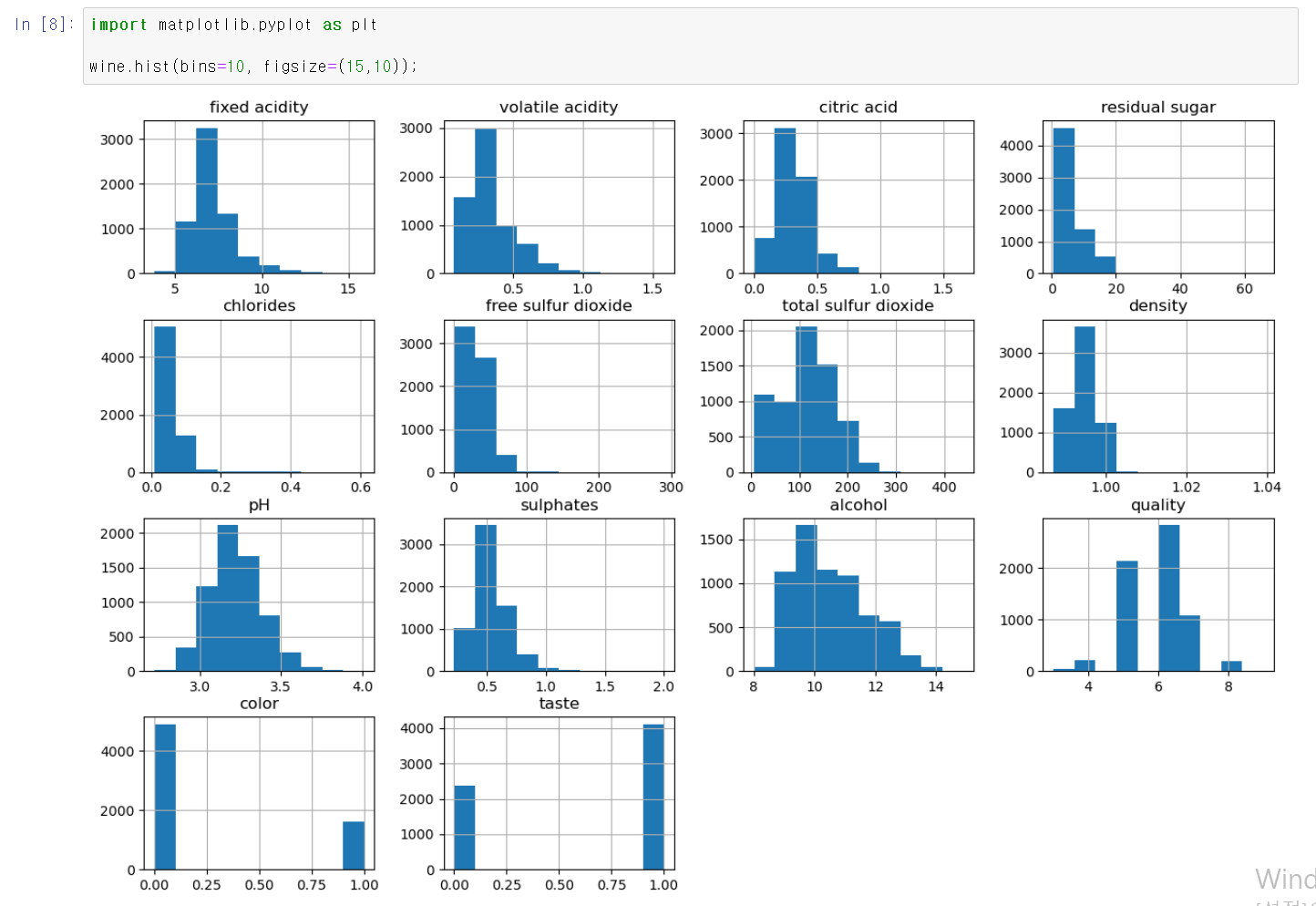
- 머신러닝 하기 전에 먼저 데이터를 간략하게 분석을 해보자
- 분포를 본 결과 pH와 alchol 등 몇몇 데이터의 분포가 보기 좋다.
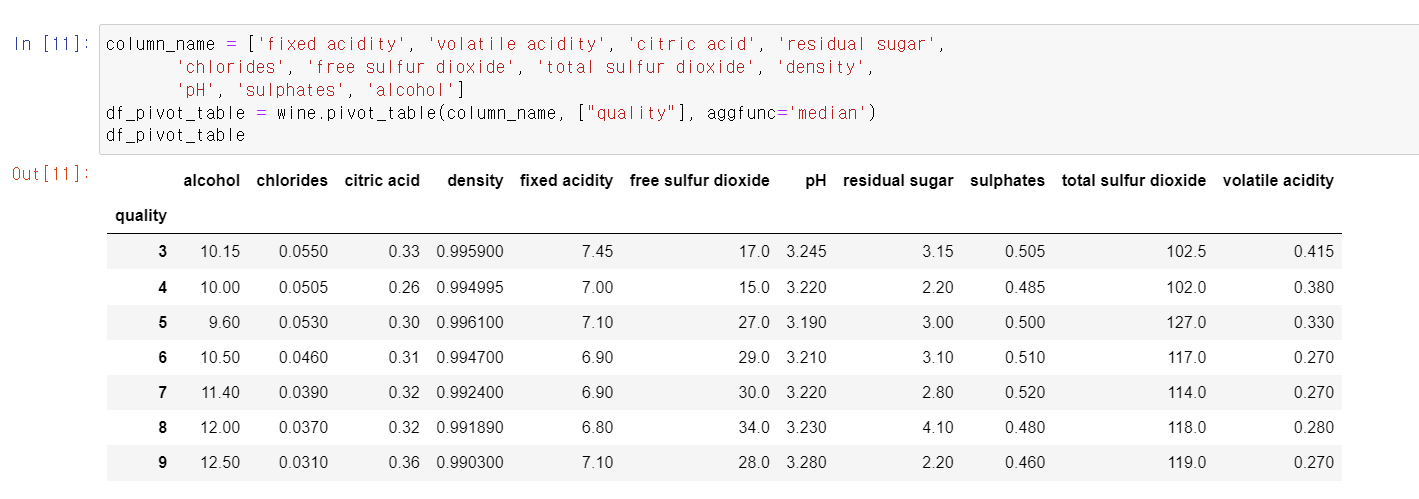
- 이제 라벨링을 할 quality를 인덱스로 각 데이터의 median값을 봤다.
- 가장 눈에 뛰는 데이터는 alcohol로 알코올이 높을수록 quality가 높은 추세를 보인다. 아직 잠정적으로
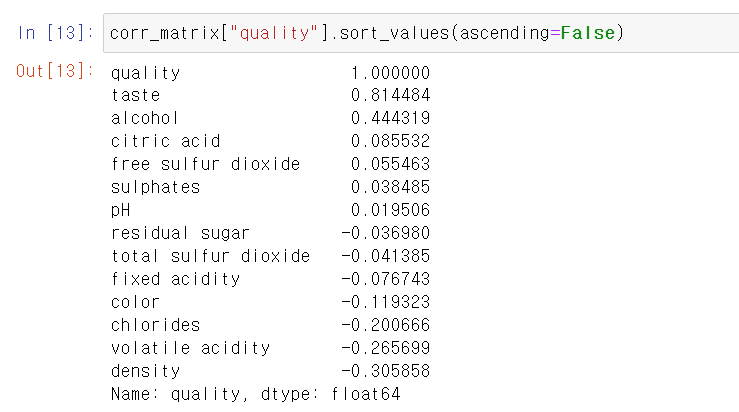
- 이제 상관계수를 보니 taste는 맛이니까 당연히 높고, 상관계수에서는 양의 상관계수들이 대체로 높게 나타난다.
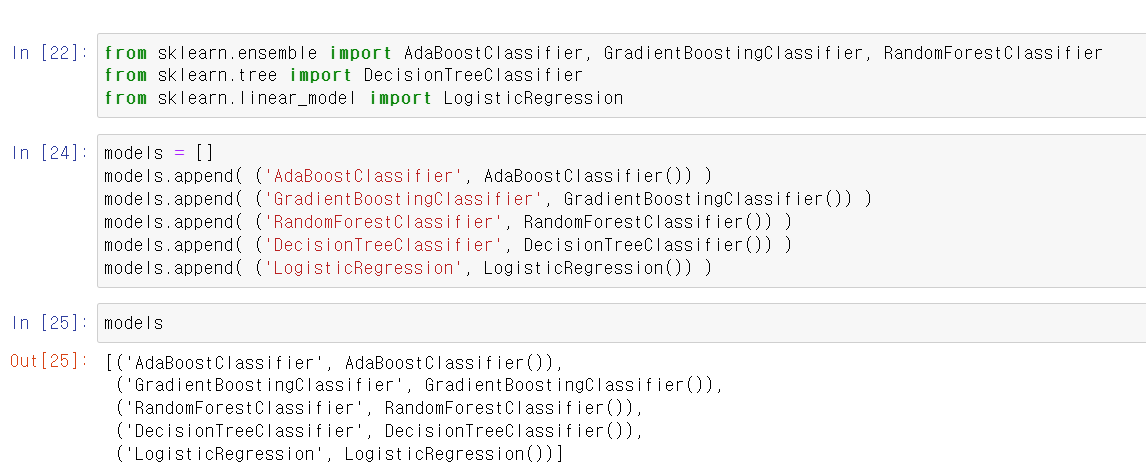
- 이제 각 부스팅 기법과 DecisionTree 및 로지스틱 회귀 모듈을 import하고,
- models라는 빈 리스트에 튜플 형태로 각 모델링 기법의 이름과 변수를 저장한다.
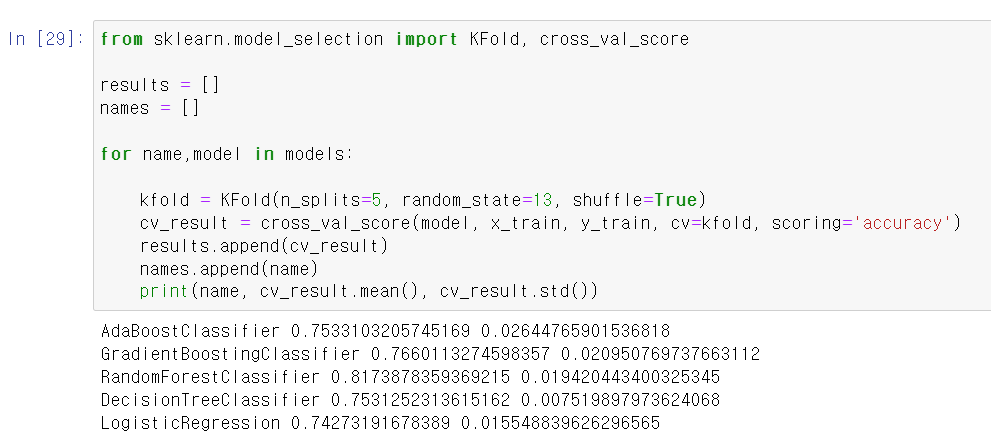
- 이제 교차검증과 성능 테스트를 위해 FKold, cross_val_score를 import하고 각 모델링마다 성능을 테스트 한 결과 랜덤포레스트가 가장 높은 성능을 보인다.
- 100%는 아니지만, 랜덤포레스트가 대체로 좋은 성능을 보여주니 자주 애용하자
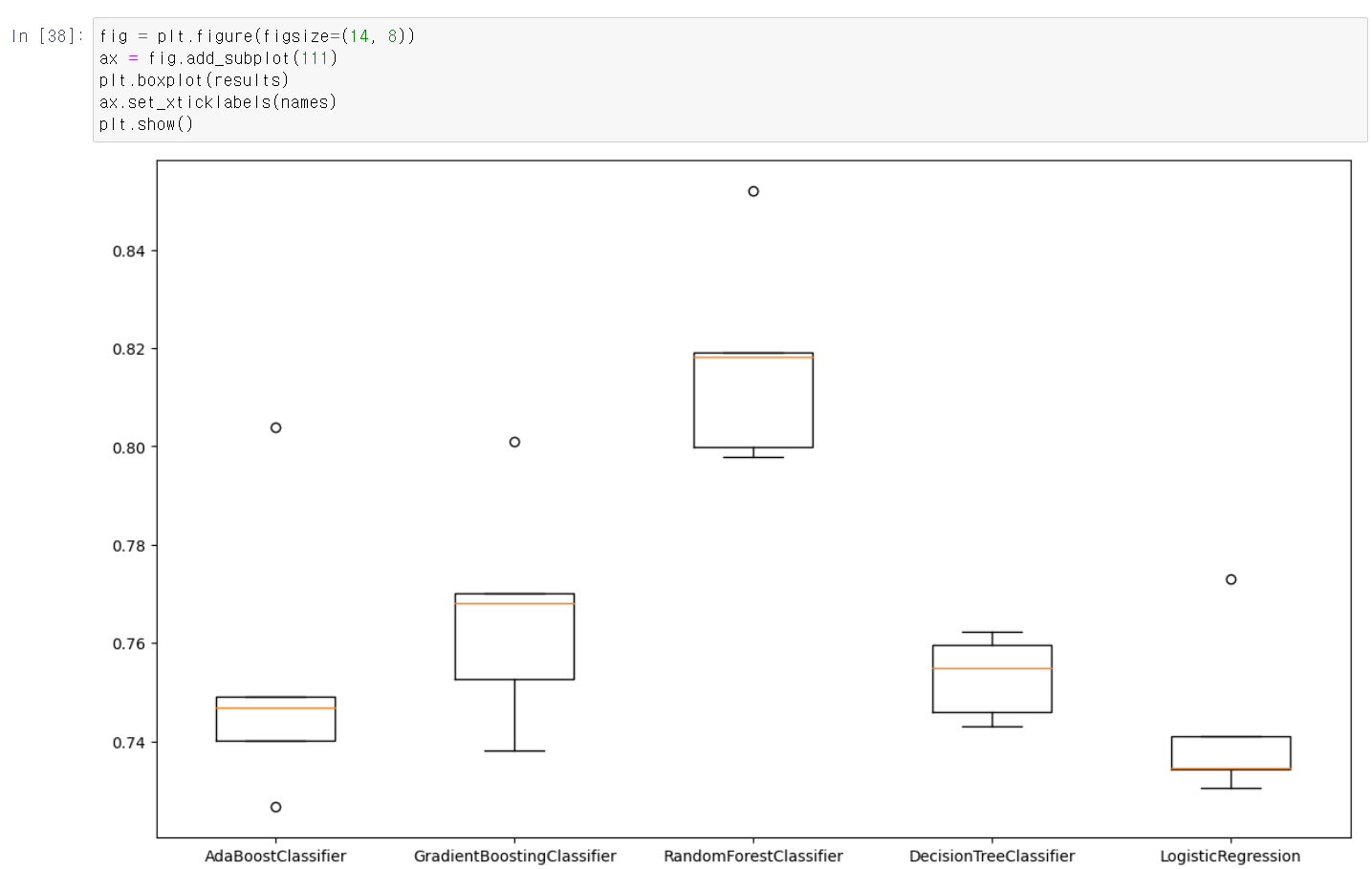
- 결과를 boxplot으로 시각화 결과 역시 높은 수치가 랜덤포레스트에서 보인다.
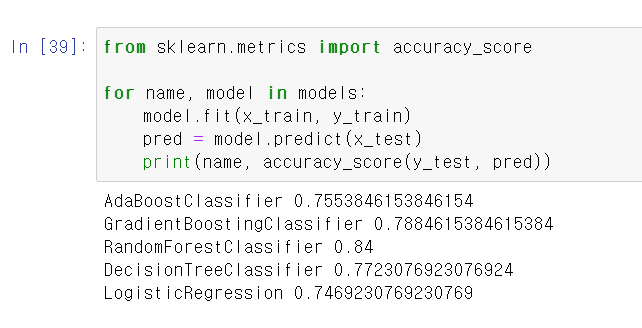
- 이제 교차검증에서 결과 확인 후 test데이터에 모델링을 한 결과를 대입해서 비교해보니 역시 0.84 즉 84%로 성능으로 랜덤포레스트가 제일 높게 나왔다.

상황을 바꿀 수 없다면, 나를 바꾸자